Automatisierung sicherer, vollautomatischer Bereitstellungen
Softwarebereitstellung und -betrieb | LEVEL 300
Themen der Seite
- Einführung
- Sichere kontinuierliche Bereitstellungen bei Amazon
- Der Weg zur kontinuierlichen Bereitstellung
- Die vier Phasen der Pipeline
- Quelle und Build
- Pipeline-Quellen
- Code-Überprüfung
- Build und Unit-Tests
- Testbereitstellungen in Vorproduktionsumgebungen
- Integrationstests
- Rückwärtskompatibilität und One-Box-Test
- Produktionsbereitstellungen
- Gestaffelte Bereitstellungen
- One-Box- und rollierende Bereitstellungen
- Metriküberwachung und automatisches Rollback
- Bake-Zeit
- Alarm- und Zeitfenster-Blockierer
- Pipelines als Code
- Zusammenfassung
- Weitere Lektüre
Einführung
Als ich mich für meine Stelle bei Amazon beworben habe, fragte ich einen der Interviewer: "Wie oft führen Sie Ihre Bereitstellung für die Produktion durch?" Zu dieser Zeit arbeitete ich an einem Produkt, das ein- oder zweimal im Jahr eine größere Version herausbrachte, aber manchmal musste ich zwischen den großen Versionen einen kleinen Fix veröffentlichen. Für jeden Fix, den ich veröffentlicht habe, habe ich Stunden damit verbracht, ihn sorgfältig zu implementieren. Dann überprüfte ich verzweifelt Protokolle und Metriken, um zu sehen, ob ich nach der Bereitstellung etwas kaputt gemacht hatte und es zurücksetzen musste.
Ich las, dass Amazon eine kontinuierliche Bereitstellung praktiziert, daher wollte ich bei meinem Interview wissen, wie viel Zeit ich als Entwickler bei Amazon für die Verwaltung und Beobachtung von Bereitstellungen aufwenden müsste. Der Interviewer erzählte mir, dass Änderungen durch kontinuierliche Bereitstellungs-Pipelines mehrmals täglich automatisch in die Produktion übernommen wurden. Als ich ihn fragte, wie viel Zeit er damit verbrachte, jede dieser Bereitstellungen sorgfältig zu betreuen und die Protokolle und Messwerte auf etwaige Auswirkungen zu überwachen, wie ich es getan hatte, sagte er mir, normalerweise keine. Da die Pipelines diese Arbeit für sein Team erledigten, wurden die meisten Bereitstellungen von niemandem aktiv beobachtet. "Wow!", sagte ich. Nachdem ich zu Amazon gekommen war, war ich gespannt, wie genau diese "hands-off" automatisierten Bereitstellungen funktionierten.
Sichere kontinuierliche Bereitstellungen bei Amazon
Seitdem habe ich aus erster Hand gesehen, wie Amazon kontinuierliche Bereitstellungspipelines einrichtet, um uns bei der schnellen und sicheren Bereitstellung zu unterstützen. Ich lernte zu schätzen, wie unsere Sicherheitspraktiken für die kontinuierliche Bereitstellung die Entwickler von der Arbeit an den Bereitstellungen entlasten und ihnen Zeit für andere Aufgaben geben. Wenn ich den Produktionscode in den Hauptzweig des Quellcode-Repositorys meines Service verschiebe, vergesse ich das normalerweise und mache mit meiner nächsten Aufgabe weiter, während die Pipeline meines Teams die Produktion dieser Änderung übernimmt. Die Freigabe meiner Code-Änderung an einen produktiven Service wird durch die Pipeline vollständig automatisiert, d. h. das letzte Mal, dass ich oder ein anderer Entwickler ein Stück Code berühre oder überprüfe, ist, wenn es in das Quellcode-Repository eingebunden wird.
Mein Team hat diese Pipeline mit automatisierten Schritten eingerichtet, die unsere Änderungen sicher in die Produktion einbringen, so dass wir nicht jede Bereitstellung beobachten müssen. Die Pipeline führt die neuesten Änderungen durch eine Reihe von Tests und Sicherheitsprüfungen für Ihre Bereitstellung. Diese automatisierten Schritte verhindern, dass Defekte, die sich auf den Kunden auswirken, die Produktion erreichen, und begrenzen die Auswirkungen von Defekten auf den Kunden, wenn sie die Produktion erreichen. Als Entwickler kann ich darauf vertrauen, dass die Pipeline meine Bereitstellung vorsichtig und sicher für mich in die Produktion überführt, ohne dass ich sie aktiv beobachten muss.
Der Weg zur kontinuierlichen Bereitstellung
Amazon begann nicht damit, eine kontinuierliche Lieferung zu praktizieren, und die Entwickler hier verbrachten Stunden und Tage damit, die Bereitstellung ihres Codes bis zur Produktion zu verwalten. Wir haben uns für die kontinuierliche Lieferung im gesamten Unternehmen entschieden, um die Art und Weise, wie wir Software bereitstellen, zu automatisieren und zu standardisieren und die Zeit zu verkürzen, bis Änderungen die Produktion erreichen. Die Verbesserungen unseres Freigabeprozesses haben sich im Laufe der Zeit schrittweise aufgebaut. Wir haben Risiken bei der Bereitstellung identifiziert und Wege gefunden, diese Risiken durch neue Sicherheitsautomatisierung in Pipelines zu mindern. Wir setzen die Wiederholung des Bereitstellungsprozesses fort, indem wir neue Risiken und neue Wege zur Verbesserung der Sicherheit bei der Bereitstellung identifizieren. Um mehr über unseren Weg zur kontinuierlichen Bereitstellung zu erfahren und darüber, wie wir uns weiter verbessern, lesen Sie den Artikel aus der Builders’ Library: Schneller mit kontinuierlicher Lieferung.
Die vier Phasen der Pipeline
In diesem Artikel besprechen wir die Schritte, die eine Codeänderung in einer Pipeline bei Amazon auf dem Weg zur Produktion durchläuft. Eine typische Pipeline für kontinuierliche Lieferung hat vier Hauptphasen: Quelle, Build, Test und Produktion (Prod). Wir gehen auf die Einzelheiten ein, was in jeder dieser Pipeline-Phasen für einen typischen AWS-Service geschieht, und geben Ihnen ein Beispiel dafür, wie ein typisches AWS-Serviceteam eine seiner Pipelines aufbaut.
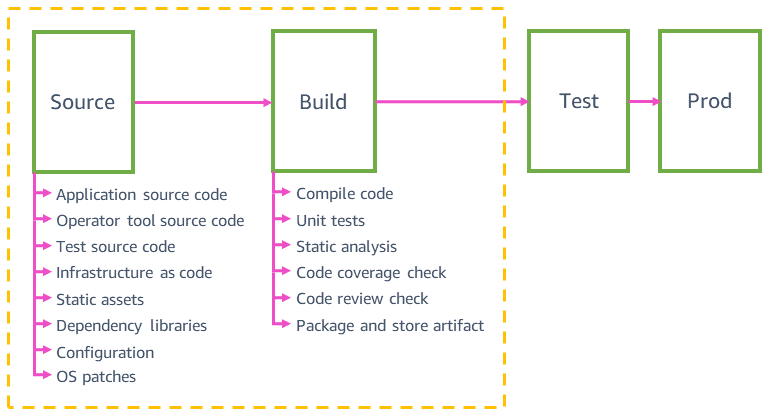
Quelle und Build
Das folgende Diagramm gibt Ihnen einen Überblick über die Schritte Quelle und Build, die Sie in typischen Pipelines von AWS-Services-Teams finden können.
Pipeline-Quellen
Pipelines bei Amazon validieren automatisch jede Art von Quellcode-Änderungen und setzen diese sicher in der Produktion um, nicht nur Änderungen am Anwendungscode. Sie können Änderungen an Quellen wie statischen Website-Ressourcen, Tools, Tests, Infrastruktur, Konfiguration und dem zugrunde liegenden Betriebssystem (OS) der Anwendung validieren und bereitstellen. All diese Änderungen sind in einzelnen Quellcode-Repositorys versionskontrolliert. Die Quellcode-Abhängigkeiten, wie z. B. Bibliotheken, Programmiersprachen und Parameter wie AMI-IDs, werden mindestens wöchentlich automatisch auf die neueste Version aktualisiert.
Diese Quellen werden in einzelnen Pipelines mit den gleichen Sicherheitsmechanismen (wie automatisches Rollback) eingesetzt, die wir für die Bereitstellung von Anwendungscode verwenden. Beispielsweise werden Konfigurationswerte für einen Service, die sich zur Laufzeit ändern können (wie API-Ratenbegrenzungserhöhungen und Feature-Flags), automatisch in einer dedizierten Konfigurationspipeline bereitgestellt. Quelländerungen werden automatisch rückgängig gemacht, wenn sie Probleme bei der Produktion für den Service verursachen (z. B. Fehler beim Parsen einer Konfigurationsdatei).
Ein typischer Mikroservice könnte eine Anwendungscode-Pipeline, eine Infrastruktur-Pipeline, eine Betriebssystem-Patching-Pipeline, eine Konfigurations-/Feature-Flags-Pipeline und eine Operator-Tools-Pipeline haben. Wenn wir mehrere Pipelines für denselben Mikroservice haben, können wir Änderungen schneller in der Produktion bereitstellen. Änderungen am Anwendungscode, die Integrationstests fehlschlagen und die Anwendungs-Pipeline blockieren, haben keine Auswirkungen auf andere Pipelines. Beispielsweise blockieren sie nicht, dass Änderungen des Infrastruktur-Codes die Produktion in der Infrastruktur-Pipeline erreichen. Alle Pipelines für ein und denselben Mikroservice sehen sich in der Regel sehr ähnlich. Beispielsweise verwendet eine Feature-Flag-Pipeline dieselben sicheren Bereitstellungstechniken wie die Anwendungscode-Pipeline, da eine schlechte Feature-Flag-Konfigurationsänderung ebenso wie eine schlechte Anwendungscode-Änderung Auswirkungen auf die Produktion haben kann.
Code-Überprüfung
Alle Änderungen, die in Produktion gehen, beginnen mit einer Code-Überprüfung und müssen von einem Teammitglied genehmigt werden, bevor sie in den Mainline-Zweig (unsere Version von "main" oder "trunk") übernommen werden, wodurch die Pipeline automatisch gestartet wird. Die Pipeline erzwingt die Anforderung, dass alle Commits auf dem Mainline-Zweig von einem Mitglied des Service-Teams für diese Pipeline einer Code-Überprüfung unterzogen und genehmigt werden müssen. Die Pipeline wird alle nicht überprüften Commits von der Bereitstellung ausschließen.
Bei vollautomatisierten Pipelines ist die Code-Überprüfung die letzte manuelle Überprüfung und Genehmigung, die eine Code-Änderung von einem Ingenieur erhält, bevor sie in die Produktion eingeführt wird, so dass dies ein kritischer Schritt ist. Code-Prüfer bewerten die Korrektheit des Codes und beurteilen auch, ob die Änderung sicher in der Produktion eingesetzt werden kann. Sie bewerten, ob der Code über ausreichende Tests (Unit-Tests, Integrationstests und Canary-Tests) verfügt, ob er für die Überwachung der Bereitstellung ausreichend instrumentiert ist und ob er sicher zurückgerollt werden kann. Einige Teams verwenden eine benutzerdefinierte Checkliste wie die im folgenden Beispiel, die automatisch zu jedem Code-Prüfer des Teams hinzugefügt wird, um explizit auf Sicherheitsbedenken bei der Bereitstellung zu prüfen.
Beispiel einer Checkliste für Code-Prüfer
## Testen
[ ] Hast du neue Modultests für diese Änderung geschrieben?
[ ] Hast du neue Integrationstests für diese Änderung geschrieben?
Schließen Sie die Testbefehle ein, die Sie lokal ausgeführt haben, um diese Änderung zu testen:
```
mvn test && mvn verify
```
## Überwachung
[ ] Wird diese Änderung durch unsere bestehende Überwachung abgedeckt?
(es sind keine neuen Canaries/Metriken/Dashboards/Alarme erforderlich)
[ ] Wird sich diese Änderung nicht (oder positiv) auf Ressourcen und/oder Limits auswirken?
(einschließlich CPU, Arbeitsspeicher, AWS-Ressourcen, Aufrufe anderer Dienste)
[ ] Kann diese Änderung in Prod implementiert werden, ohne Alarme auszulösen?
## Einführung
[ ] Kann diese Änderung nach Genehmigung sofort in die Pipeline übernommen werden?
[ ] Sind alle abhängigen Änderungen bereits in Prod implementiert?
[ ] Kann diese Änderung nach der Bereitstellung auf Prod ohne Probleme rückgängig gemacht werden?
Build und Unit-Tests
In der Build-Phase wird der Code kompiliert und in Einheiten getestet. Die Build-Tools und die Buildlogik können von Sprache zu Sprache und sogar von Team zu Team variieren. So können die Teams beispielsweise die für sie am besten geeigneten Unit-Test-Rahmenwerke, Linters und statischen Analysewerkzeuge auswählen. Darüber hinaus können die Teams die Konfiguration dieser Tools wählen, wie z. B. die minimal akzeptable Code-Abdeckung in ihrem Unit-Test-Rahmenwerk. Die Tools und Arten von Tests, die ausgeführt werden, hängen auch von der Art des Codes ab, der von der Pipeline bereitgestellt wird. Beispielsweise werden Unit-Tests für Anwendungscode und Linters für die Infrastruktur als Code-Vorlagen verwendet. Alle Builds laufen ohne Netzwerkzugriff, um die Builds zu isolieren und die Reproduzierbarkeit der Builds zu fördern. Üblicherweise werden bei Unit-Tests alle API-Aufrufe zu Abhängigkeiten, wie z. B. anderen AWS-Services, nachgebildet (simuliert). Interaktionen mit "live", nicht gemockten Abhängigkeiten werden später in der Pipeline in Integrationstests getestet. Im Vergleich zu Integrationstests sind Unit-Tests mit gemockten Abhängigkeiten in der Lage, Edge-Fälle wie unerwartete Fehler, die von API-Aufrufen zurückgegeben werden, auszuüben und eine elegante Fehlerbehandlung im Code zu gewährleisten. Wenn der Build abgeschlossen ist, wird der kompilierte Code verpackt und signiert.
Testbereitstellungen in Vorproduktionsumgebungen
Vor der Bereitstellung für die Produktion werden in der Pipeline Änderungen in mehreren Vorproduktionsumgebungen, z. B. Alpha, Beta und Gamma, bereitgestellt und validiert. Alpha und Beta validieren, dass der neueste Code wie erwartet funktioniert, indem funktionale API-Tests und End-to-End-Integrationstests durchgeführt werden. Gamma validiert, dass der Code sowohl funktionsfähig ist als auch sicher zur Produktion bereitgestellt werden kann. Gamma ist so produktionsähnlich wie möglich, einschließlich der gleichen Bereitstellungskonfiguration, der gleichen Überwachung und Alarme und der gleichen kontinuierlichen Canary-Tests wie in der Produktion. Gamma wird auch in mehreren AWS-Regionen bereitgestellt, um mögliche Auswirkungen der regionalen Unterschiede aufzufangen.
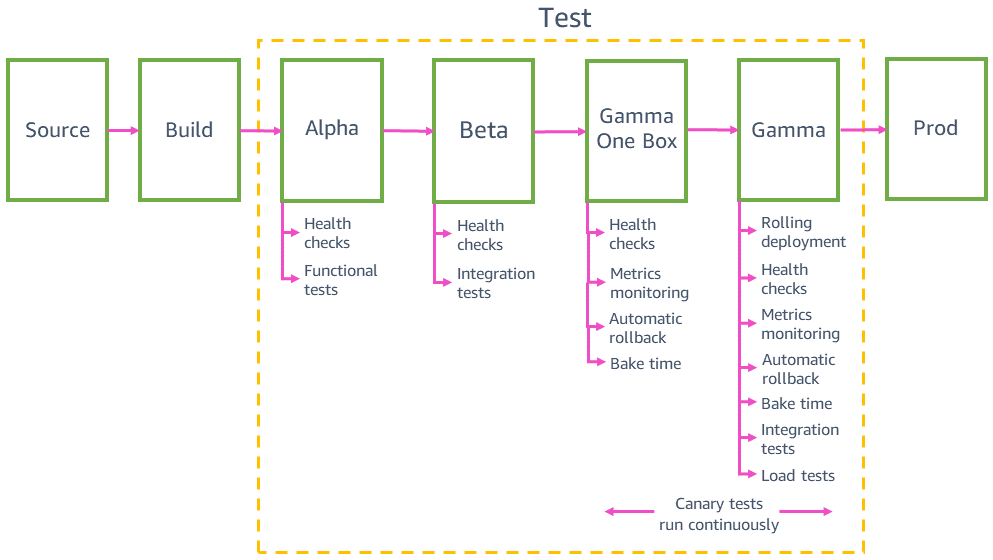
Integrationstests
Integrationstests helfen uns dabei, einen Service automatisch so zu nutzen, wie es Kunden als Teil der Pipeline tun. Diese Tests üben den kompletten Stack end-to-end aus, indem reale APIs, die auf einer realen Infrastruktur laufen, in jeder Vorproduktionsstufe für alle sinnvollen Kundenszenarien aufgerufen werden. Das Ziel von Integrationstests ist es, jedes unerwartete oder fehlerhafte Verhalten des Service zu erfassen, bevor er zur Produktion bereitgestellt wird.
Während Unit-Tests gegen gespottete Abhängigkeiten laufen, laufen Integrationstests gegen ein Vorproduktionssystem, das reale Abhängigkeiten aufruft und die Annahmen der Mocks über das Verhalten dieser Abhängigkeiten validiert. Integrationstests validieren das Verhalten der einzelnen APIs bei verschiedenen Inputs. Darüber hinaus validieren sie vollständige Workflows, die mehrere APIs verbinden, wie z. B. das Erstellen einer neuen Ressource, die Beschreibung der neuen Ressource, bis sie fertig ist, und die anschließende Verwendung der Ressource.
Integrationstests führen sowohl positive als auch negative Testfälle aus, wie z. B. die Bereitstellung einer ungültigen Eingabe an eine API und die Überprüfung, ob ein Fehler "ungültige Eingabe" wie erwartet zurückgegeben wird. Einige Pipelines führen einen Fuzz-Test durch, um viele mögliche API-Eingaben zu generieren und zu validieren, dass sie keine internen Fehler im Service verursachen. Einige Pipelines führen in einer Vorproduktionsphase auch einen kurzen Lasttest durch, um sicherzustellen, dass die neuesten Änderungen keine Latenz- oder Durchsatzrückgänge bei realen Lastniveaus verursachen.
Rückwärtskompatibilität und One-Box-Test
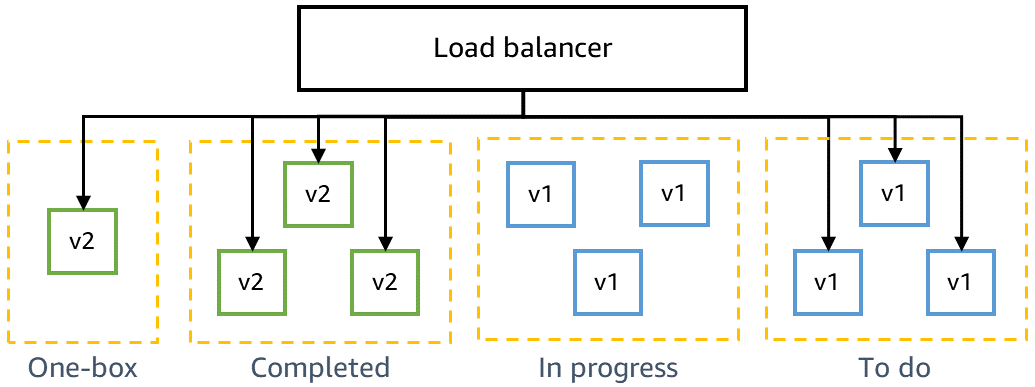
Vor der Bereitstellung für die Produktion müssen wir sicherstellen, dass der neueste Code rückwärtskompatibel ist und neben dem aktuellen Code sicher bereitgestellt werden kann. Zum Beispiel müssen wir erkennen, ob der neueste Code Daten in einem Format schreibt, das der aktuelle Code nicht parsen kann. In der Ein-Box-Stufe von Gamma wird der neueste Code in der kleinsten Einheit der Bereitstellung bereitgestellt, z. B. in einer einzelnen virtuellen Maschine oder einem einzelnen Container, oder in einem kleinen Prozentsatz der AWS Lambda-Funktionsaufrufe. Bei dieser One-Box-Bereitstellung wird der Rest der Gamma-Umgebung mit dem aktuellen Code für eine gewisse Zeit, z. B. 30 Minuten oder eine Stunde, bereitgestellt. Der Verkehr muss nicht extra zu der One-Box geleitet werden. Sie kann demselben Load Balancer hinzugefügt werden oder dieselbe Warteschlange wie der Rest der Gamma-Umgebung abfragen. In einer Gamma-Umgebung mit zehn Containern hinter einem Load Balancer beispielsweise erhält die One-Box zehn Prozent des Gamma-Verkehrs, der durch kontinuierliche Canary-Tests erzeugt wird. Der One-Box-Einsatz überwacht Canary-Erfolgsraten und Service-Metriken, um die Auswirkungen des Einsatzes oder der Bereitstellung einer "gemischten" Flotte nebeneinander zu erkennen.
Das folgende Diagramm zeigt den Zustand einer Gamma-Umgebung, nachdem neuer Code für die One-Box-Stufe bereitgestellt, aber noch nicht für den Rest der Gamma-Flotte bereitgestellt wurde:
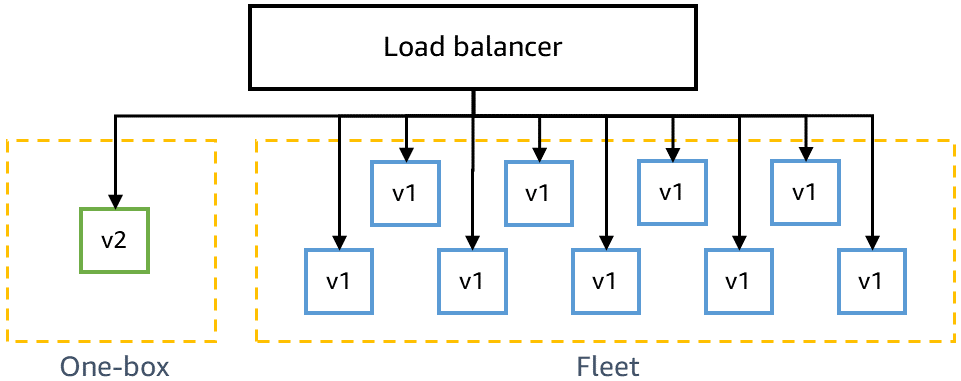
Wir müssen auch sicherstellen, dass der neueste Code mit unseren Abhängigkeiten rückwärtskompatibel ist, zum Beispiel wenn eine Änderung über Mikrodienste hinweg in einer bestimmten Reihenfolge vorgenommen werden muss. Mikroservices in Vorproduktionsumgebungen rufen in der Regel den Produktions-Endpunkt aller Services auf, die einem anderen Team gehören, wie z. B. Amazon Simple Storage Service (S3) oder Amazon DynamoDB, aber sie rufen den Vorproduktions-Endpunkt der anderen Mikroservices des Service-Teams in der gleichen Phase auf. Beispielsweise ruft der Mikroservice A eines Teams in Gamma den Mikroservice B desselben Teams in Gamma an, aber er ruft den Produktionsendpunkt für Amazon S3 an.
Einige Pipelines führen auch Integrationstests in einer separaten Abwärtskompatibilitätsphase durch, die wir Zeta nennen. Dabei handelt es sich um eine separate Umgebung, in der jeder Mikroservice nur die Produktionsendpunkte aufruft, um zu testen, ob Änderungen, die in die Produktion gehen, mit dem Code kompatibel sind, der derzeit in der Produktion über mehrere Mikroservices bereitgestellt wird. Zum Beispiel nennt Mikroservice A in Zeta den Produktendpunkt von Mikroservice B und den Produktionsendpunkt für Amazon S3.
Eine Beschreibung der Strategien für das Schreiben und Bereitstellen rückwärtskompatibler Änderungen finden Sie im Artikel aus der Builders' Library Gewährleistung der Rollback-Sicherheit bei Bereitstellungen.
Produktionsbereitstellungen
Unser Ziel Nr. 1 für Produktionsbereitstellungen bei AWS ist es, negative Auswirkungen auf mehrere Regionen zur gleichen Zeit und auf mehrere Availability Zones in derselben Region zu verhindern. Die Beschränkung des Umfangs jeder einzelnen Bereitstellung begrenzt die potenziellen Auswirkungen auf die Kunden durch fehlgeschlagene Produktionsbereitstellungen und verhindert eine Auswirkung auf mehrere Availability Zones oder Regionen. Um den Umfang der automatischen Bereitstellungen zu begrenzen, teilen wir die Produktionsphase der Pipeline in viele Phasen und viele Bereitstellungen in einzelnen Regionen auf. Die Teams teilen regionale Einsätze in noch kleinere Einsätze auf, indem sie sie in einzelne Availability Zones oder in die einzelnen internen Scherben (aufgerufene Zellen) ihres Services in ihrer Pipeline bereitstellen, um das Ausmaß der möglichen Auswirkungen eines fehlgeschlagenen Produktionseinsatzes weiter zu begrenzen.
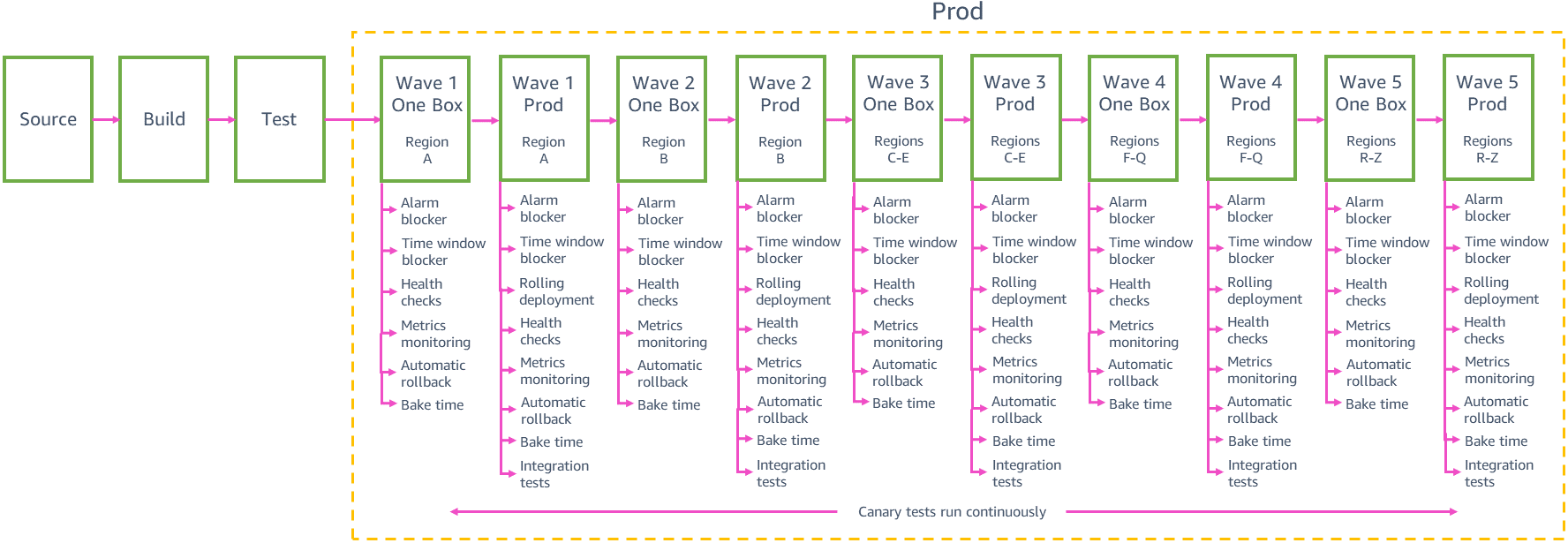
Gestaffelte Bereitstellungen
Jedes Team muss ein ausgewogenes Verhältnis zwischen der Sicherheit von Einsätzen mit kleinem Umfang und der Geschwindigkeit, mit der wir Kunden in allen Regionen Änderungen bereitstellen können, finden. Die Bereitstellung von Änderungen in 24 Regionen oder 76 Availability Zones durch die Pipeline nacheinander hat das geringste Risiko, Breitenwirkung zu erzielen, aber es könnte Wochen dauern, bis die Pipeline eine Änderung an Kunden weltweit liefert. Wir haben festgestellt, dass die Gruppierung von Bereitstellungen in "Wellen" von zunehmender Größe, wie in der vorhergehenden Beispielprojektpipeline zu sehen war, uns hilft, ein gutes Gleichgewicht zwischen Bereitstellungsrisiko und Geschwindigkeit zu erreichen. Die Phase jeder Welle in der Pipeline orchestriert Bereitstellungen für eine Gruppe von Regionen, wobei Änderungen von Welle zu Welle gefördert werden. Neue Änderungen können jederzeit in die Produktionsphase der Pipeline eintreten. Nachdem in Welle 1 ein Satz von Änderungen vom ersten Schritt in den zweiten Schritt befördert wurde, wird der nächste Satz von Änderungen von Gamma in den ersten Schritt der Welle 1 befördert, damit wir am Ende nicht mit großen Paketen von Änderungen dastehen, die darauf warten, zur Produktion bereitgestellt zu werden.
Die ersten beiden Wellen in der Pipeline schaffen das größte Vertrauen in den Wandel: Die erste Welle wird in einer Region mit einer geringen Anzahl von Anfragen bereitgestellt, um die möglichen Auswirkungen der ersten produktiven Bereitstellung der neuen Änderung zu begrenzen. Die Welle wird jeweils nur in jeweils einer Availability Zone (oder Zelle) innerhalb dieser Region bereitgestellt, um die Änderung in der gesamten Region behutsam umzusetzen. Die zweite Welle wird dann jeweils in einer Availability Zone (oder Zelle) in einer Region mit einer hohen Anzahl von Anfragen bereitgestellt, in der es sehr wahrscheinlich ist, dass die Kunden alle neuen Codepfade üben werden und in der wir eine gute Validierung der Änderungen erhalten.
Nachdem wir nach den ersten Pipeline-Wellen mehr Vertrauen in die Sicherheit des Wechsels haben, können wir mehr und mehr Regionen parallel in derselben Welle bereitstellen. Beispielsweise wird die Pipeline der vorherigen Stichprobe in drei Regionen in Welle 3 bereitgestellt, dann in bis zu 12 Regionen in Welle 4, dann in den verbleibenden Regionen in Welle 5. Die genaue Anzahl und Auswahl der Regionen in jeder dieser Wellen und die Anzahl der Wellen in der Pipeline eines Serviceteams hängen von den Nutzungsmustern und dem Umfang des einzelnen Service ab. Die späteren Wellen in der Pipeline helfen uns immer noch, unser Ziel zu erreichen, negative Auswirkungen auf mehrere Availability Zones in derselben Region zu verhindern. Wenn eine Welle in mehreren Regionen parallel bereitgestellt wird, folgt sie für jede Region dem gleichen vorsichtigen Rollout-Verhalten, das in den ersten Wellen verwendet wurde. Jeder Schritt in der Welle stellt nur eine einzige Availability Zone oder Zelle aus jeder Region der Welle bereit.
One-Box- und rollierende Bereitstellungen
Die Bereitstellung für jede Produktionswelle beginnt mit einer One-Box-Stufe. Wie in der Gamma One-Box-Stufe stellt jede Prod One-Box-Stufe den neuesten Code für eine Box (eine einzelne virtuelle Maschine, einen einzelnen Container oder einen kleinen Prozentsatz der Aufrufe von Lambda-Funktionen) in jeder der Regionen oder Availability Zones der Welle bereit. Die Bereitstellung von Prod One-Box minimiert die potentiellen Auswirkungen von Änderungen auf die Welle, indem zunächst die Anfragen, die von dem neuen Code in dieser Welle bedient werden, begrenzt werden. In der Regel bedient die One-Box höchstens zehn Prozent der gesamten Anfragen für die Region oder Availability Zone. Wenn die Änderung eine negative Auswirkung in der One-Box verursacht, rollt die Pipeline die Änderung automatisch zurück und fördert sie nicht auf die übrigen Produktionsstufen.
Nach der One-Box-Phase verwenden die meisten Teams rollende Bereitstellungen, um die Hauptproduktionsflotte der Welle bereitzustellen. Eine rollende Bereitstellung stellt sicher, dass der Service über genügend Kapazität verfügt, um die Produktionslast während des gesamten Einsatzes zu bedienen. Sie steuert die Geschwindigkeit, mit der der neue Code in Betrieb genommen wird (d. h. ab dem Zeitpunkt, ab dem er den Produktionsverkehr bedient), um die Auswirkungen von Änderungen zu begrenzen. Bei einer typischen rollenden Bereitstellung in einer Region werden höchstens 33 Prozent der Boxen des Service in dieser Region (Container, Lambda-Aufrufe oder Software, die auf virtuellen Maschinen läuft) durch den neuen Code ersetzt.
Während einer Bereitstellung wählt das Bereitstellungssystem zunächst einen ersten Stapel von bis zu 33 Prozent der Boxen aus, die durch den neuen Code ersetzt werden sollen. Während der Ablösung sind mindestens 66 Prozent der Gesamtkapazität gesund und bedienen die Anfragen. Alle Services sind so skaliert, dass sie dem Verlust einer Availability Zone in der Region standhalten, so dass wir wissen, dass der Service auch bei dieser Kapazität die Produktionslast noch bedienen kann. Nachdem das Bereitstellungssystem festgestellt hat, dass eine Box aus der ersten Charge von Kisten die Gesundheitskontrollen durchläuft, kann eine Kiste aus der verbleibenden Flotte durch den neuen Code ersetzt werden, und so weiter. In der Zwischenzeit halten wir immer noch ein Minimum von 66 Prozent der Kapazität aufrecht, um Anfragen jederzeit bedienen zu können. Um die Auswirkungen von Änderungen weiter zu begrenzen, werden in den Pipelines einiger Teams jeweils nur fünf Prozent ihrer Boxen bereitgestellt. Dann jedoch führen sie schnelle Rollbacks durch, bei denen das System 33 Prozent der Boxen auf einmal durch den vorherigen Code ersetzt, um das Rollback zu beschleunigen.
Das folgende Diagramm zeigt den Zustand einer Produktionsumgebung in der Mitte einer rollenden Bereitstellung. Der neue Code wurde für die "One-Box"-Stufe und für den ersten Batch der Hauptproduktflotte bereitgestellt. Ein weiterer Batch wurde aus dem Load Balancer entfernt und wird zum Austausch abgeschaltet.
Metriküberwachung und automatisches Rollback
Bei automatisierten Bereitstellungen in der Pipeline gibt es in der Regel keinen Entwickler, der jede bereitzustellende Bereitstellung aktiv überwacht, die Metriken prüft und manuell zurücksetzt, wenn er Probleme feststellt. Diese Bereitstellungen erfolgen völlig unbemerkt. Das Bereitstellungssystem überwacht einen Alarm aktiv, um festzustellen, ob es einen Einsatz automatisch zurücknehmen muss. Ein Rollback schaltet die Umgebung zurück auf das Container-Image, das Paket zur Bereitstellung der AWS Lambda-Funktion oder das interne Bereitstellungspaket, das zuvor bereitgestellt wurde. Unsere internen Bereitstellungspakete ähneln den Container-Images, da die Pakete unveränderlich sind und eine Prüfsumme verwenden, um ihre Integrität zu überprüfen.
Jeder Mikroservice in jeder Region verfügt in der Regel über einen hochgradigen Alarm, der bei Schwellenwerten für die Metriken, die sich auf die Kunden des Service auswirken (wie Fehlerraten und hohe Latenzzeiten), und bei Metriken für den Systemzustand (wie die CPU-Auslastung) ausgelöst wird, wie im folgenden Beispiel dargestellt. Dieser hochempfindliche Alarm wird verwendet, um den Bereitschaftsdiensttechniker zu rufen und den Service automatisch zurückzusetzen, wenn eine Bereitstellung erfolgt. Häufig ist das Rollback bereits im Gange, wenn der Bereitschaftsdiensttechniker angepiept wurde und mit dem Eingriff beginnt.
Beispiel eines hochgradigen Mikroservice-Alarms
ALARM("FrontEndApiService_High_Fault_Rate") ODER
ALARM("FrontEndApiService_High_P50_Latency") ODER
ALARM("FrontEndApiService_High_P90_Latency") ODER
ALARM("FrontEndApiService_High_P99_Latency") ODER
ALARM("FrontEndApiService_High_Cpu_Usage") ODER
ALARM("FrontEndApiService_High_Memory_Usage") ODER
ALARM("FrontEndApiService_High_Disk_Usage") ODER
ALARM("FrontEndApiService_High_Errors_In_Logs") ODER
ALARM("FrontEndApiService_High_Failing_Health_Checks")
Änderungen, die durch eine Bereitstellung eingeführt werden, können Auswirkungen auf vor- und nachgelagerte Mikrodienste haben, so dass das Bereitstellungssystem den Hochsicherheitsalarm für den Mikroservice, der gerade bereitgestellt wird, überwachen und die Hochsicherheitsalarme für die anderen Mikrodienste des Teams überwachen muss, um zu bestimmen, wann ein Rollback erfolgen soll. Eingestellte Änderungen können auch die Metriken der kontinuierlichen Canary-Tests beeinflussen, so dass das Bereitstellungssystem zusätzlich auf fehlgeschlagene Canary-Tests überwachen muss. Um alle diese möglichen Wirkungsbereiche automatisch wieder in den Griff zu bekommen, erstellen die Teams hochgradige Sammelalarme, die vom Bereitstellungssystem überwacht werden. Hochgradige Sammelalarme rollen den Zustand aller einzelnen hochgradigen Mikroservice-Alarme des Teams und den Zustand der Canary-Alarme zu einem einzigen Sammelzustand zusammen, wie im folgenden Beispiel dargestellt. Wenn einer der hochrangigen Alarme für die Mikrodienste des Teams in den Alarmzustand gerät, werden alle laufenden Bereitstellungen des Teams für alle ihre Mikrodienste in dieser Region automatisch zurückgesetzt.
Beispiel eines hochgradigen Aggregat-Rollback-Alarms
ALARM("FrontEndApiService_High_Severity") ODER
ALARM("BackendApiService_High_Severity") ODER
ALARM("BackendWorkflows_High_Severity") ODER
ALARM("Canaries_High_Severity")
Eine One-Box-Stufe bedient einen kleinen Prozentsatz des Gesamtverkehrs, so dass Probleme, die durch eine One-Box-Bereitstellung eingeführt werden, möglicherweise nicht den hochgradigen Rollback-Alarm des Service auslösen. Um Änderungen, die in der One-Box-Phase Probleme verursachen, aufzufangen und rückgängig zu machen, bevor sie den Rest der Produktionsstufen erreichen, werden in der One-Box-Phase zusätzlich Metriken rückgängig gemacht, die sich nur auf die One-Box-Phase beziehen. So wird beispielsweise die Fehlerquote bei den Anforderungen, die speziell durch die One Box bedient wurden, zurückgenommen, die nur einen kleinen Prozentsatz der Gesamtzahl der Anforderungen ausmacht.
Beispiel für einen One-Box-Rollback-Alarm
ALARM("High_Severity_Aggregate_Rollback_Alarm") ODER
ALARM("FrontEndApiService_OneBox_High_Fault_Rate") ODER
ALARM("FrontEndApiService_OneBox_High_P50_Latency") ODER
ALARM("FrontEndApiService_OneBox_High_P90_Latency") ODER
ALARM("FrontEndApiService_OneBox_High_P99_Latency") ODER
ALARM("FrontEndApiService_OneBox_High_Cpu_Usage") ODER
ALARM("FrontEndApiService_OneBox_High_Memory_Usage") ODER
ALARM("FrontEndApiService_OneBox_High_Disk_Usage") ODER
ALARM("FrontEndApiService_OneBox_High_Errors_In_Logs") ODER
ALARM("FrontEndApiService_OneBox_Failing_Health_Checks")
Zusätzlich zur Rücknahme von Alarmen, die vom Serviceteam definiert wurden, kann unser Bereitstellungssystem auch Anomalien in gemeinsamen Metriken, die von unserem internen Web-Service-Framework ausgegeben werden, erkennen und automatisch zurücknehmen. Die meisten unserer Mikroservices geben Metriken wie die Anzahl der Anfragen, die Latenzzeit der Anfragen und die Anzahl der Fehler in einem Standardformat aus. Unter Verwendung dieser Standardmetriken kann das Bereitstellungssystem automatisch einen Rollback durchführen, wenn es während einer Bereitstellung zu Anomalien in den Metriken kommt. Beispiele hierfür sind, wenn die Anzahl der Anfragen plötzlich auf null fällt, oder wenn die Latenz oder die Anzahl der Fehler viel höher als normal ist.
Bake-Zeit
Manchmal ist eine negative Auswirkung, die durch eine Bereitstellung verursacht wird, nicht ohne Weiteres erkennbar. Sie brennt langsam. Das heißt, sie taucht nicht sofort während der Bereitstellung auf, vor allem dann nicht, wenn der Service zu diesem Zeitpunkt unter geringer Last steht. Die Förderung des Wechsels zur nächsten Pipeline-Stufe unmittelbar nach Abschluss der Bereitstellung kann sich in mehreren Regionen auswirken, wenn die Auswirkungen in der ersten Region sichtbar werden. Bevor ein Wechsel zur nächsten Produktionsstufe gefördert wird, hat jede Produktionsstufe in der Pipeline eine Bake-Zeit, d. h. wenn die Pipeline nach Abschluss einer Bereitstellung und vor dem Übergang zur nächsten Stufe weiterhin den hochschnellen Aggregatalarm des Teams auf langsam brennende Auswirkungen überwacht.
Bei der Berechnung der Zeit, die wir für das Backen einer Bereitstellung aufwenden, müssen wir das Risiko, eine breitere Wirkung zu erzielen, wenn wir Änderungen in mehreren Regionen zu schnell vorantreiben, gegen die Geschwindigkeit abwägen, mit der wir Kunden weltweit Änderungen bereitstellen können. Wir haben festgestellt, dass eine gute Möglichkeit, diese Risiken auszugleichen, darin besteht, dass frühere Wellen in der Pipeline eine längere Bake-Zeit haben, während wir Vertrauen in die Sicherheit der Änderung aufbauen, und dass spätere Wellen eine kürzere Bake-Zeit haben. Unser Ziel ist es, das Risiko einer Auswirkung zu minimieren, die mehrere Regionen betrifft. Da die meisten Bereitstellungen nicht aktiv von einem Teammitglied beobachtet werden, sind die Standard-Bake-Zeiten der typischen Pipeline konservativ und werden eine Änderung in allen Regionen in etwa vier oder fünf Werktagen bereitstellen. Services, die größer oder höchst kritisch sind, haben noch konservativere Bake-Zeiten und Zeiten für ihre Pipelines, um eine Veränderung global bereitzustellen.
Eine typische Pipeline wartet mindestens eine Stunde nach jeder One-Box-Phase, mindestens 12 Stunden nach der ersten regionalen Welle und mindestens zwei bis vier Stunden nach jeder der übrigen regionalen Wellen, wobei für einzelne Regionen, Availability Zones und Zellen innerhalb jeder Welle eine zusätzliche Bake-Zeit vorgesehen ist. Die Bake-Zeit umfasst die Anforderung, auf eine bestimmte Anzahl von Datenpunkten in den Metriken des Teams zu warten (z. B. "Warten auf mindestens 100 Anfragen an die Erstellungs-API"), um sicherzustellen, dass genügend Anfragen aufgetreten sind, so dass es wahrscheinlich ist, dass der neue Code vollständig ausgeführt wurde. Während der gesamten Bake-Zeit wird die Bereitstellung automatisch zurückgenommen, wenn der hochgradige Aggregatalarm des Teams in den Alarmzustand geht.
Auch wenn dies äußerst selten vorkommt, kann es in einigen Fällen erforderlich sein, dass eine dringende Änderung (wie z. B. eine Sicherheitskorrektur oder eine Entschärfung für ein Großereignis mit Auswirkungen auf die Verfügbarkeit des Service) schneller an die Kunden geliefert werden muss als die Zeit, die die Pipeline normalerweise benötigt, um Änderungen zu baken und bereitzustellen. In diesen Fällen können wir die Bake-Zeit der Pipeline herabsetzen, um die Bereitstellung zu beschleunigen, aber wir benötigen dazu ein hohes Maß an Kontrolle über die Änderung. Für diese Fälle benötigen wir die Überprüfung durch die Chefingenieure der Organisation. Das Team muss die Code-Änderung sowie ihre Dringlichkeit und das Risiko von Auswirkungen mit sehr erfahrenen Entwicklern überprüfen, die Experten für Betriebssicherheit sind. Der Wechsel durchläuft nach wie vor die gleichen Schritte in der Pipeline wie üblich, wird aber schneller in die nächste Stufe befördert. Wir begegnen dem Risiko einer schnelleren Bereitstellung, indem wir die in dieser Zeit anstehenden Flugänderungen begrenzen, um nur die minimalsten Code-Änderungen zuzulassen, die zur Lösung des aktuellen Problems erforderlich sind, und indem wir die Bereitstellungen aktiv beobachten.
Alarm- und Zeitfenster-Blockierer
Die Pipeline verhindert automatische Bereitstellungen für die Produktion, wenn ein höheres Risiko besteht, negative Auswirkungen zu verursachen. Die Pipeline verwendet eine Reihe von "Blockierern", die das Bereitstellungsrisiko bewerten. Beispielsweise könnte die automatische Bereitstellung einer neuen Änderung für die Prod, wenn ein Problem in der Umgebung gerade läuft, die Auswirkungen verschlimmern oder verlängern. Vor Beginn einer neuen Bereitstellung für eine bestimmte Produktionsstufe prüft die Pipeline den hochrangigen Gesamtalarm des Teams, um festzustellen, ob es aktive Probleme gibt. Wenn sich der Alarm gerade im Alarmzustand befindet, verhindert die Pipeline, dass die Änderung voranschreitet. Pipelines können auch unternehmensweite Alarme überprüfen, wie z. B. einen Großereignis-Alarm, der anzeigt, ob es eine Breitenwirkung in den Systemen eines anderen Teams gibt, und verhindert, dass ein neuer Einsatz bereitgestellt wird, der die Gesamtwirkung verstärken könnte. Diese Bereitstellungsblockierer können von den Entwicklern außer Kraft gesetzt werden, wenn eine Änderung bereitgestellt werden muss, um sich von einem hochbrisanten Problem zu erholen.
Die Pipeline ist außerdem mit einer Reihe von Zeitfenstern konfiguriert, die festlegen, wann eine Bereitstellung gestartet werden darf. Wenn wir Zeitfenster konfigurieren, müssen wir zwei Ursachen für das Risiko der Bereitstellung gegeneinander abwägen. Einerseits können sehr kleine Zeitfenster dazu führen, dass sich Änderungen in der Pipeline stapeln, während das Zeitfenster geschlossen ist, was die Wahrscheinlichkeit erhöht, dass eine dieser Änderungen beim nächsten Bereitstellen Auswirkungen hat, wenn sich das Zeitfenster öffnet. Auf der anderen Seite erhöhen sehr große Zeitfenster, die über die regulären Geschäftszeiten hinausgehen, das Risiko, die Auswirkungen einer fehlgeschlagenen Bereitstellung zu verlängern. Außerhalb der Geschäftszeiten dauert es länger, den Bereitschaftsdiensttechniker einzuschalten, als tagsüber, wenn der Bereitschaftsdiensttechniker und andere Teammitglieder arbeiten. Während der regulären Geschäftszeiten kann das Team nach einer fehlgeschlagenen Bereitstellung schneller eingesetzt werden, falls manuelle Wiederherstellungsschritte erforderlich sind.
Die meisten Bereitstellungen werden nicht aktiv von einem Teammitglied überwacht, daher optimieren wir die zeitliche Planung der Bereitstellungen, um die Zeit für die Einschaltung eines Bereitschaftstechnikers zu minimieren, falls nach einem automatischen Rollback manuelle Maßnahmen zur Wiederherstellung erforderlich sind. Bereitschaftsdienstingenieure benötigen in der Regel nachts, an Feiertagen im Büro und an Wochenenden länger, so dass diese Zeiten nicht in die Zeitfenster einbezogen werden. Je nach den Nutzungsmustern des Service tauchen einige Probleme möglicherweise erst Stunden nach der Bereitstellung auf, so dass viele Teams auch Freitage und Bereitstellungen am späten Nachmittag von ihrem Zeitfenster ausschließen, um das Risiko zu verringern, dass der Bereitschaftsdiensttechniker nachts oder am Wochenende nach einer Bereitstellung eingesetzt werden muss. Wir haben festgestellt, dass dieser Satz von Zeitfenstern eine schnelle Wiederherstellung auch dann ermöglicht, wenn ein manuelles Eingreifen erforderlich ist, dass er dafür sorgt, dass die Bereitschaftsdienste außerhalb der regulären Arbeitszeiten weniger in Anspruch genommen werden und eine kleine Anzahl von Änderungen gebündelt wird, während die Zeitfenster geschlossen sind.
Pipelines als Code
Das typische AWS-Serviceteam besitzt viele Pipelines, um die verschiedenen Mikroservices und Quelltypen des Teams (Anwendungscode, Infrastrukturcode, Betriebssystem-Patches usw.) bereitzustellen. Jede Pipeline hat viele Bereitstellungsphasen für eine ständig wachsende Zahl von Regionen und Availability Zones. Dies bedeutet für das Team viel Konfigurationsaufwand für die Verwaltung im Pipelinesystem, im Bereitstellungssystem und im Alarmsystem sowie viel Aufwand, um sich über die neuesten bewährten Methoden und über neue Regionen und Availability Zones auf dem Laufenden zu halten. In den letzten Jahren haben wir uns dafür eingesetzt, "Pipelines als Code" zu praktizieren, um sichere, aktuelle Pipelines einfacher und konsistenter zu konfigurieren, indem wir diese Konfiguration im Code modellieren. Unsere internen Pipelines als Code-Tool holen Daten aus einer zentralisierten Liste von Regionen und Availability Zones, um neue Regionen und Availability Zones einfach zu den Pipelines in AWS hinzuzufügen. Das Tool ermöglicht es Teams auch, Pipelines durch Vererbung zu modellieren, indem es Konfigurationen definiert, die in den Pipelines eines Teams in einer übergeordneten Klasse gemeinsam sind (z. B. welche Regionen in jede Welle gehen und wie lange die Bake-Zeit für jede Welle sein soll), und indem es die gesamte Pipeline-Konfiguration der Mikroservices als Unterklasse definiert, die die gesamte gemeinsame Konfiguration erbt.
Zusammenfassung
Bei Amazon haben wir unsere automatisierten Bereitstellungspraktiken im Laufe der Zeit auf der Grundlage dessen entwickelt, was uns hilft, die Sicherheit der Bereitstellung gegen die Geschwindigkeit der Bereitstellung abzuwägen. Gleichzeitig wollen wir den Zeitaufwand für die Entwickler minimieren, die sich um die Bereitstellung kümmern müssen. Durch den Einbau einer automatisierten Bereitstellungssicherheit in den Bereitstellungsprozess durch umfangreiche Vorproduktionstests, automatische Rollbacks und gestaffelte Produktionsbereitstellungen können wir die potenziellen Auswirkungen auf die Produktion durch Bereitstellungen minimieren. Das bedeutet, dass die Entwickler nicht aktiv die Bereitstellung in der Produktion beobachten müssen.
Bei vollautomatisierten Pipelines verwenden Entwickler Code-Prüfungen, um ihren Code zu überprüfen und auch um zu bestätigen, dass die Änderung produktionsbereit ist. Nachdem die Änderung in das Quellcode-Repository eingearbeitet ist, kann der Entwickler mit der nächsten Aufgabe fortfahren und die Bereitstellung vergessen und darauf vertrauen, dass die Pipeline ihre Änderung sicher und vorsichtig in die Produktion bringt. Die automatisierte Pipeline sorgt dafür, dass sie mehrmals am Tag kontinuierlich für die Produktion bereitgestellt wird, wobei Sicherheit und Geschwindigkeit im Gleichgewicht sind. Indem wir unsere Praxis der kontinuierlichen Lieferung in Code modellieren, ist es für AWS-Service-Teams einfacher denn je, ihre Pipelines so einzurichten, dass sie ihre Code-Änderungen automatisch und sicher bereitstellen können.
Weitere Lektüre
Weitere Informationen zur Verbesserung der Sicherheit und Verfügbarkeit von Diensten durch Amazon bei gleichzeitiger Steigerung der Kundenzufriedenheit und der Entwicklerproduktivität finden Sie unter Schneller mit kontinuierlicher Lieferung.
Eine Beschreibung der Strategien für das Schreiben und Bereitstellen rückwärtskompatibler Änderungen finden Sie im Artikel aus der Builders' Library Gewährleistung der Rollback-Sicherheit bei Bereitstellungen.
Über den Autor
Clare Liguori ist Principal Software Engineer bei AWS. Zurzeit arbeitet sie an der Entwickler-Erfahrung für AWS Container Services und entwickelt Tools an der Kreuzung von Containern und Software-Entwicklungszyklus: lokale Entwicklung, Infrastruktur als Code, CI/CD, Beobachtbarkeit und Betrieb.

Ähnliche Inhalte
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern