Artificial Intelligence
Train fraudulent payment detection with Amazon SageMaker
The ability to detect fraudulent card payments is becoming increasingly important as the world moves towards a cashless society. For decades, banks have relied on building complex mathematical models to predict whether a given card payment transaction is likely to be fraudulent or not. These models must be both accurate and precise—they must catch fraudulent activity when it occurs, but must not incorrectly predict fraud for valid transactions. Such false positives can cause embarrassing customer experiences.
These mathematical models for detecting fraud are developed using machine learning (ML) algorithms. Data scientists provide large samples of both valid and fraudulent transaction data to an algorithm. The algorithm learns from the data how to train mathematical models that can accurately predict whether future transactions with similar features are fraudulent or not.
Businesses can use Amazon Fraud Detector to detect online payment fraud. This fully managed service from AWS uses ML models developed from Amazon’s over 20 years of experience in detecting fraud. Large financial institutions, however, typically rely on running their own proprietary algorithms developed in-house to train their own models. But training these mathematical models requires significant compute resources and massive amounts of data. It requires iterative processing of massive datasets. As fraud patterns become more sophisticated, the compute resources needed to keep up with these patterns continues to evolve.
Fortunately, the emergence of cloud computing makes the training and deployment of ML models easier and more cost-efficient. In this post, we show how AWS Cloud services like Amazon Simple Storage Service (Amazon S3) and Amazon SageMaker can help banks and financial institutions train mathematical models in the cloud for detecting card payment fraud with an approach that is more agile and cost-efficient. It’s more agile because the cloud enables banks to spin up powerful compute resources and elastic data storage on demand that meet changing and specific requirements. It’s more cost-efficient because it allows banks to operate on an Opex (versus Capex) model where they pay only for compute and storage resources that they consume.
Typical ML workflow for fraud detection
The following diagram shows the typical workflow for building and deploying models for detecting credit card payment fraud.

Banks ingest real-time credit card transaction data from point of sale (POS) systems. Banks initially do not know whether a given transaction is fraudulent or not as it comes in. Fraudulent transactions can only be confirmed after the fact – usually days or weeks, when the customer finally notices the transaction posted to their account. The customer then notifies their card-issuing bank and disputes the fraudulent credit card charges. The bank proceeds with fraud claims processing and investigation, and labels the transaction as fraudulent if it is in fact confirmed as fraudulent.
Banks periodically submit a batch of real customer transaction data that has been labeled to an ML algorithm. The algorithm uses this labeled data to learn patterns (fraud vs. not fraud) and uses learned patterns to predict whether future transactions are fraudulent. Banks typically do this on a regular schedule to keep the model up to date with the latest fraud patterns.
The challenge of this workflow is that large banks ingest massive amounts of transaction data on a daily basis, which drives the increasing need for more and more data storage. With more data comes the need for even more powerful compute resources that can process the massive datasets for training jobs.
Expensive compute infrastructure can also become obsolete in shorter cycles as hardware vendors continually roll out faster and more advanced chips and servers. Fortunately, AWS offers cloud computing services that can make the training and deployment of custom ML models much more agile and cost-effective.
Overview of solution
The following diagram shows how to use AWS services to deploy an agile solution for detecting fraudulent card payment.
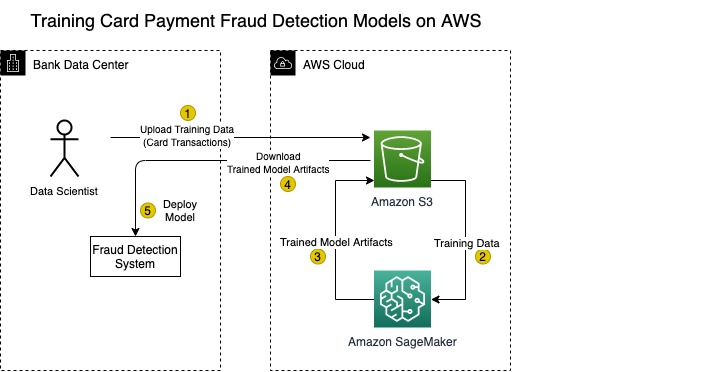
The solution uses two foundational AWS services: Amazon S3 and Amazon SageMaker.
Amazon S3
Amazon S3 provides low-cost, highly reliable, secure, and scalable storage for training data. It’s ideal for large banks that need to ingest and store massive volumes of card transaction data needed to run ML training jobs. Because Amazon S3 is a fully managed service, AWS takes care of backing up your data and making sure it’s highly durable.
Banks of course could store data this data in their own on-premises storage devices. But scalability becomes a challenge. The amount of required storage only increases, forcing banks into a perpetual cycle of purchasing expensive storage hardware that not only incurs more financial costs, but more physical space as well. With Amazon S3, banks can store a seemingly infinite amount of unstructured data and pay for only the amount of storage used. There is no requirement to forecast future storage requirements and pay up front.
With Amazon S3, you can upload batches of labeled data into the cloud on a daily, weekly, or monthly basis over a secure TLS connection. To provide security, Amazon S3 can encrypt the data at rest and restrict access to only specified users and ML workloads.
Amazon SageMaker
After labeled card transcation data is uploaded to Amazon S3, SageMaker can run ML algorithms to process the data and train a model for detecting fraudulent transactions. SageMaker is a platform for helping data scientists prepare, build, train, and deploy ML models. The platform consists of over a dozen services designed to help with a specific phase of the ML workflow.
Central to SageMaker is SageMaker Studio. Studio is a fully integrated development environment for ML. It provides a single web interface from which you can manage and implement all of your ML steps. Studio hosts and provides Jupyter notebook instances that are easy to share. From these notebooks, you can load and run over 200 example ML notebooks that are provided by SageMaker. These example notebooks include built-in common ML algorithms that you can use to train your models on SageMaker.
Bring your own algorithm: SageMaker Script Mode
Banks typically prefer to develop their own custom algorithms that better fit their specific data and use cases. SageMaker also provides data scientists the option to run your own custom ML algorithms with SageMaker Script Mode. In Script Mode, SageMaker provides optimized Docker containers for popular open-source frameworks such as TensorFlow, PyTorch, MXNet, XGBoost, and SciKit. The following diagram illustrates the workflow of SageMaker Script Mode.

ML developers can develop their own Python scripts running their own algorithms and then run these scripts on containers managed by SageMaker. These SageMaker containers run on Amazon Elastic Compute Cloud (Amazon EC2) instances. The beauty of the cloud is that you can select from a wide array of EC2 instance types and pay for only what you use. SageMaker manages the underlying compute infrastructure. For high-end ML jobs that require high-performance computing, consider selecting the EC2 P3 instance type with its 8 NVIDIA® V100 Tensor Core GPUs.
After SageMaker completes a training job, it has created a trained model that is ready to be deployed. SageMaker automatically shuts down the compute instances to make sure that costs are incurred only for compute resources actually used for the training job.
Deploy the model on premises
You can deploy the newly created model in AWS to provide real-time inferences on credit card transactions. However, to minimize network latency, banks may choose to download and deploy the model on their own premises. Deploying the model on premises also removes the risk of any network disruption to the cloud.
The newly trained model is outputted in the form of a model artifact. Model artifacts are saved to Amazon S3 as a .zip file. Model artifacts consist of parameters, definitions, and other metadata for the ML model. You can download the model artifact from Amazon S3 and build an inference executable based on the model artifact. You can then deploy this inference executable on a web service to provide batch or real-time monitoring of card transactions. The model deployment process is summarized in the following diagram.
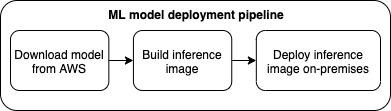
You can repeat this process of building and training in the cloud and then deploying the model on premises as newer training data with more sophisticated fraud patterns becomes available. For a step-by-step tutorial on SageMaker Script Mode, check out Bring your own model with Amazon SageMaker script mode and Bring Your Own Custom ML Models with Amazon SageMaker.
Conclusion
In this post, we showed how Amazon S3 and SageMaker Studio can help banks and financial institutions train custom mathematical models in the cloud for detecting card payment fraud with an approach that is agile and cost-efficient. After you train the model in the AWS Cloud, you can deploy it on premises for fast, resilient performance. Banks that use this approach can focus on building custom ML models that take advantage of the latest and most advanced compute resources offered from the AWS Cloud.
Learn more about how you can get started with SageMaker today!
About the Authors
 Michael Nguyen is a Senior Solutions Architect at AWS, helping startups and fintechs build innovative solutions. His areas of focus include AI/ML and the financial services industry. Prior to AWS he worked for over 20 years as a lead architect in the banking industry specializing in payment card services. Michael is 13x AWS Certified and holds a B.S. in Electrical Engineering from Penn State University, M.S. in Electrical Engineering from Binghamton University, and an MBA from the University of Delaware.
Michael Nguyen is a Senior Solutions Architect at AWS, helping startups and fintechs build innovative solutions. His areas of focus include AI/ML and the financial services industry. Prior to AWS he worked for over 20 years as a lead architect in the banking industry specializing in payment card services. Michael is 13x AWS Certified and holds a B.S. in Electrical Engineering from Penn State University, M.S. in Electrical Engineering from Binghamton University, and an MBA from the University of Delaware.
 Nolan Chen is a Solutions Architect at AWS, where he helps customers build innovative and cost-efficient solutions using the cloud. Prior to AWS, Nolan specialized in data security and helping customers deploy high performing wide area networks. In his spare time, Nolan enjoys reading history books while thinking about what the future might hold.
Nolan Chen is a Solutions Architect at AWS, where he helps customers build innovative and cost-efficient solutions using the cloud. Prior to AWS, Nolan specialized in data security and helping customers deploy high performing wide area networks. In his spare time, Nolan enjoys reading history books while thinking about what the future might hold.