Artificial Intelligence
Few-click segmentation mask labeling in Amazon SageMaker Ground Truth Plus
Amazon SageMaker Ground Truth Plus is a managed data labeling service that makes it easy to label data for machine learning (ML) applications. One common use case is semantic segmentation, which is a computer vision ML technique that involves assigning class labels to individual pixels in an image. For example, in video frames captured by a moving vehicle, class labels can include vehicles, pedestrians, roads, traffic signals, buildings, or backgrounds. It provides a high-precision understanding of the locations of different objects in the image and is often used to build perception systems for autonomous vehicles or robotics. To build an ML model for semantic segmentation, it is first necessary to label a large volume of data at the pixel level. This labeling process is complex. It requires skilled labelers and significant time—some images can take up to 2 hours or more to label accurately!
In 2019, we released an ML-powered interactive labeling tool called Auto-segment for Ground Truth that allows you to quickly and easily create high-quality segmentation masks. For more information, see Auto-Segmentation Tool. This feature works by allowing you to click the top-, left-, bottom-, and right-most “extreme points” on an object. An ML model running in the background will ingest this user input and return a high-quality segmentation mask that immediately renders in the Ground Truth labeling tool. However, this feature only allows you to place four clicks. In certain cases, the ML-generated mask may inadvertently miss certain portions of an image, such as around the object boundary where edges are indistinct or where color, saturation, or shadows blend into the surroundings.
Extreme point clicking with a flexible number of corrective clicks
We now have enhanced the tool to allow extra clicks of boundary points, which provides real-time feedback to the ML model. This allows you to create a more accurate segmentation mask. In the following example, the initial segmentation result isn’t accurate because of the weak boundaries near the shadow. Importantly, this tool operates in a mode that allows for real-time feedback—it doesn’t require you to specify all points at once. Instead, you can first make four mouse clicks, which will trigger the ML model to produce a segmentation mask. Then you can inspect this mask, locate any potential inaccuracies, and subsequently place additional clicks as appropriate to “nudge” the model into the correct result.

Our previous labeling tool allowed you to place exactly four mouse clicks (red dots). The initial segmentation result (shaded red area) isn’t accurate because of the weak boundaries near the shadow (bottom-left of red mask).
With our enhanced labeling tool, the user again first makes four mouse clicks (red dots in top figure). Then you have the opportunity to inspect the resulting segmentation mask (shaded red area in top figure). You can make additional mouse clicks (green dots in bottom figure) to cause the model to refine the mask (shaded red area in bottom figure).

Compared with the original version of the tool, the enhanced version provides an improved result when objects are deformable, non-convex, and vary in shape and appearance.
We simulated the performance of this improved tool on sample data by first running the baseline tool (with only four extreme clicks) to generate a segmentation mask and evaluated its mean Intersection over Union (mIoU), a common measure of accuracy for segmentation masks. Then we applied simulated corrective clicks and evaluated the improvement in mIoU after each simulated click. The following table summarizes these results. The first row shows the mIoU, and the second row shows the error (which is given by 100% minus the mIoU). With only five additional mouse clicks, we can reduce the error by 9% for this task!
| . | . | Number of Corrective Clicks | . | |||
| . | Baseline | 1 | 2 | 3 | 4 | 5 |
| mIoU | 72.72 | 76.56 | 77.62 | 78.89 | 80.57 | 81.73 |
| Error | 27% | 23% | 22% | 21% | 19% | 18% |
Integration with Ground Truth and performance profiling
To integrate this model with Ground Truth, we follow a standard architecture pattern as shown in the following diagram. First, we build the ML model into a Docker image and deploy it to Amazon Elastic Container Registry (Amazon ECR), a fully managed Docker container registry that makes it easy to store, share, and deploy container images. Using the SageMaker Inference Toolkit in building the Docker image allows us to easily use best practices for model serving and achieve low-latency inference. We then create an Amazon SageMaker real-time endpoint to host the model. We introduce an AWS Lambda function as a proxy in front of the SageMaker endpoint to offer various types of data transformation. Finally, we use Amazon API Gateway as a way of integrating with our front end, the Ground Truth labeling application, to provide secure authentication to our backend.
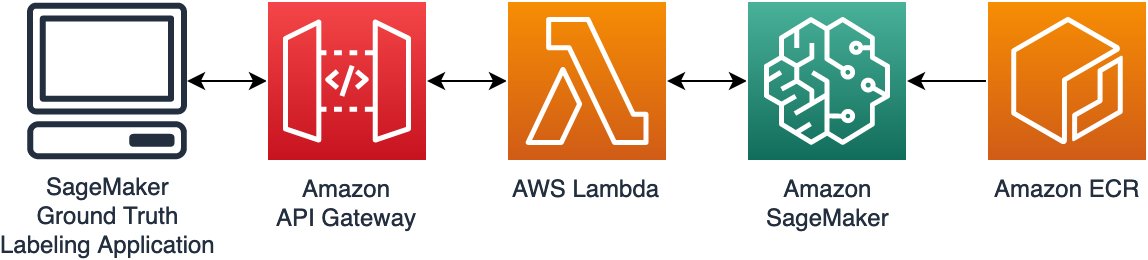
You can follow this generic pattern for your own use cases for purpose-built ML tools and to integrate them with custom Ground Truth task UIs. For more information, refer to Build a custom data labeling workflow with Amazon SageMaker Ground Truth.
After provisioning this architecture and deploying our model using the AWS Cloud Development Kit (AWS CDK), we evaluated the latency characteristics of our model with different SageMaker instance types. This is very straightforward to do because we use SageMaker real-time inference endpoints to serve our model. SageMaker real-time inference endpoints integrate seamlessly with Amazon CloudWatch and emit such metrics as memory utilization and model latency with no required setup (see SageMaker Endpoint Invocation Metrics for more details).
In the following figure, we show the ModelLatency metric natively emitted by SageMaker real-time inference endpoints. We can easily use various metric math functions in CloudWatch to show latency percentiles, such as p50 or p90 latency.
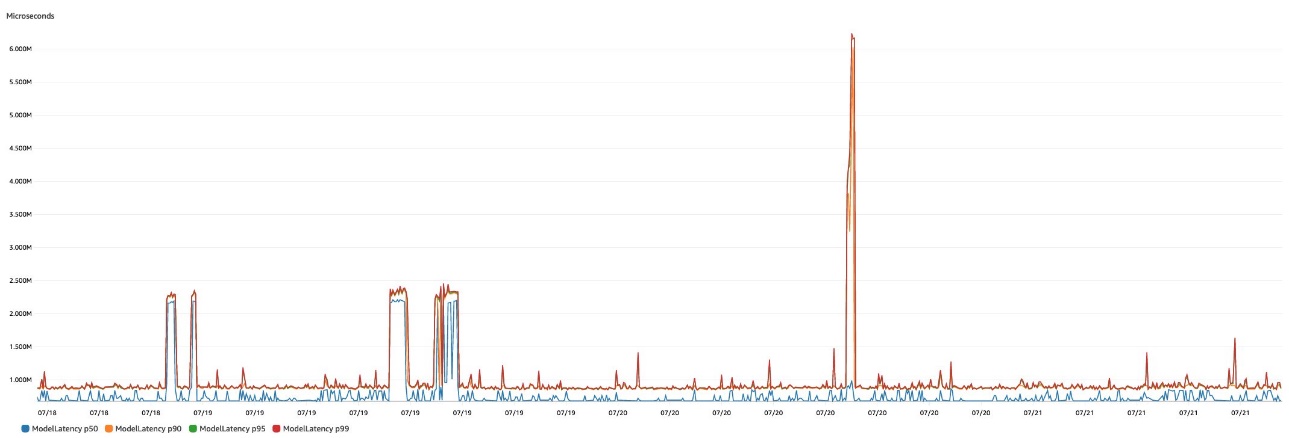
The following table summarizes these results for our enhanced extreme clicking tool for semantic segmentation for three instance types: p2.xlarge, p3.2xlarge, and g4dn.xlarge. Although the p3.2xlarge instance provides the lowest latency, the g4dn.xlarge instance provides the best cost-to-performance ratio. The g4dn.xlarge instance is only 8% slower (35 milliseconds) than the p3.2xlarge instance, but it is 81% less expensive on an hourly basis than the p3.2xlarge (see Amazon SageMaker Pricing for more details on SageMaker instance types and pricing).
| SageMaker Instance Type | p90 Latency (ms) | |
| 1 | p2.xlarge | 751 |
| 2 | p3.2xlarge | 424 |
| 3 | g4dn.xlarge | 459 |
Conclusion
In this post, we introduced an extension to the Ground Truth auto segment feature for semantic segmentation annotation tasks. Whereas the original version of the tool allows you to make exactly four mouse clicks, which triggers a model to provide a high-quality segmentation mask, the extension enables you to make corrective clicks and thereby update and guide the ML model to make better predictions. We also presented a basic architectural pattern that you can use to deploy and integrate interactive tools into Ground Truth labeling UIs. Finally, we summarized the model latency, and showed how the use of SageMaker real-time inference endpoints makes it easy to monitor model performance.
To learn more about how this tool can reduce labeling cost and increase accuracy, visit Amazon SageMaker Data Labeling to start a consultation today.
About the authors
 Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
Jonathan Buck is a Software Engineer at Amazon Web Services working at the intersection of machine learning and distributed systems. His work involves productionizing machine learning models and developing novel software applications powered by machine learning to put the latest capabilities in the hands of customers.
 Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.
Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon. His research interests are 3D deep learning, and vision and language representation learning. Previously he was a senior scientist at Alexa AI, the head of machine learning at Scale AI and the chief scientist at Pony.ai. Before that, he was with the perception team at Uber ATG and the machine learning platform team at Uber working on machine learning for autonomous driving, machine learning systems and strategic initiatives of AI. He started his career at Bell Labs and was adjunct professor at Columbia University. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized several workshops at NeurIPS, ICML, CVPR, ICCV on machine learning for autonomous driving, 3D vision and robotics, machine learning systems and adversarial machine learning. He has a PhD in computer science at Cornell University. He is an ACM Fellow and IEEE Fellow.