亚马逊AWS官方博客
使用 AWS Batch 轻松玩转遥感计算
遥感应用简介
经过半个多世纪的发展,遥感技术及多领域应用已进入新的阶段。它不但可以被动接收地物反射的自然光,还可以接收地物发射的长波红外辐射,并能够利用合成孔径雷达和激光雷达主动发射电磁波,实现全天候的对地观测。遥感技术与国民经济、生态保护和国防安全的关系也越来越紧密,比如土地资源调查、生态环境监测、农业监测与作物估产、灾害预报与灾情评估、海洋环境调查等,包括与日常生活息息相关的天气预报、空气质量监测、电子地图与导航等活动,遥感都发挥了重大作用。目前,遥感科技已显现出高空间分辨率、高光谱分辨率、高时间分辨率的“三高”新特征,并开拓了更多的应用新领域。
遥感技术应用痛点
遥感成像方式的多样化以及遥感数据获取能力的增强,导致遥感数据的多元化和海量化。然而,现有的遥感数据获取、影像分析和海量数据处理还面临着一些挑战。
• 遥感数据量大、数据获取困难。国内科研机构经常使用的Landsat 、MODIS、Sentinel-1、Sentinel-2等大量数据存储在国外,数据回传到国内IDC和超算中心面临困难。
• 海量的遥感数据分析对计算资源有更高的要求。IDC和超算中心上千台主机计算环境的运维和管理也成为科研工作者面临的挑战。要花费精力在业务价值之后的环境管理上面。
方案计算架构
本方案架构为客户在 AWS 云上快速部署遥感数据计算提供指导。方案以计算遥感数据 NDVI 为例,介绍如何使用 AWS Batch、ECS、ECR、S3 等服务,完成整个计算流程。帮助您轻松地在 AWS 开启遥感数据计算旅程。

本架构主要使用到的服务简介:
- AWS Step Functions : AWS 平台提供的无服务器(Serverless)的任务编排服务
- AWS Lambda: AWS 平台提供的无服务器(Serverless)的函数计算服务
- AWS Batch: AWS 平台提供的批量计算服务
- Amazon ECR: AWS 平台提供的容器镜像仓库服务
- Amazon DynamoDB: AWS 平台提供的 NoSQL 数据库服务
- Amazon SNS:AWS 平台提供的消息通知服务,发送邮件、短信等通知
- Amazon S3: AWS平台分布式对象存储服务。提供 99.999999999% 的持久性
- Amazon CloudWatch:AWS平台提供的监控与日志收集服务
方案架构实现流程介绍:
- 构建计算遥感数据使用的自定义容器镜像,并存储到AWS ECR容器镜像仓库
- 定义AWS Batch计算环境和计算任务,以运行自定义容器镜像
- 定义AWS Lambda 执行计算任务初始化工作
- 定义 AWS SNS 服务,邮件订阅接收消息
- 定义 AWS Step Functions 状态机,来编排任务流。调度 AWS Lambda 进行任务初始化,并行调度AWS Batch 计算任务实现遥感数据计算,调度AWS SNS接收任务执行结果通
- 启动AWS Step Functions 状态机执行计算,监控任务执行过程
基于AWS Batch开展遥感计算优势 - AWS Open Data(https://registry.opendata.aws/)公共数据集中提供了大量的实时和历史卫星遥感数据,并且数据类别还在不断的增加。用户在 AWS 平台可以快速下载遥感数据,降低数据获取时间成本。同时也可以在数据资源所有区域直接开启计算资源进行分析,减少数据复制时间与存储成本。
- 利用AWS提供的批量计算服务AWS Batch,用户可快速的构建自定义的遥感数据计算分析环境,批量启动研究所需的计算资源,计算完成后资源自动释放,无需花费时间精力运维计算环境。
- 计算资源使用AWS Spot实例大量节约计算成本。
基于Batch的遥感数据计算实验
1. 实验内容简介
本计算实验使用AWS Open Data中的 Landsat8 卫星遥感数据。关于 AWS Open Data请参考(https://registry.opendata.aws/)。遥感数据处理流程环节较多计算过程相对复杂,包括滤波、裁剪、辐射校正、波段拆分、波段融合、NDVI等。本实验以计算NDVI为例,帮助大家了解如何使用 AWS Batch 对遥感数据进行处理。
2. 实验过程
准备条件: 需要开通AWS 中国区或者 AWS Global 账号
2.1 创建Lambda函数
Lambda 是 AWS 平台推出的函数计算服务,通过 AWS Lambda,无需预置或管理服务器即可运行代码。借助 Lambda,您几乎可以为任何类型的应用程序或后端服务运行代码,而且完全无需管理。在本实验中使用lambda来完成计算过程记录DynamoDB 表初始化工作。 在生产应用中也可以根据需要增加任务分解等功能到lambda中实现。
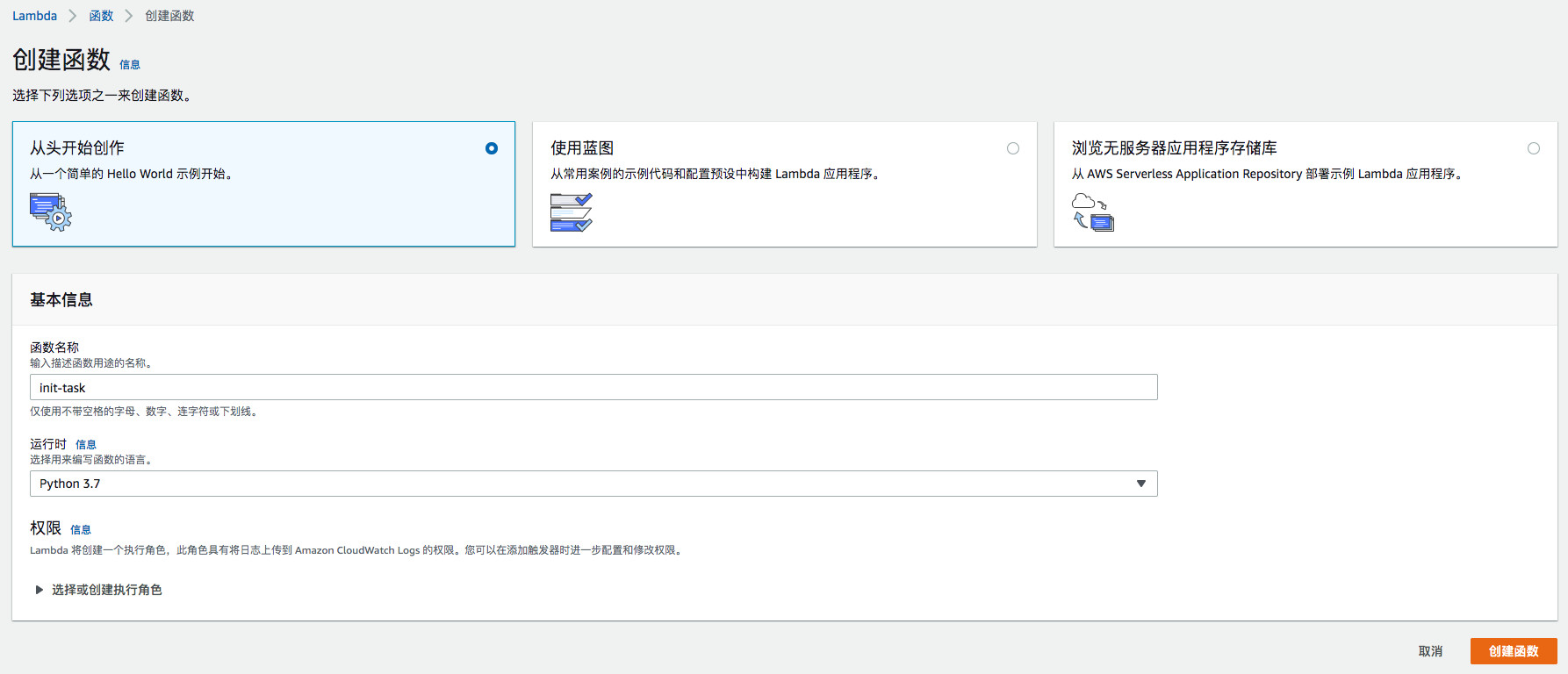
新建Lambda 函数 init-task,运行时选择Python 3.7:
将Lambda函数内容替换为:
import json
import boto3
dynamodb_client = boto3.client('dynamodb')
def lambda_handler(event, context):
table_name = 'task-log'
existing_tables = dynamodb_client.list_tables()['TableNames']
if table_name not in existing_tables:
response = dynamodb_client.create_table(
AttributeDefinitions=[
{
'AttributeName': 'TaskID',
'AttributeType': 'S'
}
],
TableName='task-log',
KeySchema=[
{
'AttributeName': 'TaskID',
'KeyType': 'HASH'
}
],
BillingMode='PAY_PER_REQUEST')
print(response)
print(event)
return event
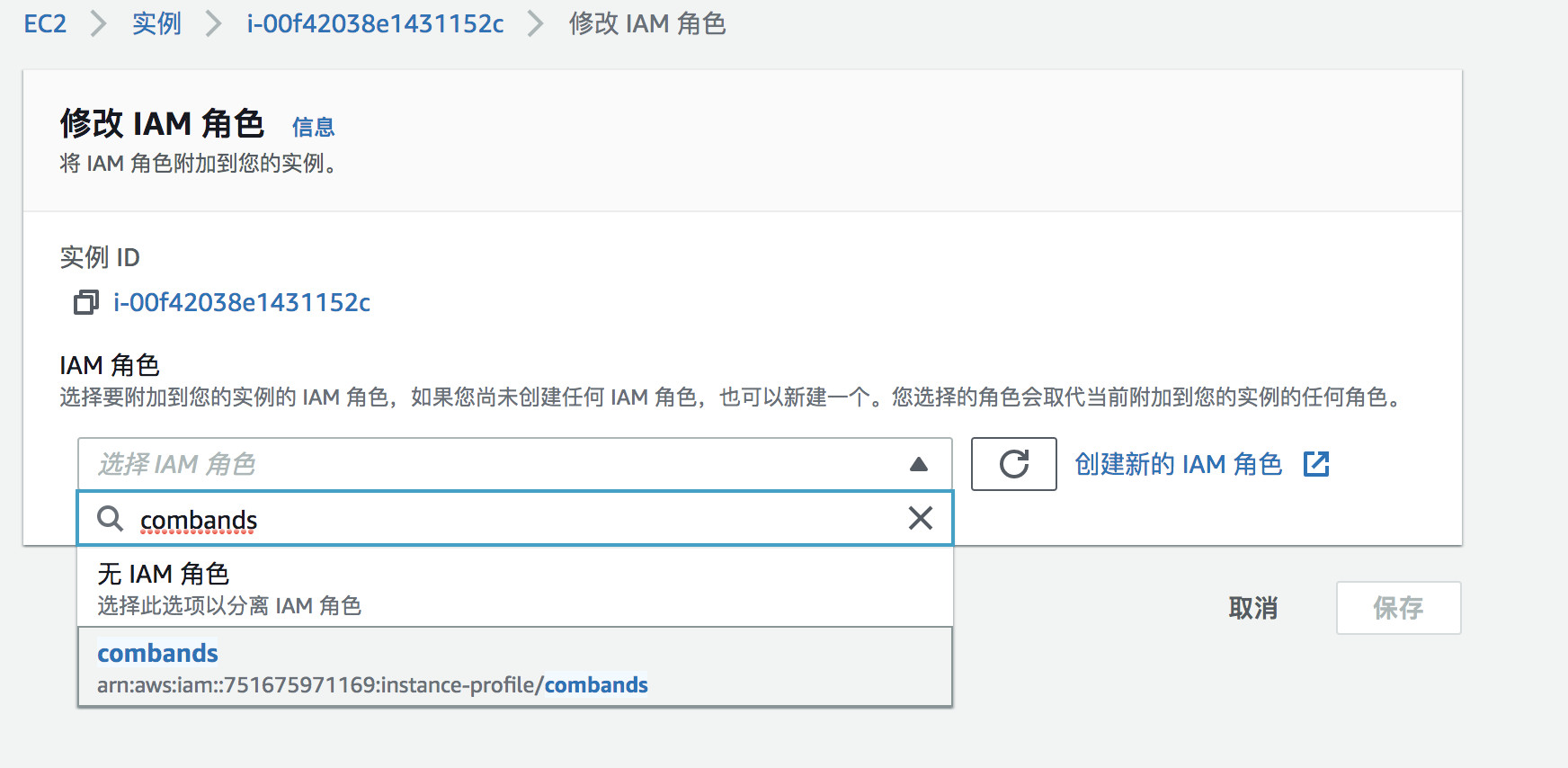
为此 Lambda 函数增加创建DynamoDB 表和写入数据权限:
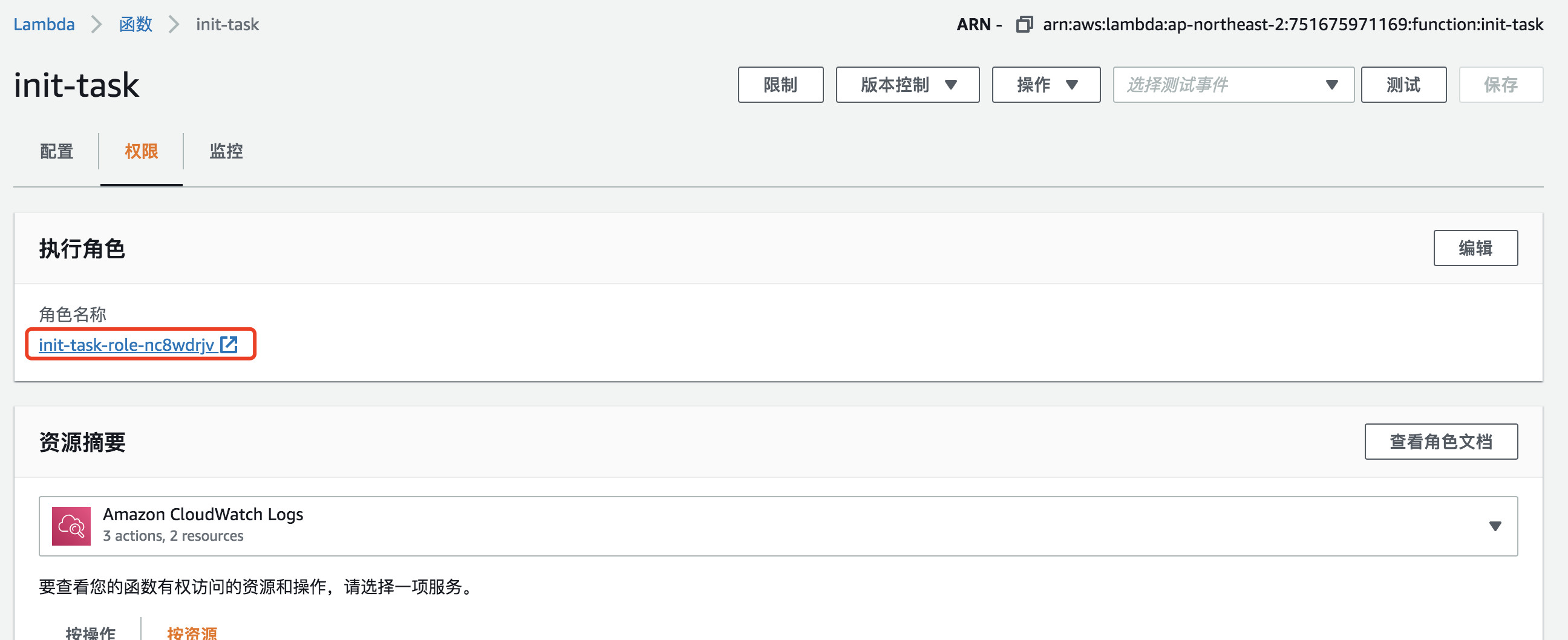
点击执行角色名称 URL,导航到IAM服务中,点击“附加策略” ,增加DynamoDB 的读写权限。

2.3 制作容器镜像
准备环境:打开AWS Console 创建一台EC2虚拟机,具体步骤如下:
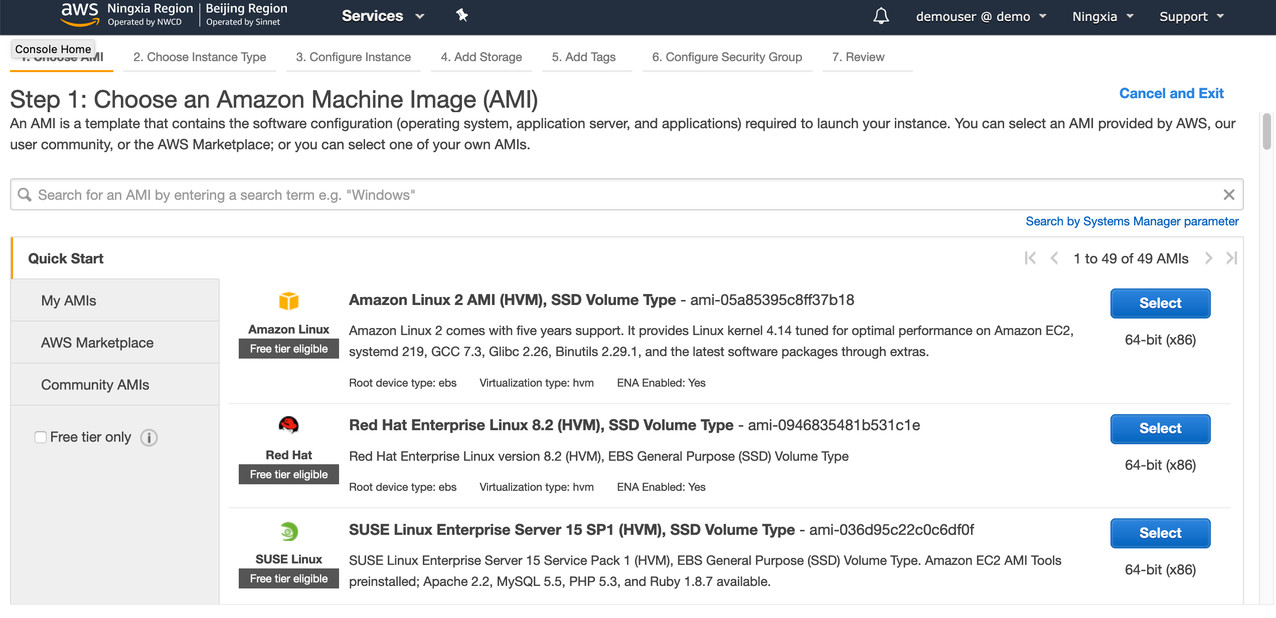
选择Amazon Linux 2 AMI(HVM)



创建角色并与EC2绑定,目的是为了给EC2授权。
创建角色:
打开IAM服务,并执行创建角色,如下图:




将角色绑定到EC2实例
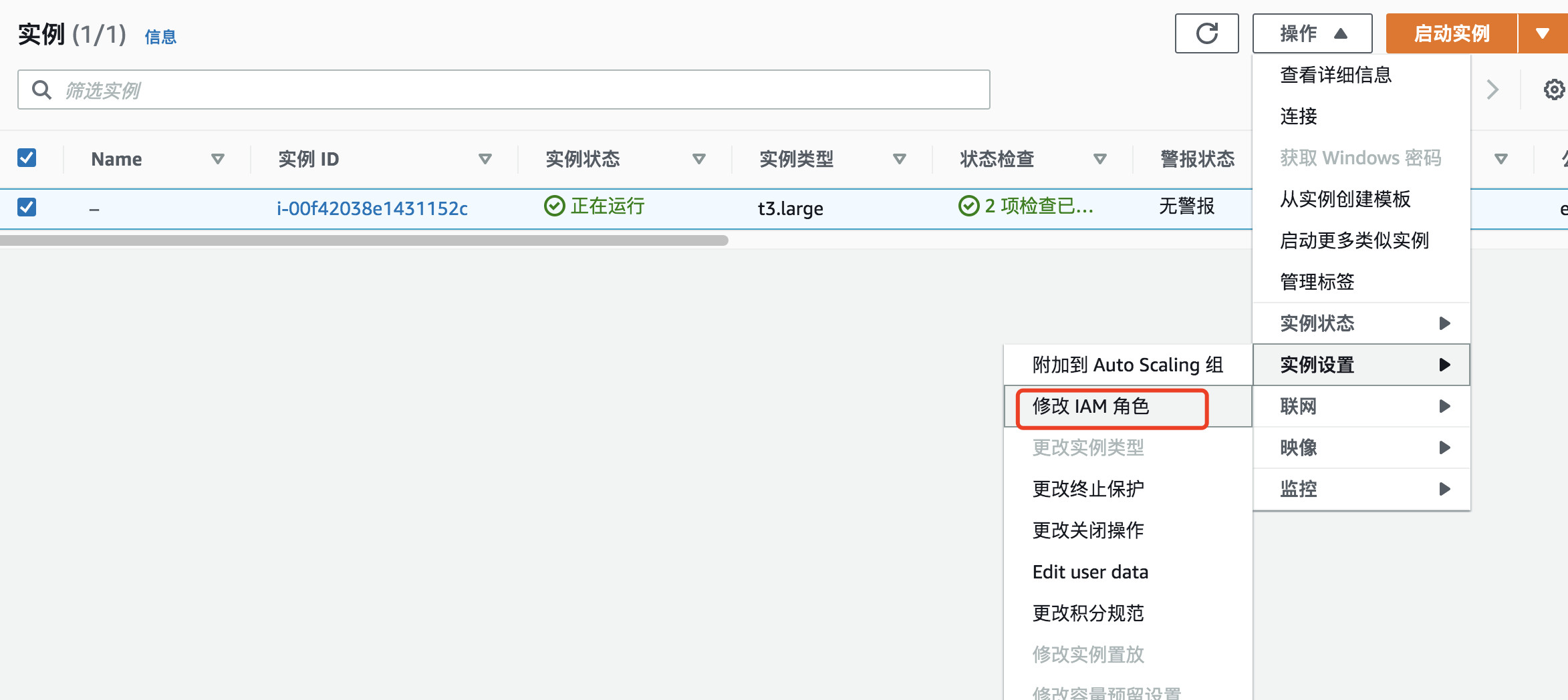
选择上一步创建的角色:
登录EC2并安装Docker软件
sudo yum update -y
sudo yum install docker
sudo service docker start
新建目录,并准备制作镜像文件:
mkdir combands
新建requirements.txt文件,文件内容如下:
boto3
在S3 服务中新建bucket用来存储计算过程和结果数据,bucket 名称是全球唯一的,需要自定义。bucket所在区域请选择方案实验所在的区域。

新建combands.py文件,内容如下:
# -*- coding: utf-8 -*-
import os
from osgeo import gdal
import boto3
import time
def input_log(files,date,success):
dynamodb_client = boto3.resource('dynamodb',region_name=region)
table = dynamodb_client.Table('task-log')
exec_time=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
TaskID=str(files)+"-"+str(date)
response = table.put_item(
Item={
'TaskID': TaskID,
'files': files,
'date': date,
'exec_time': exec_time,
'result':success
}
)
return response
env_dist = os.environ
print(env_dist.get('files'))
print(env_dist.get('date'))
print(env_dist.get('output_bucket'))
print(env_dist.get('region_name'))
region=env_dist.get('region_name')
files=env_dist.get('files')
strdate = env_dist.get('date')
bucketname=files.split('//')[1].split('/')[0]
objdir='/'.join(files.split('//')[1].split('/')[1:])
output_bucket=env_dist.get('output_bucket')
s3_client = boto3.client('s3',region_name=region)
s3_client.download_file(Bucket=bucketname,Key=objdir+'B02.jp2',Filename='B02.jp2',ExtraArgs={'RequestPayer':'requester'})
s3_client.download_file(Bucket=bucketname,Key=objdir+'B03.jp2',Filename='B03.jp2',ExtraArgs={'RequestPayer':'requester'})
s3_client.download_file(Bucket=bucketname,Key=objdir+'B04.jp2',Filename='B04.jp2',ExtraArgs={'RequestPayer':'requester'})
print('download files successful')
#os.chdir(r'D:\')
band1_fn = 'B02.jp2'
band2_fn = 'B03.jp2'
band3_fn = 'B04.jp2'
outputfile='sentinel_l2a_'+strdate+'_RGB.tif'
in_ds = gdal.Open(band1_fn)
#print(in_ds)
in_band = in_ds.GetRasterBand(1)
print('*******************************')
#print(in_band)
gtiff_driver = gdal.GetDriverByName('Gtiff')
out_ds = gtiff_driver.Create(outputfile,in_band.XSize,in_band.YSize,3,in_band.DataType)
out_ds.SetProjection(in_ds.GetProjection())
out_ds.SetGeoTransform(in_ds.GetGeoTransform())
in_data = in_band.ReadAsArray()
out_band = out_ds.GetRasterBand(3)
out_band.WriteArray(in_data)
in_ds = gdal.Open(band2_fn)
out_band = out_ds.GetRasterBand(2)
out_band.WriteArray(in_ds.ReadAsArray())
out_ds.GetRasterBand(1).WriteArray(gdal.Open(band3_fn).ReadAsArray())
out_ds.FlushCache()
for i in range(1,4):
out_ds.GetRasterBand(i).ComputeStatistics(False)
out_ds.BuildOverviews('average',[2,4,8,16,32])
del out_ds
#upload result data to S3
s3_client.upload_file("./"+outputfile,output_bucket,strdate+'/'+outputfile)
print('upload files successful')
#log result into ddb log table
log_resp = input_log(files,strdate,"success")
print("input log successful")
print('Task Finished')
创建Dockerfile,内容如下:
vim Dockerfile
FROM ubuntu:trusty
COPY requirements.txt /tmp/requirements.txt
# Install required software via apt and pip
RUN sudo apt-get -y update && \
apt-get install -y \
awscli \
python \
python3-pip \
software-properties-common \
&& add-apt-repository ppa:ubuntugis/ppa \
&& apt-get -y update \
&& apt-get install -y gdal-bin \
&& apt-get install -y python3-gdal \
&& apt-get install -y python3-numpy \
&& pip3 install --requirement /tmp/requirements.txt
# Copy the script to Docker image and add execute permissions
COPY combands.py combands.py
RUN chmod +x combands.py
2.4 把容器镜像推送到ECR
从控制台打开AWS ECR服务,创建镜像存储库:

创建完成后,进入combands存储库,点击“查看推送命令”,获取登录ECR命令和推送镜像到ECR的命令。

切换到root用户
sudo su
以此执行下图中的4条命令,完成构建镜像并推送到ECR的过程。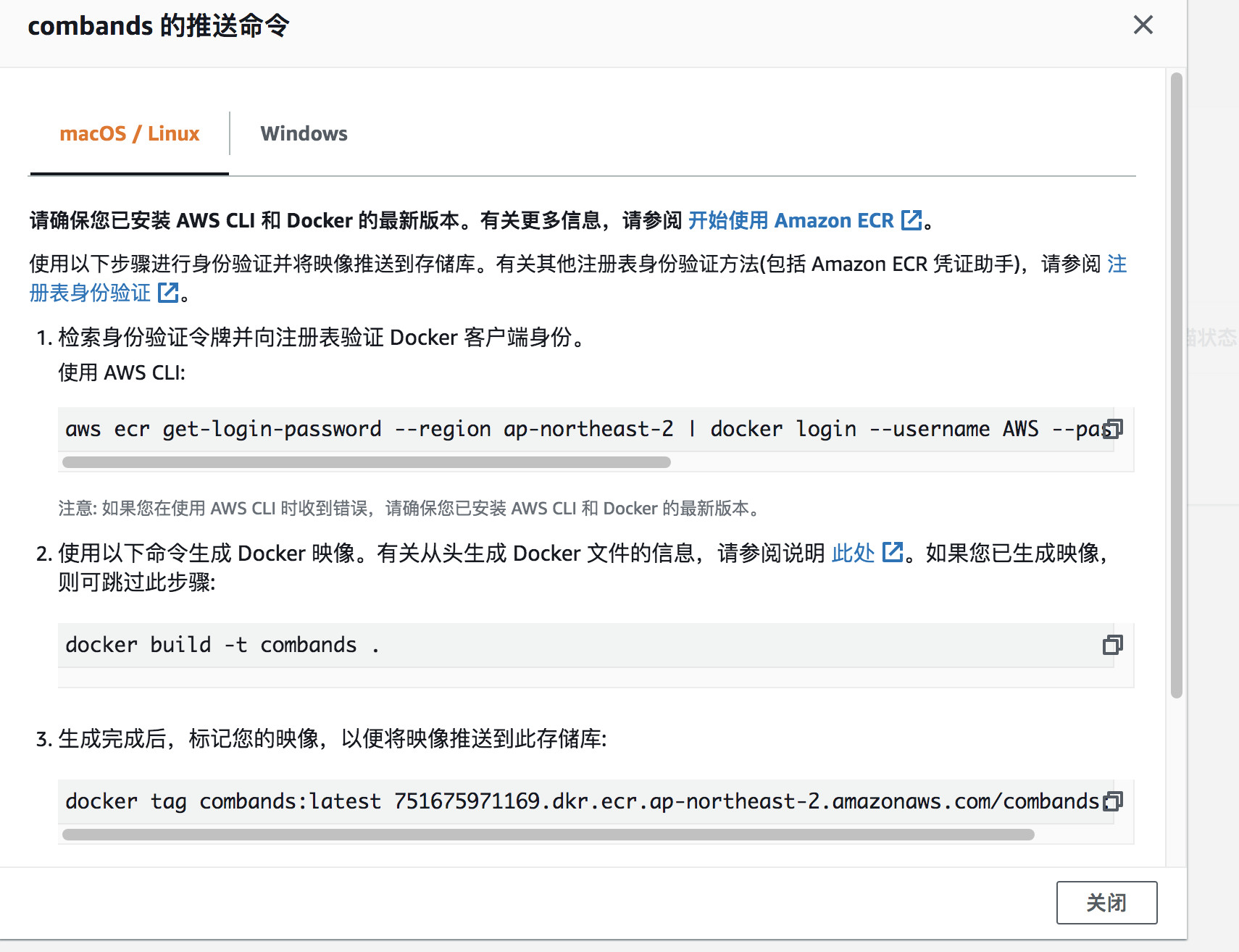
2.5 制作EC2启动模版(可选)
针对一些特定的场景,如需要指定运行环境EC2的EBS大小,或者需要安装较大的工具/软件等情况。建议选择自定义EC2运行环境。
自定义运行环境需要通过制作启动模版来实现。制作启动模版是标准化过程,步骤请参考。
https://docs.amazonaws.cn/AWSEC2/latest/UserGuide/ec2-launch-templates.html#create-launch-template-define-parameters
2.6 AWS Batch 任务设置
2.6.1 设置计算环境
登录AWS Console,打开AWS Batch service
创建计算环境部分:

配置计算资源部分截图:只需要设置所需vCPU数和最大vCPU数,其他默认即可。如果并行运行作业量大,可以根据实际情况调整所需和最大vCPU数。
2.6.2 创建作业队列
定义队列名称,选择上一步创建好的计算环境。
2.6.3 创建容器任务执行角色



2.6.4 创建作业定义
作业定义名称为:“combands-job”

选择上一步创建的角色,输入推送到ECR中的镜像地址,并为容器运行时分配cpu和内存资源:

ECR中容器镜像URI如下图:
2.7 创建SNS Topic
创建SNS Topic用来接受任务运行过程中的告警和任务完成信息。

新建Topic, Topic名称自定义,其他选项默认。
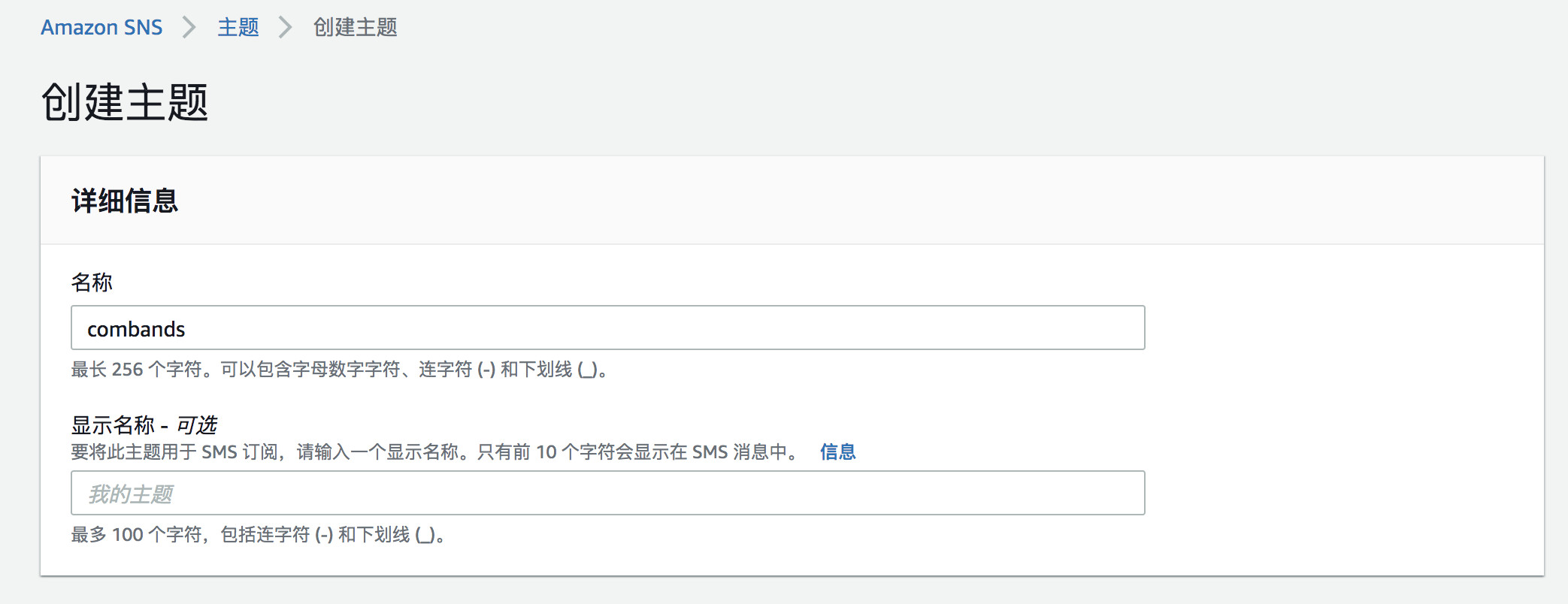
创建订阅,选择电子邮件订阅,输入您用来接收消息的电子邮件地址:


创建订阅后,登录到您上一步设置的邮箱,查收邮件,并确认订阅。
完成确认后,订阅状态变为“已确认”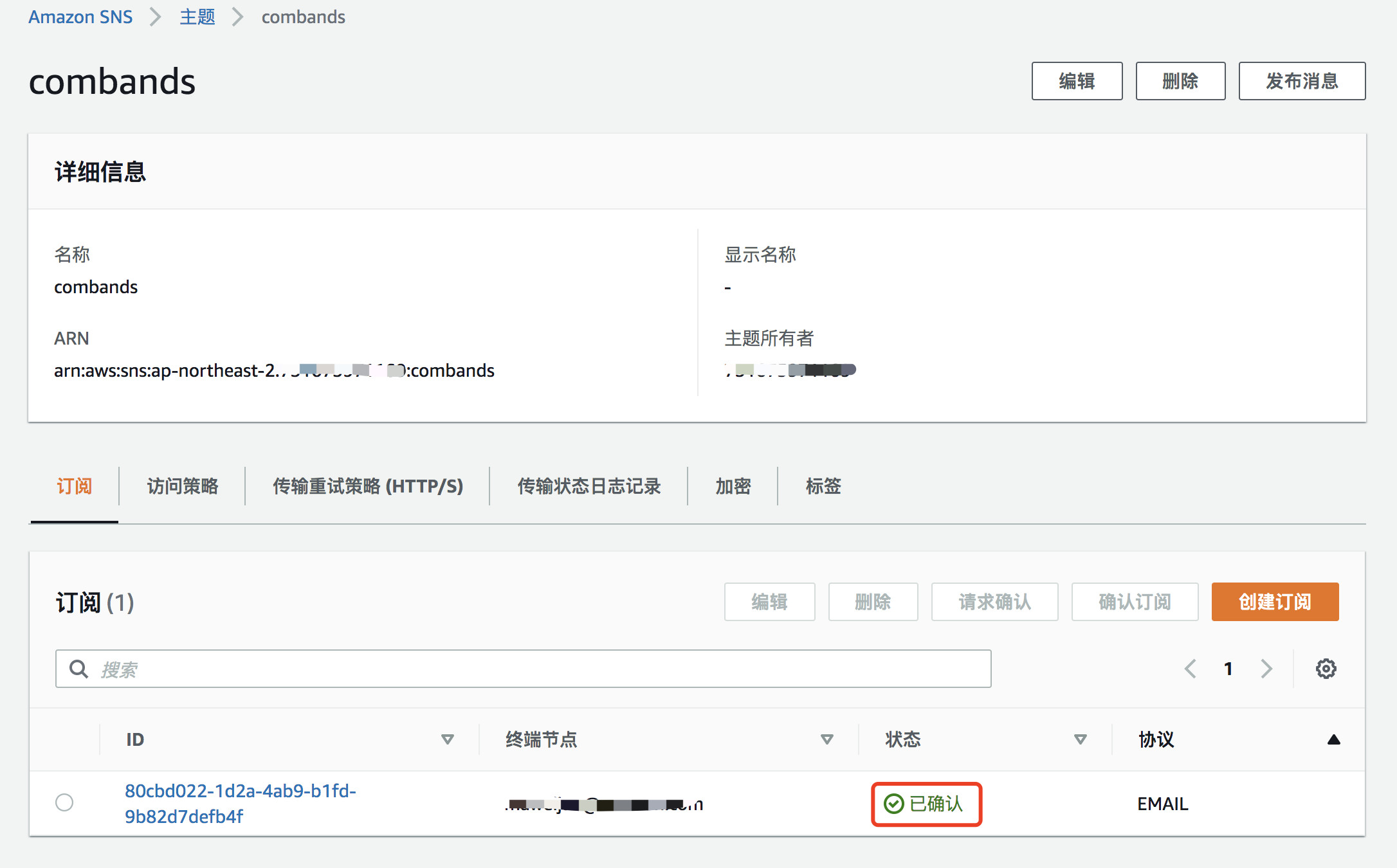
2.8 配置Step Function
配置Step Function前先获取前面步骤中创建的SNS、Batch作业等资源的ARN。在Step Function任务脚本中需要使用到。资源 ARN 获取方式如下:
SNS ARN

Batch 作业定义ARN:


Batch 作业队列ARN:

Lambda ARN:

配置Step Function,创建状态机


代码段部分使用以下内容替换:注意,以下代码中<>部分内容需要替换为您刚才获取的对应资源的ARN。
{
"Comment": "Data process flow",
"StartAt": "Redefine task",
"States": {
"Redefine task": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"ResultPath": null,
"Parameters": {
"FunctionName": "<此处使用 lambda arn 替换>",
"Payload": {
"Input.$": "$"
}
},
"Next": "Map state"
},
"Map state": {
"Type": "Map",
"MaxConcurrency": 0,
"InputPath": "$.detail",
"ItemsPath": "$.cells",
"Iterator": {
"StartAt": "batch compute",
"States": {
"batch compute": {
"Type": "Task",
"Resource": "arn:aws:states:::batch:submitJob.sync",
"Parameters": {
"JobDefinition": "<此处使用Batch 作业定义arn 替换>",
"JobName": "combands",
"JobQueue": "<此处使用Batch 作业队列arn替换>",
"ContainerOverrides": {
"Command": [
"/usr/bin/python3",
"combands.py"
],
"Environment": [{
"Name": "files",
"Value.$": "$.files"
},
{
"Name": "date",
"Value.$": "$.date"
},
{
"Name": "output_bucket",
"Value.$": "$.output_bucket"
},
{
"Name": "region_name",
"Value.$": "$.region_name"
}
]
}
},
"End": true,
"Catch": [{
"ErrorEquals": [
"States.ALL"
],
"Next": "Failure Notify"
}]
},
"Failure Notify": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "<此处使用sns topic arn 替换>",
"Message": {
"Input": "SubTask Failure!"
}
},
"End": true
}
}
},
"Next": "Task Complete"
},
"Task Complete": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "<此处使用sns topic arn 替换>",
"Message": {
"Input": "Task have complete!"
}
},
"End": true
}
}
}
定义好代码段后,Step Function会自动图形显示任务之间的逻辑关系:
输入状态机名称,选择创建新角色,创建完成状态机:
2.9 启动并跟踪任务执行过程
启动执行状态机:
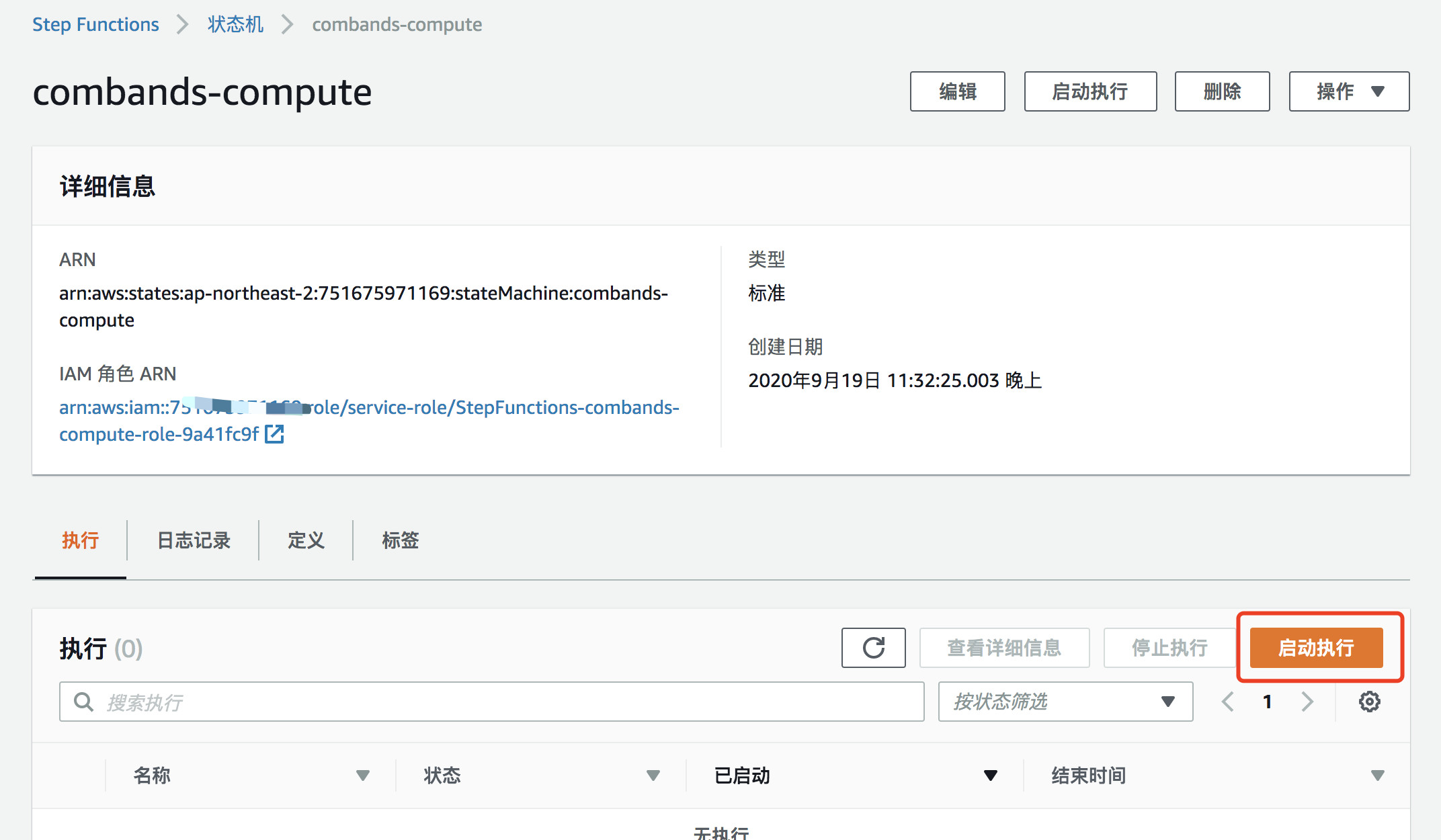
执行输入的json中,输入以下内容,替换对应参数,然后启动执行。
{
"detail": {
"cells": [
{ "files":"s3://sentinel-s2-l2a/tiles/48/R/XT/2020/8/1/0/R10m/","date":"20200801","output_bucket":"<前面步骤中新建的bucket名称>","region_name":"<实验所在的region 如:ap-northeast-1 >"},
{ "files":"s3://sentinel-s2-l2a/tiles/48/R/XT/2020/8/4/0/R10m/","date":"20200804","output_bucket":"<前面步骤中新建的bucket名称>","region_name":"<实验所在的region 如:ap-northeast-1 >"}
]
}
}
说明:以上内容为获取对应区域的20200801和20200804两天的数据,并进行波段融合。可以根据您的实际需要替换对应的参数。如果需要同时计算更多天的数据,只需要在此执行参数中定义输入即可。基于 AWS Batch 您可以同时运行数百甚至数千个并发任务。
状态机中任务运行过程:

到Batch 服务中查看任务运行过程:



状态机中任务运行成功完成:

查收邮件,收到任务完成提醒:

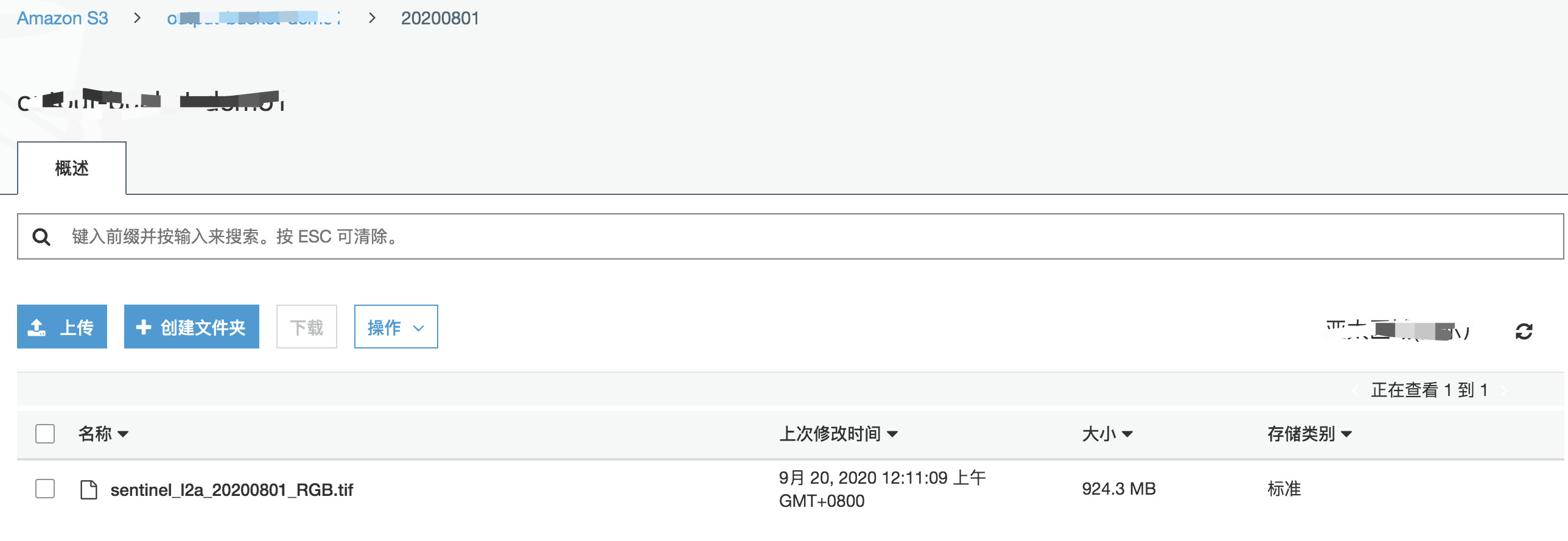
到S3存储桶中,查看任务运行结果
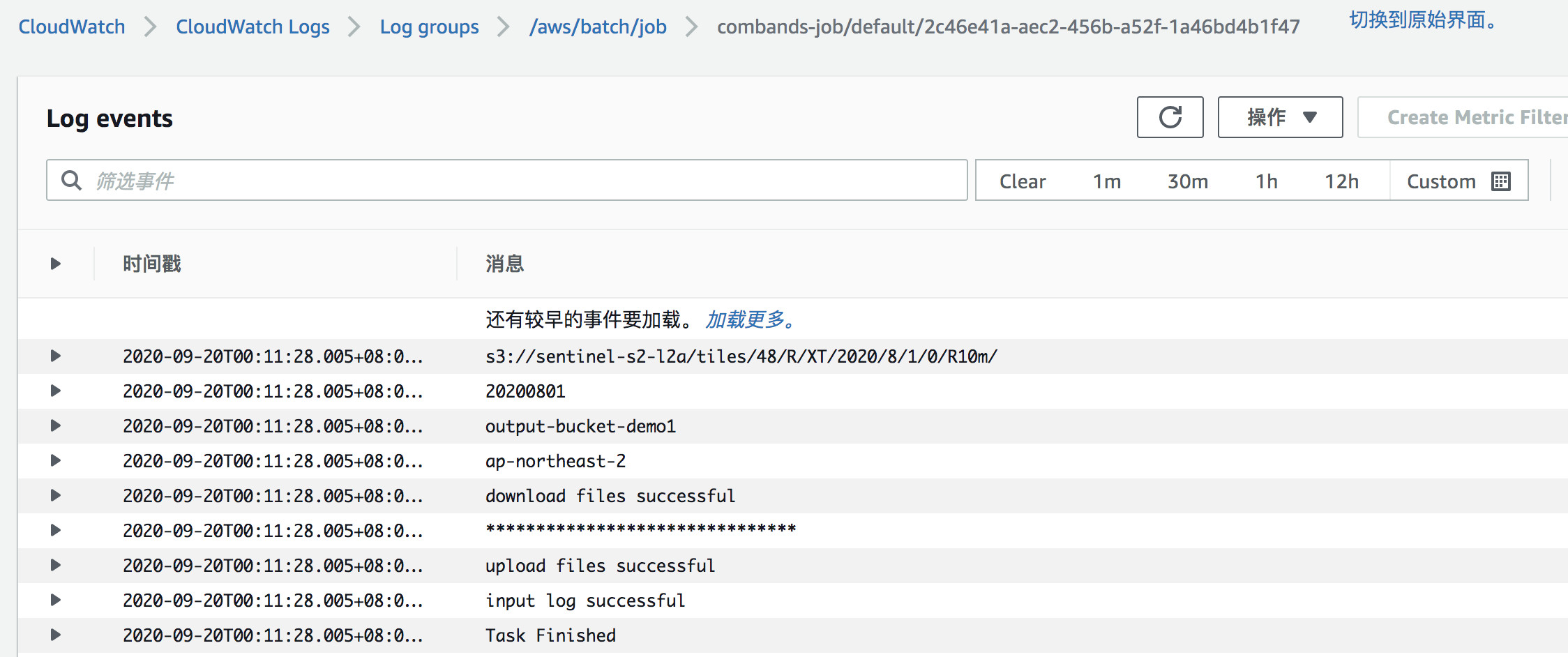
通过Cloudwatch查看任务运行过程日志

使用QGIS软件查看波段融合任务运行结果:

至此就完成了整个实验过程。实验结束后删除资源。
总结
- 通过实验可以看到 AWS Batch通过运行用户容器镜像的形式来开展计算过程,这对科研用户是非常大的优势。用户在线下环境使用的行业软件打包到容器镜像中就可以运行,不需要考虑环境安装维护、操作系统匹配等复杂问题。
- 用户不需要了解和学习分布式计算框架,使用AWS Batch可以轻松开启多任务并行计算,节约科研计算时间。
- AWS Batch 可以调度使用EC2 Spot实例,极大的节约计算成本。