Artificial Intelligence
Category: Compute

Build scalable containerized RAG based generative AI applications in AWS using Amazon EKS with Amazon Bedrock
In this post, we demonstrate a solution using Amazon Elastic Kubernetes Service (EKS) with Amazon Bedrock to build scalable and containerized RAG solutions for your generative AI applications on AWS while bringing your unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way.

How Hexagon built an AI assistant using AWS generative AI services
Recognizing the transformative benefits of generative AI for enterprises, we at Hexagon’s Asset Lifecycle Intelligence division sought to enhance how users interact with our Enterprise Asset Management (EAM) products. Understanding these advantages, we partnered with AWS to embark on a journey to develop HxGN Alix, an AI-powered digital worker using AWS generative AI services. This blog post explores the strategy, development, and implementation of HxGN Alix, demonstrating how a tailored AI solution can drive efficiency and enhance user satisfaction.

WordFinder app: Harnessing generative AI on AWS for aphasia communication
In this post, we showcase how Dr. Kori Ramajoo, Dr. Sonia Brownsett, Prof. David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology.

Build a FinOps agent using Amazon Bedrock with multi-agent capability and Amazon Nova as the foundation model
In this post, we use the multi-agent feature of Amazon Bedrock to demonstrate a powerful and innovative approach to AWS cost management. By using the advanced capabilities of Amazon Nova FMs, we’ve developed a solution that showcases how AI-driven agents can revolutionize the way organizations analyze, optimize, and manage their AWS costs.

Automate Amazon EKS troubleshooting using an Amazon Bedrock agentic workflow
In this post, we demonstrate how to orchestrate multiple Amazon Bedrock agents to create a sophisticated Amazon EKS troubleshooting system. By enabling collaboration between specialized agents—deriving insights from K8sGPT and performing actions through the ArgoCD framework—you can build a comprehensive automation that identifies, analyzes, and resolves cluster issues with minimal human intervention.

Host concurrent LLMs with LoRAX
In this post, we explore how Low-Rank Adaptation (LoRA) can be used to address these challenges effectively. Specifically, we discuss using LoRA serving with LoRA eXchange (LoRAX) and Amazon Elastic Compute Cloud (Amazon EC2) GPU instances, allowing organizations to efficiently manage and serve their growing portfolio of fine-tuned models, optimize costs, and provide seamless performance for their customers.
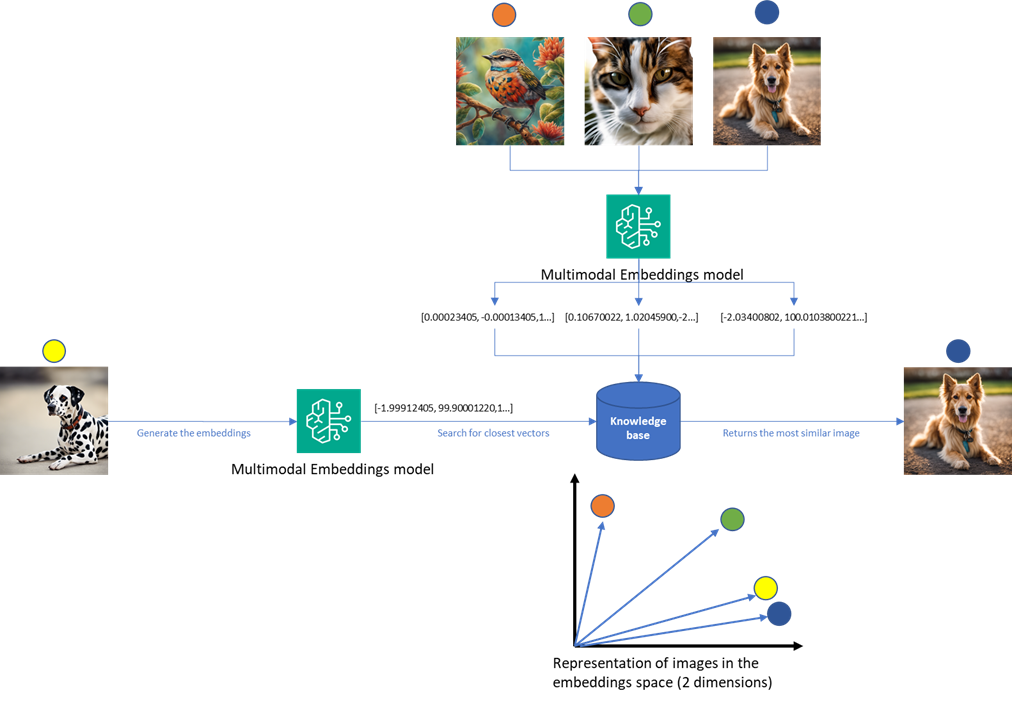
Build a computer vision-based asset inventory application with low or no training
In this post, we present a solution using generative AI and large language models (LLMs) to alleviate the time-consuming and labor-intensive tasks required to build a computer vision application, enabling you to immediately start taking pictures of your asset labels and extract the necessary information to update the inventory using AWS services

Optimizing Mixtral 8x7B on Amazon SageMaker with AWS Inferentia2
This post demonstrates how to deploy and serve the Mixtral 8x7B language model on AWS Inferentia2 instances for cost-effective, high-performance inference. We’ll walk through model compilation using Hugging Face Optimum Neuron, which provides a set of tools enabling straightforward model loading, training, and inference, and the Text Generation Inference (TGI) Container, which has the toolkit for deploying and serving LLMs with Hugging Face.

Streamline AWS resource troubleshooting with Amazon Bedrock Agents and AWS Support Automation Workflows
AWS provides a powerful tool called AWS Support Automation Workflows, which is a collection of curated AWS Systems Manager self-service automation runbooks. These runbooks are created by AWS Support Engineering with best practices learned from solving customer issues. They enable AWS customers to troubleshoot, diagnose, and remediate common issues with their AWS resources. In this post, we explore how to use the power of Amazon Bedrock Agents and AWS Support Automation Workflows to create an intelligent agent capable of troubleshooting issues with AWS resources.

Integrate generative AI capabilities into Microsoft Office using Amazon Bedrock
In this blog post, we showcase a powerful solution that seamlessly integrates AWS generative AI capabilities in the form of large language models (LLMs) based on Amazon Bedrock into the Office experience. By harnessing the latest advancements in generative AI, we empower employees to unlock new levels of efficiency and creativity within the tools they already use every day.