Artificial Intelligence
Auto-segmenting objects when performing semantic segmentation labeling with Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth helps you build highly accurate training datasets for machine learning (ML) quickly. Ground Truth offers easy access to third-party and your own human labelers and provides them with built-in workflows and interfaces for common labeling tasks. Additionally, Ground Truth can lower your labeling costs by up to 70% using automatic labeling, which works by training Ground Truth from data humans have labeled so that the service learns to label data independently.
Semantic segmentation is a computer vision ML technique that involves assigning class labels to individual pixels in an image. For example, in video frames captured by a moving vehicle, class labels can include vehicles, pedestrians, roads, traffic signals, buildings, or backgrounds. It provides a high-precision understanding of the locations of different objects in the image and is often used to build perception systems for autonomous vehicles or robotics. To build an ML model for semantic segmentation, it is first necessary to label a large volume of data at the pixel level. This labeling process is complex. It requires skilled labelers and significant time—some images can take up to two hours to label accurately.
To increase labeling throughput, improve accuracy, and mitigate labeler fatigue, Ground Truth added the auto-segment feature to the semantic segmentation labeling user interface. The auto-segment tool simplifies your task by automatically labeling areas of interest in an image with only minimal input. You can accept, undo, or correct the resulting output from auto-segment. The following screenshot highlights the auto-segmenting feature in your toolbar, and shows that it captured the dog in the image as an object. The label assigned to the dog is Bubbles.
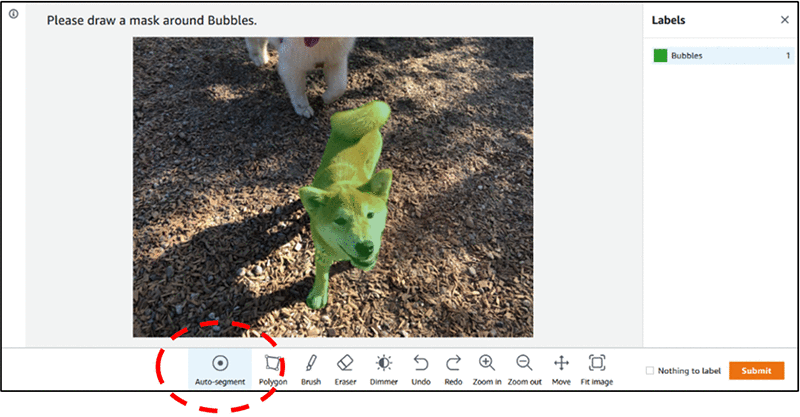
With this new feature, you can work up to ten times faster on semantic segmentation tasks. Instead of drawing a tightly fitting polygon or using the brush tool to capture an object in an image, you draw four points: one at the top-most, bottom-most, left-most, and right-most points of the object. Ground Truth takes these four points as input and uses the Deep Extreme Cut (DEXTR) algorithm to produce a tightly fitting mask around the object. The following demo shows how this tool speeds up the throughput for more complex labeling tasks (video plays at 5x real-time speed).
Conclusion
This post demonstrated the purpose and complexity of the computer vision ML technique called semantic segmentation. The auto-segment feature automates the segmentation of areas of interest in an image with minimal input from the labeler, and speeds up semantic segmentation labeling tasks.
As always, AWS welcomes feedback. Please submit any thoughts or questions in the comments.
About the authors
 Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms).
Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms).
 Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries.
Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries.