Mit Deep Learning sortiert Disney sein Universum an Inhalten
In einer Folge der Fernsehserie Disneyland aus dem Jahr 1957 führt Walt Disney die Zuschauer in die Tiefen seines Burbank-Animationsstudios. „In unserer Leichenhalle“, sagt er und bezieht sich auf die unterirdische Bibliothek, „halten diese Regale, Tische und Aktenschränke unsere gesamte Geschichte als Filmstudio fest.“
In einer Folge der Fernsehserie Disneyland aus dem Jahr 1957 führt Walt Disney die Zuschauer in die Tiefen seines Burbank-Animationsstudios. „In unserer Leichenhalle“, sagt er und bezieht sich auf die unterirdische Bibliothek, „halten diese Regale, Tische und Aktenschränke unsere gesamte Geschichte als Filmstudio fest.“
Lange vor anderen Animationsstudios bestand Disney darauf, dass das Archiv Schriftstellern und Illustratoren zugänglich sein sollte, die es möglicherweise als Referenz oder Inspiration benötigen. Zeichnungen, Konzeptgrafiken und mehr von Favoriten wie Dumbo und Peter Pan wurden sorgfältig in diesem Tresor versteckt. Und in den letzten Jahren hat sich Disney der Erhaltung verschrieben.
Mit fast einem Jahrhundert an Inhalten, ein wachsender Prozentsatz davon digital, muss Disney seine Bibliothek sorgfältiger als je zuvor organisieren. Ein kleines Team von Forschungs- und Entwicklungsingenieuren und Informationswissenschaftlern im DTCI-Technologieteam (Direct-to-Consumer & International) von Disney sorgt für Ordnung und Sauberkeit in den (virtuellen) Stapeln. DTCI wurde 2018 gegründet, um zum Teil Technologen und Fachkenntnisse aus der gesamten Walt Disney Company zusammenzubringen und Technologien auszurichten, um die Vielzahl einzigartiger Inhalte und Geschäftsanforderungen bei Disney zu unterstützen.
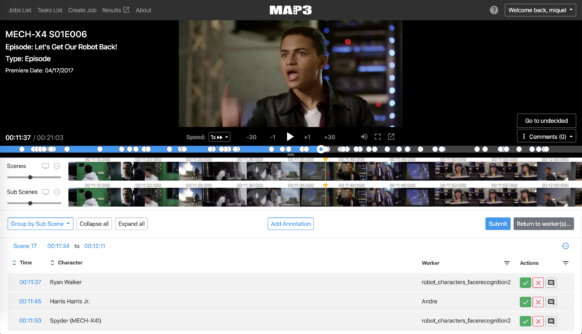
Die Grundlage des Organisationssystems sind Metadaten: Informationen zu den Geschichten, Szenen und Charakteren in den Shows und Filmen von Disney. Zum Beispiel hätte Bambi Metadaten-Tags, die nicht nur Charaktere wie Klopfer, das Kaninchen oder Faline (Bambis Rehkitz-Freund) identifizieren, sondern auch die Art des Tieres, die Beziehungen zwischen Tieren und die Charakter-Archetypen, die jedes Tier darstellt. Dinge wie die Naturszenen - bis hin zu den spezifischen Arten der abgebildeten Blumen - Musik, Stimmung und Ton der Geschichte haben auch bestimmte Tags. Daher ist es eine Herausforderung, all diese Inhalte angemessen mit den richtigen Metadaten zu versehen, damit sie richtig sortiert werden können, insbesondere angesichts des rasanten Wachstums von Disney:
„Wir haben neue Charaktere in Fernsehsendungen, Fußballspieler, die Teams wechseln, neue Waffen für Superhelden, neue Sendungen“, sagte Miquel Farré, der technische Leiter des Teams, und all dies erfordert einen Haufen neuer Metadaten.
Mithilfe von AWS-Services erstellen er und sein Team Machine Learning-Tools und tiefes Lernen, um diesen Inhalt automatisch mit beschreibenden Metadaten zu versehen und den Archivierungsprozess effizienter zu gestalten. Auf diese Weise können Autoren und Animatoren schnell nach Personen suchen und sich mit ihnen vertraut machen, von Mickey Maus bis zu Phil Dunphy von Modern Family.
Was ist so magisch an Metadaten?
Bild mit freundlicher Genehmigung von Disney
Das Team, das diese Arbeit leitet, wurde ursprünglich 2012 als Teil der Disney & ABC Television Group gegründet. Im Laufe der Jahre ist es gewachsen und jetzt als Teil der DTCI-Technologiegruppe von Disney zum Index und zur Wissensbasis der Stile und Konventionen des Disney-Universums geworden (zum Beispiel in Bambi sprechen die Tiere, in Schneewittchen nicht). Damit ihre Machine Learning-Tools Metadaten generieren, die den kreativen Inhalt genau beschreiben, ist das Team auf die Autoren und Animatoren angewiesen, um die Stilmerkmale zu erläutern, die jede Sendung einzigartig machen.
Diese kreativen Teammitglieder profitieren von ihrer Zusammenarbeit. Sobald der Inhalt mit genauen Metadaten versehen ist, können sie über eine Suchoberfläche schnell finden, was sie benötigen. Zum Beispiel muss ein Autor von Grey´s Anatomy möglicherweise wissen, wie oft die Whipple-Operation in einer Episode vorgestellt wurde, um Redundanz zu vermeiden. In der Zwischenzeit möchte ein Künstler, der Unterwasserleben für einen neuen Cartoon zeichnet, der unter dem Meer stattfindet, möglicherweise nach einer bestimmten Charakterhaltung oder -position in „Die kleine Meerjungfrau“ oder „Findet Nemo“ suchen, um sich inspirieren zu lassen.
Das Markieren aller Elemente mit den richtigen Metadaten stellt jedoch schnell ein Arbeitsproblem dar: Obwohl das manuelle Markieren ein wichtiger Teil des Prozesses ist, hat das DTCI-Technologieteam nicht die Zeit, jeden Frame manuell zu kategorisieren. Aus diesem Grund hat das Team von Farré das Machine Learning - und in jüngerer Zeit das tiefe Lernen - mit der Generierung von Metadaten beauftragt. Ziel ist es, Deep-Learning-Algorithmen zu entwickeln, mit denen die Komponenten einer Szene automatisch so gekennzeichnet werden können, dass sie mit dem Rest der Disney-Wissensdatenbank übereinstimmen. Menschen müssen die Tags des Algorithmus noch genehmigen, aber das Projekt reduziert den Arbeitsaufwand für die Organisation der Disney-Bibliothek erheblich und verbessert die Genauigkeit der darin enthaltenen Suche.
Durch diesen Fortschritt können sich die Ingenieure mehr auf die Entwicklung von Deep-Learning-Modellen mit AWS (Amazon Web Services) konzentrieren. Infolgedessen summten ihre Bemühungen, die Erstellung von Metadaten für verschiedene Arten von Disney-Inhalten zu automatisieren, mit.

Deep Learning verleiht Animationen eine Identität
Bild mit freundlicher Genehmigung von Disney
Eines der erfolgreichsten Deep Learning-/Metadaten-Projekte war die Lösung der Probleme, die sich aus der Animationserkennung ergeben.
In einem Live-Action-Film oder einer Fernsehsendung ist es für eine Maschine relativ einfach, eine Figur von ihrer Umgebung zu trennen. Aber Animation macht die Dinge komplizierter. Nehmen Sie zum Beispiel eine animierte Szene, in der ein Charakter sowohl im Fleisch als auch auf einem Poster erscheint (sagen wir, der Charakter ist ein Verbrecher, und in der ganzen Stadt wurden Gesucht-angebracht). „Für einen Algorithmus ist dies äußerst komplex“, sagte Farré.
Im letzten Jahr hat Farrés Team eine Deep-Learning-Methode entwickelt, mit der animierte Charaktere von ihren statischen Darstellungen unterschieden, innerhalb einer Menge von Doppelgängern (wie in DuckTales, wo viele Charaktere ziemlich identisch sind) identifiziert und in Szenen mit unkonventioneller Beleuchtung erkannt werden können (in Alice im Wunderland, als Alice sich zum ersten Mal in der Cheshire-Katze trifft, offenbart diese nur ihr zahniges Grinsen). Nachdem entschieden wurde, was was ist, kann der Algorithmus die Szenen mit den entsprechenden Metadaten versehen.
Die wahre Stärke des Modells besteht jedoch darin, dass es auf jeden animierten Inhalt angewendet werden kann. Das heißt, anstatt für jeden Goofy, Hercules und Elsa ein neues Modell zu erstellen, muss das Team nur das generische Modell verwenden, das mit geringfügigen Anpassungen für jeden Charakter in einer Sendung oder einem Film funktioniert.
Vor diesem Jahr arbeitete das Team mit traditionelleren Algorithmen für Machine Learning, die weniger Daten erfordern als ein Deep-Learning-Ansatz - aber auch zu begrenzteren, weniger flexiblen Ergebnissen führten. Mit weniger Dateneingaben funktionieren herkömmliche Algorithmen gut. Wenn Sie jedoch exponentiell mehr Daten haben, kann Deep Learning einen großen Unterschied machen.
Jetzt, so Farré, kann das Deep-Learning-Modell von bereits geschulten Netzwerken profitieren und sich auf bestimmte Anwendungsfälle einstellen. Im speziellen Fall von animierten Charakteren hat Disney ein neuronales Netzwerk mit Tausenden von Bildern verfeinert, um sicherzustellen, dass es das Konzept eines „animierten Charakters“ versteht. Anschließend wird für jede bestimmte Sendung das neuronale Netzwerk mit nur wenigen hundert Bildern aus einigen Episoden neu angepasst, um zu erfahren, wie „animierte Charaktere“ innerhalb der spezifischen Sendung erkannt und interpretiert werden sollten.
AWS war ein wichtiger Partner beim Übergang von Disney vom traditionellen Machine Learning zum Deep Learning, insbesondere beim Experimentieren. Mit EC2-Instanzen für elastisches Cloud-Computing kann das Team neue Versionen des Modells schnell testen. (Für das Animationserkennungsprojekt verwendet Disney das PyTorch-Framework mit vorab trainierten Modellen.) Da im Bereich Deep Learning viel geforscht wird, experimentiert das Team ständig mit neuen und neuartigen Methoden.
Die Metadatenrecherche war so erfolgreich, dass Abteilungen bei ganz Disney Wind bekommen haben. Farré sagte, sein Team habe kürzlich mit dem Personalisierungsteam von ESPN zusammengearbeitet, um detaillierte Metadaten zu allen Artikeln und Videos bereitzustellen, die auf den branchenführenden digitalen Anwendungen und Websites enthalten sind. Wenn das Produkt weiß, dass Sie ein Fan der Los Angeles Dodgers, Steph Curry, der Minnesota Vikings und Manchester United sind, können Sie mit mehr Metadaten zu jedem Artikel sicherstellen, dass Ihnen Inhalte bereitgestellt werden, die Ihren Vorlieben am besten entsprechen. Darüber hinaus können die Algorithmen für Machine Learning und die von ihnen bereitgestellten Metadaten eine fortgeschrittenere KI unterstützen, um im Laufe der Zeit eine weitere implizite Personalisierung (basierend auf Datenbeziehungen und Verhalten) voranzutreiben.
Nach Ansicht von Farré sind die Anwendungen für Metadaten endlos, insbesondere angesichts der umfangreichen und wachsenden Bibliothek von Disney mit unverwechselbaren Inhalten, Charakteren und Produkten. „Ich denke, wir werden uns nicht langweilen“, sagte er.