Artificial Intelligence
Extend model lineage to include ML features using Amazon SageMaker Feature Store
Feature engineering is expensive and time-consuming, which may lead you to adopt a feature store for managing features across teams and models. Unfortunately, machine learning (ML) lineage solutions have yet to adapt to this new concept of feature management. To achieve the full benefits of a feature store by enabling feature reuse, you need to be able to answer fundamental questions about features. For example, how were these features built? What models are using these features? What features does my model depend on? What features are built with this data source?
Amazon SageMaker provides two important building blocks to enable answering key feature lineage questions:
- SageMaker ML Lineage Tracking lets you create and store information about the steps of an ML workflow, from data preparation to model deployment. With lineage tracking information, you can reproduce the workflow steps, track model and dataset lineage, and establish model governance and audit standards.
- SageMaker Feature Store is a purpose-built solution for ML feature management. It helps data science teams reuse ML features across teams and models, serve features for model predictions at scale with low latency, and train and deploy new models more quickly and effectively.
In this post, we explain how to extend ML lineage to include ML features and feature processing, which can help data science teams move to proactive management of features. We provide a complete sample notebook showing how to easily add lineage tracking to your workflow. You then use that lineage to answer key questions about how models and features are built and what models and endpoints are consuming them.
Why is feature lineage important?
Feature lineage plays an important role in helping organizations scale their ML practice beyond the first few successful models to cover needs that emerge when they have multiple data science teams building and deploying hundreds or thousands of models. Consider the following diagram, showing a simplified view of the key artifacts and associations for a small set of models.
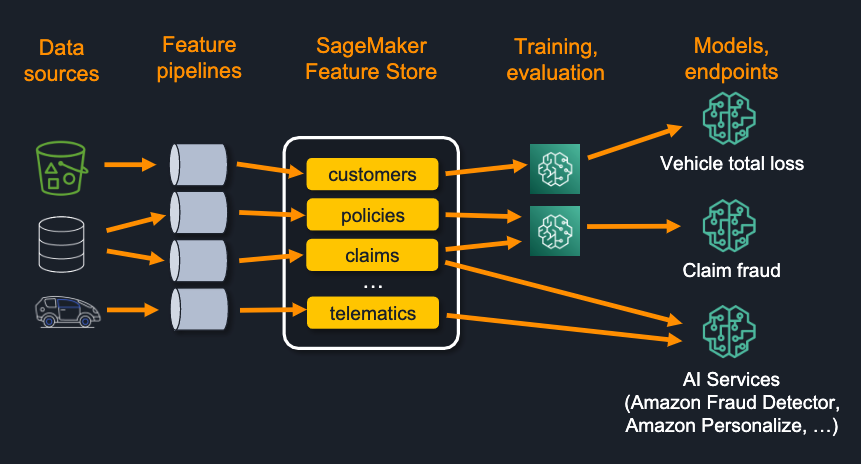
Imagine trying to manually track all of this for a large team, multiple teams, or even multiple business units. Lineage tracking and querying helps make this more manageable and helps organizations move to ML at scale. The following are four examples of how feature lineage helps scale the ML process:
- Build confidence for reuse of existing features – A data scientist may search for existing features, but won’t use them if they can’t easily identify the raw data sources, the transformations that have been performed, and who else is already using the features in other models.
- Avoid reinventing features that are based on the same raw data as existing features – Let’s say a data scientist is planning to build new features based on a specific data source. Feature lineage can help them easily find all the features that already depend on the same data source and are used by production models. Instead of building and maintaining yet another feature, they can find features to immediately reuse.
- Troubleshoot and audit models and model predictions – Incorrect predictions, or biased predictions, may occur in production, and teams need answers about how this happened. This troubleshooting may also occur as a result of a regulator looking for evidence of how models were built, including all the features driving the predictions.
- Manage features proactively – As more and more reusable features are made available in centralized feature stores, owners of specific features need to plan for the evolution of feature groups, and eventually even deprecation of old features. These feature owners need to understand what models are using their features in order to understand the impact and who they need to work with.
What relationships are important to track?
The following diagram shows a sample set of ML lifecycle steps, artifacts, and associations that are typically needed for model lineage when using a feature store.
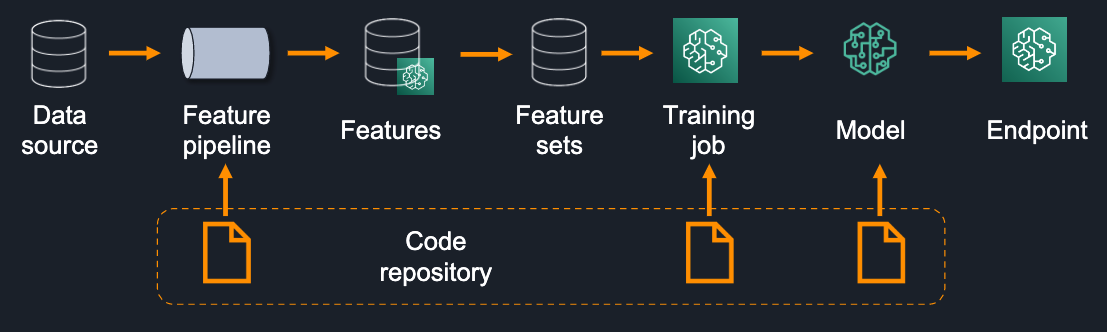
These components include the following:
- Data source – ML features depend on raw data sources like an operational data store, or a set of CSV files in Amazon Simple Storage Service (Amazon S3).
- Feature pipeline – Production-worthy features are typically built using a feature pipeline that takes a set of raw data sources, performs feature transformations, and ingests the resulting features into the feature store. Lineage tracking can help by associating those pipelines with their data sources and their target feature groups.
- Feature sets – When features are in a feature store, data scientists query it to retrieve data for model training and validation. You can use lineage tracking to associate the feature store query with the produced dataset. This provides granular detail into which features were used and what feature history was selected across multiple feature groups.
- Training job – As the ML lifecycle matures to adopt the use of a feature store, model lineage can associate training with specific features and feature groups.
- Model – In addition to relating models to hosting endpoints, you can link them to their corresponding training job, and indirectly to feature groups.
- Endpoint – Lastly, for online models, you can associate specific endpoints with the models they’re hosting, completing the end-to-end chain from data sources to endpoints providing predictions.
There is no “one size fits all” approach to an overall model pipeline. This is simply an example, and you can adapt it to cover how your teams operate to meet your specific lineage requirements. The underlying APIs are flexible enough to cover a broad range of approaches.
Create lineage tracking
Let’s walk through how to instrument your code to easily capture these associations. Our example uses a custom wrapper library we built around SageMaker ML Lineage Tracking. This library is a wrapper around the SageMaker SDK to support ease of lineage tracking across the ML lifecycle. Lineage artifacts include data, code, feature groups, features in a feature group, feature group queries, training jobs, and models.
First, we import the library:
Next, ideally you want your lineage to even track the code you used to process your data with SageMaker Processing jobs or code used to train your model in SageMaker. If this code is version controlled (which we highly recommend!), we can reconstruct what those URL links would be in your chosen git management platform like GitHub or GitLab:
Finally, we create the lineage. Many of the inputs are optional, but in this example, we assume the following:
- You started with a raw data source
- You used SageMaker Processing to process the raw data and ingest it into two different feature groups
- You queried the Feature Store to create training and test datasets
- You trained a model in SageMaker on your training and test datasets
The following screenshot shows our results.
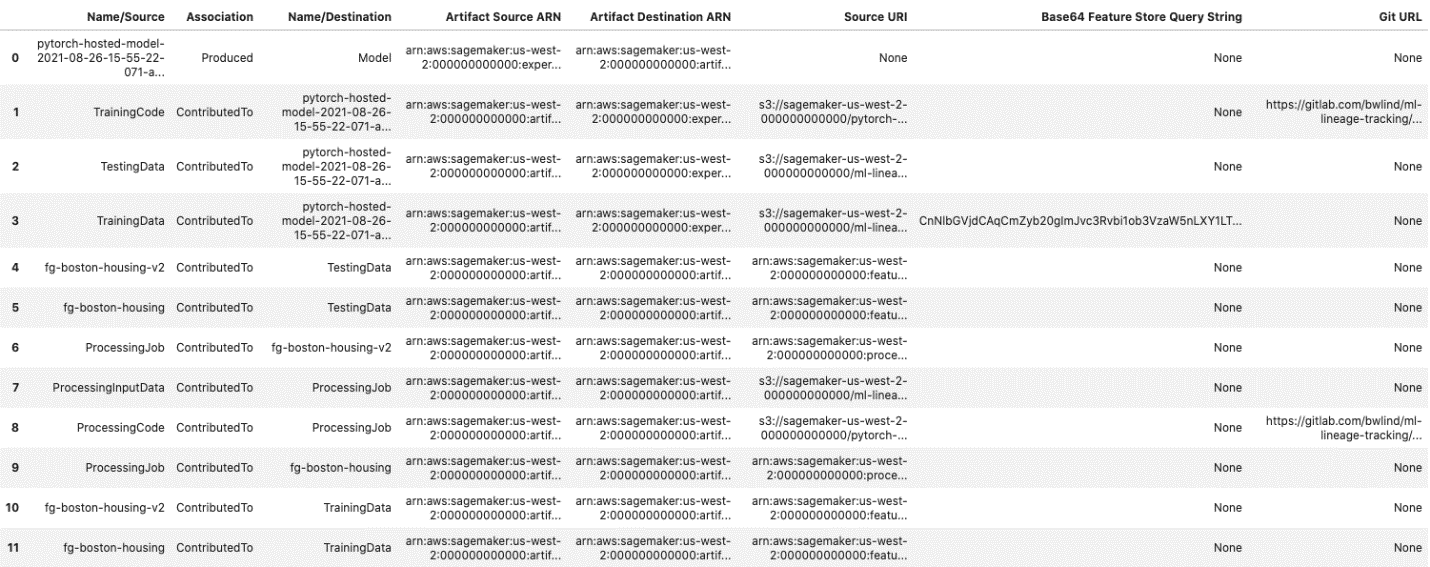
The call returns a pandas dataframe representing the lineage graph of artifacts that were created and associated on your behalf. It provides names, associations (such as Produced or ContributedTo), and ARNs that uniquely identify resources.
Now that the lineage is in place, you can use it to answer key questions about your features and models. Keep in mind that the full benefit of this lineage tracking comes when this practice is adopted across many data scientists working with large numbers of features and models.
Use lineage to answer key questions and gain insights
Let’s look at some examples of what you can do with the lineage data now that lineage tracking is in place.
As a data scientist, you might be planning to use a specific data source. To avoid reinventing features that are based on the same raw data as existing features, you want to look at all the features that have already been built and are in production using that same data source. A simple call can get you that insight:
The following screenshot shows our results.

Or maybe you’re considering using a specific feature group, and you want to know what data sources are associated with it:
We get the following results.

You might also need to audit a model or a set of model predictions. If incorrect predictions, or biased predictions, occurred in production, your team needs answers about how this happened. Given a model, you can query lineage to see all the steps used in the ML lifecycle to create the model:
We get the following results.
As more and more features are made available in a centralized feature store, owners of specific features need to plan for the evolution of feature groups, and eventually even deprecation of old features. These feature owners need to understand what models are using their features to understand the impact and who they need to work with. You can do this with the following code:
The following screenshot shows our results.

You can also reverse the question and find out which feature groups are associated with a given model:
Conclusion
In this post, we discussed the importance of tracking ML lineage, aspects of the ML lifecycle that you should track and add to the lineage, and how to use SageMaker to provide end-to-end ML lineage. We also covered how to incorporate Feature Store as you move towards reusable features across teams and models, and finally how to use the helper library to accomplish end-to-end ML lineage tracking. To try out Feature Store end to end lifecycle, including a module on lineage, you can explore this Feature Store Workshop and the notebooks for all the modules on GitHub. Also, you can extend this approach to cover your unique requirements. Visit the ML Lineage helper library we built, and try out the example notebook.
About the Authors
 Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
 Mohan Pasappulatti is a Senior Solutions Architect at AWS, based in San Francisco, USA. Mohan helps high profile disruptive startups and strategic customers architect and deploy distributed applications, including machine learning workloads in production on AWS. He has over 20 years of work experience in several roles like engineering leader, chief architect and principal engineer. In his spare time, Mohan loves to cheer his college football team (LSU Tigers!), play poker, ski, watch the financial markets, play volleyball and spend time outdoors.
Mohan Pasappulatti is a Senior Solutions Architect at AWS, based in San Francisco, USA. Mohan helps high profile disruptive startups and strategic customers architect and deploy distributed applications, including machine learning workloads in production on AWS. He has over 20 years of work experience in several roles like engineering leader, chief architect and principal engineer. In his spare time, Mohan loves to cheer his college football team (LSU Tigers!), play poker, ski, watch the financial markets, play volleyball and spend time outdoors.