概览
Well-Architected 支柱
上面的架构图是按照 Well-Architected 最佳实践创建的解决方案示例。要做到完全的良好架构,您应该遵循尽可能多的 Well-Architected 最佳实践。
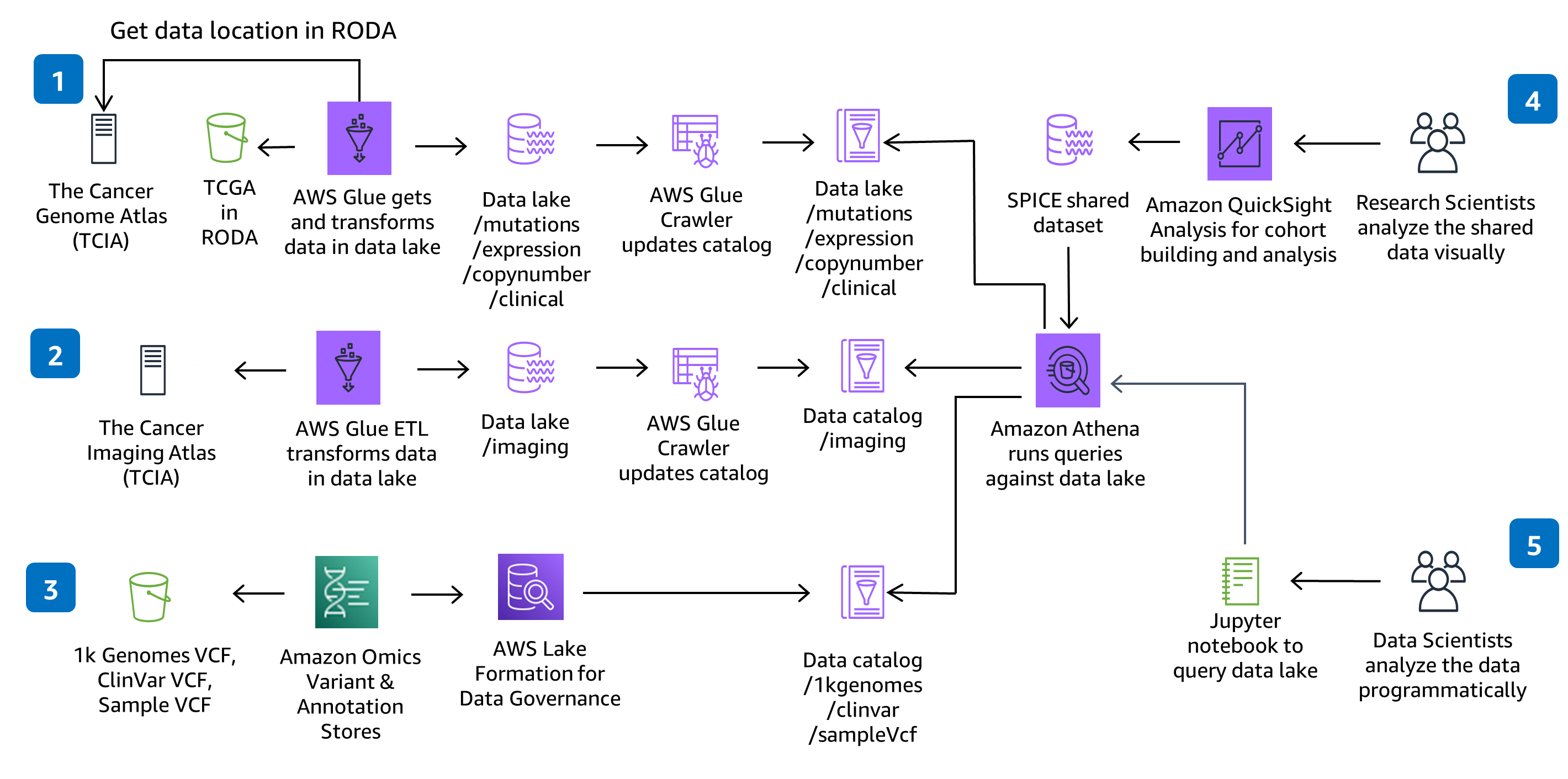
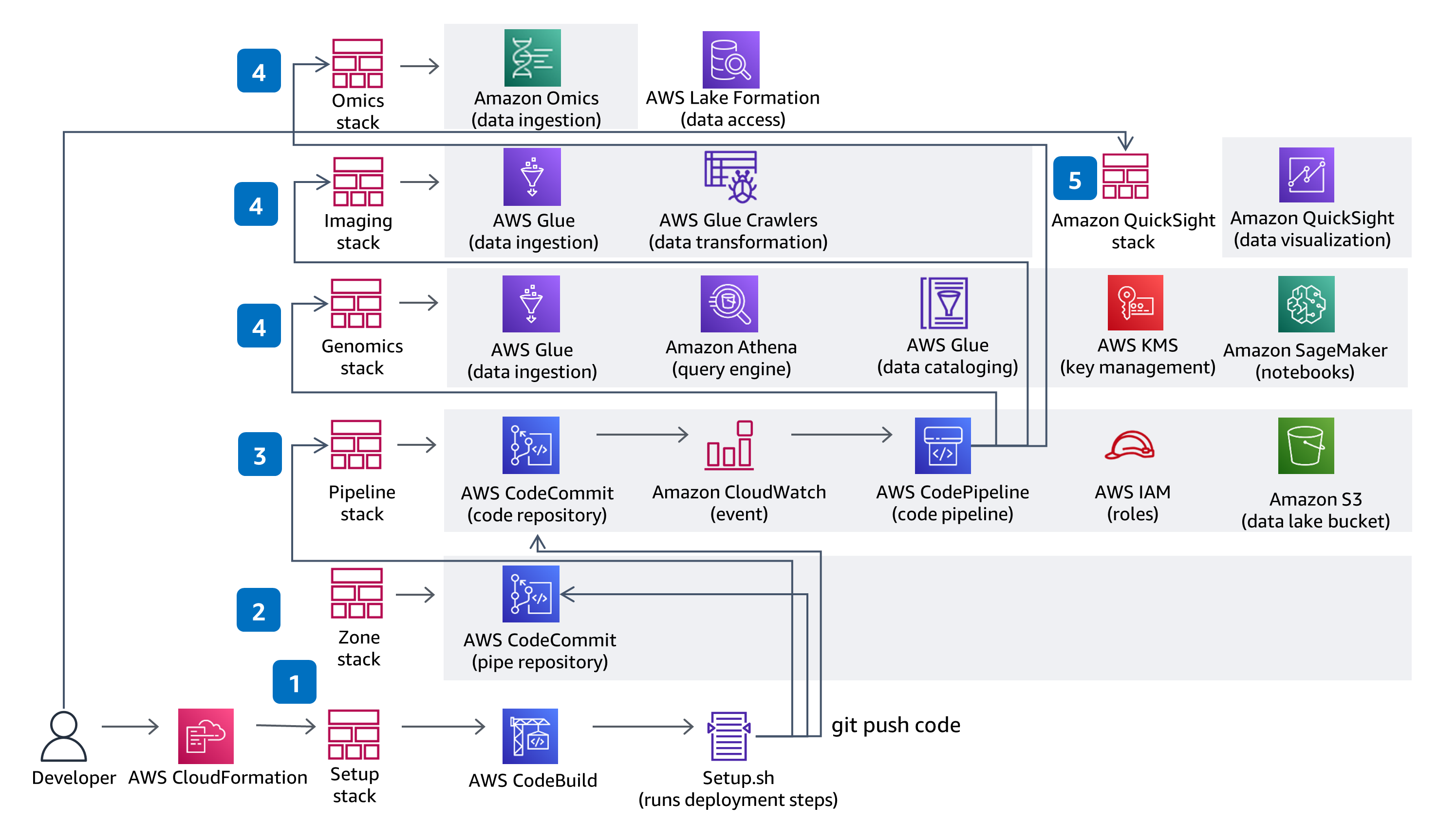
本指南使用C odeBu il d和CodePipel ine来构建、打包和部署解决方案中所需的一切,以提取和存储变体调用文件(VCF),并处理来自癌症基因组图集(TCGA)和癌症成像地图集(TCIA)中数据集的多模态和多组学数据。使用完全托管的服务-Amazon Omics 演示了无服务器基因组学数据的摄取和分析。在解决方案 CodeCommit 存储库中进行的代码更改将通过提供的 C odePipeline 部署管道进行部署。
本指南在 IAM 中使用基于角色的访问权限,所有存储桶都启用了加密、私有并禁止公有访问。AWS Glu e 中的数据目录已启用加密,A WS Glu e 写入亚马逊 S3 的所有元数据均已加密。所有角色都定义为最低权限,服务之间的所有通信都保留在客户账户内部。管理员可以控制 Jupyter 笔记本,亚马逊 Omics Variant Stores 的数据和 AWS Glue 目录的数据访问权限完全使用 Lake Formation 进行管理,而 A thena 、SageMak er Notebook 和 QuickS ig ht 的数据访问权限则通过提供的 IAM 角色进行管理。
AWS Glu e、亚马逊 S3 、亚马逊 Omics 和 A thena 都是无服务器的,将随着数据量的增加而扩展数据访问性能。AWS Gl ue 预置、配置和扩展运行数据集成任务所需的资源。Athena 是无服务器的,因此您无需设置和管理任何服务器或数据仓库即可快速查询数据。QuickSight SPICE 内存存储将把你的数据探索扩展到成千上万的用户。
使用无服务器技术,您只需预调配自己使用的准确资源即可。每个 AWS Glu e 任务将根据需要预置一个 Spark 集群,以转换数据并在完成后取消资源配置。如果您选择添加新的 TCGA 数据集,则可以添加新的 AWS Glue 任务和 AWS Gl u e 爬虫,它们还将按需预览资源。Athena 会自动并行执行查询,因此大多数结果会在几秒钟内返回。 亚马逊 Omics 通过将文件转换为 Apache Parquet 来大规模优化变体查询性能。
使用可按需扩展的无服务器技术,您只需为自己使用的资源付费。为了进一步优化成本,您可以在不使用 SageMaker 的笔记本电脑环境时将其停止。QuickSight 仪表板还通过单独的 CloudFormation 模板进行部署,因此,如果您不打算使用可视化仪表板,可以选择不部署它以节省成本。 亚马逊 Omics 大规模优化变体数据存储成本。查询成本由 Athena 扫描的数据量决定,可以通过相应地编写查询来进行优化。
通过密集地使用托管服务和动态扩展,您可以最大限度地降低后台服务的环境影响。可持续性的关键组件是最大限度地使用笔记本服务器实例。不使用笔记本电脑环境时,应停止运行。
其他注意事项
数据转换
该架构选择了 AWS Glue 来进行提取、转换和加载 (ETL),以在解决方案中提取、准备和编目数据集以提高查询和性能。您可以根据需要添加新的 AWS Glue 任务和 AWS Glue Crawler s 来摄取新的癌症基因组图集 (TCGA) 和癌症图像地图集 (TCIA) 数据集。您还可以添加新作业和爬网程序,以提取、准备自己的私有数据集并编制目录。
数据分析
该架构选择了 SageMaker 笔记本电脑来提供用于分析的Jupyter笔记本电脑环境。您可以向现有环境添加新笔记本,也可以创建新环境。如果你更喜欢 RStudio 而不是 Jupyter 笔记本电脑,你可以在亚马逊 SageMaker 上使用 RStudio 。
数据可视化
该架构选择 QuickSight 为数据可视化和探索提供交互式仪表板。QuickSight 仪表板的设置是通过单独的 CloudFormation 模板进行的,因此,如果您不打算使用该仪表板,则无需进行配置。在 QuickSight 中,您可以创建自己的分析,浏览其他过滤器或可视化效果,并与同事共享数据集和分析。
自信地进行部署
本存储库在 AWS 创建可扩展的环境,为大规模分析准备基因组、临床、突变、表达和成像数据,并对数据湖执行交互式查询。该解决方案演示了如何 1) 使用 HealthOmics 变体存储和注释存储来存储基因组变异数据和注释数据,2) 为多模态数据准备和编目配置无服务器数据摄取管道,3) 通过交互式界面可视化和浏览临床数据,以及 4) 使用亚马逊 Athena 和 Amazon SageMaker 对多模态数据湖运行交互式分析查询。
提供了在 AWS 账户中进行实验和使用的详细指南。构建指南的每个阶段(包括部署、使用和清理)都将被检查,以便为部署做好准备。
示例代码为起点。它经过行业验证,是规范性但不是决定性的,可以帮助您开始。
相关内容
指南
在 AWS 上使用健康 AI 和 ML 服务进行多模态数据分析的指南
本指南演示了如何建立端到端框架来分析多模式医疗保健和生命科学(HCLS)数据。
贡献者
免责声明
找到今天要查找的内容了吗?
请提供您的意见,以便帮助我们提高页面内容的质量