AWS Public Sector Blog
How MPAC accelerates IT support resolution using generative AI on AWS

MPAC, Ontario’s property assessment expert managing 5.7 million properties, faced mounting pressure on their IT support desk. Routine requests consumed most of the support team’s resources, creating bottlenecks and impacting organization-wide productivity. MPAC needed a round-the-clock IT support solution that maintained stringent security and governance standards for a public sector organization.
MPAC’s IT Support Assistant—powered by their custom MPAC Orchestrator platform and Amazon Bedrock on Amazon Web Services (AWS)—revolutionized its IT support, resulting in:
- More than 4,500 support requests handled autonomously in the first 3 months
- Over 83.5% autonomous resolution rate for routine IT inquiries
- An average response time of 3.6 seconds for employee queries
- Over 96% reduction in operating costs through serverless architecture
- Round-the-clock availability, eliminating wait times for common support issues
Solution overview
MPAC developed a custom AI-powered IT Support Assistant using the MPAC Orchestrator platform built on AWS serverless services and Amazon Bedrock. This solution transforms routine support interactions into instant, intelligent responses while providing control, compliance, and cost-effectiveness.
The architecture consists of four key layers:
- User interface layer – Drag-and-drop interface for creating and managing AI workflows
- Orchestration layer – Serverless framework built on Amazon API Gateway and AWS Lambda that abstracts model management, prompt templating, data retrieval, and security behind a single API and UI
- AI/ML layer – Amazon Bedrock foundation models (FMs) with vector database integration
- Data layer – Amazon Relational Database (Amazon RDS) for metadata, Amazon Simple Storage Service (Amazon S3) for document storage, Amazon Elastic Kubernetes Service (Amazon EKS) for vector databases
The following diagram shows the solution architecture.
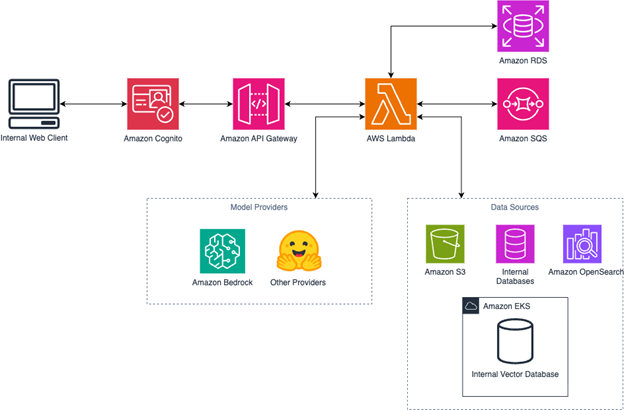
Figure 1. Reference serverless solutions architecture showing how the platform connects users to generative AI models while integrating with existing enterprise data infrastructure.
Solution deep dive: MPAC Orchestrator
To streamline development and enforce enterprise-grade guardrails, MPAC created the MPAC Orchestrator, a serverless framework that abstracts model management, prompt templating, data retrieval, and security behind a single API and UI. The service runs on Amazon API Gateway and AWS Lambda, stores metadata in Amazon RDS, and integrates natively with Amazon Bedrock as well as internally hosted models, giving teams a flexible yet governed foundation for any generative-AI workflow. Below are the core components for the MPAC Orchestrator.
| Component | AWS services | Function |
| Orchestrator API | Amazon API Gateway, AWS Lambda (TypeScript), Amazon RDS | Manages users, endpoints, workflows, and audit trails |
| Streaming service | Amazon EKS | Provides private streaming from Amazon Bedrock without public Lambda URLs |
| Data ingestion | Amazon Simple Queue Service (Amazon SQS), AWS Lambda (Python), Amazon S3 | Processes documents with semantic chunking and embedding generation |
| Security and governance | Amazon Cognito, AWS Lambda authorizer, Amazon Virtual Private Cloud (Amazon VPC) | Enforces single sign-on, access controls, and prompt guardrails |
Key implementation details
In this section, we provide some code snippets to demonstrate the capabilities of the MPAC Orchestrator.
1) Agentic orchestration: Supervisor pattern with dynamic tool execution
This is a high-level example of MPAC’s custom agentic framework built on Amazon Bedrock, where a supervisor agent dynamically routes tasks to specialized tools and manages multi-step reasoning within a single, governed workflow.
2) Built-in cost tracking and workflow lifecycle
The workflow lifecycle hooks automatically track token usage and calculate real-time costs per interaction, giving teams instant visibility into AI spend without additional instrumentation.
3) Clean Lambda handlers: Simplicity through runtime abstraction
Custom runtime provides a clean, simple abstraction that plugs seamlessly into Lambda’s streaming capabilities, letting developers focus more on AI logic.
The AI workflow in action
The IT Support Assistant follows a sophisticated agentic workflow:
- Intent entry point: A first node decides whether the user wants general help or a formal escalation.
- Ticket creation path:
- Confirms an IT issue is present, and no ticket exists.
- Uses an endpoint node to craft a JSON payload for the Jira Service Desk API.
- Posts the payload, captures the ticket ID, and passes it to a follow-up endpoint.
- The final node sends the user the ticket link plus a short summary of why it was created.
- Self-help path:
- Extracts error messages from user screenshots.
- Queries vector database with contextual information.
- Returns tailored responses with relevant documentation snippets.
- Advanced question routing to live agents: When a question requires nuance, the assistant hands off to an agent with full context, so customers get faster help, and teams focus on the complex issues that matter most.
This agentic workflow is orchestrated entirely inside the MPAC Orchestrator and streamed back to the user through the Orchestrator Echo.
“We built the Orchestrator not just to abstract complexity, but to establish a secure and extensible foundation for generative AI at scale,” explained Brandon Jull, principal IT engineer at MPAC. “By leveraging a fully serverless architecture and layering in deep governance—from prompt integrity to private streaming and access control—we’ve created a system where flexibility doesn’t come at the cost of control.”
No-code interface for enterprise adoption
The MPAC Orchestrator’s drag-and-drop interface democratizes AI development across the organization. It loads unstructured documents (PDF, JSON, HTML, and more) directly into MPAC’s internal vector database or link an AWS native vector store such as Amazon RDS or Amazon OpenSearch Service with Amazon Bedrock Knowledge Bases. The ingestion and indexing happen automatically. It then creates endpoints or chains them into agentic workflows (for example, summarize → translate → classify) without writing boilerplate code. The MPAC Orchestrator is modular by design. For example, endpoints natively invoke Amazon Bedrock foundation models today and can extend to additional providers—or self-hosted models—without refactoring business logic. Furthermore, it monitors usage and savings with built-in dashboards that track tokens, latency, and cost.
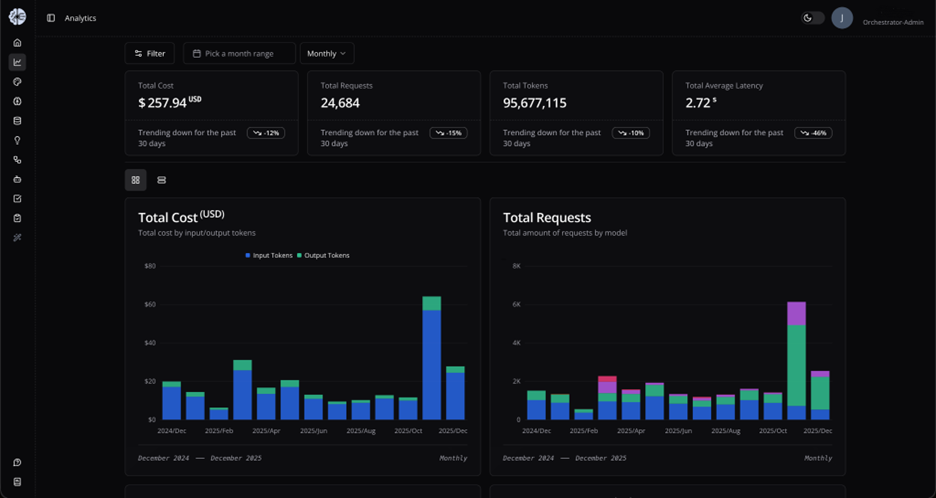
Figure 2. Real-time analytics dashboard providing full visibility into token usage, costs, and latency across all model usage
Custom agentic orchestration runtime is designed to eliminate the infrastructure complexity that holds back AI deployments on AWS. The Node.js runtime runs on Lambda ARM64 for 20% better price-performance, while intelligent abstractions automatically handle streaming responses, retry logic, and real-time cost tracking. As a result, developers write simple handlers focused purely on AI logic while our runtime delivers enterprise-scale reliability through AWS Bedrock, API Gateway, and SAM—turning complex agentic workflows into production-ready applications with minimal code.
“We didn’t just build a tool, we built a foundation for the future of intelligent automation,” noted Stratos Kaloutas, director of artificial intelligence and automation at MPAC. “By developing the orchestrator in-house, we’ve created a platform where anyone, from developers to business users, can harness the power of LLMs through a simple, no-code interface.”
Lesson learned
MPAC’s journey with the MPAC Orchestrator and the IT Support Assistant revealed valuable insights into balancing innovation speed, cost, and control in generative AI adoption, particularly for public sector organizations with strict compliance needs.
- Hybrid flexibility via the MPAC Orchestrator: Building an in-house orchestration layer allowed seamless integration of Amazon Bedrock with self-hosted models, abstracting complexities behind a single API—for example, using the proprietary model for property assessment, and Amazon Bedrock for general-purpose scenarios.
- Security and governance trade-offs: Amazon Bedrock’s built-in guardrails (for example, prompt safety and VPC isolation) complemented the custom controls in the MPAC Orchestrator. This reduced the need for bespoke security layers that self-hosting would demand. A key lesson: Prioritizing serverless governance upfront prevented “runaway costs” or compliance gaps, saving the team from potential rework as they scaled to HR, valuation, and beyond.
- Overall scalability insight: The 83.5% resolution rate and improved agent efficiency underscore that Amazon Bedrock’s on-demand pricing and performance make it ideal for experimentation-to-production transitions—especially versus self-hosting’s capex-heavy model. This positions MPAC to confidently extend the MPAC Orchestrator to automate identity workflows or embed AI in portals, focusing resources on business value rather than infra management.
By applying these lessons, organizations can accelerate their generative AI journey from pilot to production while maintaining enterprise-grade security, regulatory compliance, and predictable costs.
Future roadmap and expansion
MPAC’s vision extends far beyond IT support automation. The organization plans enterprise-wide deployment, bringing generative AI capabilities to human resources for benefits and policy inquiries and to facilities for service requests, maintenance, and space planning guidance. This expansion uses the flexible foundation of the MPAC Orchestrator to create consistent AI experiences across all departments.
The technical roadmap focuses on embedding AI into core business workflows—integrating intelligent assistants and semantic search into MPAC’s internal systems to streamline processes, surface insights, and deliver consistent experiences across departments. MPAC also envisions a unified employee experience where AI-powered widgets integrate seamlessly into existing internal portals, creating an always-available “Ask MPAC” interface that employees can access from any system or application they use daily.
Getting started with your own implementation
Schedule an architecture review with your AWS team to discuss your specific requirements and constraints. Explore Amazon Bedrock capabilities hands-on through the AWS Management Console to understand available foundation models and their applications. Review the sample code and reference architectures provided to understand implementation patterns and connect with the MPAC team through the AWS customer reference program to learn from their experience.
“MPAC was one of the first public sector organizations in Canada to move to the cloud when we partnered with AWS Canada in 2015, and that partnership paved the way for our strategic adoption of generative AI,” said Nicole McNeill, president and CEO of MPAC. “Our support service desk is already very responsive and exceptionally well-reviewed by our employees and adding an AI-based support assistant has drastically increased the speed at which we resolve simple questions and issues so we can resolve complex issues even faster.”
MPAC’s success demonstrates how public sector organizations can rapidly move from generative AI experimentation to production-grade deployment without compromising security, compliance, or budget. With the right architecture and AWS services, your organization can achieve similar results in scaling employee productivity through intelligent automation.
Ready to transform your IT support with generative AI? Contact your AWS solutions architect today to begin your journey. To learn more about AWS in the public sector, contact the AWS Public Sector team.