Amazon Redshift 数据共享
无需复制数据即可安全地跨仓库共享数据
优势
-
一旦数据进入任何 Amazon Redshift 数据库,即可在多个仓库中使用。使用一个仓库提取、转换、加载(ETL)数据,并且可以在组织和 AWS 区域内部和之间访问数据。数据工程师无需构建和维护多个管道,将数据存储到多个地方。
-
使用自选计算方式访问数据:不同大小(节点或 RPU)、类型(预置与无服务器)和定价计划(按需型实例与预留实例)。根据团队、应用程序或工作负载的性价比需求选择仓库。跟踪和监控团队的使用情况,控制成本并提高透明度
-
消除数据孤岛和数据重复,因为团队不必将数据从一个位置移动或复制到另一个位置。团队可以在源位置协作处理实时数据,以加快对数据采取行动。访问权限通过 AWS Lake Formation 进行集中管理,从而实现精细的访问控制。
-
安全、轻松地访问来自第三方提供商的数据,无需手动许可流程或在仓库中执行 ETL 操作。只需从 Amazon Redshift 订阅 AWS Data Exchange 中的数据集即可。数据提供商只需点击几下即可使数据在客户仓库中可用,从而从数据中获利并为客户提供价值
Amazon Redshift 数据共享
Amazon Redshift 数据共享允许您在组织、AWS 区域甚至第三方提供商内部和之间共享数据,而无需移动或复制数据。使用多个数据仓库从相同的 Redshift 数据库读取数据/向其写入数据,将 Amazon Redshift 提供的易用性、性能和成本优势扩展到多仓库、数据网格架构。支持即时访问组织内部和整个组织内的实时最新数据,从而消除多个提取、转换、加载(ETL)管道,实现数据协作,缩短获得见解的时间。此外,它允许您为 ETL 使用多个不同类型/大小的仓库,以便您可以根据写入工作负载的性价比需求调整仓库。通过集成到 AWS Data Exchange(容纳数千个第三方数据集的 AWS 市场),Amazon Redshift 用户可以轻松、安全地许可第三方数据集与其 Redshift 数据库中的数据相结合,从而进行全面的分析并创造新的数据获利机会。
应用场景
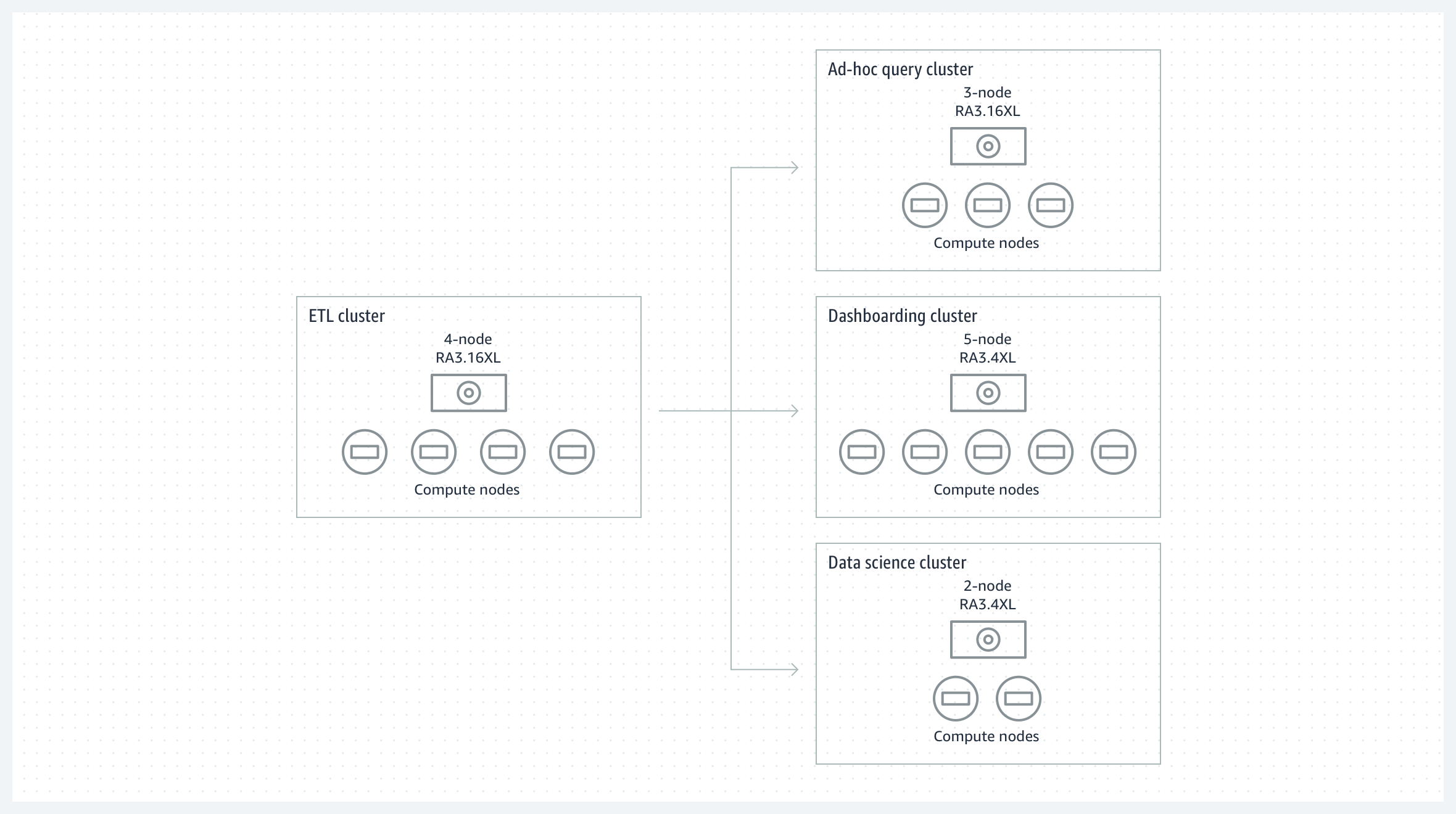
工作负载隔离和可计费
在中心辐射型架构中与多个隔离的 BI 和分析集群共享来自 ETL 集群的数据,以提供读取工作负载隔离和可选的费用计收。可以根据价格性能要求调整每个分析集群的大小,并且轻松地加入新的工作负载。
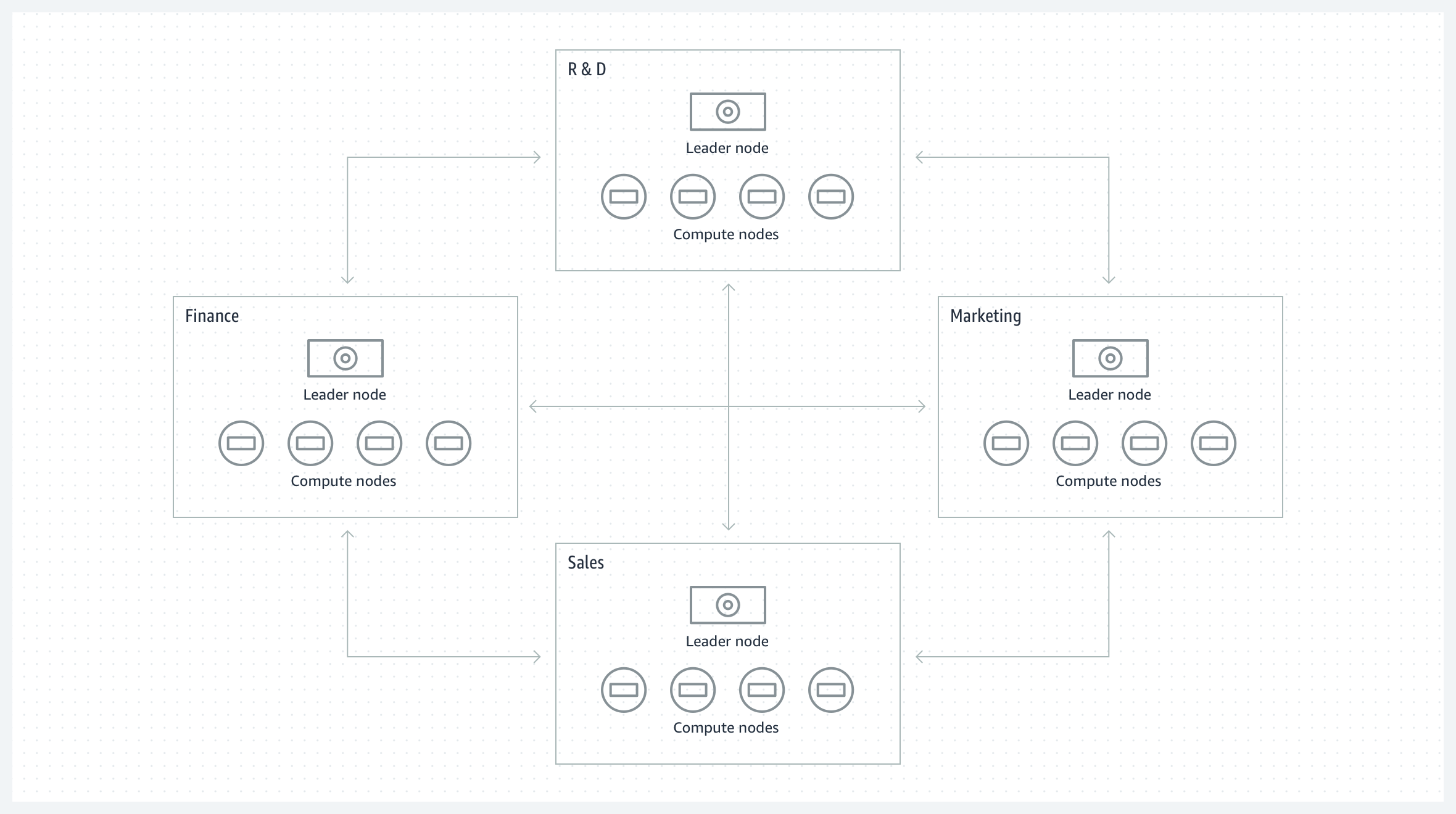
跨组协作
在多个业务组之间共享数据,每个业务组维护单独的 Amazo Redshift 集群,以协作开展更广泛的分析和数据科学研究。各个 Amazon Redshift 集群可以是一些数据的生产者,也可以是其他数据集的消费者。
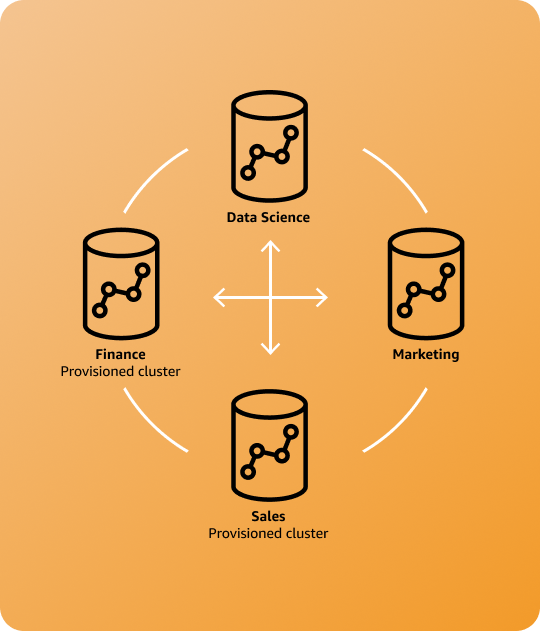
数据和分析即服务
在组织中的不同组以及与组织范围外的外部单位之间共享数据即服务。

开发敏捷性
只需点击几下,即可在不同的预配置集群和不同类型和规模的无服务器工作组之间读取和写入数据。
