Artificial Intelligence
Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart
Today, we announce that large language models Bloom and GPT-2 are available in SageMaker JumpStart. Amazon SageMaker JumpStart is the machine learning hub of SageMaker that provides hundreds of built-in algorithms, pre-trained models, and end-to-end solution templates to help customers quickly get started with machine learning (ML). You can use these models for a wide range of applications such as generating stories, summarizing long-form text, translating between multiple languages, information extraction, and much more. They can be applied even when there are only a few available training examples, or even none at all.
In this post, we provide an overview of how to deploy and run inference with Bloom and GPT-2 models in two ways: via JumpStart’s graphical interface on Amazon SageMaker Studio, and programmatically through JumpStart APIs, available in the SageMaker Python SDK.
Text generation, GPT-2, Bloom, and Prompting
Text generation is the task of generating text that is fluent and appears indistinguishable from human-written text. It is also known as natural language generation.
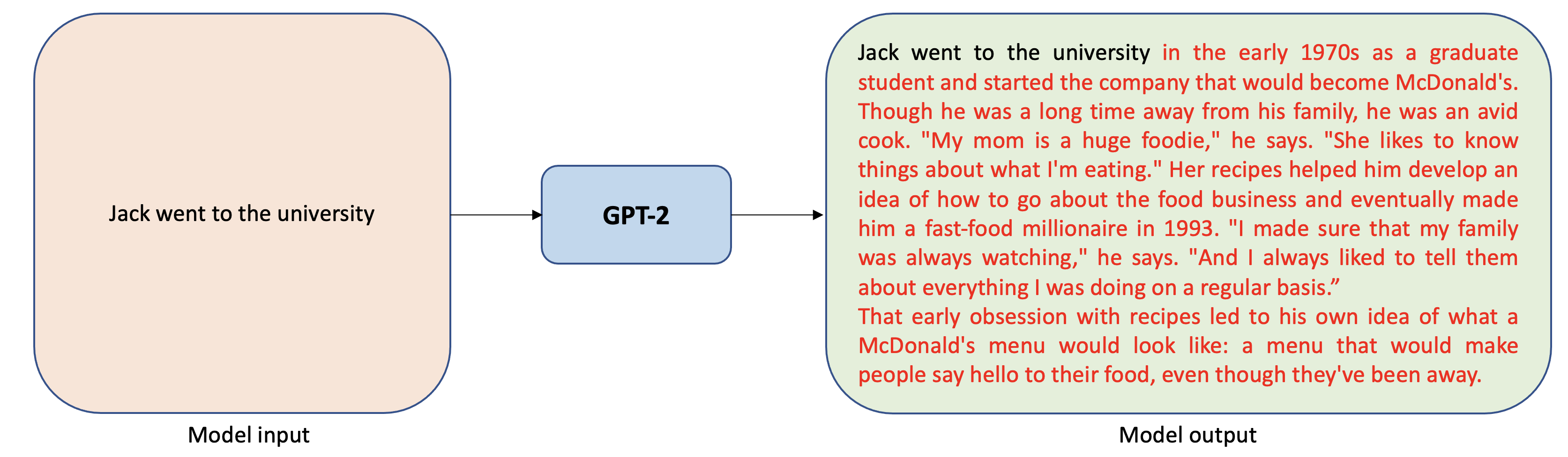
GPT-2 is a popular transformer-based text generation model. It is pre-trained on a large corpus of raw English text with no human labeling. Given a partial sequence (a sentence or a piece of text) during training, the model predicts the next token (such as a word or letter) in the sequence. GPT-2 can be used to generate long stories from a small input text as demonstrated in the figure below:
Bloom is also a transformer-based text generation model and is trained similarly to GPT-2. However, Bloom is pre-trained on 46 different languages and 13 programming languages. The following is an example of running text generation with the Bloom model:

Even though the models are pre-trained for text generation, they can be applied to other tasks such as translation or keyword extraction via prompting. Prompting refers to a method of formulating a task as a text generation task by embedding the problem description in the input along with any available training samples. The following figure shows an example of formulating a translation task as a text generation task when we have two training samples available:

The following figure shows an example of prompting when the task is to extract the important keywords from a paragraph.
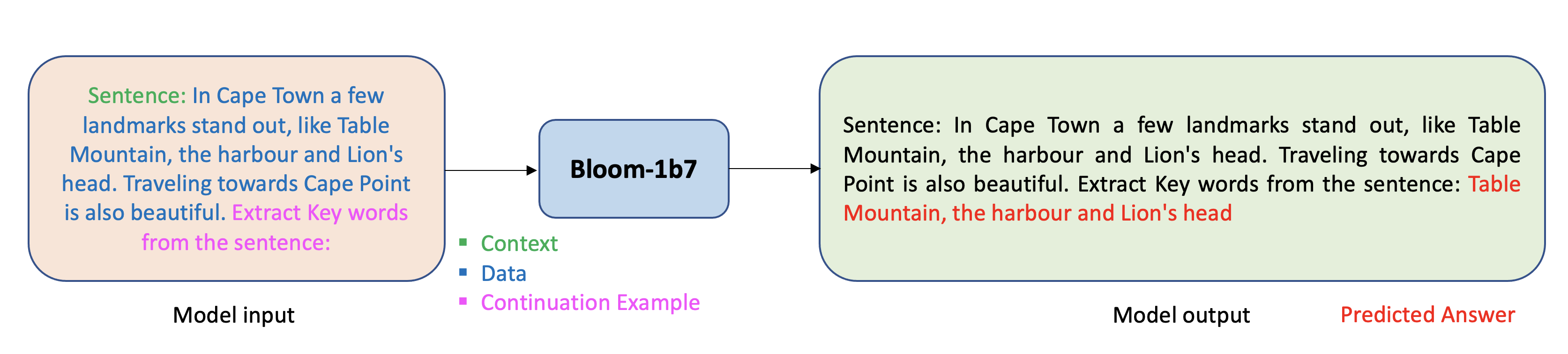
Prompt engineering can sometimes be an art and small changes in the prompt template can significantly impact the model’s performance. Promptsource and Natural Instructions are two open-source frameworks for standardizing prompt templates, and they provide a variety of example prompts used for existing modeling tasks.
By using the Bloom model, you agree to the BigScience RAIL License v1.0 license.
Solution overview
To use a large language model in SageMaker, you need inference script and create end-to-end tests for scripts, models, and the desired instance types to validate that all three can work together. JumpStart simplifies this process by providing ready-to-use scripts that have been robustly tested. You can access these scripts with one-click through the Amazon SageMaker Studio UI or with very few lines of code through the JumpStart APIs.
The following sections provide an overview of how to deploy the model and run inference using either the Studio UI or the JumpStart APIs:
- Access JumpStart through the SageMaker Studio to deploy and run inference on the pre-trained model.
- Use JumpStart programmatically with the SageMaker Python SDK to deploy the pre-trained model and run inference.
Access JumpStart through the Studio UI and run inference with a pre-trained model
In this section, we demonstrate how to train and deploy JumpStart models through the Studio UI.
The following video shows you how to find a pre-trained text generation model on JumpStart and deploy it. The model page contains valuable information about the model and how to use it. You can deploy any of the pre-trained models available in JumpStart. For inference, we pick the ml.p3.2xlarge instance type, because it provides the GPU acceleration needed for low inference latency at a low price point. After you configure the SageMaker hosting instance, choose Deploy. It may take 20–25 minutes until your persistent endpoint is up and running.
Once your endpoint is operational, it’s ready to respond to inference requests!
To accelerate your time to inference, JumpStart provides a sample notebook that shows you how to run inference on your freshly deployed endpoint. Choose Open Notebook under Use Endpoint from Studio.
Use JumpStart programmatically with the SageMaker SDK
You can use the SageMaker JumpStart UI to deploy a pre-trained model interactively in just a few clicks. However, you can also use JumpStart models programmatically by using APIs that are integrated into the SageMaker Python SDK.
In this section, we choose an appropriate pre-trained model in JumpStart, deploy this model to a SageMaker endpoint, and run inference on the deployed endpoint all using the SageMaker Python SDK. The following examples contain code snippets. For the full code with all of the steps in this demo, see the Introduction to JumpStart – Text Generation example notebook.
Deploy the pre-trained model
SageMaker is a platform that makes extensive use of Docker containers for build and runtime tasks. JumpStart uses the available framework-specific SageMaker Deep Learning Containers (DLCs). We first fetch any additional packages, as well as scripts to handle training and inference for the selected task. Finally, the pre-trained model artifacts are separately fetched with model_uris, which provides flexibility to the platform. You can use any number of models pre-trained on the same task with a single inference script. See the following code:
Bloom is a very large model and can take up to 20–25 minutes to deploy. You can also use a smaller model such as GPT-2. To deploy a pre-trained GPT-2 model, you can set model_id = huggingface-textgeneration-gpt2. For a list of other available models in JumpStart, refer to JumpStart Available Model Table.
Next, we feed the resources into a SageMaker model instance and deploy an endpoint:
After our model is deployed, we can get predictions from it in real time!
Run inference
The following code snippet gives you a glimpse of what the outputs look like. To send requests to a deployed model, we use a JSON dictionary encoded in UTF-8 format.
The endpoint response is a JSON object containing a list with input text followed by the generated texts.
Our output is as follows:
Text generation models supports 10 text generation parameters during inference: max_length, num_return_sequences, num_beams, no_repeat_ngram_size, temperature, early_stopping, do_sample, top_k, top_p, and seed. For detailed information on valid values for each parameter and their impact on the output, see the accompanying notebook: Introduction to JumpStart – Text Generation
Conclusion
In this post, we showed how to deploy a pre-trained text generation model using JumpStart. You can accomplish this without needing to write code. Try out the solution on your own and send us your comments.
JumpStart overview
JumpStart helps you get started with ML models for a variety of tasks without writing a single line of code. Currently, JumpStart enables you to do the following:
- Deploy pre-trained models for common ML tasks – JumpStart enables you to address common ML tasks with no development effort by providing easy deployment of models pre-trained on large, publicly available datasets. The ML research community has put a large amount of effort into making a majority of recently developed models publicly available for use. JumpStart hosts a collection of over 300 models, spanning the 15 most popular ML tasks such as object detection, text classification, and text generation, making it easy for beginners to use them. These models are drawn from popular model hubs such as TensorFlow, PyTorch, Hugging Face, and MXNet.
- Fine-tune pre-trained models – JumpStart allows you to fine-tune pre-trained models without needing to write your own training algorithm. In ML, the ability to transfer the knowledge learned in one domain to another domain is called transfer learning. You can use transfer learning to produce accurate models on your smaller datasets, with much lower training costs than the ones involved in training the original model. JumpStart also includes popular training algorithms based on LightGBM, CatBoost, XGBoost, and Scikit-learn, which you can train from scratch for tabular regression and classification.
- Use pre-built solutions – JumpStart provides a set of 17 solutions for common ML use cases, such as demand forecasting and industrial and financial applications, which you can deploy with just a few clicks. Solutions are end-to-end ML applications that string together various AWS services to solve a particular business use case. They use AWS CloudFormation templates and reference architectures for quick deployment, which means they’re fully customizable.
- Refer to notebook examples for SageMaker algorithms – SageMaker provides a suite of built-in algorithms to help data scientists and ML practitioners get started with training and deploying ML models quickly. JumpStart provides sample notebooks that you can use to quickly use these algorithms.
- Review training videos and blogs – JumpStart also provides numerous blog posts and videos that teach you how to use different functionalities within SageMaker.
JumpStart accepts custom VPC settings and AWS Key Management Service (AWS KMS) encryption keys, so you can use the available models and solutions securely within your enterprise environment. You can pass your security settings to JumpStart within Studio or through the SageMaker Python SDK.
- Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart
- AlexaTM 20B is now available in Amazon SageMaker JumpStart
- Run image segmentation with Amazon SageMaker JumpStart
- Run text classification with Amazon SageMaker JumpStart using TensorFlow Hub and Hugging Face models
- Amazon SageMaker JumpStart models and algorithms now available via API
- Incremental training with Amazon SageMaker JumpStart
- Transfer learning for TensorFlow object detection models in Amazon SageMaker
- Transfer learning for TensorFlow text classification models in Amazon SageMaker
- Transfer learning for TensorFlow image classification models in Amazon SageMaker
About the Authors
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Santosh Kulkarni is an Enterprise Solutions Architect at Amazon Web Services who works with sports customers in Australia. He is passionate about building large-scale distributed applications to solve business problems using his knowledge in AI/ML, big data, and software development.
Santosh Kulkarni is an Enterprise Solutions Architect at Amazon Web Services who works with sports customers in Australia. He is passionate about building large-scale distributed applications to solve business problems using his knowledge in AI/ML, big data, and software development.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana Champaign. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.