亚马逊AWS官方博客
使用 Amazon Neptune 绘制投资依存关系图
Original URL: https://aws.amazon.com/blogs/database/graphing-investment-dependency-with-amazon-neptune/
通过在 Amazon Neptune 中以图形形式存储和查询投资依存关系,可揭示新的关系。EDGAR(电子数据收集、分析和检索)是美国证券交易委员会 (SEC) 的在线公共数据库。EDGAR 负责处理按照法律要求向 SEC 提交相关表格的实体的自动化收集、验证、索引、接受和转交。这些实体包括机构投资经理,如注册投资顾问、银行、保险公司、对冲基金以及对此类账户具有投资自由裁量权的其他集团。
这些文件包含许多数据块,例如:
- 有关公开上市公司和已向公众发行债券的公司的数据。
- 高管薪酬,包括:
- 公司的年度委托书。
- 公司的 10-K 表年度报告。
- 公司为登记要向公众发行的证券所提交的登记声明。
- 管理超过 1 亿美元的资产且长期持有美国股票的所有机构投资经理的股票持仓披露。包括经理投资组合中的所有美国上市股票,并根据股票数量、股票代码和发行人名称进行详细说明。
这些数据块被视为这些公司提交的事件的独立事实。但是,EDGAR 未将所有事件联系在一起以揭示任何关系或模式。
本博文展示如何处理 EDGAR 文件并将其合并到 Amazon Neptune 中,以提取关系并提供有关其他事件的可重复模型。
数据库选项
在处理数据时,当今的技术人员有许多选择。下表显示了一些常见的数据类别和用例。
| 关系 | 键值 | 文档 | 内存 | 图形 | 时间序列 | ||
| 参照完整性 | 高吞吐量 | 存储文档和快速访问对任何属性的查询 | 具有微秒级延迟的按键查询 | 快速轻松地创建和浏览数据之间的关系 | 收集、存储和处理按时间排序的数据 | ||
| ACID 事务 | 低延迟 读取和写入 | ||||||
| 写时模式 | 无限扩展 | ||||||
| 常见用例 | 直接迁移、 ERP、CRM、财务 | 实时竞价、购物车、社交产品目录、客户偏好 | 内容管理、 个性化、移动 | 排行榜、实时分析、 缓存 | 欺诈检测、 社交网络、 推荐引擎 | IoT 应用程序 事件跟踪 | |
本博文使用两个数据库来处理数据库工作负载:Amazon DynamoDB 和 Amazon Neptune。DynamoDB 负责处理加载过程的协调。DynamoDB 是一个键值和文档数据库,用于提供个位数毫秒级性能。它是一种完全托管、多区域、多主、持久的数据库,具有内置的安全性、备份和还原以及内存缓存功能。这些特征可满足插入/选择操作的快速访问要求,并允许您使用其流传输功能来触发 AWS Lambda 函数。
Amazon Neptune 是一种高性能图形数据库,它快速、可靠且完全托管,可处理高度互连的数据集。它专为以毫秒级延迟存储数十亿个关系和查询图形而构建。Amazon Neptune 支持常见的图形模型“属性图”和 W3C 资源描述框架 (RDF),及其各自的查询语言 Apache TinkerPop Gremlin 和 SPARQL。
SPARQL 协议和 RDF 查询语言是一种 RDF 查询语言—数据库的语义查询语言,可以检索和操作 RDF 中存储的数据。
Gremlin 是 Apache TinkerPop 的图形遍历语言。它是一种函数式数据流语言,使您能够简洁地表达对应用程序属性图的复杂遍历(或查询)。每个 Gremlin 遍历都由一系列(可能嵌套的)步骤组成。其中一个步骤将对数据流执行原子操作。
您可以解析此信息以获取关键元素,这些元素将转换为用于呈现详细信息的节点(数据实体)、边缘(关系)和属性。
下图显示了一个双节点 Neptune 模型。

其中一个节点对应于控股公司;另一个节点是证券本身。节点关系来自 EDGAR 表格,它具有与持仓相关的属性。
SEC EDGAR 存储库包含由已增持、减持或获得公司股权的公司高管披露的股票持仓信息。此信息将该模型扩展为以下三节点模型。

这三个节点分别对应于证券的控股公司、证券本身和实益持股量。此基本模型反映了个别证券、共享购买和内幕活动的大规模活动。
您可以添加社交媒体、新闻和行业事件来进一步扩展该模型。下图显示了一个五节点模型。
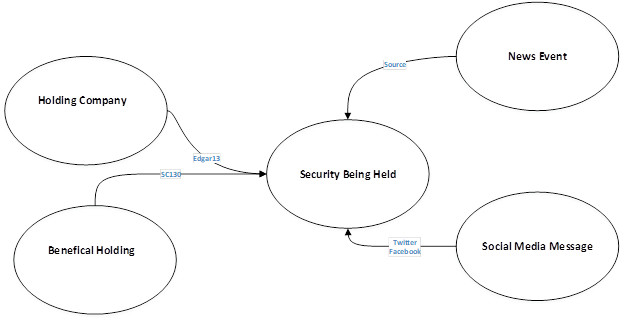
这些节点分别对应于证券持有人、证券、实益持股量、社交媒体和新闻事件。节点之间的关系来自 EDGAR 表格、新闻来源或社交媒体发起人。
该图形范例展示可通过使用数据元素内的连接以及从交叉连接中提取的信息得出哪些结论。借助此信息,您可以查看对于给定证券持仓量最大的多个实体之间的大额证券持仓和普通基础证券持仓情况。
使用 EDGAR 数据
您可以实施一个流程来从 SEC EDGAR 中提取有关持股的公开数据。本博文只关注个别公司的股份。该系统使用 AWS Lambda、Amazon SQS、Amazon DynamoDB 和 Amazon Neptune。Step Function将触发整个流程。下图展示了此流程。

AWS Lambda 函数与 EDGAR 网站相连。在步骤 1 中,服务将检索所需季度和年度的主索引。系统将解析主索引,其中包含与持仓相关的所有文档的 URL,然后将其插入 SQS 队列。
在步骤 2 中,记录将进入 Amazon SQS 队列,它会触发可根据需求进行扩展的 Lambda 函数。此 Lambda 函数将解析每个 EDGAR 文档,并提取控股公司和所持证券的相关数据。AWS Lambda 会将这些单独的记录插入 DynamoDB 表中(对于本博文,该表为 Edgarrecord)。
在步骤 3 中,Amazon DynamoDB 将流式传输表 Edgarrecord,并触发 AWS Lambda 函数来处理每条记录,并为每个 Neptune 边缘和节点创建格式化的新记录。
在Step Function中,有一个 AWS Lambda 函数,它将确认 SQS 队列上的所有处理和 DynamoDB 流传输均已完成。在步骤 4 中,此确认操作将触发最终的 Lambda 函数,它会处理 DynamoDB 表中的所有记录并加载 Neptune 数据库。
这会生成一个图形数据库,它记录了证券与大额持仓的公司(基于 SEC 数据)之间的联系。下图是您可以创建的图形数据库的视图。
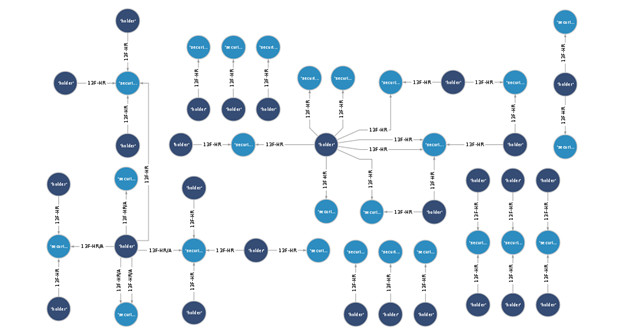
当数据完全加载后,您可以运行 Gremlin 查询来检查数据库。有关这些查询的详细信息,请参阅 GitHub 存储库。笔记本包含的示例数据不反映任何当前或以前的 SEC EDGAR 关系。
要确定在加载过程中创建的顶点数,请输入以下代码:
要确定所创建的边缘数,请输入以下代码:
要确定顶点上的边缘数,请输入以下代码:
小结
SEC EDGAR 数据库包含大量金融信息。您可以使用 Neptune 的图形模型来记录关系并映射共性,以了解 SEC EDGAR 公司之间的依存关系。
通过公开数据创建的模型只是一个构建块。您可以扩展它以显示问题关联、与证券相关的市场事件以及与证券相关的经济事件。我们在笔记本中包含了示例数据集,该笔记本位于 Amazon Neptune GitHub 存储库中。