Artificial Intelligence
How Beekeeper by LumApps optimized user personalization with Amazon Bedrock
This post is cowritten by Mike Koźmiński from Beekeeper.
Large Language Models (LLMs) are evolving rapidly, making it difficult for organizations to select the best model for each specific use case, optimize prompts for quality and cost, adapt to changing model capabilities, and personalize responses for different users.
Choosing the “right” LLM and prompt isn’t a one-time decision—it shifts as models, prices, and requirements change. System prompts are becoming larger (for example, Anthropic system prompt) and more complex. A lot of mid-sized companies don’t have resources to quickly evaluate and improve them. To address this issue, Beekeeper built an Amazon Bedrock-powered system that continuously evaluates model+prompt candidates, ranks them on a live leaderboard, and routes each request to the current best choice for that use case.
Beekeeper: Connecting and empowering the frontline workforce
Beekeeper by LumApps offers a comprehensive digital workplace system specifically designed for frontline workforce operations. The company provides a mobile-first communication and productivity solution that connects non-desk workers with each other and headquarters, enabling organizations to streamline operations, boost employee engagement, and manage tasks efficiently. Their system features robust integration capabilities with existing business systems (human resources, scheduling, payroll), while targeting industries with large deskless workforces such as hospitality, manufacturing, retail, healthcare, and transportation. At its core, Beekeeper addresses the traditional disconnect between frontline employees and their organizations by providing accessible digital tools that enhance communication, operational efficiency, and workforce retention, all delivered through a cloud-based SaaS system with mobile apps, administrative dashboards, and enterprise-grade security features.
Beekeeper’s solution: A dynamic evaluation system
Beekeeper solved this challenge with an automated system that continuously tests different model and prompt combinations, ranks options based on quality, cost, and speed, incorporates user feedback to personalize responses, and automatically routes requests to the current best option. Quality is scored with a small synthetic test set and validated in production with user feedback (thumbs up/down and comments). By incorporating prompt mutation, Beekeeper created an organic system that evolves over time. The result is a constantly-optimizing setup that balances quality, latency, and cost—and adapts automatically when the landscape changes.
Real-world example: Chat Summarization
Beekeeper’s Frontline Success Platform unifies communication for deskless workers across industries. One practical application of their LLM system is chat summarization. When a user returns to shift, they might find a chat with many unread messages – instead of reading everything, they can request a summary. The system generates a concise overview with action items tailored to the user’s needs. Users can then provide feedback to improve future summaries. This seemingly simple feature relies on sophisticated technology behind the scenes. The system must understand conversation context, identify important points, recognize action items, and present information concisely—all while adapting to user preferences.

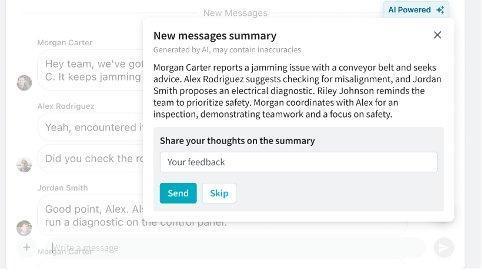
Solution overview
Beekeeper’s solution consists of two main phases: building a baseline leaderboard and personalizing with user feedback.
The system uses several AWS components, including Amazon EventBridge for scheduling, Amazon Elastic Kubernetes Service (EKS) for orchestration, AWS Lambda for evaluation functions, Amazon Relational Database Service (RDS) for data storage, and Amazon Mechanical Turk for manual validation.
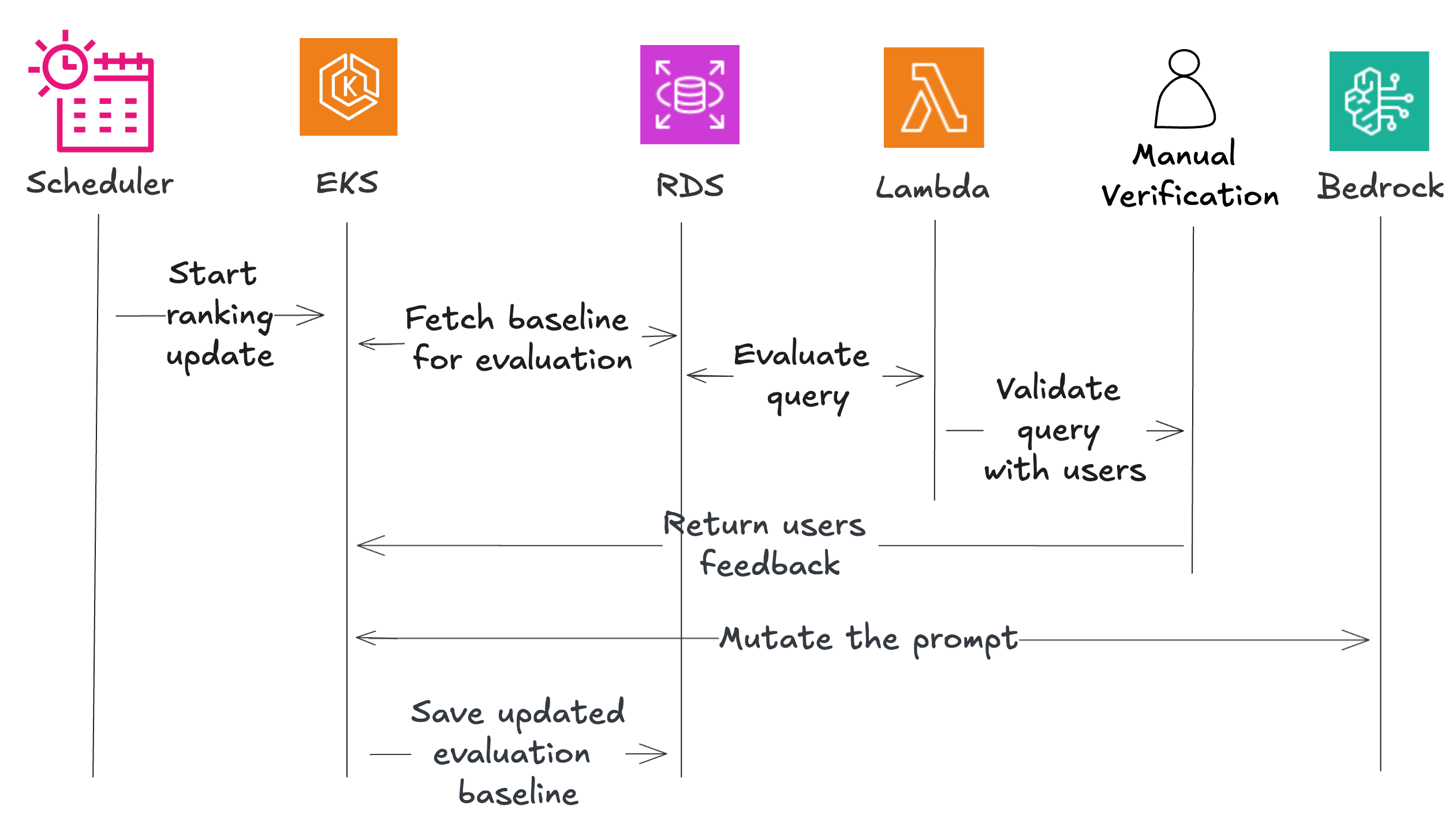
The workflow begins with a synthetic rank creator that establishes baseline performance. A scheduler triggers the coordinator, which fetches test data and sends it to evaluators. These evaluators test each model/prompt pair and return results, with a portion sent for manual validation. The system mutates promising prompts to create variations, evaluates these again, and saves the best performers. When user feedback arrives, the system incorporates it through a second phase. The coordinator fetches ranked model/prompt pairs and sends them with user feedback to a mutator, which returns personalized prompts. A drift detector makes sure these personalized versions don’t stray too far from quality standards, and validated prompts are saved for specific users.
Building the baseline leaderboard
To kick-start the optimization journey, Beekeeper engineers selected various models and provided them with domain-specific human-written prompts. The tech team tested these prompts using LLM-generated examples to make sure they were error-free. A solid baseline is crucial here. This foundation helps them refine their approach when incorporating feedback from real users.
The following sections, we dive into their success metrics, which guides their refinement of prompts and helps create an optimal user experience.
Evaluation criteria for baseline
The quality of summaries generated by model/prompt pairs is measured using both quantitative and qualitative metrics, including the following:
- Compression ratio – Measures summary length relative to the original text, rewarding adherence to target lengths and penalizing excessive length.
- Presence of action items – Makes sure user-specific action items are clearly identified.
- Lack of hallucinations – Validates factual accuracy and consistency.
- Vector comparison – Assesses semantic similarity to human-generated perfect results.
In the following sections, we walk through each of the evaluation criteria and how they are implemented.
Compression ratio
The compression ratio evaluates the length of the summarized text compared to the original one and its adherence to a target length (it rewards compression ratios close to the target and penalizes texts that deviate from target length). The corresponding score, between 0 and 100, is computed programmatically with the following Python code:
Presence of action items related to the user
To check whether the summary contains all the action items related to the users, Beekeeper relies on the comparison to the ground truth. For the ground truth comparison, the expected output format requires a section labeled “Action items:” followed by bullet points, which uses regular expressions to extract the action item list as in the following Python code:
They include this additional extraction step to make sure the data is formatted in a way that the LLM can easily process. The extracted list is sent to an LLM with the request to check whether it’s correct or not. A +1 score is assigned for each action item correctly assigned, and a -1 is used in case of false positive. After that, scores are normalized to not penalize/gratify summaries with more or less action items.
Lack of hallucinations
To evaluate hallucinations, Beekeeper uses two approaches: cross-LLM evaluation and manual validation.

In the cross-LLM evaluation, a summary created by LLM A (for example, Mistral Large) is passed to the evaluator component, together with the prompt and the initial input. The evaluator submits this text to LLM B (for example, Anthropic’s Claude), asking if the facts from the summary match the raw context. An LLM of a different family is used for this evaluation. Amazon Bedrock makes this exercise particularly simple through the Converse API—users can select different LLMs by changing the model identifier string.
Another important point is the presence of manual verification on a small set of evaluations at Beekeeper, to avoid cases of double hallucination. They assign a score of 1 if no hallucination was detected and -1 if any is detected. For the whole pipeline, they use the same heuristic of 7% manual evaluation (details discussed further along in this post).
Vector comparison
As an additional evaluation method, semantic similarity is used for data with available ground truth information. The embedding models are chosen among the MTEB Leaderboard (multi-task and multi-language comparison of embedding models), considering large vector dimensionality to maximize the amount of information stored inside the vector. Beekeeper uses as its baseline Qwen3, a model providing a 4096 dimensionality and supporting 16-bit quantization for fast computation. Further embedding models are also used directly from Amazon Bedrock. After computing the embedding vectors for both the ground truth answer and the one generated by a given model/prompt pair, cosine similarity is used to compute the similarity, as shown in the following Python code:
Evaluation baseline
The evaluation baseline of each model/prompt pair is performed by collecting the generated output of a set of fixed, predefined queries that are manually annotated with ground truth outputs containing the “true answers” (in this case, the ideal summaries from in-house and public dataset). This set as mentioned before is created from a public dataset as well as hand crafted examples better representing a customer’s domain. The scores are evaluated automatically based on the metrics described earlier: compression, lack of hallucinations, presence of action items, and vector comparison, to build a baseline version of the leaderboard.
Manual evaluations
For additional validation, Beekeeper manually reviews a scientifically determined sample of evaluations using Amazon Mechanical Turk. This sample size is calculated using Cochran’s formula to support statistical significance.
Amazon Mechanical Turk enables businesses to harness human intelligence for tasks computers can’t perform effectively. This crowdsourcing marketplace connects users with a global, on-demand workforce to complete microtasks like data labeling, content moderation, and research validation—helping to scale operations without sacrificing quality or increasing overhead. As mentioned earlier, Beekeeper employs human feedback to verify that the automatic LLM-based rating system is working correctly. Based on their prior assumptions, they know what percentage of responses should be classified as containing hallucinations. If the number detected by human verification diverges by more than two percentage points from their estimations, they know that the automated process isn’t working properly and needs revision. Now that Beekeeper has established their baseline, they can provide the best results to their customers. By constantly updating their models, they can bring new value in an automated fashion. Whenever their engineers have ideas for new prompt optimization, they can let the pipeline evaluate it against previous ones using baseline results. Beekeeper can take it further and embed user feedback, allowing for more customizable results. However, they don’t want user feedback to fully change the behavior of their model through prompt injection in feedback. In the following section, we examine the organic part of Beekeeper’s pipeline that embeds user preferences into responses without affecting other users.
Evaluation of user feedback
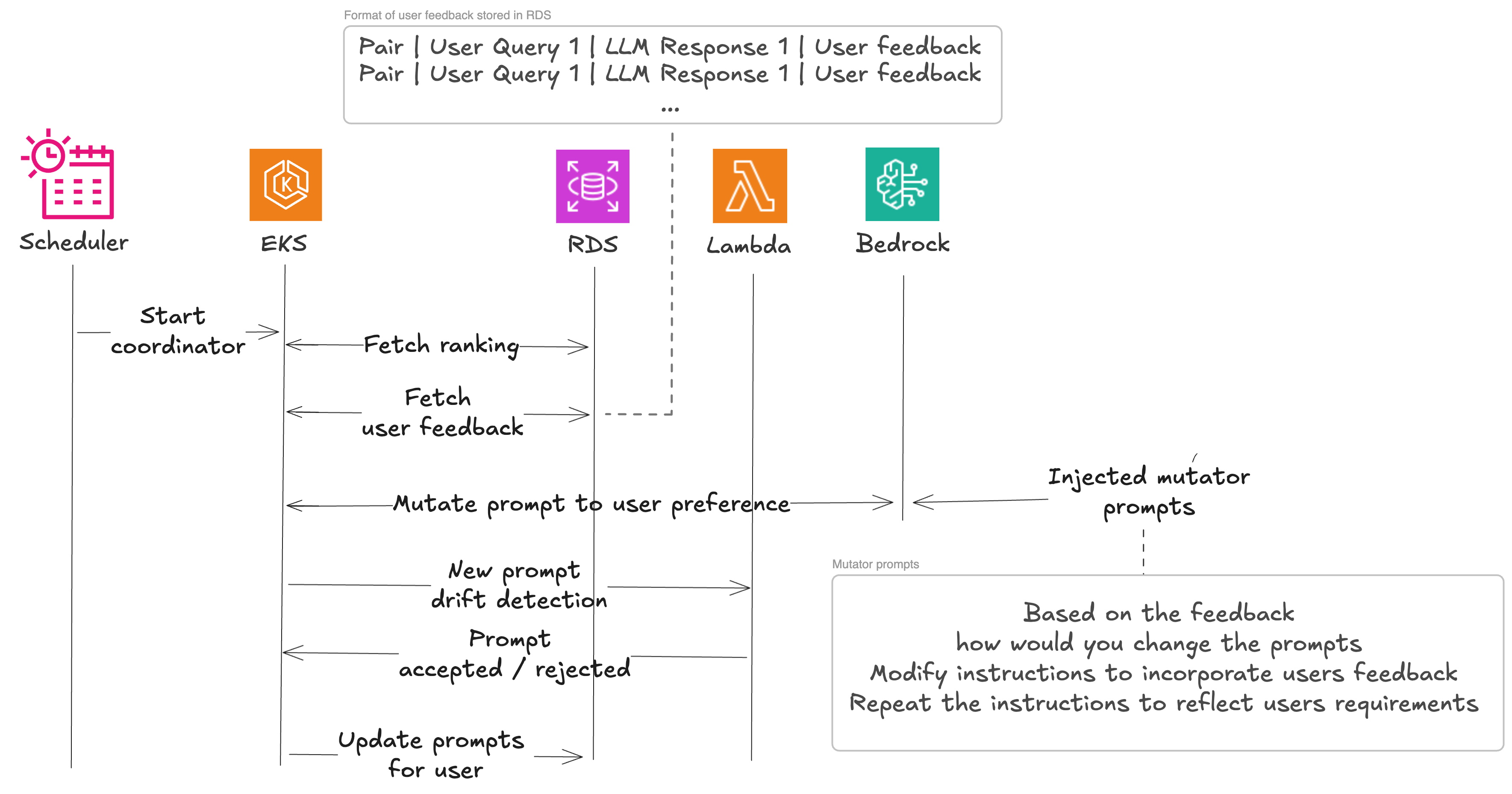
Now that Beekeeper has established their baseline using ground truth set, they can start incorporating human feedback. This works according to the same principles as the previously described hallucination detection process. User feedback is pulled together with input and LLM response. They pass questions to the LLM in the following format:
They use this to check whether the feedback provided is still applicable after the prompt-model pair was updated. This works as a baseline for incorporating user feedback. They are now ready to start mutating the prompt. This is done to avoid feedback being applied multiple times. If model change or mutation already solved the problem, there is no need to apply it again.
The mutation process consists of reevaluating the user generated dataset after prompt mutation until the output incorporates the user feedback, then we use the baseline to understand differences and discard changes in case they undermine model work.
The four best-performing model/prompt pairs chosen in the baseline evaluation (for mutated prompts) are further processed through a prompt mutation process, to check for residual improvement of the results. This is essential in an environment where even small modifications to a prompt can lead to dramatically different results when used in conjunction with user feedback.
The initial prompt is enriched with a prompt mutation, the received user feedback, a thinking style (a specific cognitive approach like “Make it creative” or “Think in steps” that guides how the LLM approaches the mutation task), the user context, and is sent to the LLM to produce a mutated prompt. The mutated prompts are added to the list, evaluated, and the corresponding scores are incorporated into the leaderboard. Mutation prompts can also include users feedback when such is present.
Examples of generated mutations prompts include:
Solution example
The baseline evaluation process starts with eight pairs of prompts and associated models (Amazon Nova, Anthropic Claude 4 Sonnet, Meta Llama 3, and Mistral 8x7B). Beekeeper usually uses four base prompts and two models to start with. These prompts are used across all the models, but results are considered in pairs of prompt-models. Models are automatically updated as newer versions become available via Amazon Bedrock.
Beekeeper starts by evaluating the eight existing pairs:
- Each evaluation requires generating 20 summaries per pair (8 x 20 = 160)
- Each summary is checked by three static checks and two LLM checks (160 x 2 = 320)
In total, this creates 480 LLM calls. Scores are compared, creating a leaderboard, and two prompt-model pairs are selected. These two prompts are mutated using user feedback, creating 10 new prompts, which are again evaluated, creating 600 calls to the LLM (10 x 20 + 10 x 20 x 2 = 600).
This process can be run n times to perform more creative mutations; Beekeeper usually performs two cycles.
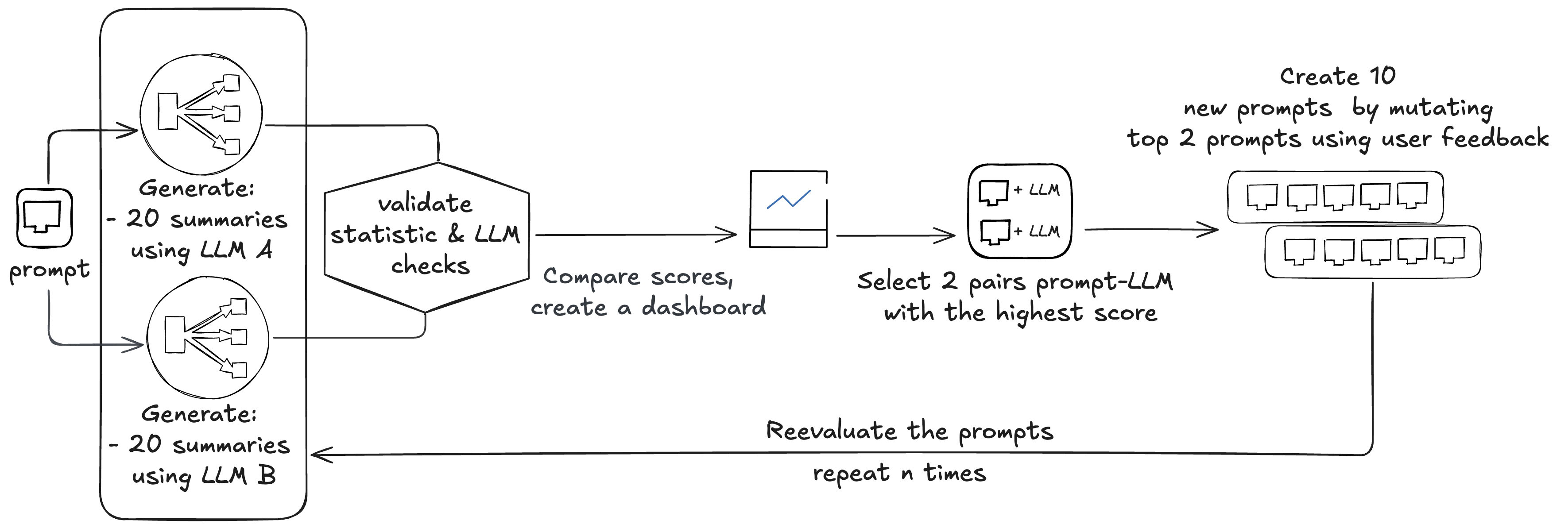
In total, this exercise performs tests on (8 + 10 + 10) x 2 model/prompt pairs. The whole process on average requires around 8,352,000 input tokens and around 1,620,000 output tokens, costing around $48.Newly selected model/prompt pairs are used in production with ratios 1st: 50%, 2nd: 30%, and 3rd: 20%.After deploying the new model/prompt pairs, Beekeeper gathers feedback from the users. This feedback is used to feed the mutator to create three new prompts. These prompts are sent for drift detection, which compares them to the baseline. In total, they create four LLM calls, costing around 4,800 input tokens and 500 output tokens.
Benefits
The key benefit of Beekeeper’s solution is its ability to rapidly evolve and adapt to user needs. With this approach, they can make initial estimations of which model/prompt pairs would be optimal candidates for each task, while controlling both cost and the quality of results. By combining the benefits of synthetic data with user feedback, the solution is suitable even for smaller engineering teams. Instead of focusing on generic prompts, Beekeeper prioritizes tailoring the prompt improvement process to meet the unique needs of each tenant. By doing so, they can refine prompts to be highly relevant and user-friendly. This approach allows users to develop their own style, which in turn enhances their experience as they provide feedback and see its impact. One of the side effects they observed is that certain groups of people prefer different styles of communication. By mapping these results to customer interactions, they aim to present a more tailored experience. This makes sure that feedback given by one user doesn’t impact another. Their preliminary results suggest 13–24% better ratings on response when aggregated per tenant. In summary, the proposed solution offers several notable benefits. It reduces manual labor by automating the LLM and prompt selection process, shortens the feedback cycle, enables the creation of user- or tenant-specific improvements, and provides the capacity to seamlessly integrate and estimate the performance of new models in the same manner as the previous ones.
Conclusion
Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models. By continuously evaluating and optimizing quality, size, speed, and cost, the solution helps customers use the best-performing model/prompt combinations for their specific use cases. Looking ahead, Beekeeper plans to further refine and expand the capabilities of this system, incorporating more advanced techniques for prompt engineering and evaluation. Additionally, the team is exploring ways to empower users to develop their own customized prompts, fostering a more personalized and engaging experience. If your organization is exploring ways to optimize LLM selection and prompt engineering, there’s no need to start from scratch. Using AWS services like Amazon Bedrock for model access, AWS Lambda for lightweight evaluation, Amazon EKS for orchestration, and Amazon Mechanical Turk for human validation, a pipeline can be built that automatically evaluates, ranks, and evolves your prompts. Instead of manually updating prompts or re-benchmarking models, focus on creating a feedback-driven system that continuously improves results for your users. Start with a small set of models and prompts, define your evaluation metrics, and let the system scale as new models and use cases emerge.
About the authors
 Mike (Michał) Koźmiński is a Zürich-based Principal Engineer at Beekeeper by LumApps, where he builds the foundations that make AI a first-class part of the product. With 10+ years spanning startups and enterprises, he focuses on translating new technology into reliable systems and real customer impact.
Mike (Michał) Koźmiński is a Zürich-based Principal Engineer at Beekeeper by LumApps, where he builds the foundations that make AI a first-class part of the product. With 10+ years spanning startups and enterprises, he focuses on translating new technology into reliable systems and real customer impact.
 Magdalena Gargas is a Solutions Architect passionate about technology and solving customer challenges. At AWS, she works mostly with software companies, helping them innovate in the cloud.
Magdalena Gargas is a Solutions Architect passionate about technology and solving customer challenges. At AWS, she works mostly with software companies, helping them innovate in the cloud.
 Luca Perrozzi is a Solutions Architect at Amazon Web Services (AWS), based in Switzerland. He focuses on innovation topics at AWS, especially in the area of Artificial Intelligence. Luca holds a PhD in particle physics and has 15 years of hands-on experience as a research scientist and software engineer.
Luca Perrozzi is a Solutions Architect at Amazon Web Services (AWS), based in Switzerland. He focuses on innovation topics at AWS, especially in the area of Artificial Intelligence. Luca holds a PhD in particle physics and has 15 years of hands-on experience as a research scientist and software engineer.
 Simone Pomata is a Principal Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day.
Simone Pomata is a Principal Solutions Architect at AWS. He has worked enthusiastically in the tech industry for more than 10 years. At AWS, he helps customers succeed in building new technologies every day.