Artificial Intelligence
TC Energy builds an intelligent document processing workflow to process over 20 million images with Amazon AI
This is a guest post authored by Paul Ngo, US Gas Technical and Operational Services Data Team Lead at TC Energy.
TC Energy operates a network of pipelines, including 57,900 miles of natural gas and 3,000 miles of oil and liquid pipelines, throughout North America. TC Energy enables a stable network of natural gas and crude oil pipelines with safety, integrity, collaboration, and responsibility top of mind. TC Energy’s natural gas pipeline supplies more than 25% of the clean-burning natural gas consumed daily across North America to heat homes, fuel industries, and generate power.
To ensure the maintenance and safety requirements for the US natural gas system, a significant focus is spent on data collection, analysis, and management. With an aging pipeline system coupled with a growing repository of electronic records, any opportunity to leverage technology can reduce cost in performing re-work associated with not being able to locate these high-value records.
In this post, we share how TC Energy built an intelligent document processing workflow using Amazon AI services.
Pressure test records
One example high-value record, identified through the customized intelligent document processing workflow, is a pressure test record. Pressure test records are important for pipeline safety, maintenance, and regulatory compliance. These documents, now totaling over 2.2 million physical pages (and counting) of text and diagrams, present a challenge to both label and discover when needed. Although the key pressure test data remains the same, over the years the documentation formats, ownership, and pressure charts have changed many times, including both typed and handwritten documentation and imagery from as early as the 1900s.
Within the US Integrity & Data team, Paul Ngo learned that manually searching and reviewing these electronic records for pressure test or design pressure records is both time-consuming and introduces missed opportunities in locating high-value records. Incorporating technology through innovation with machine learning (ML) has proven a more enhanced way to search for these types of records quickly as such we wanted to use ML to meet our directive to “leave no stone unturned.”
The solution
To address these challenges, Dallas Kinzel, Delivery Lead within the IS Canadian Innovation team, turned to fully managed ML. The solution is built around Amazon Rekognition Custom Labels, a feature of Amazon Rekognition with AutoML capabilities that classifies images with custom labels , and Amazon Textract, an AI service that easily extracts text (including handwriting or written) and data from virtually any document.
Collectively, our US Business Unit and IS Innovation teams worked together to develop an intelligent document processing workflow in stages. First, the team built a document classifier with Amazon Rekognition Custom Labels (training on 111 distinct document types). Second, they processed classified documents with Amazon Textract, and used DetectText to make sense of scribbled handwriting and numbers.
The following diagram illustrates the solution architecture (click on the image for an expanded view).
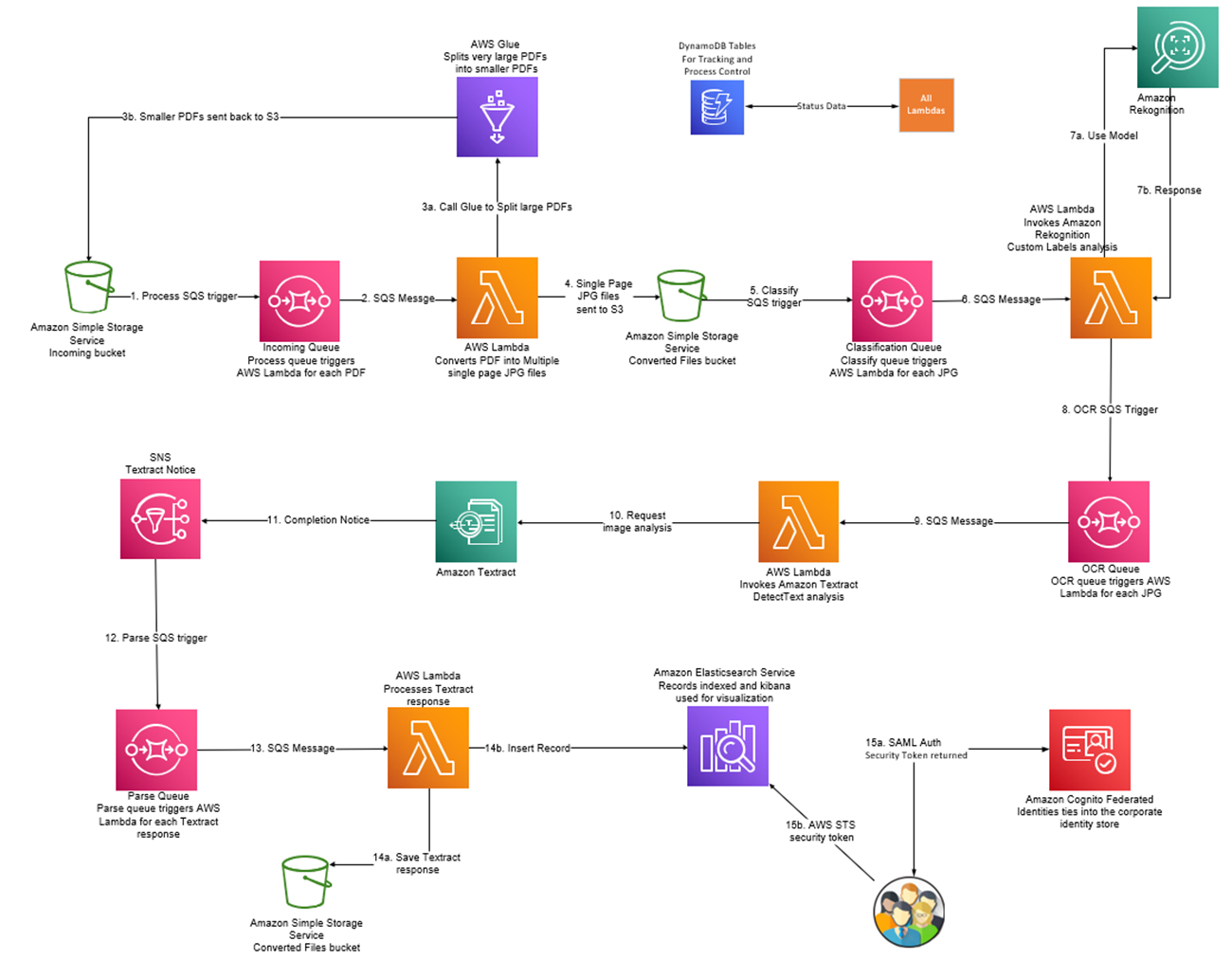
Using Amazon Rekognition Custom Labels to create a document classifier was simple and easy. First, the team gathered less than 100 samples to train a custom model, yielding an initial 96% F-Score accuracy rate. Think of F-Score as a measure of how accurately the system is classifying documents. With further improvements to the model, the F-Score improved to 98%. The team was able to achieve this high level of accuracy in a fraction of the time as opposed to if they had they built their own computer vision model from scratch.
Conclusion
What’s next? This system is still in its early stages, and we have more exciting things in store! As a continuation of the work led by Duane Patton, the IS Product team continues to enhance the existing solution by adding new custom labels to the document classifier and increasing the accuracy of classification by utilizing the combined results of Amazon Rekognition and Amazon Textract. We have plans to add other features to the solution, including serverless compute for automatic document processing with AWS Lambda. Amazon DynamoDB, for processing status recording, is also on the roadmap to make the new TC Energy computer vision solution even more efficient and accurate.
Contact sales or visit the product pages to learn more about how Amazon Rekognition and Amazon Textract can help your business.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
 Paul Ngo has a BSc in Computer Science and is the US Gas Technical and Operational Services Data Team Lead at TC Energy. He has over 15 years experience at TC Energy and has experience in data analytics and repeatable sustainable reporting. He has a passion for innovation and leveraging technology to improve productivity.
Paul Ngo has a BSc in Computer Science and is the US Gas Technical and Operational Services Data Team Lead at TC Energy. He has over 15 years experience at TC Energy and has experience in data analytics and repeatable sustainable reporting. He has a passion for innovation and leveraging technology to improve productivity.