使用 Amazon EC2 Spot 实例以更低成本运行 kOps Kubernetes 集群 30 分钟教程


不到 10 美元

简介
Amazon EC2 Spot 实例让您能够充分利用 AWS Cloud 中闲置的 EC2 资源。与按需实例相比,Spot 实例最高可节省 90% 的成本。
对于 Kubernetes 集群上运行的容器化无状态工作负载而言,Spot 实例堪称完美搭档。这是因为容器和 Spot 实例有着相似的理念——弹性多变、自动扩缩。这意味着您可以在满足服务等级协议 (SLA) 的前提下,灵活地添加和移除资源,而不影响应用程序的性能或可用性。
在本教程中,您将学习如何在 kOps Kubernetes 集群中添加 Spot 实例,同时遵循 Spot 的最佳实践。这样一来,您就可以在保证性能与可用性的前提下,更经济实惠地运行应用程序。Kubernetes Operations (kOps) 是一个开源项目,它提供了一整套工具,让您可以轻松地在云上预配、运行和管理 Kubernetes 集群。在本教程中,您将部署一个 kOps Kubernetes 集群,并通过 Kubernetes Cluster Autoscaler 在 Spot 实例的 worker 节点上自动扩展应用。
学习内容
- 如何搭建 kOps CLI 以及通过 kOps CLI 创建由按需实例节点组成的 Kubernetes 集群
- 如何自动化添加由 Spot 实例组成的节点组,同时遵循最佳实践
- 如何部署 AWS Node Termination Handler(节点终止处理程序)
- 如何部署 Kubernetes Cluster Autoscaler(集群自动扩缩器)
- 如何部署示例应用程序,验证其是否运行在 Spot 实例上并自动扩展
- 如何清理资源
步骤 1:搭建 AWS CLI、kOps 和 kubectl
在此步骤中,我们将安装教程中需要的所有依赖项。
- 1.1 —
- 如果您使用的是 Linux,请运行以下命令来安装 AWS CLI v2;如果您使用的是其他操作系统,请按照 AWS CLI 安装指南中的指示操作来安装 AWS CLI v2。
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install- 1.2 —
- 如需使用 kOps,则必须在环境中配置 AWS 凭证。运行 aws configure 命令是为日常使用配置 AWS CLI 的最快捷的方式。请运行此命令并按照提示操作。直接分配管理员 IAM 策略固然省事,但如果想要遵循最小权限原则,kOps 至少需要以下这些 IAM 权限:
- AmazonEC2FullAccess
- AmazonRoute53FullAccess
- AmazonS3FullAccess
- IAMFullAccess
- AmazonVPCFullAccess
- Events(事件):
- DeleteRule
- ListRules
- ListTargetsByRule
- ListTagsForResource
- PutEvents
- PutRule
- PutTargets
- RemoveTargets
- TagResource
- SQS(消息队列):
- CreateQueue
- DeleteQueue
- GetQueueAttributes
- ListQueues
- ListQueueTags
- AmazonEC2FullAccess
- 如需使用 kOps,则必须在环境中配置 AWS 凭证。运行 aws configure 命令是为日常使用配置 AWS CLI 的最快捷的方式。请运行此命令并按照提示操作。直接分配管理员 IAM 策略固然省事,但如果想要遵循最小权限原则,kOps 至少需要以下这些 IAM 权限:
- 1.3 —
- 在您的环境中安装 kOps。您也可以参考本教程,在其他架构或平台上安装 kOps。截至本文撰写时,kOps 的最新版本为 v1.21.0
export KOPS_VERSION=v1.21.0
curl -LO https://github.com/kubernetes/kops/releases/download/${KOPS_VERSION}/kops-linux-amd64
chmod +x kops-linux-amd64
sudo mv kops-linux-amd64 /usr/local/bin/kops
kops version- 1.4 —
- 安装 kubectl。同样,您也可以参考此指南,在其他架构或平台上安装 kubectl。kubectl 的主版本号应该与 kOps 保持一致。
export KUBECTL_VERSION=v1.21.3
sudo curl --silent --location -o /usr/local/bin/kubectl https://storage.googleapis.com/kubernetes-release/release/${KUBECTL_VERSION}/bin/linux/amd64/kubectl
sudo chmod +x /usr/local/bin/kubectl
kubectl versionGO111MODULE=on go get github.com/mikefarah/yq/v3 ; export PATH=$PATH:~/go/bin步骤 2:搭建 kOps 集群运行环境并创建状态存储
在此步骤中,我们将配置用于搭建环境的部分环境变量,以及创建和配置供 kOps 用作状态存储的 S3 存储桶。
- 2.1 —
- 我们的集群名称定为 spot-kops-cluster。为了减少对其他服务的依赖,本教程将使用 Gossip DNS 创建集群,因此集群域为 k8s.local,集群的完全限定域名为 spot-kops-cluster.k8s.local。
- 我们还将创建一个 S3 存储桶,用于存储 kOps 配置和集群的状态。我们将使用 uuidgen 命令生成一个全局唯一的 S3 存储桶名。
- 最后,我们通过如下命令定义若干环境变量,供本教程后续步骤使用。
export NAME=spot-kops-cluster.k8s.local
export KOPS_STATE_PREFIX=spot-kops-$(uuidgen)
export KOPS_STATE_STORE=s3://${KOPS_STATE_PREFIX}- 2.2 —
- 接下来,我们还需设置一些环境变量,用于指定集群部署的区域 (Region) 和可用区 (Availability Zone)。本教程选择将集群部署在 eu-west-1 区域,您可以根据实际需求修改为其他区域。
export AWS_REGION=eu-west-1
export AWS_REGION_AZS=$(aws ec2 describe-availability-zones \
--region ${AWS_REGION} \
--query 'AvailabilityZones[0:3].ZoneName' \
--output text | \
sed 's/\t/,/g')- 2.3 —
- 定义了集群和 S3 状态存储桶的名称后,我们来创建 S3 存储桶。
aws s3api create-bucket \
--bucket ${KOPS_STATE_PREFIX} \
--region ${AWS_REGION} \
--create-bucket-configuration LocationConstraint=${AWS_REGION}- 2.4 —
- 存储桶创建完成后,我们需要为其开启 S3 版本控制功能,这是 kOps 的最佳实践之一。由于 S3 要承担集群状态存储的角色,对其启用版本控制后,我们就能随时将集群回滚到先前的状态和配置。
aws s3api put-bucket-versioning \
--bucket ${KOPS_STATE_PREFIX} \
--region ${AWS_REGION} \
--versioning-configuration Status=Enabled步骤 3:创建集群和配置按需节点
在此步骤中,我们将创建集群控制面板,并添加一个由按需实例组成的 kOps 节点组。我们还会为该节点组打上一些标签,便于后续将 Pod 调度到指定节点。
- 3.1 —
- 下面我们来创建集群。我们将选用 m5.large 实例类型,在 3 个可用区各配置一个 Kubernetes 主节点,组成一个满足高可用 (HA) 标准的集群。另外,我们还会创建一个包含两个 t3.large 按需实例的节点组。通过该节点组,我们将演示如何根据不同工作负载类型,选择性地将应用程序部署在 Spot 或按需实例上。
kops create cluster \
--name ${NAME} \
--state ${KOPS_STATE_STORE} \
--cloud aws \
--master-size m5.large \
--master-count 3 \
--master-zones ${AWS_REGION_AZS} \
--zones ${AWS_REGION_AZS} \
--node-size t3.large \
--node-count 2 \
--dns private - 3.2 —
- 太棒了!该命令的输出列举了即将创建的所有资源。现在,我们需要确认 kOps 是否已将集群配置写入状态存储桶。
- 运行如下命令,输出结果应与以下的示例类似,表明集群状态已正确保存:
aws s3 ls --recursive ${KOPS_STATE_STORE}aws s3 ls --recursive ${KOPS_STATE_STORE}
2020-06-17 13:36:02 5613 spot-kops-cluster.k8s.local/cluster.spec
2020-06-17 13:36:02 1516 spot-kops-cluster.k8s.local/config
2020-06-17 13:36:02 359 spot-kops-cluster.k8s.local/instancegroup/master-eu-west-1a
2020-06-17 13:36:02 359 spot-kops-cluster.k8s.local/instancegroup/master-eu-west-1b
2020-06-17 13:36:02 359 spot-kops-cluster.k8s.local/instancegroup/master-eu-west-1c
2020-06-17 13:36:02 363 spot-kops-cluster.k8s.local/instancegroup/nodes
2020-06-17 13:36:02 406 spot-kops-cluster.k8s.local/pki/ssh/public/admin/55ecc7ffb2f113a7ac354cc7b7c8adf2- 3.3 —
- 对于新创建的两个节点,我们需要为其添加生命周期标签,标识节点类型为按需实例。由于 kOps 在每个可用区中分别创建了节点组,这里需要对每个可用区的节点组都执行该操作。我们将使用 yq 工具,将上述修改后的配置合并到集群定义中。
for availability_zone in $(echo ${AWS_REGION_AZS} | sed 's/,/ /g')
do
NODEGROUP_NAME=nodes-${availability_zone}
echo "Updating configuration for group ${NODEGROUP_NAME}"
cat << EOF > ./nodes-extra-labels.yaml
spec:
nodeLabels:
kops.k8s.io/lifecycle: OnDemand
EOF
kops get instancegroups --name ${NAME} ${NODEGROUP_NAME} -o yaml > ./${NODEGROUP_NAME}.yaml
yq merge -a append --overwrite --inplace ./${NODEGROUP_NAME}.yaml ./nodes-extra-labels.yaml
aws s3 cp ${NODEGROUP_NAME}.yaml ${KOPS_STATE_STORE}/${NAME}/instancegroup/${NODEGROUP_NAME}
done- 3.4 —
- 我们可以运行以下命令,检查相应标签是否已成功添加至 spec.nodeLabels 字段,以验证配置生效。
- 此命令的输出结果应如下所示:
- nodes-eu-west-1a 节点组包含标签 kops.k8s.io/lifecycle: OnDemand
- nodes-eu-west-1b 节点组包含标签 kops.k8s.io/lifecycle: OnDemand
- nodes-eu-west-1c 节点组包含标签 kops.k8s.io/lifecycle: OnDemand
for availability_zone in $(echo ${AWS_REGION_AZS} | sed 's/,/ /g')
do
NODEGROUP_NAME=nodes-${availability_zone}
kops get ig --name ${NAME} ${NODEGROUP_NAME} -o yaml | grep "lifecycle: OnDemand" > /dev/null
if [ $? -eq 0 ]
then
echo "Instancegroup ${NODEGROUP_NAME} contains label kops.k8s.io/lifecycle: OnDemand"
else
echo "Instancegroup ${NODEGROUP_NAME} DOES NOT contains label kops.k8s.io/lifecycle: OnDemand"
fi
done- 3.5 —
- 除了验证生命周期标签是否生效,建议您再仔细检查某个节点组的配置详情。运行以下命令即可查看:
kops get ig --name ${NAME} nodes-$(echo ${AWS_REGION_AZS}|cut -d, -f 1) -o yaml步骤 4:通过 kops toolbox instance-selector 添加 Spot worker 节点
在此之前,用户若想基于 kOps 管理 Spot 实例,还必须手动挑选一批型号各异的 Spot 实例,以实现实例多样化这一最佳实践。接着,用户需要为实例组定义混合实例组策略 (MixedInstancePolicy),才能让 kOps 在同一节点组内混搭多种实例类型。现在,我们引入了一个新的工具: kOps toolbox instance-selector。该工具内置于 kOps 的官方发行版中,可按照 Spot 最佳实践自动创建节点组,大大简化了 kOps 节点组的配置流程。
- 4.1 —
- 为了将工作负载分散到多个 Spot 容量池,我们将创建两个节点组,每组都包含多种实例类型。实例类型越多样化,越有机会满足预期的资源配额。即便部分容量池中的实例被释放(供 EC2 之需),剩余的多样化实例仍可保障整体容量稳定。kOps 会为每个节点组(对应一个 EC2 Auto Scaling 组)挑选当前 Spot 容量最为充裕的实例类型组合。
- 运行如下命令,创建一个名为 spot-group-base-4vcpus-16gb 的节点组。通过 kOps toolbox instance-selector 配置该节点组,我们无需手动配置即可实现实例类型多样化。 本例中,我们将 m5.xlarge 传递给 --instance-type-base 参数,作为基准实例类型。工具会据此筛选出同世代的实例类型(第 4 代和第 5 代)作为备选。您可以运行 kops toolbox instance-selector --help,深入了解该工具各项参数的用途。
kops toolbox instance-selector "spot-group-base-4vcpus-16gb" \
--usage-class spot --cluster-autoscaler \
--base-instance-type "m5.xlarge" --burst-support=false \
--deny-list '^?[1-3].*\..*' --gpus 0 \
--node-count-max 5 --node-count-min 1 \
--name ${NAME}
- 4.2 —
- 接下来,我们创建第二个节点组。和上一步类似,这次创建一个名为 spot-group-base-2vcpus-8gb 的节点组。
kops toolbox instance-selector "spot-group-base-2vcpus-8gb" \
--usage-class spot --cluster-autoscaler \
--base-instance-type "m5.large" --burst-support=false \
--deny-list '^?[1-3].*\..*' --gpus 0 \
--node-count-max 5 --node-count-min 1 \
--name ${NAME}
4.3 — 生成最终的集群配置之前,我们有必要检查和验证新创建的节点组配置。执行以下命令,查看 spot-group-base-2vcpus-8gb 节点组的详细配置信息。
kops get ig spot-group-base-2vcpus-8gb --name $NAME -o yaml- 4.4 —
- 至此,集群拓扑与下图所示的架构图已经完全一致。
- 但请注意,目前为止我们只是定义了集群的配置。若要实际创建集群资源,还需执行以下命令:
- 注意:如果环境中已存在 kubeconfig 文件,则需运行 kops export kubecfg --name ${NAME} 命令,以保存并切换至新的 kubeconfig 上下文。
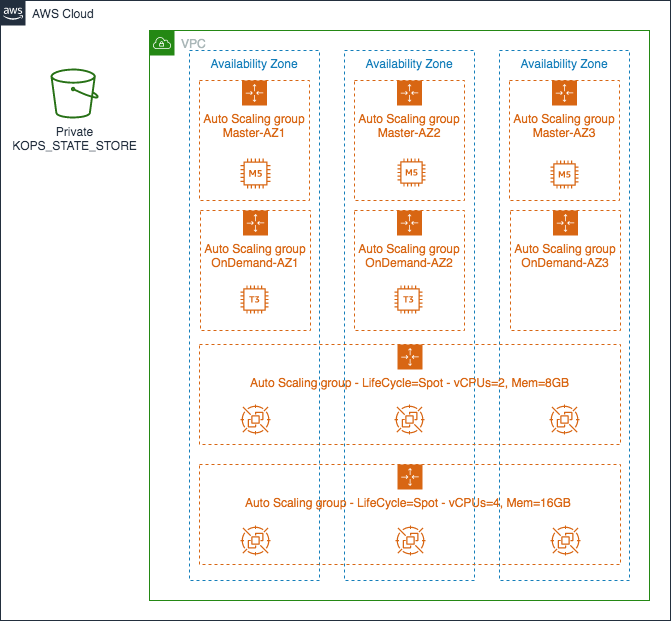
kops update cluster --state=${KOPS_STATE_STORE} --name=${NAME} --yes --admin- 4.5 —
- 上一步中的命令会为整个集群及其资源生成配置清单,输出结果应与以下示例类似。命令执行时长约为 5 分钟。
- 在此期间,您可以每隔一分钟左右运行一次 kOps validate cluster 命令,跟踪集群的创建进度。
- 待集群进入就绪状态后,即可运行 kubectl get nodes --show-labels 命令,检查集群及其关联资源的运行状况。
NODE STATUS
NAME ROLE READY
ip-172-20-113-157.eu-west-1.compute.internal node True
ip-172-20-49-151.eu-west-1.compute.internal master True
ip-172-20-64-43.eu-west-1.compute.internal node True
ip-172-20-64-52.eu-west-1.compute.internal master True
ip-172-20-99-157.eu-west-1.compute.internal master True
Your cluster spot-kops-cluster.k8s.local is readykops validate cluster --wait 10m步骤 5:部署 AWS Node Termination Handler(节点终止处理程序)
当 EC2 决定回收 Spot 实例时,会提前向实例发送一个 Spot 实例中断通知,留给应用程序两分钟的时间妥善处理这一中断,最大程度降低可用性和性能的影响。此外,我们最近还引入了一项新的事件——实例再平衡建议。该事件会在 Spot 实例中断风险加剧时提前向您发出通知,比中断通知来得更早,让您有更充裕的时间主动迁移有风险的实例,将工作负载均衡到其他风险较低的新 Spot 实例或现有 Spot 实例。为了在 Kubernetes 集群中优雅地处理这两类事件,我们将在本节部署 AWS Node Termination Handler。
- 5.1 —
- 接下来,我们使用 kOps 以队列处理器模式安装 AWS Node Termination Handler。该处理程序通过轮询 Amazon SQS 队列,接收来自 Amazon EventBridge 的事件。这些事件预示着集群中节点可能发生终止,比如 Spot 实例中断或再平衡、EC2 维护,以及 Auto Scaling 组生命周期挂钩触发等场景。如此一来,处理程序就能在终止发生前主动隔离和驱逐相关节点,并向其上的 Pod 和容器进程发送 SIGTERM 信号,确保应用程序得以优雅退出。
- kOps 提供了一键部署 AWS Node Termination Handler 的功能,我们只需在集群配置清单中添加相应的附加组件定义即可。该 kOps 附加组件会自动配置所需的 AWS 服务资源,包括:SQS 队列、EventBridge 规则,以及 Auto Scaling 组生命周期挂钩等。
kops get cluster --name ${NAME} -o yaml > ~/environment/cluster_config.yaml
cat << EOF > ./node_termination_handler_addon.yaml
spec:
nodeTerminationHandler:
enabled: true
enableSQSTerminationDraining: true
managedASGTag: "aws-node-termination-handler/managed"
EOF
yq merge -a append --overwrite --inplace ~/environment/cluster_config.yaml ~/environment/node_termination_handler_addon.yaml
aws s3 cp ~/environment/cluster_config.yaml ${KOPS_STATE_STORE}/${NAME}/config
kops update cluster --state=${KOPS_STATE_STORE} --name=${NAME} --yes --admin- 5.2 —
- 为确认 AWS Node Termination Handler 是否已正确部署,请运行以下命令:
kubectl get deployment aws-node-termination-handler -n kube-system -o wide步骤 6:(可选)部署 Kubernetes Cluster Autoscaler
Cluster Autoscaler 是 Kubernetes 的一种控制器,可以动态调节集群规模。一旦集群中出现因资源不足而无法调度的 Pod,Cluster Autoscaler 就会触发扩容 (Scale Out) 操作。反之,如果某些节点长时间处于低利用率状态,Cluster Autoscaler 则会对集群执行缩容 (Scale In)。具体来说,Cluster Autoscaler 会依次评估每个节点组,进而横向扩缩集群。在 AWS 环境中,Cluster Autoscaler 的节点组是通过 EC2 Auto Scaling 组实现的。为了计算扩缩容时新增或删除的节点数,Cluster Autoscaler 默认每个节点组内的实例规格都是同质的(即 vCPU 和内存配置相同)。
- 6.1 —
- Cluster Autoscaler 需要一些额外的 IAM 权限策略才能正常运行。在安装之前,我们先来添加所需的策略,以便集群节点能够调用相关 API 对 Auto Scaling 组进行管理。待上述策略添加完成后,我们需要更新集群配置,策略才能真正生效。
kops get cluster --name ${NAME} -o yaml > ./cluster_config.yaml
cat << EOF > ./extra_policies.yaml
spec:
additionalPolicies:
node: |
[
{
"Effect":"Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeTags",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeLaunchTemplateVersions"
],
"Resource":"*"
}
]
EOF
yq merge -a append --overwrite --inplace ./cluster_config.yaml ./extra_policies.yaml
aws s3 cp ./cluster_config.yaml ${KOPS_STATE_STORE}/${NAME}/config
kops update cluster --state=${KOPS_STATE_STORE} --name=${NAME} --yescurl -sSL https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
helm repo add stable https://charts.helm.sh/stable
helm version --short- 6.3 —
- 现在,我们来安装和配置 Cluster Autoscaler。安装时需要为 Cluster Autoscaler 指定若干配置参数。其中之一是 autoDiscovery.clusterName。该参数的值需要与此前 kops toolbox instance-selector 命令为节点组添加的标签保持一致。如此 Cluster Autoscaler 才能自动发现这些节点组并接管之。
- 除此之外,还有一个参数值得注意。我们将 expander 参数设为了 random。此 expander 配置用于定义当有 Pod 处于 Pending 状态时,Cluster Autoscaler 的扩容策略。random 策略会从所有节点组中随机选取一个进行扩容。对于生产环境的集群,随机扩容更有利于实现节点多样化,让新增节点分散到各个实例组中。而对于测试或开发环境,建议您将策略改为 least-waste(最小浪费)。顾名思义,该策略会优先选择扩容后 CPU 和内存空闲最少的节点组,通过从而调整实例组的大小和优化 EC2 实例的利用率,来最大程度地节约资源。
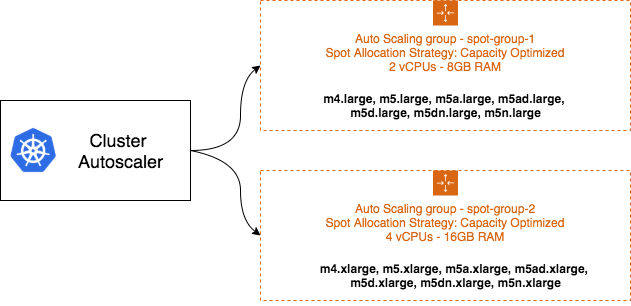
helm repo add autoscaler https://kubernetes.github.io/autoscaler
helm upgrade --install cluster-autoscaler autoscaler/cluster-autoscaler \
--set fullnameOverride=cluster-autoscaler \
--set nodeSelector."kops\.k8s\.io/lifecycle"=OnDemand \
--set cloudProvider=aws \
--set extraArgs.scale-down-enabled=true \
--set extraArgs.expander=random \
--set extraArgs.balance-similar-node-groups=true \
--set extraArgs.scale-down-unneeded-time=2m \
--set extraArgs.scale-down-delay-after-add=2m \
--set autoDiscovery.clusterName=${NAME} \
--set rbac.create=true \
--set awsRegion=${AWS_REGION} \
--wait- 6.4 —
- 您还可以通过以下命令查看 Cluster Autoscaler 的运行日志和操作记录。该命令会输出 Cluster Autoscaler 的日志。
kubectl logs -f deployment/cluster-autoscaler --tail=10步骤 7:部署示例应用程序
最后,让我们部署一个测试应用程,并观察集群的扩容过程。要模拟应用程序扩容,我们将创建一个 Deployment。Deployment 中可以指定需要运行的副本个数。我们将副本数设置得很大,使其中一些副本因资源不足而无法调度,进而处于 Pending 状态。
- 7.1 —
- 运行以下命令,确认应用程序已部署成功,且当前有一个 Nginx Web 服务器副本在运行:
- 运行以下命令,确认应用程序已部署成功,且当前有一个 Nginx Web 服务器副本在运行:
kubectl get deployment/nginx-app- 7.2 —
- 该命令的输出结果应如下所示:
- 该命令的输出结果应如下所示:
deployment.apps/nginx-app created- 7.3 —
- 扩展该 Deployment(即增加副本数量)。
kubectl scale --replicas=20 deployment/nginx-app- 7.4 —
- 检查并确保有一些 Pod 处于 Pending 状态。Cluster Autoscaler 正是以 Pending 状态作为触发器来发起 Scale Out 操作。
- 输出结果应如下所示:
- 检查并确保有一些 Pod 处于 Pending 状态。Cluster Autoscaler 正是以 Pending 状态作为触发器来发起 Scale Out 操作。
bash-4.2$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cluster-autoscaler-5b9d46ffcb-pj4jn 1/1 Running 0 13m
kube-ops-view-5d455db74f-j7v4t 1/1 Running 0 6m23s
nginx-app-746b9b4bbc-57v7b 0/1 Pending 0 27s
…
nginx-app-746b9b4bbc-72zsr 0/1 Pending 0 27s
nginx-app-746b9b4bbc-bz9g2 0/1 Pending 0 27skubectl get pods - 7.5 —
- 检查 Cluster Autoscaler 的日志,确保其已发现处于 Pending 状态的 Pod,并启动 Scale Out 活动,增加所选节点组的实例数。
- 输出结果应如下所示:
kubectl logs -f deployment/cluster-autoscaler | grep -I scale_upI0810 11:34:33.384647 1 scale_up.go:431] Best option to resize: spot-group-base-2vcpus-8gb.spot-kops-cluster.k8s.local
I0810 11:34:33.384656 1 scale_up.go:435] Estimated 4 nodes needed in spot-group-base-2vcpus-8gb.spot-kops-cluster.k8s.local
I0810 11:34:33.384698 1 scale_up.go:539] Final scale-up plan: [{spot-group-base-2vcpus-8gb.spot-kops-cluster.k8s.local 1->5 (max: 5)}]- 7.6 —
- 打开 AWS 管理控制台,检查确认相应的 EC2 Auto Scaling 组内的 Spot 实例数量是否有所增加。
- 等待一段时间(约 1-3 分钟)后,确认新的 Spot 实例节点已加入集群。命令输出应显示拥有 node, spot-worker 标签的 worker 节点数量为 2 个以上。
kubectl get nodes -L node.kubernetes.io/instance-type- 7.7 —
- 节点加入集群后,检查之前处于 Pending 状态的 Pod 是否都已成功调用。
kubectl get pods步骤 8:清理资源
- 8.1 —
- 移除测试应用程序。
- 移除测试应用程序。
kubectl delete deployment/nginx-app- 8.2 —
- 移除 Cluster Autoscaler。
helm delete cluster-autoscaler- 8.3 —
- 移除 kOps 集群,删除集群状态和所有相关资源。
kops delete cluster --name ${NAME} --yes- 8.4 —
- 在控制台中移除 S3 存储桶。
- 如需了解如何从控制台删除存储桶,请阅读 AWS 文档中的“删除单个对象”章节。
恭喜您
您已成功部署基于 Spot 实例的 kOps 集群,并借助
相关工具践行最佳实践,轻松应对各种中断场景。
对于 Kubernetes 上运行的可容错工作负载而言,Spot 实例
在控制成本方面优势巨大,堪称不二之选。
更多资源
- 深入了解 kops toolbox instance-selector 工具
- 详细了解 AWS Node Termination Handler 的其他功能
- 浏览 EKS 集群中使用 Spot 实例研讨会,学习更多进阶的 Kubernetes 教程,掌握如何将 EKS 和 eksctl 结合使用
- 通过 Spot 实例研讨会网站中的动手实践,学习如何在 Spot 实例上运行其他类型的工作负载
