亚马逊AWS官方博客
使用 Athena Federated Query 为 Tableau Server 提供多种数据源的统一管理和联合查询能力
如今大多数企业会采取多样的数据库引擎来满足业务不同的需求,除了传统关系型数据库 RDS 外,选择 NoSQL 数据库(如 DynamoDB 或 DocumentDB)存储需要快速访问且灵活 schema 要求的属性数据;选择 Neptune 构建知识图谱或社交网络关系图;选择 ElasticSearch 做日志的查询检索等等。多样的数据库使得跨数据源进行统一的数据分析变得更有挑战性。
Amazon Athena 是一种无服务器式的交互式查询服务,让您能够轻松使用标准 SQL 分析 Amazon S3 中的数据,而无需重复的复制和存储数据。 联合查询(Athena Federated Query)是 Athena 的一项新功能,通过运行单个 SQL 查询,可以分析多个数据源的数据,如 MySQL, PostgreSQL (等与 JDBC 兼容的关系型数据库),Redis, DynamoDB,Apache HBase, Amazon DocumentDB, Amazon Redshift, ElasticSearch, CloudWatch logs 等等。对于暂时还没有提供的数据源连接器,您也可以使用 Athena Query Federation SDK,构建自定义数据源的连接器。Athena 数据源连接器运行在 Lambda 上,无需管理任何基础设施。

Athena 可以直接与流行的 BI 工具相连,如 Tableau, Quicksight 等,可跨关系、键值、文档、内存、搜索、图形进行数据查询和报表展现,而无需为 BI 工具单独添加并管理多个数据源。此外,对于某些 BI 工具并不原生支持的数据源,通过 Athena 联合查询可以突破此瓶颈。
本文以 CentOS 版本的 Tableau Server 为例,主要介绍如何通过 Athena 集成 Tableau 并不支持的数据源 (如 ElasticSearch,DynamoDB),并且利用 Athena单一数据来源,实现多数据库跨表读取与查询。
本文适用的场景
- 一些企业级用户需要使用Tableau Server做数据源发布的权限管控,而不是简单的使用Tableau Desktop直接链接数据源。然而在这样的需求下,部分 Tableau Server版本,如Tableau Server on Linux,不支持 ElasticSearch 作为数据源 [出处] ;另外,某些 Tableau 版本存在与 ElasticSearch 的兼容性问题。两种情况均可通过本文实现Tableau Server连接查询 ElasticSearch 的数据。
- 以 DynamoDB 为示例,演示如何通过 Athena 接入 Tableau Server ,并与其他数据库一起做联合查询。
- Athena 作为 BI 工具的单一的数据来源,实现数据的统一管理。
架构图
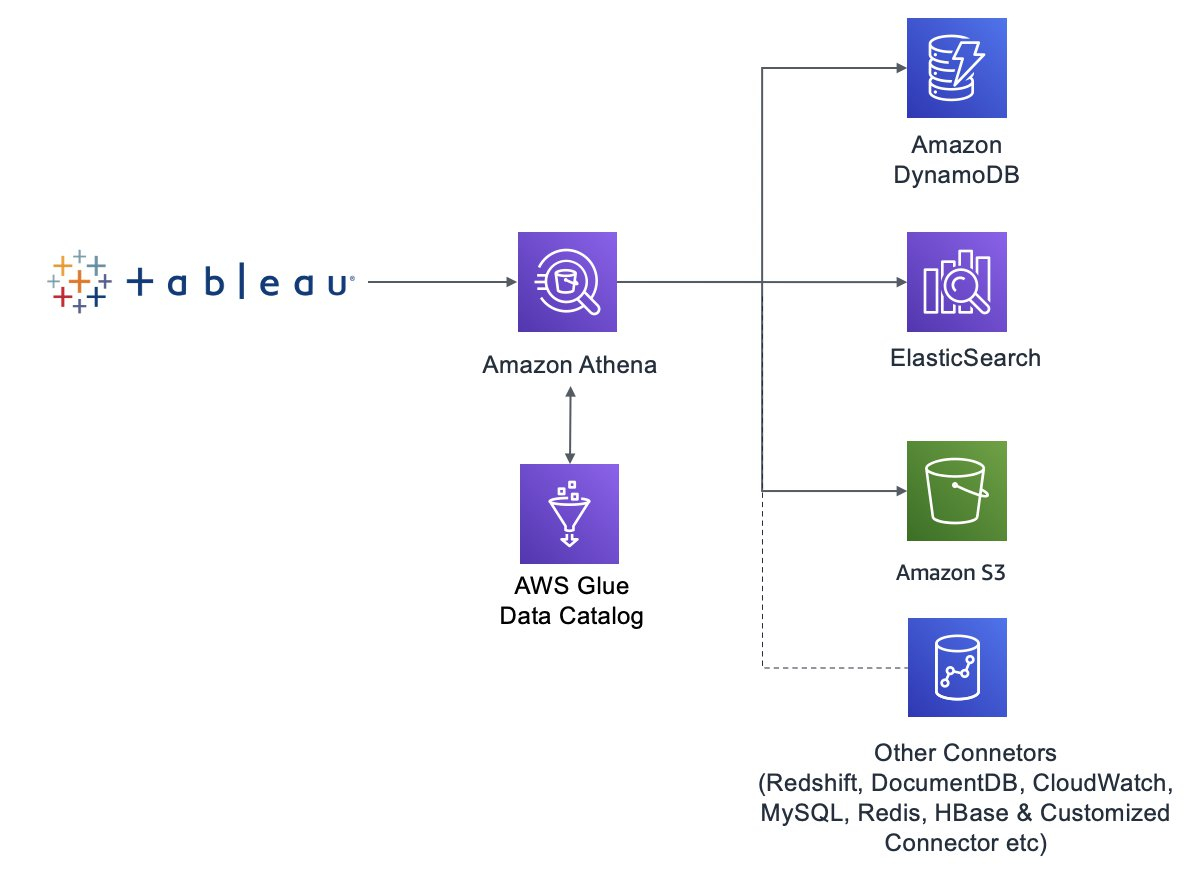
在 Tableau 中添加 Athena 作为数据源,Athena 以 Glue 作为 Data Catalog。
通过 Athena 联合查询,跨数据源做数据查询,并将结果存储在 Amazon S3 中以备随后使用。本文以 DynamoDB 以及 ElasticSearch 为例,对于 Athena 支持的其他数据源,方式相同,本文不再赘述。
测试环境
- 本文使用由光环新网运营的亚马逊云科技中国(北京)区域
- EC2:CentOS 7 on marketplace
- ElasticSearch版本: 7.10
- Tableau Server on Linux (2021.3.3)
测试步骤
步骤一:创建ElasticSearch域并导入示例数据
- 我们首先在Amazon OpenSearch服务中 (前身为 Amazon Elasticsearch Service)创建一个ElasticSearch域。域名根据实际情况自己指定,部署类型选择开发测试,版本选择 7.10。
注:Amazon ElasticSearch Service 已改名为 Amazon OpenSearch,有关于改名原因以及更多 OpenSearch 的介绍,请参考此页面。

- 在测试环境中实例类型选择的是一个
t3.medium.search节点,其他选项默认即可。在真实环境中可以根据需求自行调整实例类型和节点数。

- 为了方便展示,我们选择了公有访问权限。在生产环境中,强烈建议采用 VPC 访问方式部署,从而带来最佳的安全性。 在精细访问控制中启动精细访问控制并创建主用户,请记录好主用户名和密码,我们会在后续的步骤中用到。
注:在 VPC 访问模式下,需要注意 Tableau Server 与 ElasticSearch 所在子网的网络连通性,建议放置在同一个 VPC 中。

- 配置域级别的访问策略,编辑访问策略的JSON文档,需要修改的地方如下图箭头所示:

注:如希望使用 Kibana,在 Action 处,需修改为 “es:ESHttp*”
- 创建完成后集群运行状态会显示为绿色,记录下域端点的URL,后续步骤中会使用到.

- 在本地使用批量方式将数据导入到ElasticSearch中,index名称为account
请将:
- ‘athena:P@ssw0rd ‘替换为自己设置的ElasticSearch精细访问控制中的主用户名和主密码
- https://search-tableau-athena-opensearch-2euxiki3q2i5e123phpfwzzhxm.cn-north-1.es.amazonaws.com.cn 替换为自己的ElasticSearch的域端点URL.
- accounts.json 为解压后的示例数据文件
步骤二:在Secrets Manager服务中保存ElasticSearch的主用户名和密码
Secrets Manager服务允许您将代码中的硬编码凭证(包括密码)替换为对 Secrets Manager 的 API 调用,以便以编程方式检索密钥。这有助于确保密钥不会被检查代码的人员泄露,因为密钥不再位于代码中。此外,您还可以配置 Secrets Manager 以根据指定的计划自动轮换密钥。这样,您就可以将长期密钥替换为短期密钥,从而显著降低泄露风险。
Athena ElasticSearch Connector会调用Secrets Manager的API获取ElasticSearch的主用户名和密码,因此我们在部署Athena ElasticSearch Connector之前需要先将该用户名和密码储存到Secrets Manager服务中。
- 点击橘黄色的“Store a new secret” 按钮

- 选择 “Other type of secrets”之后,注意要使用Plaintext方式填入用户名和密码,格式为 username@password。本文中使用的用户名是athena,密码是P@ssw0rd,因此最终填写为athena@P@ssw0rd。

- 在Secret name一栏填写自己secret的名称,本文命名为elasticsearch-secret,这个名字在后面的部署过程中会用到,请记录下来。后续步骤均接受默认设置,点击 Next 即可,直到最后一页点 Store 保存。

步骤三:部署 Athena ElasticSearch Connector
- 在服务页面的文本框输入serverless, 系统会自动联想出Serverless Application Repository,点击该服务。使用Serverless Application Repository您可以轻松地发布Serverless应用程序,将其与整个社区公开共享,或在团队中或在您的组织中私下共享。我们接下来要部署的Athena ElasticSearch Connector即是亚马逊官方通过Serverless Application Repository发布出来的

- 在可用应用程序中选择公用应用程序,并在搜索框输入AthenaElasticsearchConnector。点击该应用进入部署环节。

- 在这一页中您可以浏览应用部署模版的代码,以及许可证相关的信息。所有和部署相关的参数都在右下角的应用程序设置中配置,按照后面的提示配置完成后点击橘黄色的部署按钮。
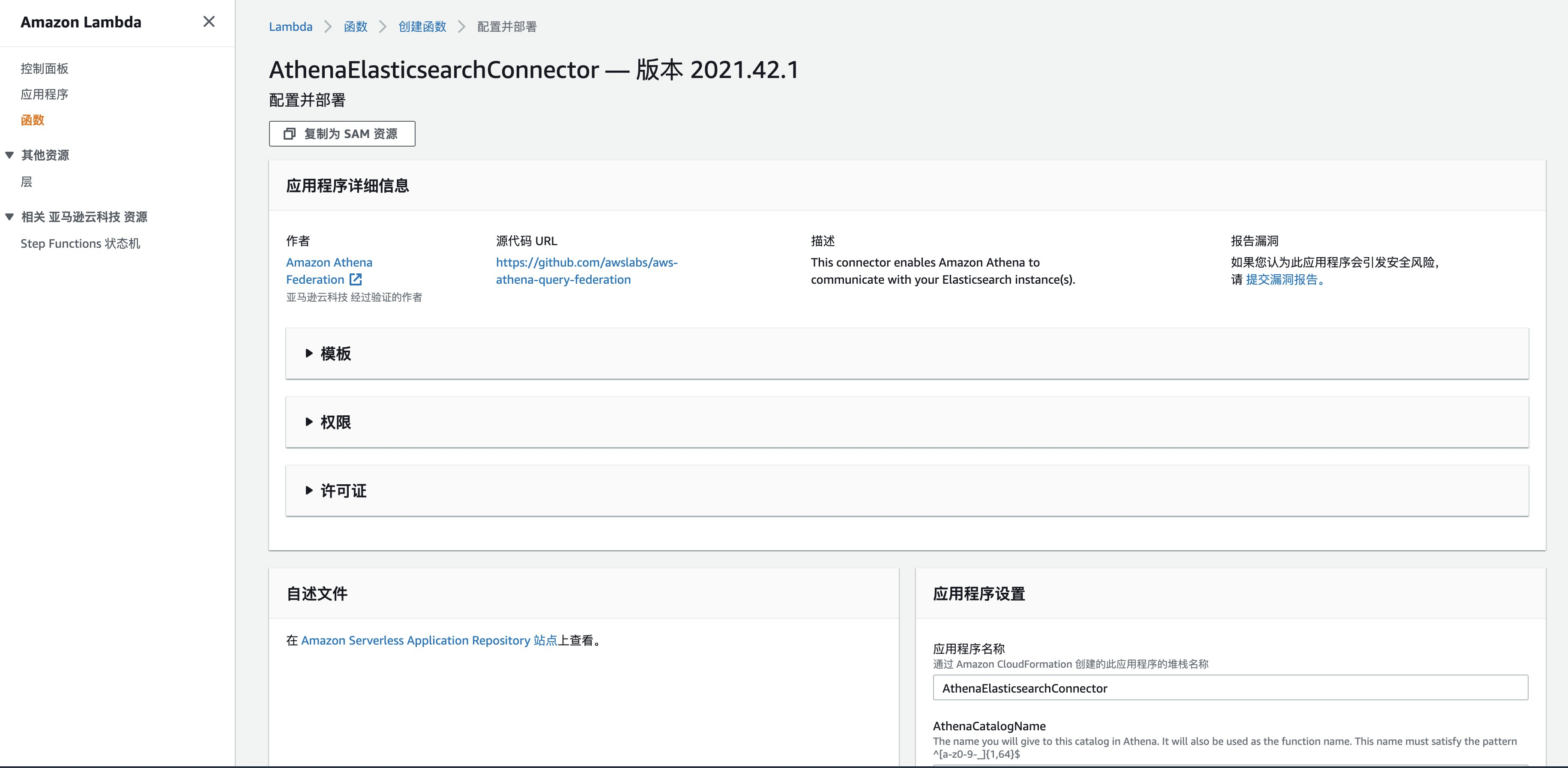
- 应用程序名称使用默认即可,也可自己指定
- AthenaCatalogName 会是Athena中的catalog名称,同时也是部署完成后Lambda函数的名称。这里需要注意的是起名规则需要匹配截图中的要求,基本上在起名的时候使用小写字母和数字即可。
- SecretNamePrefix 这里填入我们之前在Secrets Manager中创建的secret名称,这样模版会自动赋予Lambda函数相应的权限去读取这个secret.
- SpillBucket 选择一个现有的S3桶或者新建一个桶都可以,这个桶的作用主要是当Lambda获取到的数据过大的时候作为数据的存储空间的。

- AutoDiscoverEndpoint改为false,我们会在后面手动指定ElasticSearch的访问路径以及用户名密码。
- DomainMapping 是设置ElasticSearch的访问路径以及用户名密码的地方,格式如图所示。其中等号左边为ElasticSearch的域名,等号右边的${secret-credentials}中填写我们之前在Secrets Manager中创建的secret名称,最后面是ElasticSearch的域端点URL,中间用冒号分割。
- SpillPrefix 是在SpillBucket中指定一个prefix路径
- 我确认系应用程序将创建自定义IAM角色 需要勾选上

- 当状态变为绿色的”Create complete“之后即已部署完成。您可以进入Lambda服务中检查对应的Lambda函数是否已经创建,并且通过修改这个函数的环境变量可以随时修改我们前面设置的各个参数。


- 接下来可以进入到Athena服务中,简单测试一下 Athena 是否可以读到 ElasticSearch 的数据,需要注意的是自己的Athena引擎版本是否已升级到version 2.。其中athena-elasticsearch-connector是lambda函数名称,tableau-athena-opensearch是ElasticSearch域名,account是index名。您可以按照您之前的命名方式做相应的修改。

您也可以进一步在Athena中为这个数据集创建Database和Table,这里我们在Athena的default数据库中创建了一张叫做account的表,并且以PARQUET格式存在S3桶里面,这样可以大大加快查询速度。
步骤四:Tableau Server 的安装及设置
- 启动 EC2 (本文使用 Centos 7) ,并注意安全组开启 tableau 所需要的必要端口。
- 8850 端口 (用于TSM访问)
- 22 端口 (用于ssh访问)
- 80端口(用于Tableau Server访问)。
- 安装 Tableau Server 。Tableau 有很多版本可以供用户选择,参考此页面做版本选择。如选择的是 Tableau CentOS版本,下面命令为基本安装步骤,详细安装指南,建议参考 tableau 官方安装文档。
- 在此页面下载连接 Athena 所需要的驱动,同样挪到
/opt/tableau/tableau_driver/jdbc/文件夹下
tsm restart
# 为了使 driver 生效
- 访问
http://<EC2-IP-Address>使用创建的admin 密码登录到 Tableau Server。
步骤五:Explore tableau
- 在访问页面,打开 Explore – 创建新 Project (或使用 Default Project) – New Workbook 。在 Connectors 中,选择 Athena (如有报错,请检查是否安装了 Athena driver)

- 设置连接信息。

- Server:
- Port: 443
- S3 Staging Directory: 自定义设置Athena 的S3的路径, 如 s3://<S3-bucket-name>/elasticsearch/
- Access Key & Secret Access Key: 都为必填。如未曾使用过,请在此页面查询如何创建 AKSK (选择 IAM服务— User —security credentials 的tab 下 — 创建 Access key)
- 连接成功后,可以在左侧看到我们之前创建的 ElasticSearch 的表 account,选择此表格拖拽到 data 区。可以在此页面上查看 table metadata 信息,以及 data preview。

步骤六:创建图表
左下方选择 sheet tab,可以自由的选择目标图表所需要的数据,以及希望展示的图表类型。每个 sheet 为一个图表。用上文提供的示例数据,图表示例如下。
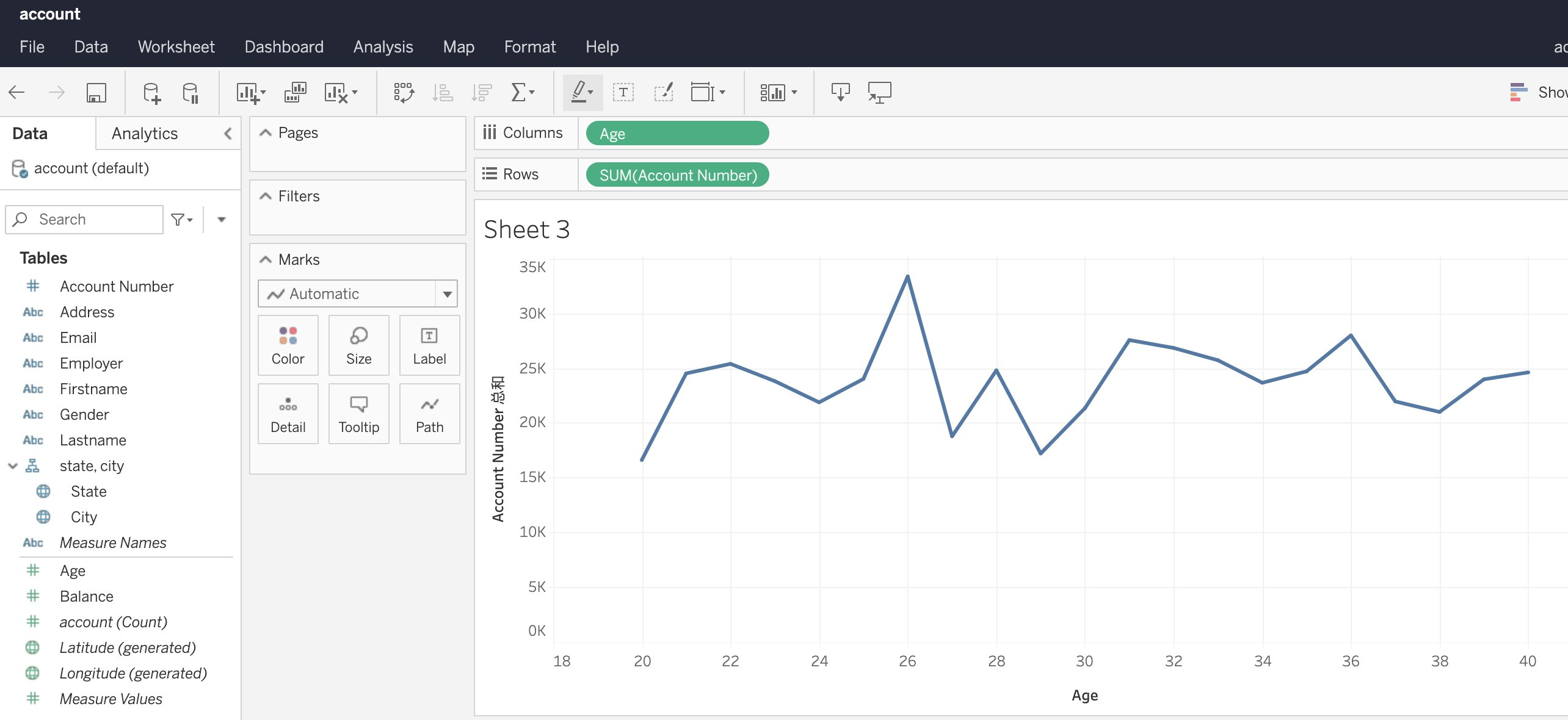
例一:统计会员年龄区间
将age以及SUM (account number) 分别拖拽至行和列。
例二:统计会员的男女比并做饼状图展示
- 选择图标类型为 PIE,分别将 gender、account number 拖拽至 marks 区域,将 account number 信息 measure 成 sum 值。
- 区分颜色:将 gender 拖拽至 color。
- 饼状图展示男女人数统计: 将 SUM(account number) 拖拽到饼状图 SHOW ME 中。
- 打开 label。此时鼠标移动至图标,可以看到具体男女会员数量。

例三:会员人数地图热力图
- 将经纬度信息拖拽至 columns 和 rows 中
- 将 state 以及 account number 信息拖拽至 marks,并且选择图标类型为 MAP。将 account number 聚合为 SUM。
- 区分颜色:将 state 拖拽至 color

- 展开至 city,做城市人数统计

步骤七:多表联合查询
在上文中,我们通过 Athena 查询到单个数据源 ElasticSearch 中的数据。 Athena 联合查询也可以方便的实现多数据源的跨表查询。本文以 DynamoDB 为例,演示如何将做联合查询。
数据准备
- 在 DynamoDB table 中,我们准备了一些数据,以模拟记录用户所购买的产品的具体信息。accountNumber 为用户 userID 标记位。随机抽一条数据如下,表示 206 ID 的用户购买了 Keyboard 类、白色、“Handmade Rubber Computer” 产品。 点击此处下载 (如您有可用的已有数据,请跳过此步骤)
- 参考此 RUBY 代码将数据 load 到 DynamoDB table 中。 (注:如简单测试,可直接使用控制台手动几行输入;如已有数据,请跳过此步骤)
数据查询
- 部署 Athena DynamoDB connector,类似于在步骤三中部署 Athena ElasticSearch connector 的方法,搜索并进入 Serverless Application Repository,在可用应用程序中选择公用应用程序,并在搜索框输入
serverlessrepo-AthenaDynamoDBConnector,输入splitBucket,AthenaCatalogName,SpillPrefix 等参数(参数定义详见步骤三),勾选确认,点击部署。 - 替换 S3-bucket-name 为自己的桶名,在 Athena 当中运行以下命令建表
- 刷新 Athena,可以看到 table 信息。在 Tableau 中刷新,同样可以看到此 table。
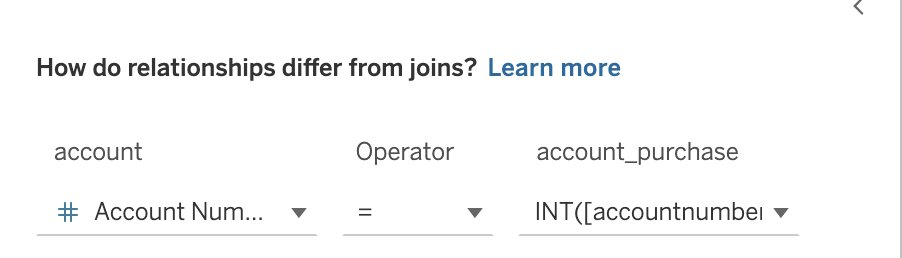
- 通过 Tableau relationship 建立 tables 之间的关联。将 account_purchase 信息拖动到画布中,填写关联 key 值。
注意,此时可能会报数据类型不同无法关联的错误,这时只需要转换数据类型,比如在此例中,将 dynamodb 表的 accountnumber 修改做INT转换。

5. 此时,在 sheet 面板,可以随意拖拽两个table的属性值以及聚合值,跨 ElasticSearch 和 DynamoDB 做查询。如,选择条形图,将 gender 和 SUM(product) 组合,即可统计出男性女性分别购买的产品数量合。

- 下载 S3 中的示例点击流数据
步骤八:建立自定义 dashboard
点击 dashboard,创建 dashboard,左侧 tab 为所创建的 sheet,可以自由选择拖拽至画板区、控制大小、标题命名等等,自定义后点击保存即可。

结论
本文使用 Athena 联合查询 (Athena Federated Query), 解决了某些 Tableau Server 版本不直接支持部分数据源连接的问题 (如ElasticSearch), 并且进一步实现了使用 Tableau Server 进行多数据源 ElasticSearch , DynamoDB 的联合查询需求,您也可以参照此文章进一步添加其他数据源,如关系型数据库 RDS 等。
参考链接
- https://docs.aws.amazon.com/athena/latest/ug/connect-data-source-serverless-app-repo.html
- https://serverlessrepo.aws.amazon.com/applications/us-east-1/292517598671/AthenaElasticsearchConnector
- https://github.com/awslabs/aws-athena-query-federation
- https://docs.amazonaws.cn/opensearch-service/latest/developerguide/gsgupload-data.html
- https://docs.amazonaws.cn/opensearch-service/latest/developerguide/sql-support.html
- https://help.tableau.com/current/guides/everybody-install-linux/en-us/everybody_admin_install_linux.htm
- https://help.tableau.com/v2021.3/server/en-us/get_started_server.htm