亚马逊AWS官方博客
通过 AWS DMS 将更改数据流式传输到 Amazon Kinesis Data Streams
在本文中,我们将讨论如何使用 AWS Database Migration Service (AWS DMS) 本机更改数据捕获 (CDC) 功能将更改流式传输到 Amazon Kinesis Data Streams。
AWS DMS 是一项云服务,可以轻松迁移关系数据库、数据仓库、NoSQL 数据库和其他类型的数据存储。您可以使用 AWS DMS 将数据迁移到 AWS 云中,或在云和本地设置的组合之间迁移。AWS DMS 还可以帮助您复制正在进行的更改,使源和目标保持同步。CDC 是指这样的过程:识别和捕获对数据库中数据所做的更改,然后将这些更改实时传送到下游系统。捕获源数据库中事务的每一项更改并将其实时移到目标,这样可使系统保持同步,并有助于实时分析使用案例和零停机数据库迁移。
Kinesis Data Streams 是一项完全托管的流数据服务。您可以不断将数十万个来源的各种类型的数据(如点击流、应用程序日志和社交媒体)添加到 Kinesis 流中。几秒钟之内,流数据便可供 Kinesis 应用程序读取和处理。AWS DMS 可以同时执行复制和迁移。Kinesis Data Streams 在复制使用案例中最有价值,因为它允许您对其他集成式 AWS 系统中复制的数据更改做出反应。
本文是使用 AWS Database Migration Service 将更改数据流式传输到 Amazon Kinesis Data Streams 一文的更新。这篇新文章包括针对 CDC 使用案例配置 AWS DMS 和 Kinesis Data Streams 所需的步骤。通过将 Kinesis Data Streams 作为 AWS DMS 的目标,您可以更轻松地流式传输、分析和存储 CDC 数据。AWS DMS 使用最佳实践自动收集数据存储的更改,并将其流式传输到 Kinesis Data Streams。
通过将 Kinesis Data Streams 添加为目标,我们正在帮助客户构建数据湖,并对数据存储中的更改数据执行实时处理。您可以在数据集成管道中使用 AWS DMS,将数据近乎实时地直接复制到 Kinesis Data Streams 中。通过这种方法,您可以构建分离、最终一致的数据库视图,而不必在数据库之上构建应用程序,这样做成本太高。您可以参阅 AWS 白皮书 AWS 云数据摄取模式和实践,详细了解数据摄取模式。
实时更改数据的 AWS DMS 源
下图说明了 AWS DMS 可以使用许多最受欢迎的数据库引擎作为源以将数据复制到 Kinesis Data Streams 目标。数据库源可以是在 Amazon Elastic Compute Cloud (Amazon EC2) 实例上运行的自我管理的引擎或本地数据库,也可以是 Amazon Relational Database Service (Amazon RDS)、Amazon Aurora 或 Amazon DocumentDB(与 MongoDB 兼容)。
Kinesis Data Streams 可以实时收集、处理和存储任何规模的数据流,并将其写入 AWS Glue,这是一项无服务器数据集成服务,可轻松地发现、准备和合并用于分析、机器学习和应用程序开发的数据。您可以使用 Amazon EMR 进行大数据处理,使用 Amazon Kinesis Data Analytics 处理和分析流数据,使用 Amazon Kinesis Data Firehose 针对流数据运行 ETL(提取、转换和加载)作业,将 AWS Lambda 作为无服务器计算,进一步处理、转换和传送使用数据。
您可以将数据存储在数据仓库中,比如 Amazon Redshift,这是一个云规模数据仓库,也可以存储在 Amazon Simple Storage Service (Amazon S3) 数据湖中供使用。您可以使用 Kinesis Data Firehose 捕获数据流并将数据加载到 S3 存储桶中进行进一步分析。
一旦数据在 Kinesis Data Streams 目标中可用(如下图所示),您便可使用 Amazon QuickSight 将其可视化;使用 Amazon Athena 运行临时查询;使用 Amazon SageMaker 笔记本实例对其进行访问、处理和分析;并高效地从 Amazon S3 文件中查询和检索结构化数据与半结构化数据,而无需使用 Amazon Redshift Spectrum 将数据加载到 Amazon Redshift 表中。

解决方案概述
在本文中,我们将介绍如何使用 AWS DMS 将数据库中的数据实时加载到 Kinesis Data Streams。我们以 SQL Server 数据库为例,但 Oracle、Microsoft Azure SQL、PostgreSQL、MySQL、SAP ASE、MongoDB、Amazon DocumentDB 和 IBM DB2 等其他数据库也支持此配置。
您可以使用 AWS DMS 捕获数据库中的数据更改,然后将这些数据发送到 Kinesis Data Streams。在 Kinesis Data Streams 中摄取流后,Lambda、Kinesis Data Analytics、Kinesis Data Firehose 等其他服务以及使用 Kinesis Client Library (KCL) 或 AWS 开发工具包的自定义使用者便可使用这些流。
以下是一些可以使用 AWS DMS 和 Kinesis Data Streams 的使用案例:
- 触发实时事件驱动型应用程序 – 此使用案例集成了 Lambda 和 Amazon Simple Notification Service (Amazon SNS)。
- 简化和分离应用程序 – 例如,从整体迁移到微服务。该解决方案集成了 Lambda 和 Amazon API Gateway。
- 缓存失效以及更新或重新构建索引 – 集成 Amazon OpenSearch Service(Amazon Elasticsearch Service 的下一代产品)和 Amazon DynamoDB。
- 跨多个异构系统的数据集成 – 此解决方案将数据发送到 DynamoDB 或其他数据存储。
- 聚合数据并将其推送到下游系统 – 此解决方案使用 Kinesis Data Analytics 分析和集成不同的源,并将结果加载到另一个数据存储中。
为了便于理解 AWS DMS、Kinesis Data Streams 和 Kinesis Data Firehose 之间的集成,我们定义了一个您可以解决的业务案例。在此使用案例中,您是一家能源公司的数据工程师。这家公司使用 Amazon Relational Database Service (Amazon RDS) 来存储其最终客户信息、账单信息以及电表和燃气使用数据。Amazon RDS 是他们的核心交易数据存储。
您每周运行一次批处理作业来收集所有交易数据,并将其发送到数据湖进行报告、预测,甚至向客户发送账单信息。您还有基于触发器的系统,用于定期向客户发送有关其用电量和每月账单信息的电子邮件和短信。
由于该公司拥有数百万客户,因此,每天需要处理大量数据以及发送电子邮件或短信,这样拖慢了核心交易系统的速度。此外,每周运行批处理作业进行分析并不能提供准确、最新的结果,以预测客户的燃气和电力使用情况。最初,您的团队考虑重新构建整个平台并避免所有这些问题,但核心应用程序的设计很复杂,在生产环境中运行多年,重新构建整个平台将需要数年时间,花费数百万美元。
因此,您采取了新方法。您不再在核心事务数据库上运行批处理作业,而是开始使用 AWS DMS 捕获数据更改并将此类数据发送到 Kinesis Data Streams。然后,您使用 Lambda 监听特定数据流,并使用 Amazon SNS 生成电子邮件或短信,将其发送给客户(例如,发送月度账单信息或通知客户的用电量或燃气使用量高于正常水平)。您还使用 Kinesis Data Firehose 将所有交易数据发送到数据湖,这样,您的公司就可以立即准确地运行预测。
下图展示了此架构。

在以下步骤中,您将数据库配置为使用 AWS DMS 将更改复制到 Kinesis Data Streams。此外,您还将 Kinesis Data Firehose 配置为将 Kinesis Data Streams 数据加载到 Amazon S3。
在 AWS DMS 中将 Kinesis Data Streams 设置为变更数据目标并开始流式传输数据非常简单。有关更多信息,请参阅使用 Amazon Kinesis Data Streams 作为 AWS Database Migration Service 的目标。
要开始,您首先需在 Kinesis Data Streams 中创建 Kinesis 数据流,然后创建具有最低访问权限的 AWS Identity and Access Management (IAM) 角色,如使用 Kinesis 数据流作为 AWS Database Migration Service 目标的先决条件中所述。定义 IAM 策略和角色后,在 AWS DMS 中设置源和目标端点与复制实例。源是要从中移动数据的数据库,目标是要将数据移动到其中的数据库。在我们的例子中,源数据库是 Amazon RDS 上的 SQL Server 数据库,目标是 Kinesis 数据流。复制实例处理迁移任务,需要访问您的 VPC 内的源端点和目标端点。
Kinesis 传送流(在 Kinesis Data Firehose 中创建)用于将数据库中的记录加载到 Amazon S3 上托管的数据湖。Kinesis Data Firehose 还可以将数据加载到 Amazon Redshift、Amazon OpenSearch Service、HTTP 端点、Datadog、Dynatrace、LogicMonitor、MongoDB Cloud、New Relic、Splunk 和 Sumo Logic。
配置源数据库
出于测试目的,我们使用托管在 SQL Server on Amazon RDS 上的数据库 democustomer。使用以下命令和脚本创建数据库与表,并插入 10 条记录:
要捕获添加到表中的新记录,请在数据库级别使用以下命令启用 MS-CDC (Microsoft Change Data Capture)(替换 SchemaName 和 TableName)。如果在 AWS DMS 中对任务迁移配置了持续复制,则必须执行此操作。
您可以在本地或 Amazon Elastic Compute Cloud (Amazon EC2) 上为自我管理的 SQL Server 数据库、Amazon RDS 等云数据库或 Azure SQL 托管实例使用持续复制 (CDC)。必须将 SQL Server 配置为完全备份,且必须在开始复制数据之前执行备份。
有关更多信息,请参阅使用 Microsoft SQL Server 数据库作为 AWS DMS 的源。
配置 Kinesis 数据流
接下来,我们配置 Kinesis 数据流。有关完整说明,请参阅通过 AWS 管理控制台创建流。请完成以下步骤:
- 在 Kinesis Data Streams 制台上,选择 Create data stream(创建数据流)。
- 对于 Data stream name(数据流名称),输入一个名称。
- 对于 Capacity mode(容量模式),选择 On-demand(按需)。选择按需容量模式时,Kinesis Data Streams 会在工作负载增加或减少时立即适应。有关更多信息,请参阅选择数据流容量模式。

- 选择 Create data stream(创建数据流)。
- 当数据流处于活动状态时,复制 ARN。

配置 IAM 策略和角色
接下来,配置您的 IAM 策略和角色。
- 在 IAM 控制台上,选择导航窗格中的 Policies(策略)。
- 选择 Create policy(创建策略)。
- 选择 JSON 并使用以下策略作为模板,替换数据流 ARN:
- 在导航窗格中,选择 Roles(角色)。
- 选择 Create role(创建角色)。
- 选择 AWS DMS,然后选择 Next: Permissions(下一步:权限)。
- 选择您创建的策略。
- 分配角色名称,然后选择 Create role(创建角色)。
配置 Kinesis 传送流
我们使用 Kinesis 传送流将 Kinesis Data Stream 中的信息加载到 Amazon S3。要配置传送流,请完成以下步骤:
- 在 Kinesis 控制台上,选择 Delivery streams(传送流)。
- 选择 Create delivery stream(创建传送流)。
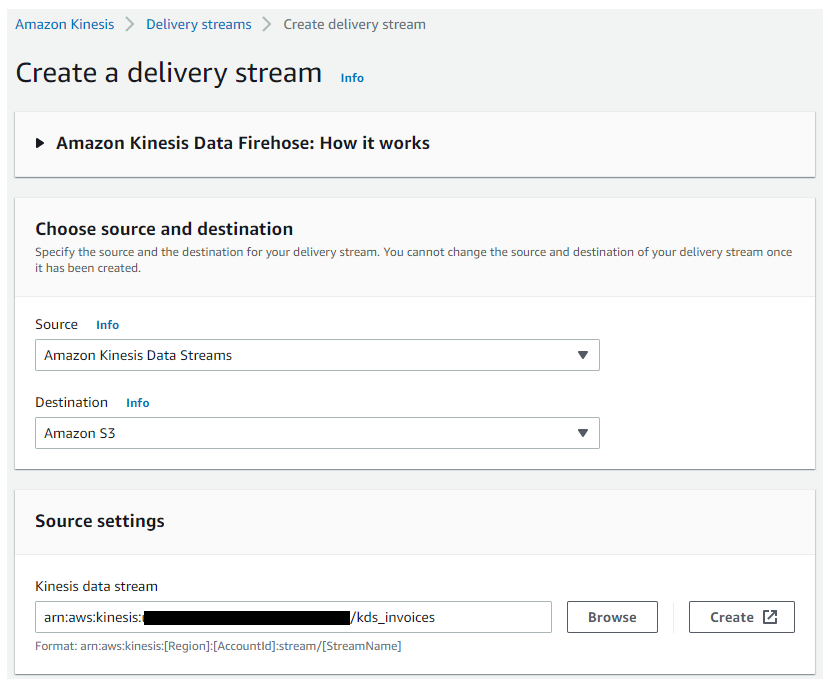
- 对于 Source(源),选择 Amazon Kinesis Data Streams。
- 对于 Destination(目标),选择 Amazon S3。
- 对于 Kinesis data stream(Kinesis 数据流),输入数据流的 ARN。
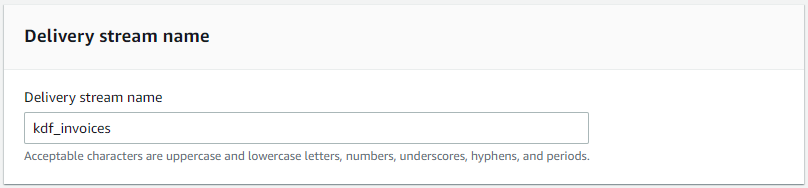
- 对于 Delivery stream name(传送流名称),输入一个名称。
- 将变换和转换选项保留为默认值。

- 提供目标存储桶并指定事件和错误的存储桶前缀。

- 在 Buffer hints, compression and encryption(缓冲区提示、压缩和加密)下,将缓冲区大小更改为 1 MB,将缓冲区间隔更改为 60 秒。

- 将其他配置保留为默认值。
配置 AWS DMS
我们使用 AWS DMS 实例连接到 SQL Server 数据库,然后将表和未来事务复制到 Kinesis data stream 中。在本部分中,我们将创建复制实例、源端点、目标端点和迁移任务。有关端点的更多信息,请参阅创建源和目标端点。
- 在能连接到 SQL Server 数据库的 VPC 中创建复制实例,并将具有足够数据库访问权限的安全组关联起来。
- 在 AWS DMS 控制台的导航窗格中,选择 Endpoints(端点)。
- 选择 Create endpoint(创建端点)。
- 选择 Source endpoint(源端点)。

- 对于 Endpoint identifier(端点标识符),输入端点的标签。
- 对于 Source engine(源引擎),选择 Microsoft SQL Server。
- 对于 Access to endpoint database(访问端点数据库),选择 Provide access information manually(手动提供访问信息)。
- 输入端点数据库信息。

- 测试与源端点的连接。
接下来,我们创建目标端点。 - 在 AWS DMS 控制台的导航窗格中,选择 Endpoints(端点)。
- 选择 Create endpoint(创建端点)。
- 选择 Target endpoint(目标端点)。

- 对于 Endpoint identifier(端点标识符),输入端点的标签。
- 对于 Target engine(目标引擎),选择 Amazon Kinesis。
- 提供 AWS DMS 服务角色 ARN 和数据流 ARN。

- 测试与目标端点的连接。

最后一步是创建数据库迁移任务。此任务将现有数据从 SQL Server 表复制到数据流,并复制正在进行的更改。有关更多信息,请参阅创建任务。 - 在 AWS DMS 控制台上,选择 Database migration tasks(数据库迁移任务)。
- 选择 Create task(创建任务)。
- 对于 Task identifier(任务标识符),输入任务的名称。
- 对于 Replication instance(复制实例),选择您的实例。
- 选择您创建的源和目标数据库端点。
- 对于 Migration type(迁移类型),选择 Migrate existing data and replicate ongoing changes(迁移现有数据并复制正在进行的更改)。

- 在 Task settings(任务设置)中,使用默认设置。
- 在 Table mappings(表映射)中,添加新的选择规则,并指定 SQL Server 数据库的架构和表名。在本例中,我们的架构名称为 dbo,表名为 invoices。
- 对于 Action(操作),选择 Include(包含)。

任务准备就绪后,迁移开始。

加载数据后,表统计信息将更新,您可以看到最初创建的 10 条记录。

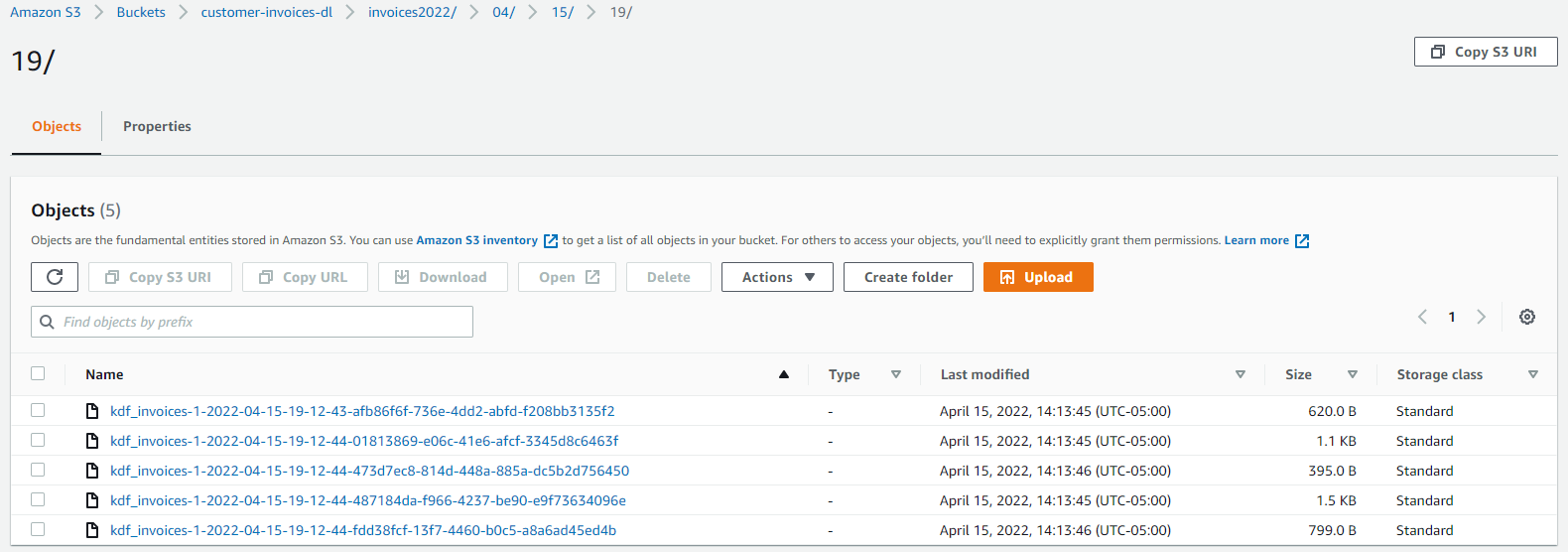
当 Kinesis 传送流从 Kinesis Data Streams 中读取数据并将其加载到 Amazon S3 中时,这些记录在您之前定义的存储桶中可用。
要检查 AWS DMS 正在进行的复制和 CDC 是否正常运行,请使用该脚本,将 1,000 条记录添加到表中。
您可以在 Table statistics(表统计信息)选项卡中看到数据库迁移任务的 1,000 条插入。

大约 1 分钟后,您可以看到 S3 存储桶中的记录。

此时,复制已激活,Lambda 函数可以开始使用数据流,通过 Amazon SNS 向客户发送电子邮件短信。相关详情,请参阅将 AWS Lambda 与 Amazon Kinesis 结合使用。
结论
通过将 Kinesis Data Streams 作为 AWS DMS 目标,现在,您可以采用强大的方法,将更改数据从数据库直接流式传输到 Kinesis 数据流。您可以使用此方法流式传输 AWS DMS 支持的任何源的更改数据,以执行实时数据处理。流式传输愉快哦!
如果您有任何问题或建议,请留言。
关于作者
 Luis Eduardo Torres 是一名在哥伦比亚波哥大工作的 AWS 解决方案架构师。他利用 AWS 云平台帮助公司建立业务。他对分析非常感兴趣,一直以西班牙语领导 AWS Podcast 的分析跟踪。
Luis Eduardo Torres 是一名在哥伦比亚波哥大工作的 AWS 解决方案架构师。他利用 AWS 云平台帮助公司建立业务。他对分析非常感兴趣,一直以西班牙语领导 AWS Podcast 的分析跟踪。
 Sukhomoy Basak 是 Amazon Web Services 解决方案架构师,对数据和分析解决方案充满热情。Sukhomoy 与企业客户合作,帮助他们设计、构建和扩展应用程序,以实现业务成果。
Sukhomoy Basak 是 Amazon Web Services 解决方案架构师,对数据和分析解决方案充满热情。Sukhomoy 与企业客户合作,帮助他们设计、构建和扩展应用程序,以实现业务成果。