Artificial Intelligence
How TourRadar automates the translation process using Amazon EventBridge and Amazon Translate
This is a guest post written by Gergely Kadi, Senior Systems Engineer and Martin Petraschek-Stummer, Senior Data Engineer at TourRadar.
TourRadar is a travel marketplace to connect people to life-enriching travel experiences.
When it was launched, TourRadar only offered tours and content in English. As the company grew, we saw an opportunity to expand our offering to non-English speaking customers. This was our first content translation effort, and we knew that manual translations wouldn’t be a viable option in terms of cost and time to market. The ease of use, extensive capabilities, and simple integration with other AWS services and Weblate, our translation management solution, were the critical aspects that led us to choose Amazon Translate as our preferred machine translation service.
The initial proof of concept was successfully run within a few hours and we were ready to go live within a few weeks with German language translations. With Amazon Translate and Amazon EventBridge, we will be able to scale into new markets at a much faster pace and help us achieve a truly global reach.
Overview of the solution
The following diagram illustrates our solution architecture.

When the content of our tours gets created or updated, a process takes notice of that particular change on the database level and sends an event to a custom event bus on EventBridge. A separate process, the translation Lambda function, implemented using AWS Lambda, gets invoked by EventBridge with the event payload. This Lambda function then either calls Amazon Translate to translate the content, or use cached data from our Translation Memory stored in Amazon DynamoDB. Finally, it stores the newly translated content in Amazon RDS, after it goes through a quality assurance process (QA Tool).
Communication between microservices can be difficult if there is no middleware between them and they call each other directly. Error handling is one such example. With the growing number of services, the number of connections can grow exponentially. A solution for that is to decouple systems with a mechanism that takes care of carrying information from one service to another. This makes the system asynchronous, decoupled, independent, scalable, and more manageable.
We already use Amazon Simple Queue Service (Amazon SQS) and Amazon Simple Notification Service (Amazon SNS) for new microservices, but with a concrete use case in the web application, we came to a point where we wanted to explore the possibilities of a fully event-driven architecture. Most of our data still sits in our main database. Multiple apps are writing to it, therefore there is no single owner of the data at this moment. This implies that we couldn’t easily or reliably generate events at the application layer, but it would be easier to push the event generation lower to the database level.
Once there is a new tour inserted in the TourRadar database, or the content of an existing one gets updated, either via importer or our operator dashboard, we have to translate the new content. Because the volume of new and updated data can be high, we have to be careful with the involved cost of the solution. For example, if there are only tiny changes made to the tour (which aren’t relevant), we shouldn’t translate the data again. We have two options for change detection to keep costs low:
- In the target system, we keep a copy of all data, and when we receive an event, we compare the payload of the event to the local storage to determine whether we have to perform translation
- For the event payload, we not only attach the new record, but also include the old version of the data, so the target system can decide without additional lookup if relevant data changed
We chose the second approach so we can avoid having copies of primary data in each microservice.
According to our database statistics, we have tens of millions of events per month for the tables. This gives us an indication of how many events we might have per month, and therefore a forecast for the cost for the infrastructure.
Although we explored many options, we identified three options that didn’t work for us:
- First, we explored application-level event generation. This solution would have been a good practice, but because there is no single owner for the tour data, it would require massive refactoring, which would be costly.
- The second option was database triggers and Lambda. This solution would access the old record, but didn’t scale well, and incurred significant costs related to database operations.
- Third, we explored Debezium, an open-source distributed platform for change data capture (CDC). It can also ship the old record but requires a Kafka cluster to run, which wasn’t an ideal option for us.
We chose ZongJI for CDC capture. With some optimizations (how many events are processed in parallel), we made it possible to run it on the smallest Amazon Elastic Container Service (Amazon ECS) container size: 0.256 CPU and 0.512 memory, which costs less than $10/month to capture all events. So, it’s very cost-efficient.
For event delivery, we chose EventBridge.
The following code shows the integration to EventBridge in Node.js:
We generate EventBridge events using a generic CDC, as shown in the following diagram.
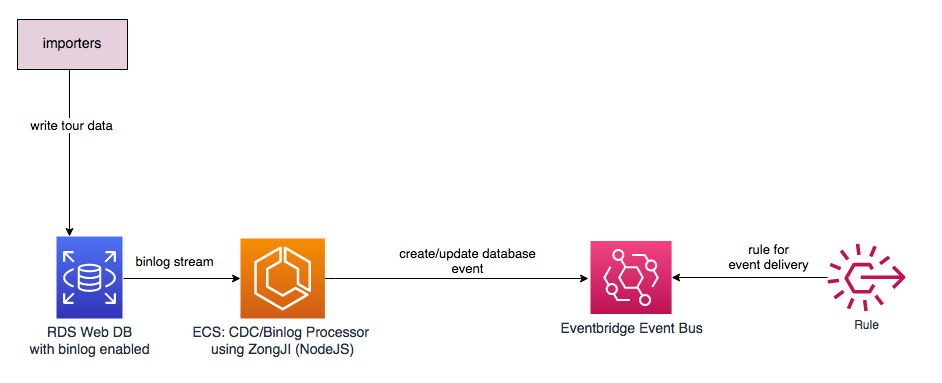
Translation workflow
At this point, we can create EventBridge events whenever data is changed in the database.
As a first use case, we implement a Lambda function that automatically machine translates textual data right after it is written to the database.
For machine translation, we use Amazon Translate, which is a neural machine translation service that allows you to do translations using simple API calls.
Database layout
Any database table that contains translatable content is split into two tables:
- One table that contains non-translatable data
- One table that contains language-dependent data

The column with translatable content (name) is removed from the base table (tours) and added to the new tours_translations table. tours_translations.tour_id is a foreign key into tours.id. For each tour_id, there can be various translations into other languages, which are distinguished by locale_id.
We decided to store translations not per language, but per locale (a combination of language and country). This gives us the flexibility to handle translations separately, for example American English vs. British English or Castilian Spanish vs. Latin American Spanish.
We use the concept of a translation status to specify whether a specific database entry holds original content (status 1), machine translated content (status 2), or if the content has already been QAed by a human (status 3).
Translation Lambda function
Whenever a database entry gets changed, the CDC process generates an event that looks like the following:
An EventBridge rule triggers the translation Lambda function, which does the following:
- Checks if the translation status is “
original”, because we only translate original content. Otherwise, processing stops here. - Based on the table name specified in
detail.metadata, it reads the translation configuration. - The translation configuration specifies which column names need to be translated. If there is no change for this specific column (comparing
data.oldandand.newvalues), the processing stops here. - The function then iterates over all languages that are configured as target languages and calls an external translation service (Amazon Translate, in our case). The resulting translations are written back into the database. Because we’re using the generic database table layout we described, this process is the same for all tables in our database.
- As a last step, the function creates another event that is consumed by a separate QA tool, where a human can correct any machine translation errors.
Data that is written back into the database is always marked with translation status “machine translated”. This is important, because the write operation to the database triggers another CDC event, and we have to make sure that this event doesn’t trigger another write operation within the Lambda function, because this would produce an endless loop of write operations.
Translation memory using DynamoDB
Looking at the data that gets translated, we realized that we have some scenarios where the same strings get translated over and over from different sources. To save costs for machine translation, we decided to introduce a storage layer for historic translations. This translation memory is a simple DynamoDB table. Before the translation Lambda function makes a call to Amazon Translate, it consults the translation memory to check if there is already an entry for the given source string and source or target locale. If yes, this translation is used. If not, Amazon Translate is called and the response is stored in the translation memory.
The key for the translation memory is a concatenation of the following strings:
A data object behind this key might look like the following code:
The is_approved flag is set to True after a human has checked and potentially corrected the machine translated entry via our internal QA tool.
If we want to scope certain translations to a specific area, we can set a translation_scope, which is empty by default.
Conclusion
In this post, we shared how TourRadar built a scalable solution to serve non-English-speaking customers and expand the addressable market size. We demonstrated how we built a solution using an event-driven architecture where, when a content is updated, we machine translate only the data that changed and implement a QA tool where the machine translation is reviewed by a human to ensure translation quality. To learn more about what Amazon Translate can do for your business, visit the webpage.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Author
Gergely Kadi is a Senior Systems Engineer at TourRadar. Gergely joined TourRadar way back when the company had a single EC2 instance running the entire platform and helped the company expand to a full microservice architecture deployed across multiple regions. Gergely has a deep understanding of cloud architecture design and operations and holds a key role in designing, building and maintaining the overall TourRadar platform
Martin Petraschek-Stummer is a Senior Data Engineer at TourRadar. Martin joined TourRadar as the first data engineer building the entire company capabilities from scratch. Martin was responsible for the solution design and implementation of the entire ETL architecture leveraging AWS Glue and Amazon Redshift, which now holds data from 80+ different sources, internal and external. Martin has a deep understanding of data in general and specifically in a cloud context and plays a vital role on solution design for all company data needs.