Artificial Intelligence
HawkEye 360 predicts vessel risk using the Deep Graph Library and Amazon Neptune
This post is co-written by Ian Avilez and Tim Pavlick from HawkEye 360.
HawkEye 360 is a commercial radio frequency (RF) constellation, data, and analytics provider. Their signals of interest include very high frequency (VHF) push-to-talk radios, maritime radar systems, Automatic Identification System (AIS) beacons, emergency beacons, and more. The signals of interest library will continue to grow over time.
Their Mission Space offering, which was released in February 2021, allows users to intuitively visualize RF signals and analytics. Through an intuitive interface, mission analysts can identify activity, understand trends, and improve maritime situational awareness by revealing unseen human behavior and illicit vessel activities such as smuggling, piracy, illegal fishing, and human trafficking.
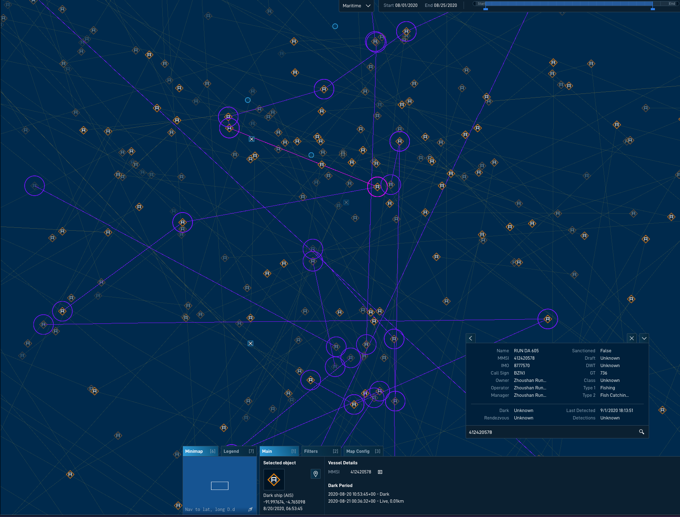
This post summarizes the collaborative effort between HawkEye 360 and the Amazon Machine Learning (ML) Solutions Lab to build machine learning (ML) capabilities into their analytical workflows. The collaboration involved two steps:
- Create an Amazon Neptune graph database consisting of all the vessels registered in the world to understand the relationship between vessels and to analyze how the vessels are related each other.
- Use the Deep Graph Library (DGL) to create a risk score for each vessel. This vessel risk is used to predict how likely a vessel is to do something suspicious by inferring risk through associations with other suspicious vessels.
Overview
Thousands of shipping vessels travel around the world every day. Finding the few bad actors can be time-consuming and challenging for analysts. Understanding how vessel networks operate is important to help analysts determine what kind of vessel behavior they’re seeing in their area. This data can help analysts inform their teams as to which questionable behaviors they can expect from vessels near them and find out if any vessels might be engaged in risky or nefarious activities. For example, if multiple vessels are in the area of operations, an analyst may want to know who those vessels have interacted with in the past. This information can be helpful to identify any indirect relationships among the vessels of interest. The existence of these relationships across the vessel network makes it a great use case for a graph database coupled with deep learning techniques to infer relationships. HawkEye 360 chose Neptune as their graph database to store relationship information and DGL for their graph neural network (GNN) capability.
HawkEye 360’s data contains the following information about vessels:
- Rendezvous between vessels gathering at sea
- Vessel information, including the ownership, management, and operating relationships
- Vessels that have disappeared from AIS for a significant amount of time
Using Neptune as the graph database
Neptune is a fast, reliable, fully managed graph database that is optimized for storing complex relationships and querying the graph with millisecond latency. HawkEye 360 used Amazon SageMaker Neptune notebooks, with its built-in graph notebook library, to process the dataset and create CSV datasets that were ready to be loaded into the Neptune cluster. For more information on Neptune data formats, see Load Data Formats. With the graph notebook Jupyter magic function %load, HawkEye 360 loaded the data into the Neptune cluster.
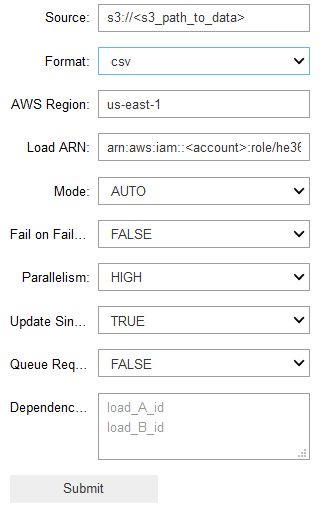
With the graph notebook library, HawkEye 360 was able to query the underlying graph data in Gremlin query language using the %%gremlin function. The following image is one example of a query that can be run.
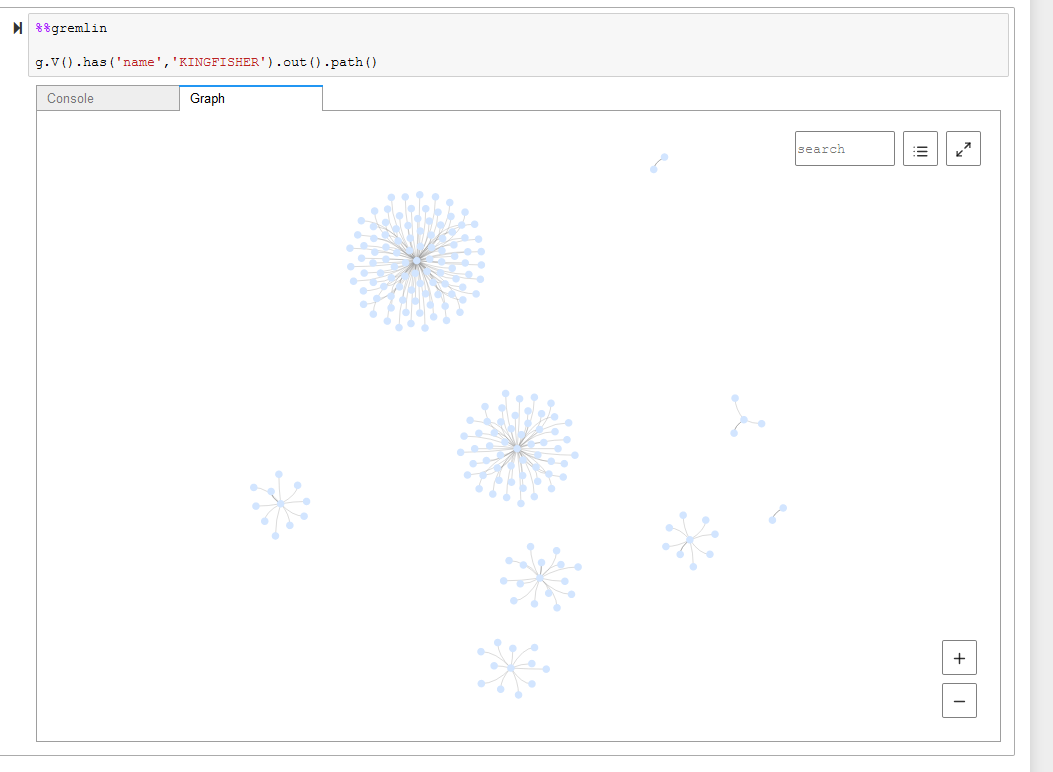
With Neptune, the HawkEye 360 team was able to immediately see hidden connections among vessels in the network. For example, typically analysts can only see vessels that interact with one another within the data. Graphs can take the analysis a step further by uncovering relationships between vessels that are three or more hops (or nodes) away from each other.
With the data in Neptune, HawkEye 360 created a per-vessel risk score to identify the risk that a given vessel will engage in suspicious behavior. This enables analysts to identify all risky vessels in the area of interest. A higher risk score in the area of interest points towards the vessel engaging in nefarious activities based on the relationships with other nefarious vessels.
Using the Deep Graph Library to predict vessel risk
The first step to predicting vessel risk is to create the graph dataset. The DGL expects the node ID data to be rank order data with integers starting from zero. The dataset uses three different types of nodes:
- Vessel nodes
- Owner company nodes
- Ship flag nodes
Because there are different node types, HawkEye 360 used a heterogeneous graph to accommodate mixed data types. They used relationships as edges to create the graph dataset using dgl.heterograph. The heterogeneous graph consisted of ground truth values for approximately 1% of the nodes. With these nodes, HawkEye 360 formulated a semi-supervised node classification problem to classify vessel risk. Semi-supervised learning consists of datasets with labeled and unlabeled data. The labeled data in the dataset is used for training the model, and the model predicts the labels for the unlabeled data.
Training a Relational Graph Convolutional Network model
Because the data is heterogeneous, HawkEye 360 chose to use a heterogeneous Relational Graph Convolutional Network (R-GCN) graph algorithm for model training. In an R-GCN algorithm, each edge type uses different weights and only edges of the same relation type r are associated with the same weight W_r. With the R-GCN algorithm, HawkEye 360 trained the model using ground truth values for a subset of the nodes to find and classify all the vessels with a risk score.
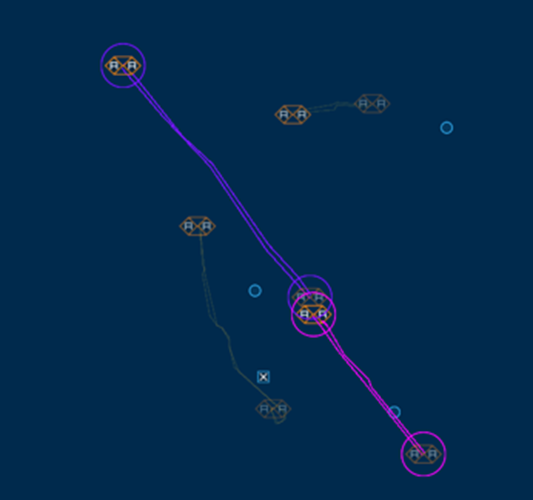
Using existing known vessel behavior to infer novel behavior from unknown vessels enables HawkEye 360 to create insights. Analysts can determine which vessels are more likely to engage in suspicious behavior simply by their association with known suspicious vessels.
Conclusion
The ML Solutions Lab and HawkEye 360 team worked closely to build the graph data in Neptune and model the data to find risks for nearby ships. The graph networks in Neptune and GNN models enable HawkEye 360 to reveal hidden relationships among vessels that would otherwise be lost in the vast sea of complexity. This enables HawkEye 360’s new flagship product, Mission Space, to identify which vessels have the potential to engage in suspicious activity and allows users to easily identify where to focus their attention and investigate further.
Today, customers can also use Amazon Neptune ML, which provides a streamlined way to create, train, and apply ML models on Neptune data in hours instead of weeks, without the need to learn new tools and ML technologies.
For more information about HawkEye 360’s Mission Space offering, see Mission Space. For more information about how AWS supports customers and partners in the satellite and aerospace industry, see AWS Aerospace and Satellite.
If you’d like assistance in accelerating the use of ML in your products and services, contact the Amazon ML Solutions Lab.
About the Authors
 Tim Pavlick, PhD, is VP of Product at HawkEye 360. He is responsible for the conception, creation, and productization of all HawkEye space innovations. Mission Space is HawkEye 360’s flagship product, incorporating all the data and analytics from the HawkEye portfolio into one intuitive RF experience. Dr. Pavlick’s prior invention contributions include Myca, IBM’s AI Career Coach, Grit PTSD monitor for Veterans, IBM Defense Operations Platform, Smarter Planet Intelligent Operations Center, AI detection of dangerous hate speech on the internet, and the STORES electronic food ordering system for the US military. Dr. Pavlick received his PhD in Cognitive Psychology from the University of Maryland College Park.
Tim Pavlick, PhD, is VP of Product at HawkEye 360. He is responsible for the conception, creation, and productization of all HawkEye space innovations. Mission Space is HawkEye 360’s flagship product, incorporating all the data and analytics from the HawkEye portfolio into one intuitive RF experience. Dr. Pavlick’s prior invention contributions include Myca, IBM’s AI Career Coach, Grit PTSD monitor for Veterans, IBM Defense Operations Platform, Smarter Planet Intelligent Operations Center, AI detection of dangerous hate speech on the internet, and the STORES electronic food ordering system for the US military. Dr. Pavlick received his PhD in Cognitive Psychology from the University of Maryland College Park.
 Ian Avilez is a Data Scientist with HawkEye 360. He works with customers to highlight the insights that can be gained by combining different datasets and looking at that data in various ways.
Ian Avilez is a Data Scientist with HawkEye 360. He works with customers to highlight the insights that can be gained by combining different datasets and looking at that data in various ways.
 Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
 Dan Ford is a Data Scientist at the Amazon ML Solution Lab, where he helps AWS National Security customers build state-of-the-art ML solutions.
Dan Ford is a Data Scientist at the Amazon ML Solution Lab, where he helps AWS National Security customers build state-of-the-art ML solutions.