Artificial Intelligence
Category: Expert (400)

Building age-responsive, context-aware AI with Amazon Bedrock Guardrails
In this post, we walk you through how to implement a fully automated, context-aware AI solution using a serverless architecture on AWS. This solution helps organizations looking to deploy responsible AI systems, align with compliance requirements for vulnerable populations, and help maintain appropriate and trustworthy AI responses across diverse user groups without compromising performance or governance.

Enhanced metrics for Amazon SageMaker AI endpoints: deeper visibility for better performance
SageMaker AI endpoints now support enhanced metrics with configurable publishing frequency. This launch provides the granular visibility needed to monitor, troubleshoot, and improve your production endpoints.

Multimodal embeddings at scale: AI data lake for media and entertainment workloads
This post shows you how to build a scalable multimodal video search system that enables natural language search across large video datasets using Amazon Nova models and Amazon OpenSearch Service. You will learn how to move beyond manual tagging and keyword-based searches to enable semantic search that captures the full richness of video content.

Detect and redact personally identifiable information using Amazon Bedrock Data Automation and Guardrails
This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability.
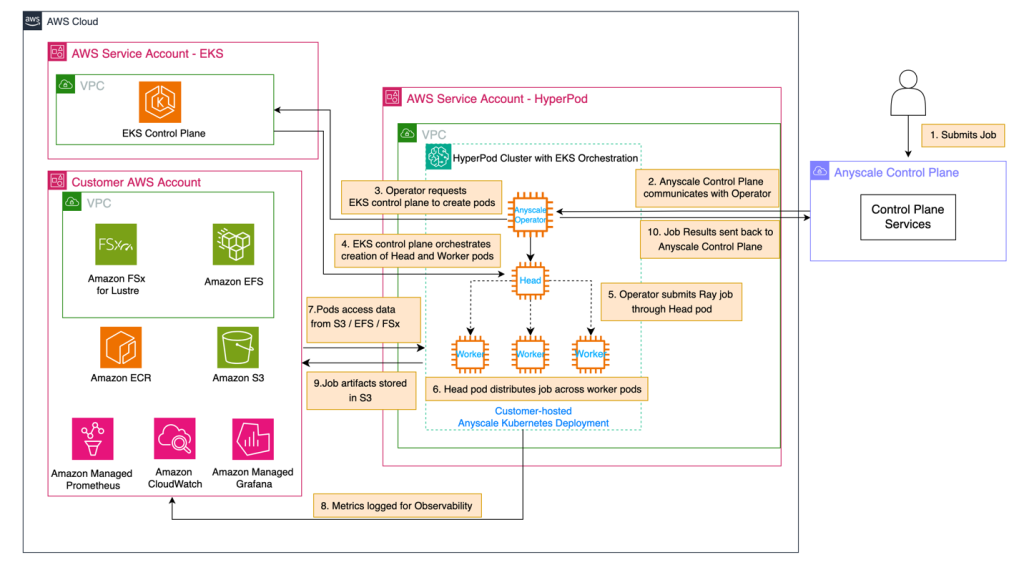
Use Amazon SageMaker HyperPod and Anyscale for next-generation distributed computing
In this post, we demonstrate how to integrate Amazon SageMaker HyperPod with Anyscale platform to address critical infrastructure challenges in building and deploying large-scale AI models. The combined solution provides robust infrastructure for distributed AI workloads with high-performance hardware, continuous monitoring, and seamless integration with Ray, the leading AI compute engine, enabling organizations to reduce time-to-market and lower total cost of ownership.
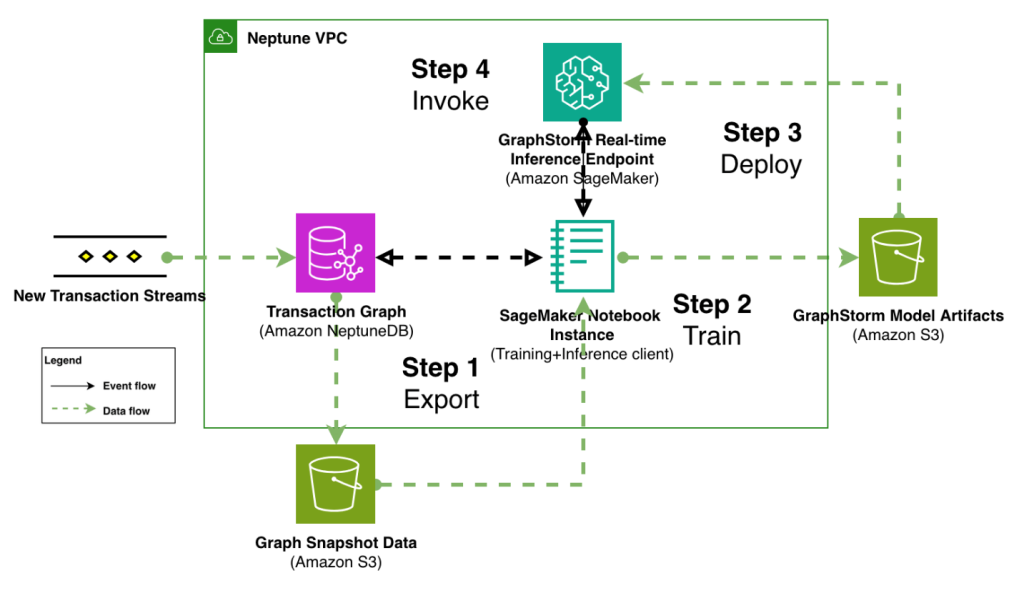
Modernize fraud prevention: GraphStorm v0.5 for real-time inference
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5’s new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with minimal operational overhead, enabling sub-second fraud detection on transaction graphs with billions of nodes and edges.
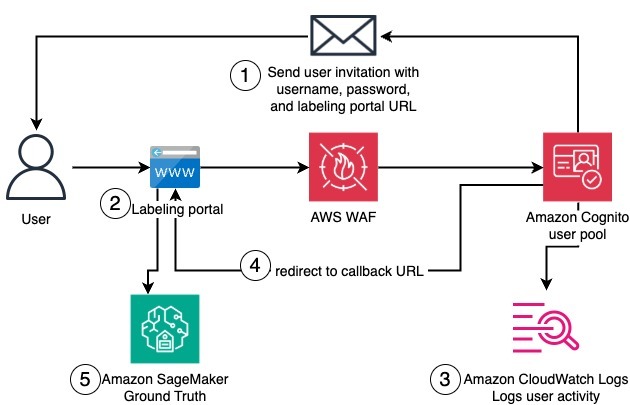
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.
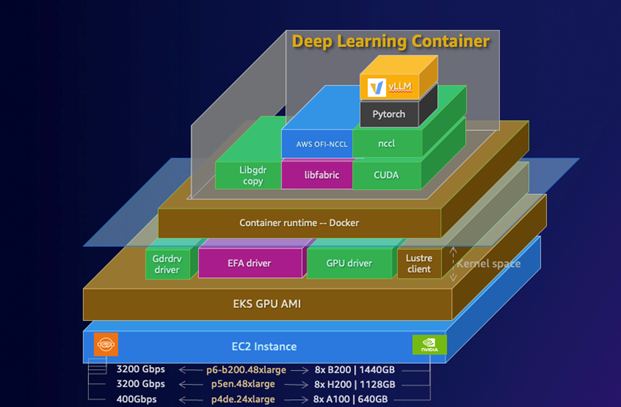
Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers
In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing how these purpose-built containers simplify deployment of this powerful inference engine. This solution can help you solve the complex infrastructure challenges of deploying LLMs while maintaining performance and cost-efficiency.

Training Llama 3.3 Swallow: A Japanese sovereign LLM on Amazon SageMaker HyperPod
The Institute of Science Tokyo has successfully trained Llama 3.3 Swallow, a 70-billion-parameter large language model (LLM) with enhanced Japanese capabilities, using Amazon SageMaker HyperPod. The model demonstrates superior performance in Japanese language tasks, outperforming GPT-4o-mini and other leading models. This technical report details the training infrastructure, optimizations, and best practices developed during the project.

Ray jobs on Amazon SageMaker HyperPod: scalable and resilient distributed AI
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. In this post, we demonstrate the steps involved in running Ray jobs on SageMaker HyperPod.