AWS Public Sector Blog
How to build API-driven data pipelines on AWS to unlock third-party data

Public sector organizations often use third-party software-as-a-service (SaaS) for project management, human resources, event registration, web analytics, donor management, marketing, and more. These systems are independent, leading to data siloes that can be difficult to consolidate for unified business insights.
Part 1 of this two-part blog post series, Unlock third-party data with API driven data pipelines on AWS, outlined considerations for developing API pipelines on Amazon Web Services (AWS) to extract data from third-party SaaS tools with APIs. With consolidated data, public sector organizations can offer new experiences for donors and members, enrich research datasets, and improve operational efficiency for their staff.
This part 2 post presents options for ingesting SaaS data with API requests from AWS services, methods for handling payload data from API calls, and guidance for orchestration and scaling an API data pipeline on AWS.
Here in Part 2, you will learn how to develop an API data pipeline using AWS Lambda, AWS Glue and AWS Step Functions to orchestrate data ingestion from two sample SaaS applications – a fundraising application and a membership platform.
Build an API-driven data pipeline on AWS to unlock third-party data
Let’s examine a use case in which an organization has membership data stored in one location, and fundraising transactions stored in another. Currently, the organization has to manually search through the membership system to determine a donor’s membership status. The organization has limited visibility to donation trends for their members and misses on the opportunity to recruit new donors as members. The goal is to integrate these two datasets to provide better visibility of member donations that will inform targeted outreach.
These two systems offer open APIs and provide API keys to registered customers. The example solution presented here uses Lambda to make an API call to each of these data sources, referencing API Key secrets secured in AWS Secrets Manager, and stores the response payload in Amazon Simple Storage Service (Amazon S3). This solution uses an AWS Glue job to flatten the payload data to a relational format so that it is available to query or load to a downstream data target. The solution then uses Amazon Athena to query the data.
The solution uses Step Functions to orchestrate the data pipeline so that the API request, storage and data transformation are executed automatically. The solution leverages parameters and arguments in Step Functions to pass values into the Lambda function and AWS Glue job. This helps simplify and scale the pipeline since the solution uses a single generic script instead of writing independent scripts for each new data source.
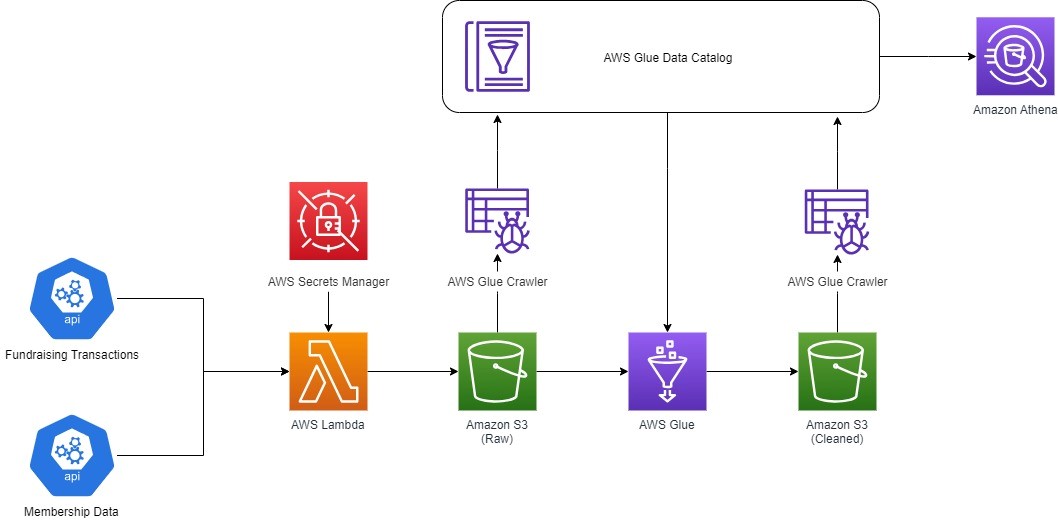
Figure 1. The fundraising and membership platform SaaS host open APIs. AWS Lambda calls each API, using API keys stored in AWS Secrets Manager, and sends the response payload to a “raw” folder in the Amazon S3 bucket, which is crawled by an AWS Glue Crawler and catalogued in the AWS Glue Catalog. AWS Glue formats the data and sends it to a “cleaned” folder in the Amazon S3 bucket. An AWS Glue Crawler populates the AWS Glue Catalog with the clean data, making it available for querying in Amazon Athena.
Prerequisites
Before beginning this solution, you need the following:
- An AWS account
- Administrative access to the following services
Deploying resources with AWS CloudFormation
An AWS CloudFormation template can deploy all the resources you need for this solution.
This template creates two sample API endpoints for the data sources (the membership data and the fundraising transactions), a Lambda function to call the APIs, an Amazon S3 bucket for data storage, AWS Glue crawlers to catalog the data, and a Step Functions state machine to orchestrate the data pipeline. Note that deploying these resources into your AWS account incurs charges. See the Cleaning up section for instructions to delete these resources after deployment. Learn more about AWS Pricing.
Deploy the solution
- Log into the AWS Management Console and ensure you are in the US East (N. Virginia) us-east-1
- Select the Launch Stack button. The AWS CloudFormation page in the AWS Management Console opens

- Enter a Stack name (example: npo-blog-api-stack).
- Check the box that says I acknowledge that AWS CloudFormation might create IAM resources and select the Create Stack
The stack takes 3-5 minutes to provision. When the template finishes deploying resources, the Stack info tab shows CREATE_COMPLETE as shown in Figure 2.

Figure 2. The CloudFormation Stack info tab showing CREATE_COMPLETE status.
Call API endpoints with Lambda and store payload data on Amazon S3
After running the CloudFormation template, you can make API calls to the sample endpoints. These calls simulate data being requested from the membership and fundraising applications.
- Navigate to the AWS Lambda console and select Functions from the navigation pane.
- Select the function that begins with lambda-api-call. This is the function that makes the GET request to your API endpoints.
- Select the Test tab to view test events pre-populated by the CloudFormation template.
- Select members-test-event from the event name dropdown. The test event references the resources created in the CloudFormation template including the API key stored as a secret in Secrets Manager, the API endpoint as a URL, the destination Amazon S3 bucket, and the name of the object to output. You can pass these in as parameters through the Event JSON to the AWS Lambda function.

Figure 3. The input for the members test event to pass as parameters through the Event JSON to the AWS Lambda function.
- Select Test to execute the AWS Lambda with the event JSON.
- Select the execution details to see a response body including the payload (Figure 4).

Figure 4. The Test tab features the execution results from the test event.
- Next, select the fundraising-test-event from the Event name Select Test to execute the Lambda function.
- Now, both APIs have been called from the same Lambda function with the payloads written to Amazon S3.
- Navigate to your Amazon S3 bucket beginning with api-blog-data-store and check the output under the raw-data
- Within the fundraising folder generated by the Lambda function, select the fundraising.json object via the checkbox. From the Actions dropdown, choose Query with S3 Select

Figure 5. The dropdown menu for viewing JSON data using Query with S3 Select
- Leave the default settings and select Run SQL query to view sample output from the JSON file. The Lambda function has successfully written the API payload to Amazon S3.

Figure 6. The SQL query results for the fundraising.json API payload displayed in the Amazon S3 console.
Catalog the API payloads with AWS Glue crawler
- Next, run an AWS Glue crawler to add a schema structure to the raw JSON payload. The CloudFormation template has already provisioned an AWS Glue crawler for you.
- Navigate to the AWS Glue console and select Crawlers from the navigation pane under Data Catalog.
- Select the crawler api-blog-crawler-raw and choose
- Once the crawler run has succeeded, navigate to Tables under the Data Catalog section of the navigation pane.
- Under the database api_blog_database find two new tables called raw_members and
- Choose the raw_fundraising table to view the schema structure and you’ll notice the Data type of array for the final column. You need to flatten this JSON to bring that array into a relational structure to properly query the data.

Figure 7. Schema structure from the raw fundraising API payload in the AWS Glue console.
Flatten API payload with an AWS Glue PySpark job
- Download the notebook file and save it to a local directory on your computer.
- In the AWS Glue console, choose ETL jobs in the navigation pane.
- Select Jupyter Notebook from the menu of job options.
- Under Options, select Upload and edit an existing notebook.
- Select Choose file and browse to the notebook file you downloaded.
- Select Create.
- For Job Name, enter a name for the job. You will reference this job name later.
- For Kernel, select Spark.
- For IAM Role, use the role beginning with AWSGlueServiceRole-APIBlog which is provisioned as part of the CloudFormation template.
- Choose Start Notebook.
- Once the notebook loads, select Save to make sure the notebook saves as an AWS Glue Job for later.
- Begin executing each cell in the notebook, paying close attention to set the bucket_name variable in CELL #3. Use the bucket name starting with api-blog-data-store. Later, you will update this notebook to use arguments passed in from Step Functions to populate these variables.
- Run through the notebook with the source_name in CELL #3 set to “members”, then run through cells 3-7 again with the source_name set to “fundraising”.
- Navigate to the Amazon S3 bucket beginning with api-blog-data-store to check the output under the flattened-data
- Within the fundraising folder, select the parquet file via the checkbox and choose Query with S3 Select from the Actions dropdown.
- Choose JSON under Output settings then select Run SQL query to view sample output from the JSON file. The AWS Glue job has successfully flattened the API payload and written it back to Amazon S3.

Figure 8. The SQL query results for the flattened fundraising API payload in the Amazon S3 console.
Catalog the flattened API payloads with AWS Glue crawler
- Navigate to the AWS Glue console and select Crawlers from the navigation pane under Data Catalog.
- Select the crawler api-blog-crawler-flat and choose
- Once the crawler run has succeeded, navigate to Tables under the Data Catalog section of the navigation pane.
- Under the database api_blog_database, find two new tables called flat_members and flat_fundraising
- Select the flat_fundraising table to view the schema structure and find the flattened columns ready for querying.

Figure 9. Schema structure from the flattened fundraising payload.
Query the flattened data with Amazon Athena
- While viewing the table schema in the AWS Glue console, find the Actions menu and choose View data. A pop-up may appear to let you know that you’re navigating to the Amazon Athena console. Select
- If this is your first time using Amazon Athena in this account, you have to set the query result location. The CloudFormation template created an Amazon S3 bucket for this output. From the Amazon Athena editor select the ‘Edit settings’ banner and browse to your Amazon S3 bucket beginning with api-blog-athena-results and choose Save.
- From the editor tab, choose Run to see the flattened data from Amazon S3.
- Now you can query the data from either flattened API payload using standard SQL to join disparate data in Amazon Athena.

Figure 10. Query results from Amazon Athena displaying the output from the flattened fundraising table in tabular form.
Prepare the AWS Glue Job for orchestration with Step Functions
- Navigate back to the AWS Glue notebook job and scroll to CELL #3.
- Comment out the initial source_name and bucket_name variables you set manually. Uncomment the rows to set these variables using arguments passed from Step Functions.
- Select Save.
- The cell should match the following code (written in Python):
#source_name = "members" #source_name = "fundraising" # When testing the notebook initially, set the bucket name to the value of the S3 bucket that was created for you by the Cloudformation template #bucket_name = "api-blog-data-store..." # Uncomment the below when ready to access the arguments passed in from AWS Step Functions args = getResolvedOptions(sys.argv,['source_name', 'bucket_name']) source_name = args['source_name'] bucket_name = args['bucket_name']
Orchestrate the API data pipeline with Step Functions
The API calls have been executed and data has been prepared for querying. Next, we will transition to an automated process using Step Functions to trigger the API call, payload storage and processing.
- The CloudFormation template has already provisioned a Step Functions state machine. Now, update this state machine with the specific argument values.
- Navigate to the AWS Step Functions console.
- Select the newest state machine, StateMachine-API-Pipeline-Blog
- Select Edit from the top menu to enter into the visual editor and review your workflow (Figure 11). This workflow executes two paths in parallel, each using the same AWS Lambda function and AWS Glue job, but injecting different parameters for each data source.

Figure 11. The Step Functions workflow includes two separate API calls, one for the members data source and one for the fundraising data source, executed in parallel with Lambda and sent to Glue for processing.
- Select the Lambda Invoke (Members) action and scroll down to the Payload section of the Configuration pane.
- Review the fields that were populated with the CloudFormation outputs that you used to test the AWS Lambda function initially. Step Functions passes this into the AWS Lambda function.

Figure 12. The payload that the Step Functions workflow passes into the AWS Lambda function for the members API call.
- After reviewing the payloads for both the members and fundraising Lambda actions, select the Glue StartJobRun (Members) action and scroll down to the API Parameters section of the Configuration pane.
- Update the JobName field with the name of your AWS Glue job you created and updated earlier. Step Functions passes the source_name and bucket_name as arguments into the AWS Glue job.
- Next, select the Glue StartJobRun (Fundraising) action and update the same JobName.
- Select Save from the top menu, then Execute to run your state machine and automate your data pipeline. Select Start Execution from the new tab.
- You can view the progress of your data pipeline in graph view. The workflow should run in 2-3 minutes.
- Once all actions have succeeded, each action shows a green checkmark and the overall execution status of the job shows Succeeded.

Figure 13. Step Functions successfully completed the API pipeline workflow and brought in new data from the members and fundraising API.
You have successfully run an orchestrated API data pipeline that requests data from two different data sources, transforms the data, and stores it for analysis. Note that you can execute this Step Functions workflow manually, or leverage Amazon EventBridge to run the workflow on a schedule. Learn more about EventBridge service integration for AWS Step Functions.
Cleaning up
To avoid unnecessary charges like storage and computing costs, you can delete the AWS CloudFormation stack to remove all resources from your AWS account.
Navigate to AWS CloudFormation in the console and select your stack. Choose Delete and select Delete Stack. All resources are deleted after about five minutes.
Additionally, AWS Glue retains the catalogued items and transformation job. You can manually delete these if you do not wish to retain them.
- Navigate to the AWS Glue console.
- In the side menu, select
- Select the api_blog_database and choose Delete from the menu.
- In the side menu, select ETL jobs.
- Select your AWS Glue job created to flatten the API payload.
- Choose Actions and select Delete job(s) from the dropdown.
Lastly, two Amazon S3 buckets were created and retained to store Amazon Athena query results and access logging. You can manually empty and delete these if you do not wish to retain them.
Conclusion
Public sector organizations can unlock data from third-party SaaS tools using an API data pipeline built on AWS to drive new business value. This includes amplifying donor and member personalization, generating new insights by enriching existing data, and improving operational efficiency for internal teams.
In this solution example, the organization has fundraising transactions stored independent from membership data. After integrating these datasets with an API-driven data pipeline, the organization can now view donation trends for existing members, or donations from non-members, and implement personalized outreach to encourage new donations and memberships.
Although this example is specific to membership and fundraising, your organization can use this AWS native API data pipeline to extract value and unify data across many SaaS applications for business insights.
If you would like to discuss this further with your AWS Account Team, complete the Public Sector Contact Us form for your organization.