Aufbau von Dashboards für operative Sichtbarkeit
Softwarebereitstellung und -betrieb | LEVEL 300
Einführung
Wir alle führen Anwendungen auf unseren Laptops, Tablets und Smartphones aus. Wir können problemlos einsehen, ob das Gerät mit Strom versorgt wird und ob die WLAN-Verbindung online ist. Wir wissen, dass auf unseren Bildschirmen wichtige Benachrichtigungen angezeigt werden, wie etwa Warnungen über geringen freien Speicherplatz. Tatsächlich kann die allgemeine Geschwindigkeit und Reaktivität der Benutzerschnittstelle (UI) Aufschluss darüber geben, ob das Gerät über ausreichend Ressourcen verfügt (wie Speicher oder CPU), um unsere Anwendungen auszuführen.
Jeder, der schon einmal aus der Entfernung technischen Support für die eigene Familie geleistet hat, wird bestätigen können, dass es etwas schwieriger ist, Probleme zu erkennen und zu diagnostizieren, wenn man das Gerät nicht sehen und nicht direkt damit interagieren kann. Bei der Ausführung von cloudbasierten Services sehen wir uns einer ähnlichen Herausforderung gegenüber: Wie überwachen wir diese Remote-Services, und wie wissen wir, dass unsere Kunden zufrieden sind?
Wenn wir einen Single-Host-Service prüfen möchten, können wir uns bei diesem Host anmelden, eine Vielzahl von Laufzeitüberwachungs-Tools ausführen und Protokolle durchgehen, um die Ursache dafür zu ermitteln, was im Host passiert. Single-Host-Lösungen sind aber nur bei den einfachsten, nicht unkritischen Services praktikabel. Das andere Extrem sind mehrstufige, verteilte Microservices, die auf Hunderten oder Tausenden Servern, Containern oder in serverlosen Umgebungen laufen.
Wie sieht Amazon, wie sich alle cloudbasierten Services, die in zahlreichen Availability Zones in mehreren Regionen der Welt laufen, tatsächlich verhalten? Automatisierte Überwachung, automatisierte Abhilfe-Workflows (zum Beispiel Datenverkehrsverlagerung) und automatisierte Bereitstellungsdienste spielen bei der Erkennung und Lösung eines Großteils der Probleme dieser Größenordnung eine entscheidende Rolle. Dennoch gibt es zahlreiche Gründe, weswegen wir jederzeit sehen können müssen, was diese Services, Workflows und Bereitstellungen gerade tun.
Dashboarding bei Amazon
Wir verwenden Dashboards als einen Mechanismus, um den Überblick über die Aktivität in unseren Cloud-Services behalten zu können. Dashboards sind der für den Menschen einsehbare Einblick in unsere Systeme, die kurze Zusammenfassungen dazu geben, wie sich das System verhält. Dafür werden Zeitreihenmetriken, Protokolle, Traces und Alarmdaten angezeigt.
Bei Amazon bezeichnen wir die Erstellung, Nutzung und laufende Pflege dieser Dashboards als „Dashboarding“. Dashboarding hat sich zu einer First-Class-Aktivität entwickelt, da es ebenso wesentlich zum Erfolg unserer Services beiträgt wie andere täglich Softwarebereitstellungs- und -betriebsaktivitäten, wie der Entwurf, das Programmieren, der Aufbau, das Testen, die Bereitstellung und die Skalierung unserer Services.
Wir erwarten selbstverständlich nicht, dass unsere Betreiber die Dashboards pausenlos überwachen. Die meiste Zeit werden die Dashboards nicht betreut. Tatsächlich haben wir festgestellt, dass jegliche Betriebsprozesse, die eine manuelle Überprüfung von Dashboards beinhalten, aufgrund menschlichen Versagens scheitern werden, ganz egal, wie häufig die Dashboards überprüft werden. Um diesem Risiko entgegenzuwirken, haben wir automatisierte Alarme eingerichtet, die die wichtigsten von unseren Systemen ausgesendeten Überwachungsdaten ständig auswerten. Das sind für gewöhnlich Metriken, die entweder angeben, dass das System eine gewisse Grenze erreicht (proaktive Erkennung, vor Auswirkung) oder dass das System bereits auf unerwartete Weise beeinträchtigt ist (reaktive Erkennung, nach Auswirkung).
Diese Alarme können automatisierte Abhilfe-Workflows ausführen und unserer Betreiber über das Problem benachrichtigen. Die Benachrichtigung verweist den Betreiber auf die genauen Dashboards und zu verwendenden Runbooks. Wenn ich Bereitschaftsdienst habe und eine Alarmbenachrichtigung mich über ein Problem informiert, kann ich umgehend über zugehörige Dashboards die Auswirkung auf die Kunden quantifizieren, die Ursache validieren oder sichten, mitigieren und die Wiederherstellungszeit verkürzen. Selbst wenn der Alarm bereits einen automatisierten Abhilfe-Workflow ausgelöst hat, muss ich prüfen, was der automatisierte Workflow macht, welche Auswirkung er auf das System hat und, in Ausnahmefällen, bei sicherheitskritischen Schritten eine menschliche Bestätigung ausführen, damit der Workflow fortfahren kann.
Wenn ein Ereignis im Gang ist, beruft Amazon für gewöhnlich mehrere Betreiber im Bereitschaftsdienst ein. Die Betreiber führen unter Umständen bei unterschiedlichen Dashboards eine Reihe von Aufgaben aus. Zu diesen Aufgaben gehören für gewöhnlich Quantifizierung der Auswirkung auf die Kunden, Sichtung, Verfolgung über mehrere Services bis zur Grundursache des Ereignisses, Beobachtung der automatisierten Abhilfe-Workflows und Ausführung und Validierungen der auf Runbooks basierenden Eindämmungsschritte. Gleichzeitig nutzen Peer-Teams und Business Stakeholdern ebenfalls Dashboards, um die laufende Auswirkung während des Ereignisses zu überwachen. Diese verschiedenen Teilnehmer kommunizieren über Störfallmanagement-Tools, Chatrooms (mit Bots wie AWS Chatbot) und Telefonkonferenzen miteinander. Jeder Stakeholder bringt eine andere Sichtweise auf die in den Dashboards angezeigten Daten mit.
Darüber hinaus halten Amazon-Teams und breitere Organisationen wöchentlich Betriebsanalysemeetings ab, an denen leitende Führungskräfte, Manager und viele Ingenieure teilnehmen. Während dieser Meetings nutzen wir ein Glücksrad, um High-Level-Audit-Dashboards auszuwählen. Stakeholder überprüfen die Erfahrung unserer Kunden und wesentliche Ziele auf Serviceebene, wie Verfügbarkeit und Latenz. Die von diesen Stakeholdern verwendeten Audit-Dashboards zeigen für gewöhnlich Betriebsdaten aus allen Availability Zones und Regionen an.
Darüber hinaus verwendet Amazon bei der langfristigen Kapazitätenplanung und -prognose Dashboards, die höchstrangige Unternehmens-, Nutzungs- und Kapizitätsmetriken anzeigen, die unser System über längere Zeitintervalle aussendet.
Dashboard-Arten
Dashboards werden genutzt, um manuelle Services zu überwachen, aber es gibt nicht ein Dashboard, das für alle Anwendungsfälle geeignet ist. Für die meisten Systeme verwenden wir zahlreiche Dashboards, von denen jeder einzelne einen anderen Einblick in das System verschafft. Über diese unterschiedlichen Einblicke können verschiedene Benutzer nachvollziehen, wie sich unsere Systeme aus unterschiedlichen Perspektiven und über unterschiedliche Zeitintervalle verhalten.
Die Daten, die eine bestimmte Zielgruppe sehen möchte, kann von Dashboard zu Dashboard stark variieren. Wir haben gelernt, bei dem Dashboardentwurf die jeweilige Zielgruppe zu berücksichtigen. Wir entscheiden in Abhängigkeit davon, wer ein bestimmtes Dashboard verwenden wird und aus welchem Grund es verwendet werden wird, welche Daten in dieses Dashboard eingespeist werden. Sie haben vermutlich bereits gehört, dass wir bei Amazon vom Kunden ausgehend rückwärts arbeiten. Die Dashboarderstellung ist ein gutes Beispiel hierfür. Wir bauen Dashboards auf Grundlage der Bedürfnisse der erwarteten Benutzer und ihrer spezifischen Anforderungen.
Das folgende Diagramm zeigt, wie unterschiedliche Dashboards unterschiedliche Einblicke in das System als Ganzes verschaffen:
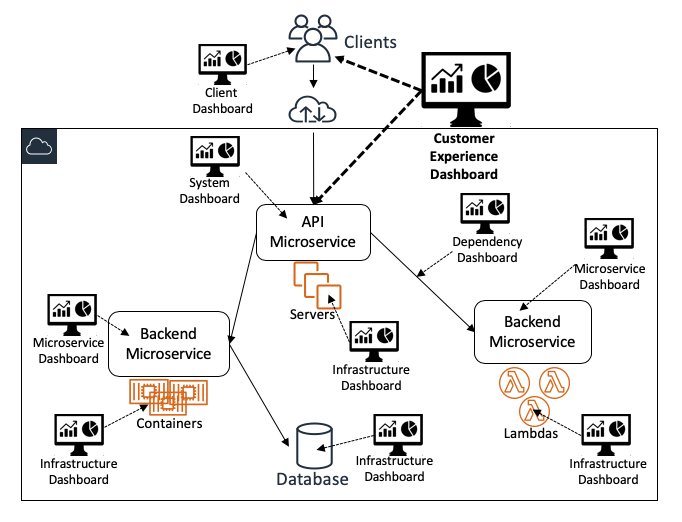
High-Level-Dashboards
Kundenerfahrungs-Dashboards
Die wichtigsten und meistgenutzten Dashboards bei Amazon sind Kundenerfahrungs-Dashboards. Diese Dashboards sind für die Nutzung durch eine breite Benutzergruppe konzipiert, darunter Servicebetreiber und viele andere Stakeholder. Sie zeigen auf effiziente Weise Metriken zum Gesamtzustand des Services und der Einhaltung von Zielen an. Sie zeigen Überwachungsdaten an, die vom Service selbst stammen sowie von Client-Instrumentierungen, fortlaufenden Testern (wie Canarys von Amazon CloudWatch Synthetics) und automatisierten Systemen zur Fehlerbehebung. Diese Dashboards enthalten zudem Daten, mit denen Benutzer Fragen in Bezug auf den Umfang der Auswirkungen beantworten können. Einige dieser Fragen lauten wahrscheinlich: „Wie viele Kunden sind betroffen?“ und „Welche Kunden sind am meisten betroffen?“
System-Level-Dashboards
Die Eintrittspunkte in unsere webbasierten Services sind für gewöhnlich UI- und API-Endpunkte. Daher müssen System-Level-Dashboards über ausreichend Daten verfügen, damit die Betreiber sehen, wie sich das System und seine kundenseitigen Endpunkte verhalten. Diese Dashboards zeigen vorrangig Überwachungsdaten auf Schnittstellenebene an. Diese Dashboards zeigen für jede API drei Überwachungsdatenkategorien an:
- Input-bezogene Überwachungsdaten. Dazu können Anzahl der aus Warteschlangen/Streams eingegangenen Anfragen oder befragten Aufträge, Bitgrößenperzentile der Anfragen und gescheiterten Authentifizierungs-/Autorisierungszählungen.
- Bearbeitungsbezogene Überwachungsdaten. Dazu können Anzahl der multimodalen Geschäftslogikpfade/Branch-Ausführung, Perzentile der Anzahl/Fehler/Latenz von Microservice-Anfragen, Stör- und Fehlerprotokollausgaben und Trace-Daten von Anfragen gehören.
- Output-bezogene Überwachungsdaten. Dazu können Anzahl von Anfragearten (mit Aufschlüsselung von Stör-/Fehlerantworten durch den Kunden), Größe der Antworten und Perzentile für Dauer bis zur Verfassung des ersten Antwort-Byte und Dauer bis zur Verfassung der vollständigen Antwort gehören.
Wir streben einen höchstmöglichen Standard dieser Kundenerfahrungs- und System-Level-Dashboards aufrechtzuerhalten. Wir widerstehen bewusst der Versuchung, diesen Dashboards zu viele Metriken hinzuzufügen, da eine Informationsflut von der eigentlichen Kernbotschaft, die dieser Dashboards vermitteln sollen, ablenken könnte.
Service-Instance-Dashboards
Wir bauen einige Dashboards, um die die schnelle und umfassende Beurteilung der Kundenerfahrung innerhalb einer Single-Service-Instance (Partition oder Zelle) zu erleichtern. Durch diese eingeschränkte Sicht wird sichergestellt, dass Betreiber, die an einer Single-Service-Instance arbeiten, nicht von unwichtigen Daten von anderen Service-Instances abgelenkt werden.
Service-Audit-Dashboards
Wir bauen zudem Kundenerfahrungs-Dashboards, die bewusst Daten für alle Instances eines Services in allen Availability Zones und Regionen anzeigen. Betreiber nutzen diese Service-Audit-Dashboards, um automatisierte Alarme in allen Service-Instances zu prüfen. Diese Alarme können auch während der oben erwähnten wöchentlichen Betriebsmeetings überprüft werden.
Dashboards für Kapazitätsplanung und -prognose
Bei längerfristigen Anwendungsfällen bauen wir außerdem Dashboards für Kapazitätsplanung und -prognose, anhand derer wir das Wachstum unserer Services sehen können.
Low-Level-Dashboards
Amazon APIs werden für gewöhnlich umgesetzt, indem Anfragen über Backend-Microservices orchestriert werden. Diese Microservices können unterschiedlichen Teams gehören, die für einige spezifische Aspekte der Bearbeitung der Anfrage verantwortlich sind. Einige Microservices sind beispielsweise auf die Authentifizierung und Autorisierung von Anfragen, die Durchsetzung von Drosselungen/Einschränkungen, das Erstellen/Aktualisieren/Löschen von Ressourcen, das Auffinden von Ressourcen aus Datenspeichern und das Starten asynchroner Workflows ausgerichtet. Die Teams bauen für gewöhnlich mindestens ein spezielles, Microservice-spezifisches Dashboards, das Metriken für jede API anzeigt bzw. für jede Arbeitseinheit, wenn der Service Daten asynchron verarbeitet.
Microservice-spezifische Dashboards
Dashboards für Microservices zeigen für gewöhnlich implementationsspezifische Überwachungsdaten, für die tiefgehende Kenntnisse über den Service erforderlich sind. Diese Dashboards werden vorrangig von den Teams genutzt, die der Service-Eigentümer sind. Da unsere Services aber stark instrumentiert sind, müssen wir die Daten aus dieser Instrumentierung so abbilden, dass sie Betreiber nicht verwirren. Aus diesem Grund zeigen diese Daten für gewöhnlich einige Daten in aggregierter Form an. Wenn Betreiber in den aggregierten Daten Anomalien entdecken, setzen sie für gewöhnlich eine Reise weitere Tools ein, um sich tiefere Einblicke zu verschaffen und Ad-hoc-Anfragen zu den zugrundliegenden Überwachungsdaten auszuführen, die die Daten aufschlüsseln, Anfragen nachzeichnen und verbundene oder korrelierte Daten aufzeigen.
Infrastruktur-Dashboards
Unsere Services werden auf AWS-Infrastruktur ausgeführt, die für gewöhnlich Metriken aussendet. Daher haben wir spezielle Infrastruktur-Dashboards. Diese Dashboards konzentrieren sich vorrangig auf die Metriken, die von den Compute-Ressourcen ,auf denen unsere Systeme laufen, ausgesendet werden, darunter Amazon Elastic Compute Cloud (EC2) Instances, Amazon Elastic Container Service (ECS)/Amazon Elastic Kubernetes Service (EKS) Containers und AWS-Lambda-Funktionen. In diesen Dashboards werden häufig Metriken wie CPU-Nutzung, Netzwerkverkehr, Festplatten-IO und Speichernutzung verwendet sowie alle verbundene Cluster-, Auto-Scaling- und Anteilmetriken, die für diese Compute-Ressourcen relevant sind.
Abhängigkeits-Dashboards
Neben Compute-Ressourcen hängen Microservices häufig von anderen Microservices ab. Selbst wenn die Teams, die Eigentümer dieser Abhängigkeiten sind, bereits über eigene Dashboards verfügen, erstellt jeder Microservice-Eigentümer für gewöhnlich eigene Abhängigkeits-Dashboards, um eine auf der Messung ihres Services basierende Übersicht darüber zu erhalten, wie sich sowohl Upstream (zum Beispiel Proxies und Load Balancers)- als auch Downstream (zum Beispiel Datenspeicher, Warteschlangen und Streams)-Abhängigkeiten verhalten. Mit diesen Dashboards können andere wichtige Metriken verfolgt werden, wie Ablaufdaten von Sicherheitszertifikaten und andere Abhängigkeitsanteilsverwendungen.
Dashboard-Aufbau
Bei Amazon sehen wir eine einheitliche Darstellung von Daten als eine entscheidende Komponente für die erfolgreiche Erstellung eines Dashboards. Die Einheitlichkeit muss in jedem Dashboards und übergreifend in allen Dashboards erreicht werden, um effektiv zu sein. Im Laufe der Jahre haben wir einen einheitlichen Formsprachen. und Konventionensatz identifiziert, angepasst und verfeinert, der unserer Überzeugung nach die Dashboards einer möglichst breiten Zielgruppe zugänglich macht und somit den Mehrwert der Dashboards für unser Unternehmen erhöht. Wir haben sogar diskrete Möglichkeiten ausgearbeitet, diese Formkonventionen im Laufe der Zeit zu messen und zu verbessern. Wenn ein neuer Betreiber zum Beispiel schnell die in den Dashboards angezeigten Daten verstehen und nutzen kann, um zu lernen, wie ein System funktioniert, weist das darauf hin, dass diese Dashboards die richtigen Informationen auf die richtige Weise anzeigen.
Häufig neigt man beim Aufbau von Dashboards dazu, die Domainkenntnisse des Zielbenutzers zu über- oder unterschätzen. Es ist leicht, ein Dashboard zu bauen, dass der Entwickler problemlos versteht. Ein solches Dashboard bietet aber unter Umständen den Benutzern keinen Mehrwert. Wir wenden die Methode der rückwärtslaufenden Arbeit ausgehend vom Kunden (in diesem Fall den Dashboard-Benutzern) an, um dieses Risiko zu verhindern.
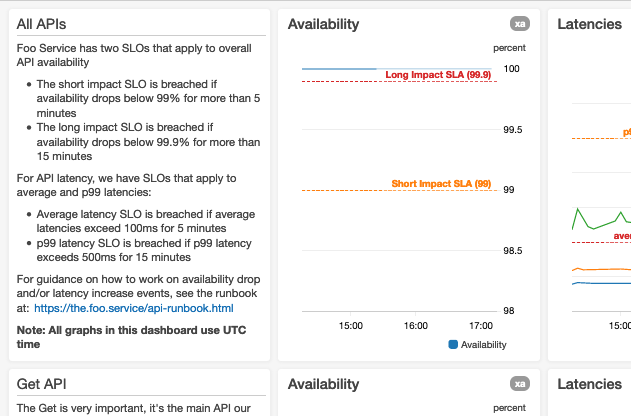
Wir haben eine Aufbaukonvention eingeführt, die die Darstellung von Daten in einem Dashboard standardisiert. Dashboards zeigen Daten von oben nach unten, und Benutzer neigen dazu, die zuerst angezeigten Graphen (die sichtbar sind, während das Dashboard lädt) als die wichtigsten anzusehen. Aus diesem Grund empfiehlt unsere Konvention, die wichtigsten Daten oben im Dashboard anzuzeigen. Unserer Erfahrung nach sind die aggregierten/zusammengefassten Verfügbarkeitsgraphen und die Graphen mit den End-to-End-Latenzperzentilen bei Webservices in der Regel die wichtigsten Dashboards.
Hier sehen Sie einen Screenshot des Dashboard-Seitenanfangs eines hypothetisches Foo-Services:
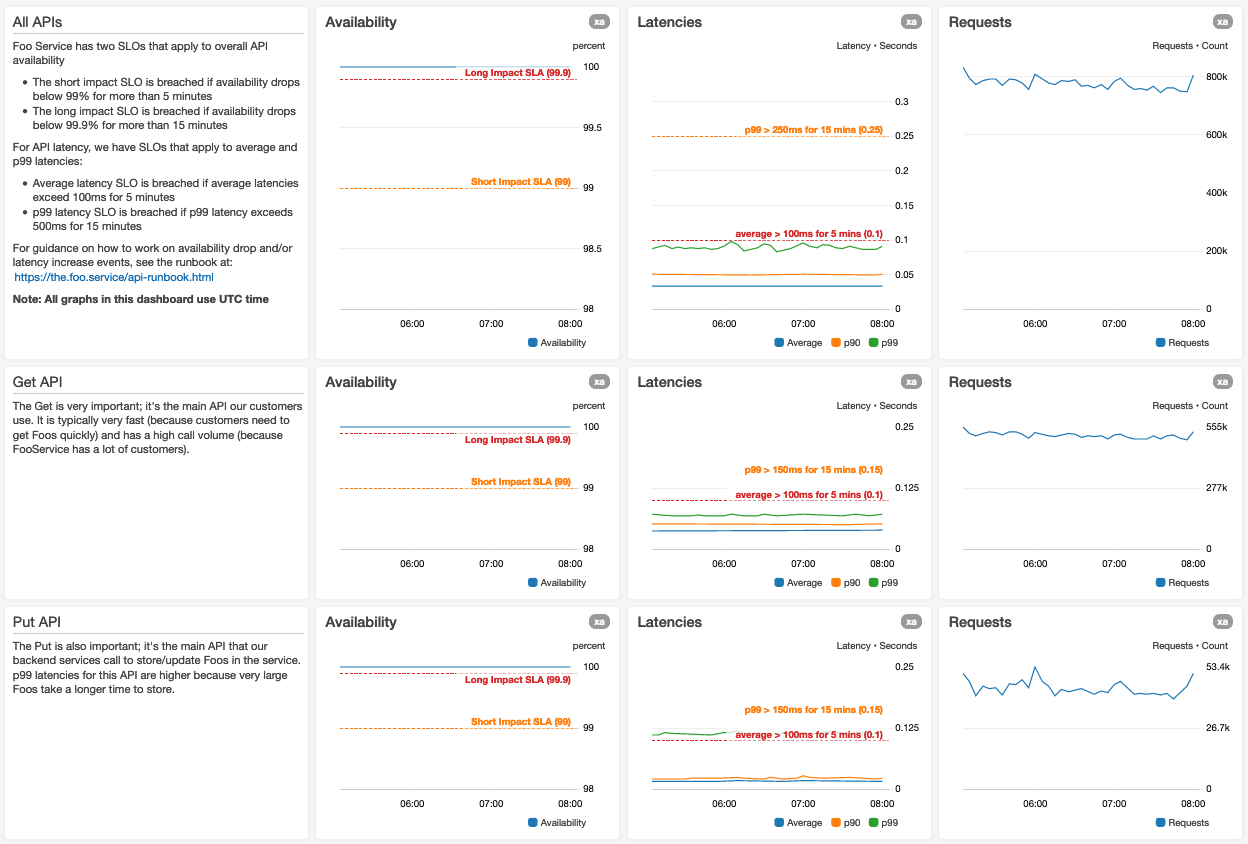
Für die wichtigsten Metriken nutzen wir größere Grafiken
Wenn in einem Graphen zahlreiche Metriken dargestellt sind, sorgen wir dafür, dass die Legende des Graphen die sichtbaren Graphdaten nicht vertikal oder horizontal staucht. Wenn wir in Graphen Suchanfragen verwenden, planen wir einen die normale Größe überschreitenden Satz an Metrikergebnissen ein.
Wir legen Graphen entsprechend der erwarteten Mindestauflösung an
Dadurch müssen Benutzer nicht horizontal scrollen. Ein Betreiber im Bereitschaftsdienst, der um 3:00 Uhr morgens am Laptop sitzt, wird den horizontalen Scroll-Balken ohne deutlich sichtbaren Hinweise, dass sich weiter rechts weitere Graphen befinden, womöglich übersehen.
Wir zeigen die Zeitzone an
Bei Dashboards, die Datums- und Zeitdaten anzeigen, wird die jeweilige Zeitzone im Dashboard angezeigt. Bei Dashboards, die von Betreibern in unterschiedlichen Zeitzonen genutzt werden, übernehmen wir eine Zeitzone (UTC) als Standardeinstellung, auf die alle Benutzer sich beziehen können. Auf diese Weise können die Benutzer unter Nutzung einer einzigen Zeitzone miteinander kommunizieren, ohne im Kopf die Zeitzonen ausrechnen zu müssen.
Wir verwenden den kürzesten Zeitintervall- und Datenpunktzeitraum
Wir übernehmen als Standardeinstellung den Zeitintervall- und Datenpunktzeitraum, der für die häufigsten Anwendungsfälle relevant ist. Wir stellen sicher, dass alle Graphen in einem Dashboard zunächst die Daten der gleichen Zeitspanne und -auflösung anzeigen. Unserer Erfahrung nach ist es von Vorteil, wenn alle Graphen innerhalb eines Dashboard-Abschnitts die gleiche horizontale Größe aufweisen. Dies ermöglicht einen einfachen zeitlichen Bezug zwischen den Graphen.
Außerdem vermeiden wir es, zu viele Datenpunkte in die Graphen einzutragen, da das die Ladezeit des Dashboards verlangsamt. Darüber hinaus haben wir beobachtet, dass die Anzeige zu vieler Datenpunkte dazu führen kann, das die Benutzer Anomalien übersehen. So wird der Graph mit einem dreistündigen Intervall und einem Datenpunkt pro Minute bei nur 180 Werten pro Metrik selbst in kleinen Dashboard-Widgets gut erkennbar angezeigt. Die Anzahl an Datenpunkten gibt den Betreibern, die laufende Betriebsereignisse sichten, zudem ausreichend Kontext.
Zeitintervall- und Metrikzeitraum können angepasst werden
In unseren Dashboards ist es möglich, für alle Graphen sowohl den Zeitintervall- als auch den Metrikzeitraum anzupassen. Weitere häufig in unseren Dashboards verwendete Intervall-zu-Auflösung-Verhältnisse sind:
- 1 Stunde x 1 Minute (60 Datenpunkte) – hilfreich, um laufende Ereignisse genau zu beobachten
- 12 Stunden x 1 Minute (720 Datenpunkte)
- 1 Tag x 5 Minuten (288 Datenpunkte) – hilfreich, um tägliche Trends zu visualisieren
- 3 Tage x 5 Minuten (864 Datenpunkte)
- 1 Woche x 1 Stunde (168 Datenpunkte) – hilfreich, um wöchentliche Trends zu visualisieren
- 1 Monat x 1 Stunde (744 Datenpunkte)
- 3 Monate x 1 Tag (90 Datenpunkte) – hilfreich, um vierteljährliche Trends zu visualisieren
- 9 Monate x 1 Tag (270 Datenpunkte)
- 15 Monate x 1 Tag (450 Datenpunkte) – hilfreich für langfristige Kapazitätsüberprüfungen
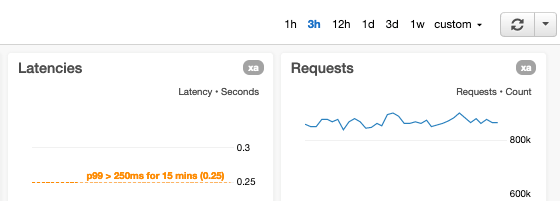
Wir versehen Graphen mit Alarmschwellen
Wenn wir Metriken mit verbundenen automatisierten Alarmen in Graphen abbilden, versehen wir die Graphen mit horizontalen Linien, falls die Alarmschwellen statisch sind. Wenn die Alarmschwellen dynamisch sind und demnach auf Prognosen oder Vorhersagen basieren, die von Künstlicher Intelligenz (KI) oder Machine Learning (MI) erzeugt werden, zeigen wir sowohl die tatsächlichen als auch die Schwellenmetriken im selben Graph an. Wenn ein Graph eine Metrik anzeigt, die einen Aspekt des Services mit bekannten Grenzen misst (wie die Grenze „maximal getestet“ oder eine harte Ressourcengrenze), erweitern wir den Graphen um eine horizontale Linie, die anzeigt, wie die bekannten oder getesteten Grenzen liegen. Bei Metriken, die Ziele haben, fügen wir horizontale Linien hinzu, damit diese Ziele für den Benutzer sofort erkenntlich sind.
Wir verzichten auf horizontale Linien in Graphen, die bereits eine linke und eine rechte Y-Achse verwenden
Wenn Sie diesen Graphen horizontale Linien hinzufügen, kann es für die Benutzer unter Umständen nicht leicht erkennbar sein, auf welche Y-Achse die horizontale Linie sich bezieht. Graphen dieser Art teilen wir daher in zwei Graphen mit jeweils einer horizontalen Achse auf und fügen nur dem Graphen horizontale Linien hinzu, auf dessen Y-Achse sich die Linien beziehen.
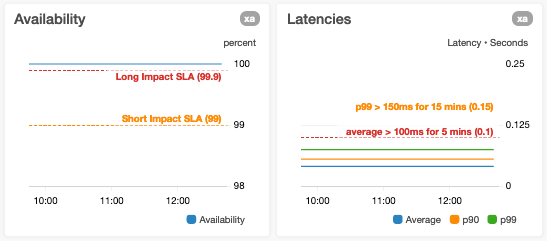
Wir vermeiden es, eine Y-Achse mit mehreren Metriken mit sehr unterschiedlichen Wertebereichen zu überladen
Wir vermeiden dies, da es zu einer schlechteren Sichtbarkeit von Abweichungen in einer oder mehreren Metriken führen kann. Ein Beispiel dafür ist, wenn wir die Latenzen p0 (Mindestwert) und p100 (Höchstwert) im selben Graph einzeichnen, in dem die Werte der p100-Datenpunkte größere Größenordnungen haben können als die p0-Datenpunkte.
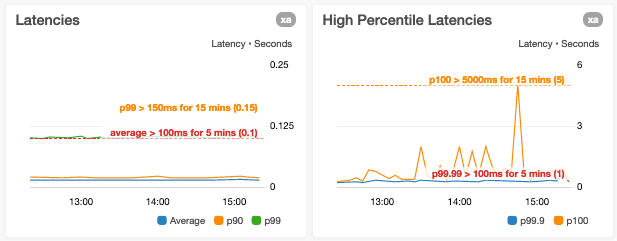
Wir sind vorsichtig, was die Verkleinerung der Y-Achsenrahmen nur auf den aktuellen Datenpunktbereich bezogen angeht
Ein flüchtiger Blick auf einen Graphen, dessen Y-Achse auf Datenpunktwerte reduziert ist kann Metriken deutlich variabler erscheinen lassen, als sie tatsächlich sind.
Wir vermeiden es, einzelne Graphen zu überladen
Wir möchten sicherstellen, dass wir in einem einzigen Graphen nicht zu viele Statistiken oder nicht in Beziehung stehende Metriken abbilden. Wenn wir zum Beispiel Graphen für die Anfragenbearbeitung hinzufügen, erstellen wir für gewöhnlich im Dashboard separate benachbarte Graphen für folgende Metriken:
- Verfügbarkeit % (Fehler/Anfragen * 100)
- p10, Durchschnitt, p90 Latenzen
- p99,9 und maximale (p100) Latenzen
Wir gehen nicht davon aus, dass der Benutzer genau weiß, was eine bestimmte Metrik oder ein bestimmtes Widget bedeutet
Dies gilt insbesondere für implementationsspezifische Metriken. Wir wollen in Dashboardtexten ausreichend Kontext liefern, zum Beispiel mithilfe von Beschreibungstexten neben oder unter jedem Graphen. Der Betreiber kann diesen Text lesen und verstehen, was die Metrik bedeutet. Der Betreiber kann dann auslegen, wie „normal“ aussieht und was es bedeuten könnte, wenn der Graph nicht „normal“ ist. In diesem Text stellen wir Links zu verwandten Ressourcen bereit, die ein Betreiber nutzen kann, um die Ursache zu ermitteln. Hier sind ein paar Beispiele der von uns bereitgestellten Links:
- Zu Runbooks. Bei Fachexperten kann das Dashboard das Runbook sein.
- Zu verwandten „Dive Deep“-Dashboards.
- Zu gleichwertigen Dashboards für andere Cluster oder Partitionen.
- Zu Bereitstellungspipelines.
- Zu Kontaktinformationen für Abhängigkeiten.
Wir verwenden, wo zutreffend, Alarmstatus, einfache Zahlen und/oder Zeitreihengraphen-Widgets
Je nach Anwendungsfällen des Dashboards ist es unserer Erfahrung nach manchmal passender, einen Widget mit einer einzigen Zahl (zum Beispiel der letzte Wert einer Metrik) oder einem Alarmstatus anzuzeigen, statt einen komplexen Zeitreihengraphen mit allen aktuellen Datenpunkten.

Wir verlassen uns nicht auf Graphen, die spärliche Metriken anzeigen
Spärliche Metriken sind Metriken, die nur bei bestimmten Fehlerbedingungen ausgesendet werden. Es kann zwar effizient sein, Services anzuweisen, diese Metriken nur bei Bedarf auszusenden, Dashboard-Benutzer können aber von leeren oder nahezu leeren Graphen irritiert sein. Wenn wir beim Dashboard-Aufbau solchen Metriken begegnen, passen wir den Service für gewöhnlich so an, dass er ständig sichere Werte (also Nullwerte) für diese Metriken aussendet, wenn keine Fehlerbedingungen bestehen. Die Betreiber können dann leicht erkennen, dass fehlende Daten darauf hindeuten, dass der Service die Telemetrie nicht korrekt aussendet.
Wir fügen weitere Graphen hinzu, die Per-Mode-Metriken anzeigen
Das tun wir, wenn wir Graphen für Metriken anzeigen, die Multi-Model-Verhalten in unseren Systemen zusammenfassen. Unter anderem in folgenden Fällen können wir so vorgehen:
- Wenn ein Service Anfragen in variabler Größe unterstützt, können wir einen Graphen für die Gesamtlatenzen der Anfragen erstellen. Darüber hinaus können wir Graphen erstellen, die Metriken für kleine, mittlere und große Anfragen anzeigen.
- Wenn ein Service Anfragen je nach den Werten (oder Kombinationen) der Input-Parameter auf unterschiedliche Weise ausführt, können wir Graphen mit Metriken hinzufügen, die jede Ausführungsweise erfassen.
Dashboard-Pflege
Der Aufbau von Dashboards, die zahlreiche Ansichten unserer Systeme bieten, ist der erste Schritt. Da unsere Systeme sich aber laufend weiterentwickeln und skaliert werden, müssen sich auch die Dashboards parallel weiterentwickeln, wenn neue Funktionen hinzugefügt und Architekturen erweiterte werden. Die Pflege und Aktualisierung von Dashboards ist in unseren Entwicklungsvorgang eingebettet. Bevor Änderungen durchgeführt werden und während Codeüberprüfungen stellen sich unsere Entwickler die Frage: „Muss ich Dashboards aktualisieren?“ Sie sind dazu befähigt, Änderungen an Dashboards vorzunehmen, bevor die zugrundeliegenden Änderungen bereitgestellt werden. Damit wird verhindert, dass ein Betreiber Dashboards während oder nach einer Systembereitstellung aktualisieren muss, um die bereitgestellte Änderung zu validieren.
Wenn ein Dashboard detailliertere Informationen als gewöhnlich enthält, kann das darauf hindeuten, dass Betreiber sich auf dieses Dashboard verlassen, um Anomalien manuell zu erkennen, anstatt auf automatisierte Alarme und Abhilfemaßnahmen zu bauen. Wir prüfen unsere Dashboards laufend, um festzustellen, ob wir diesen manuellen Aufwand verringern können, indem wir die Instrumentierung in unseren Services verbessern und unsere automatisierten Alarme verbessern. Darüber hinaus kürzen oder aktualisieren wir konsequent Grafiken, die für die Dashboards keinen Mehrwert mehr bieten.
Indem wir unseren Entwicklern ermöglichen, Dashboards zu aktualisieren, stellen wir sicher, dass wir über einen vollständigen, identischen Dashboard-Satz für unsere (Alpha-, Beta- oder Gamma-)Vorfertigungsumgebungen erhalten. Unsere automatisierten Bereitstellungspipelines stellen Änderungen zuerst in Vorfertigungsumgebungen bereit. Daher müssen unsere Teams dazu in der Lage sein, Änderungen in diesen Testumgebungen über die verbundenen Dashboards (und automatisierte Alarme) mühelos und auf eine Weise zu validieren, die exakt mit der Weise übereinstimmt, wie Änderungen in unseren Fertigungsumgebungen validiert werden.
Die meisten Systeme entwickeln sich laufend weiter, wenn im Laufe der Zeit die Anforderungen aktualisiert, neue Funktionen hinzugefügt und Software-Architekturen entsprechend der Skalierung angepasst werden. Unsere Dashboards sind wesentlicher Bestandteil unserer Systeme, und zu ihrer Pflege befolgen wir den IaC (Infrastructure as Code)-Prozess. Dieser Prozess stellt sicher, dass unsere Dashboards in Versionskontrollsystemen gepflegt werden und dass Änderungen an unseren Dashboards über die gleichen Tools bereitgestellt werden, die unsere Entwickler und Betreiber für unsere Services verwenden.
Wenn wir für ein unerwartetes Betriebsereignis eine Post-Mortem-Analyse durchführen, überprüfen unsere Teams, ob Verbesserungen an den Dashboards (oder an den automatisierten Alarmen) dem Ereignis zuvorgekommen wären, die Ursache schneller identifiziert oder die Wiederherstellungszeit verkürzt hätten. Wir stellen uns meist die Frage: „Haben die Dashboards rückblickend deutlich die Auswirkung auf die Kunden gezeigt, den Betreibern geholfen, die eigentliche Ursache zu ermitteln und zur Messung der Wiederherstellungszeit beigetragen?“ Wird eine dieser Fragen mit einem Nein beantwortet, umfasst unsere Post-Mortem-Analyse Maßnahmen zur Überarbeitung dieser Dashboards.
Zusammenfassung
Bei Amazon führen wir weltweit umfangreiche Services aus. Unsere automatisierten Systeme sind auf die laufende Überwachung, Erkennung, Benachrichtigung über und Beseitigung von auftretenden Problemen ausgerichtet. Wir müssen dazu in der Lage sein, diese Services und automatisierten Systeme zu überwachen, tiefe Erkenntnisse über sie zu gewinnen sowie sie zu prüfen und zu überprüfen. Dafür bauen und pflegen wir Dashboards, die zahlreiche verschiedene Einblicke in unsere Systeme gewähren. Wir entwickeln diese Dashboard sowohl für breitere als auch spezifische Zielgruppen, indem wir von den Dashboard-Benutzern aus rückwärts arbeiten. Damit Betreiber und Service-Eigentümer die Dashboards leichter verstehen können, verwenden wir eine einheitliche Reihe von Formensprache und Konventionen, um die Nutzbarkeit und Nützlichkeit des Dashboards zu gewährleisten.
Unsere Dashboards bieten viele verschiedene Perspektiven und Einblicke in den Betrieb von AWS-Services. Sie spielen eine entscheidende Rolle bei der Bereitstellung einer hervorragenden Kundenerfahrung, da sie Amazon-Teams ermöglichen, unsere Services zu verstehen, zu betreiben und zu skalieren. Wir hoffen, dass dieser Artikel bei dem Entwurf, dem Aufbau und der Pflege Ihrer eigenen Dashboards hilfreich sein wird. Wenn Sie gerne ein Beispiel für die Erstellung von Dashboards mithilfe von AWS-Services sehen möchten, finden Sie hier ein kurzes Video und eine Self-Service-Anleitung.
Über den Autor
John O‘Shea ist Principal Engineer bei Amazon Web Services. Sein aktueller Schwerpunkt liegt bei Amazon Cloudwatch und anderen Amazon-internen Überwachungs- und Beobachtbarkeitsservices.

Ähnliche Inhalte
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern