La creación de paneles para la visibilidad operativa
Operaciones y entrega de software | NIVEL 300
Introducción
Todos ejecutamos aplicaciones en nuestros ordenadores, tabletas y teléfonos inteligentes. Nos resulta fácil ver si el dispositivo está encendido y la conexión de red Wi-Fi está en línea. Sabemos que las pantallas mostrarán cualquier notificación esencial, como las advertencias de poco espacio libre en el disco. De hecho, la velocidad general y la capacidad de respuesta de la interfaz de usuario (UI) pueden ser un buen indicador de si el dispositivo tiene suficientes recursos, como memoria o CPU, para ejecutar las aplicaciones.
Cualquier persona que ha provisto soporte técnico remoto para los dispositivos de la familia puede atestiguar que es un poco más difícil detectar y diagnosticar problemas cuando no se puede ver e interactuar de manera directa con el dispositivo. Por lo tanto, cuando se trata de ejecutar servicios basados en la nube, enfrentamos un desafío similar: ¿Cómo monitoreamos estos servicios remotos y cómo sabemos que nuestros clientes están felices?
Para observar un servicio de alojamiento único, podemos iniciar sesión en ese alojamiento, ejecutar diversas herramientas de monitoreo del tiempo de ejecución e inspeccionar registros a fin de determinar la causa raíz de lo que allí sucede. Sin embargo, las soluciones de alojamiento único son solo posibles para los servicios no esenciales más simples. En el otro extremo están los microservicios distribuidos de múltiples capas que ejecutan cientos o miles de servidores, contenedores o entornos sin servidor.
¿De qué manera Amazon logra ver cómo se comportan realmente todos los servicios basados en la nube, que se ejecutan en varias zonas de disponibilidad en muchas regiones de todo el mundo? El monitoreo, los flujos de trabajo de resolución de problemas (por ejemplo, el cambio de tráfico) y los sistemas de implementación automatizados son esenciales para detectar y resolver la gran mayoría de los problemas en esta escala. Sin embargo, por muchas razones aún necesitamos poder ver en cualquier momento lo que hacen estos servicios, flujos de trabajo e implementaciones.
La creación de paneles en Amazon
Utilizamos los paneles como un mecanismo para abordar el desafío de estar al tanto de la actividad en nuestros servicios en la nube. Los paneles son vistas orientadas al humano en nuestros sistemas que ofrecen resúmenes concisos de cómo se comporta el sistema al mostrar datos de alarmas, rastreos, registros y métricas de series temporales.
En Amazon, nos referimos a la creación, el uso y el mantenimiento continuo de estos paneles como creación de paneles. La creación de paneles se convirtió en una actividad de primera clase porque es tan esencial para el éxito de nuestros servicios como cualquier otra entrega de software diaria o actividades operativas, como el diseño, la creación, la prueba, la implementación y el escalado de nuestros servicios.
Por supuesto, no esperamos que nuestros operadores monitoreen los paneles todo el tiempo. La mayoría de las veces, nadie los observa. De hecho, descubrimos que cualquier proceso operativo que requiera una revisión manual de los paneles falla debido al error humano, no importa con qué frecuencia se revisen los paneles. Para abordar este riesgo, creamos alarmas automatizadas que evalúan de manera constante los datos de monitoreo más importantes que nuestros sistemas emiten. Por lo general, estas son métricas que indican que el sistema se acerca a algún límite (detección proactiva, antes del impacto) o que el sistema ya se vio afectado de alguna manera inesperada (detección reactiva, después del impacto).
Estas alarmas pueden ejecutar flujos de trabajo de resolución automatizados y pueden notificar a nuestros operadores que existe un problema. La notificación dirige al operador a los paneles y runbooks exactos que necesitan utilizar. Cuando estoy de guardia y una notificación de alarma me alerta por un problema, puedo utilizar los paneles relacionados rápidamente para cuantificar el impacto del cliente, validar o evaluar la causa raíz, mitigar y reducir el tiempo de recuperación. Incluso si la alarma ya inició un flujo de trabajo de resolución automatizado, necesito ver qué hace el flujo de trabajo automatizado, cuál es el efecto sobre el sistema y, en circunstancias excepcionales, avanzar el flujo de trabajo mediante confirmación humana para los pasos esenciales de seguridad.
Cuando un evento se encuentra en progreso, Amazon generalmente involucra a numerosos operadores en servicio. Los operadores pueden utilizar diferentes paneles a medida que atraviesan una secuencia de tareas. Estas tareas generalmente incluyen cuantificar el impacto para los clientes, probar, realizar el seguimiento a través de numerosos servicios hasta la causa raíz del evento, observar los flujos de trabajo de resolución automatizados y ejecutar y validar los pasos de mitigación basados en runbooks. Mientras tanto, los equipos de colegas y las partes interesadas también utilizan los paneles a fin de monitorizar el impacto continuo durante el evento. Estos distintos participantes se comunican con herramientas de administración de incidentes, salas de chat (con bots como AWS Chatbot) y llamadas en conferencia. Cada parte interesada ofrece una perspectiva distinta sobre los datos que ven en los paneles.
Cada semana, los equipos de Amazon y organizaciones más grandes también llevan a cabo reuniones de revisión de operaciones a las que asisten directivos superiores, gerentes y muchos ingenieros. Durante esas reuniones utilizamos una rueda de la fortuna para elegir paneles de auditoría de alto nivel. Los interesados revisan la experiencia de los clientes y los objetivos de nivel de servicios principales, como la disponibilidad y la latencia. Los paneles de auditoría que utilizan estas partes interesadas generalmente muestran datos operativos de todas las regiones y zonas de disponibilidad.
Además, cuando se realiza la previsión y la planificación de la capacidad a largo plazo, Amazon utiliza paneles que visualizan la empresa de más alto nivel, el uso y las métricas de capacidad que nuestro sistema emite en intervalos de tiempo más largos.
Tipos de paneles
Las personas utilizan los paneles para monitorear los servicios de manera manual, pero no hay una solución válida para todos los casos de uso. Para la mayoría de los sistemas, utilizamos muchos paneles, cada uno de los cuales ofrece una visión diferente en el sistema. Estas diferentes visiones les permiten a los diversos usuarios comprender de qué manera nuestros sistemas se comportan desde distintas perspectivas y en diferentes intervalos de tiempo.
Los datos que cada destinatario desea ver pueden variar de manera significativa de un panel a otro. Aprendimos a centrarnos en los destinatarios previstos cuando diseñamos los paneles. Decidimos qué datos van en cada panel en función de quiénes lo utilizarán y por qué. Seguramente haya escuchado que en Amazon trabajamos retrospectivamente a partir del cliente. La creación de paneles es un buen ejemplo de esto. Creamos paneles en función de las necesidades de los usuarios esperados y sus requisitos específicos.
El siguiente diagrama ilustra de qué manera los distintos paneles ofrecen diferentes visiones del sistema en su totalidad:
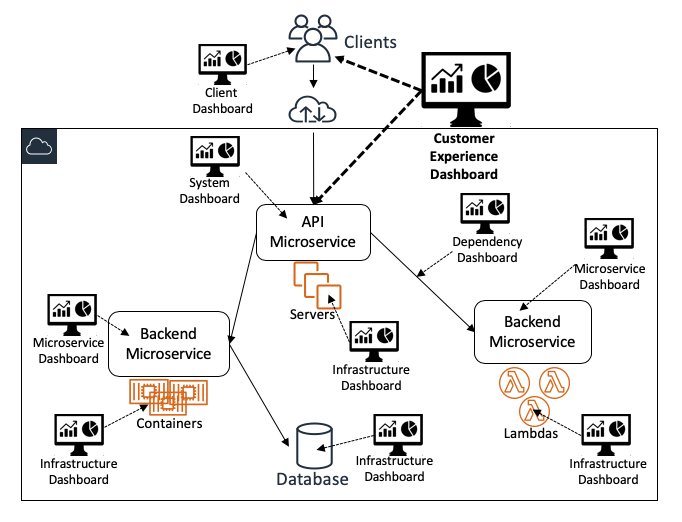
Paneles de alto nivel
Paneles de experiencia de los clientes
En Amazon, nuestros paneles más importantes y más utilizados son los de la experiencia de los clientes. Estos paneles están diseñados para ser utilizados por un amplio grupo de usuarios que incluye operadores de servicio y muchas otras partes interesadas. Presentan métricas de manera eficaz sobre el estado del servicio en general y el cumplimiento de los objetivos. Muestran los datos de supervisión que proceden del servicio y además de instrumentos del cliente, evaluadores continuos (como los valores controlados de Amazon CloudWatch Synthetics) y sistemas de resolución de problemas automáticos. Estos paneles también contienen datos que ayudan a los usuarios a responder preguntas sobre la profundidad y el alcance del impacto. Es probable que algunas de estas preguntas sean “¿cuántos clientes se ven afectados?” y “¿qué clientes se ven más afectados?”
Paneles a nivel de sistema
Los puntos de entrada a nuestros servicios basados en la Web son generalmente puntos de enlace UI y API, por lo tanto, los paneles a nivel de sistema específicos deben contener suficientes datos para que los operadores vean de qué manera se comportan el sistema y los puntos de enlace dirigidos a los clientes. Estos paneles muestran principalmente datos de monitoreo a nivel de interfaz. Estos paneles muestran tres categorías de datos de monitoreo para cada API:
- Datos de monitoreo relacionados con contenido de entrada. Puede incluir recuentos de solicitudes o trabajo de sondeo de colas o transmisiones, solicitud de percentiles de tamaño de bytes y recuentos de errores de autorización o autenticación.
- Datos de monitoreo relacionados con el proceso. Puede incluir recuentos de ejecución de ruta o ramificación lógica empresarial multimodal, solicitud de microservicio de backend de percentiles de latencia, error o recuento, resultado de registro de fallo y error y solicitud de datos de rastreo.
- Datos de monitoreo relacionados con los resultados. Puede incluir conteos de tipos de respuestas (con detalles por errores o fallas por parte de los clientes), tamaño de respuestas y percentiles de tiempo para escribir el primer byte de respuesta y tiempo para escribir la respuesta completa.
En general, nuestro objetivo es mantener las experiencias del cliente y los paneles a nivel de sistema tan alto como sea posible. Evitamos de manera deliberada la tentación de agregar demasiadas métricas a estos paneles porque la sobrecarga de información puede desviar la atención del mensaje principal que estos paneles necesitan transmitir.
Paneles de instancia de servicio
Creamos algunos paneles para facilitar la evaluación rápida e integral de la experiencia del cliente dentro de una instancia de servicio única (partición o celda). Esta visión limitada asegura que los operadores que trabajan en una instancia de servicio única no se vean sobrecargados con datos irrelevantes de otras instancias de servicio.
Paneles de auditoría de servicios
Además creamos paneles de experiencia de clientes que muestran de manera intencional los datos para todas las instancias de un servicio, a través de todas las regiones y zonas de disponibilidad. Los operadores utilizan estos paneles de auditoría de servicios para alarmas automatizadas de auditoría a través de todas las instancias de servicios. Estas alarmas también se pueden revisar durante las reuniones de operaciones semanales mencionadas anteriormente.
Paneles de previsiones y planificación de capacidad
Para casos de uso a largo plazo, también creamos paneles para la planificación de capacidad y previsiones que nos ayudan a visualizar el crecimiento de los servicios.
Paneles de bajo nivel
Las API de Amazon generalmente se implementan al organizar solicitudes mediante microservicios de backend. Estos microservicios pueden ser propiedad de distintos equipos, cada uno de los cuales es responsable por algún aspecto específico del procesamiento de la solicitud. Por ejemplo, algunos microservicios son específicos para solicitar la autenticación y autorización, la aplicación de límites o limitación controlada, la medición de uso, los recursos de eliminación, actualización o creación, la recuperación de recursos de los almacenes de datos y el inicio de flujos de trabajo asincrónicos. Los equipos generalmente crean al menos un panel de microservicios específico dedicado que muestra métricas para cada API o unidad de trabajo si el servicio procesa datos de manera asincrónica.
Paneles específicos de microservicios
Los paneles para microservicios generalmente muestran datos de monitoreo específicos de la implementación que requieren profundo conocimiento del servicio. Los equipos que poseen los servicios utilizan principalmente estos paneles. Sin embargo, porque nuestros servicios están en gran medida instrumentados, necesitamos presentar datos de esta instrumentación de forma que no abrumen a los operadores. Por lo tanto, estos paneles generalmente muestran algunos datos de forma agregada. Cuando los operadores identifican anomalías en los datos agregados, generalmente utilizan diversas herramientas para profundizar los conocimientos, ejecutar consultas ad-hoc sobre los datos de monitoreo subyacentes que desagregan los datos, rastrear solicitudes y revelar datos relacionados o correlacionados.
Paneles de infraestructura
Nuestros servicios se ejecutan en infraestructura de AWS que generalmente emite métricas, por lo tanto, también tenemos paneles de infraestructura específicos. Estos paneles se centran principalmente en las métricas emitidas por los recursos informáticos que ejecuta nuestro sistema, como las instancias de Amazon Elastic Compute Cloud (EC2), los contenedores de Amazon Elastic Container Service (ECS) o Amazon Elastic Kubernetes Service (EKS) y las funciones de AWS Lambda. Las métricas, como la utilización de CPU, el tráfico de red, el disco ES y el uso del espacio, se utilizan comúnmente en estos paneles, junto con cualquier clúster relacionado, Auto Scaling y métricas de cuota que son relevantes para estos recursos informáticos.
Paneles de dependencia
Además de los recursos informáticos, en muchos casos los microservicios dependen de otros. Incluso si los equipos que poseen esas dependencias ya tienen sus propios paneles, por lo general, cada propietario de microservicio crea paneles de dependencia específicos a fin de proveer una visión de cómo se comportan las dependencias ascendentes (por ejemplo, proxies y balanceadores de carga) y las dependencias descendentes (por ejemplo, almacenes de datos, colas y transmisiones) medidas por el servicio. Estos paneles también se pueden utilizar para realizar un seguimiento a otras métricas esenciales, como las fechas de vencimiento de los certificados de seguridad y otros usos de la cuota de dependencia.
Diseño de paneles
En Amazon, consideramos que la consistencia en la presentación de los datos es esencial para la creación correcta de un panel. Para que sea eficaz, se debe lograr la consistencia en cada panel y también entre todos ellos. Con los años, identificamos, adaptamos y depuramos un conjunto común de convenciones y expresiones de diseño que creemos que hacen que los paneles sean accesibles a una mayor audiencia, al incrementar en última instancia su valor para nuestra organización. Incluso encontramos formas sutiles de medir y mejorar estas convenciones de diseño a lo largo del tiempo. Por ejemplo, si un operador nuevo puede rápidamente comprender y utilizar los datos presentados en los paneles para aprender cómo funciona un servicio, es una indicación de que esos paneles presentan la información correcta de la manera adecuada.
Una tendencia muy común cuando se diseñan paneles es sobrestimar o subestimar el conocimiento especializado del usuario de destino. Es fácil crear un panel que tenga sentido para su creador. Sin embargo, este panel puede que no provea valor a los usuarios. Utilizamos la técnica del trabajo en retrospectiva a partir del cliente (en este caso, los usuarios del panel) a fin de eliminar este riesgo.
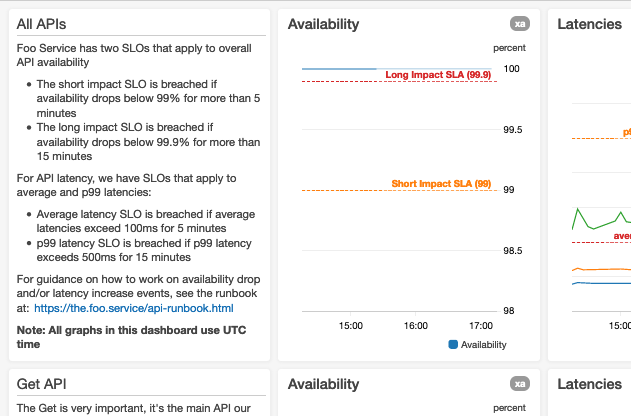
Adoptamos una convención de diseño que estandariza la disposición de los datos en un panel. Los paneles se renderizan de arriba hacia abajo y los usuarios tienden a interpretar los gráficos emitidos al principio (visibles cuando se carga el panel) como lo más importante. Por lo tanto, nuestra convención de diseño aconseja ubicar los datos más importantes en la parte superior del panel. Descubrimos que los gráficos de disponibilidad agregados o resumidos y los gráficos de percentiles de latencia completos son generalmente los paneles más importantes para nuestros servicios web.
A continuación se muestra una captura de pantalla de la parte superior de un panel para un servicio Foo hipotético:
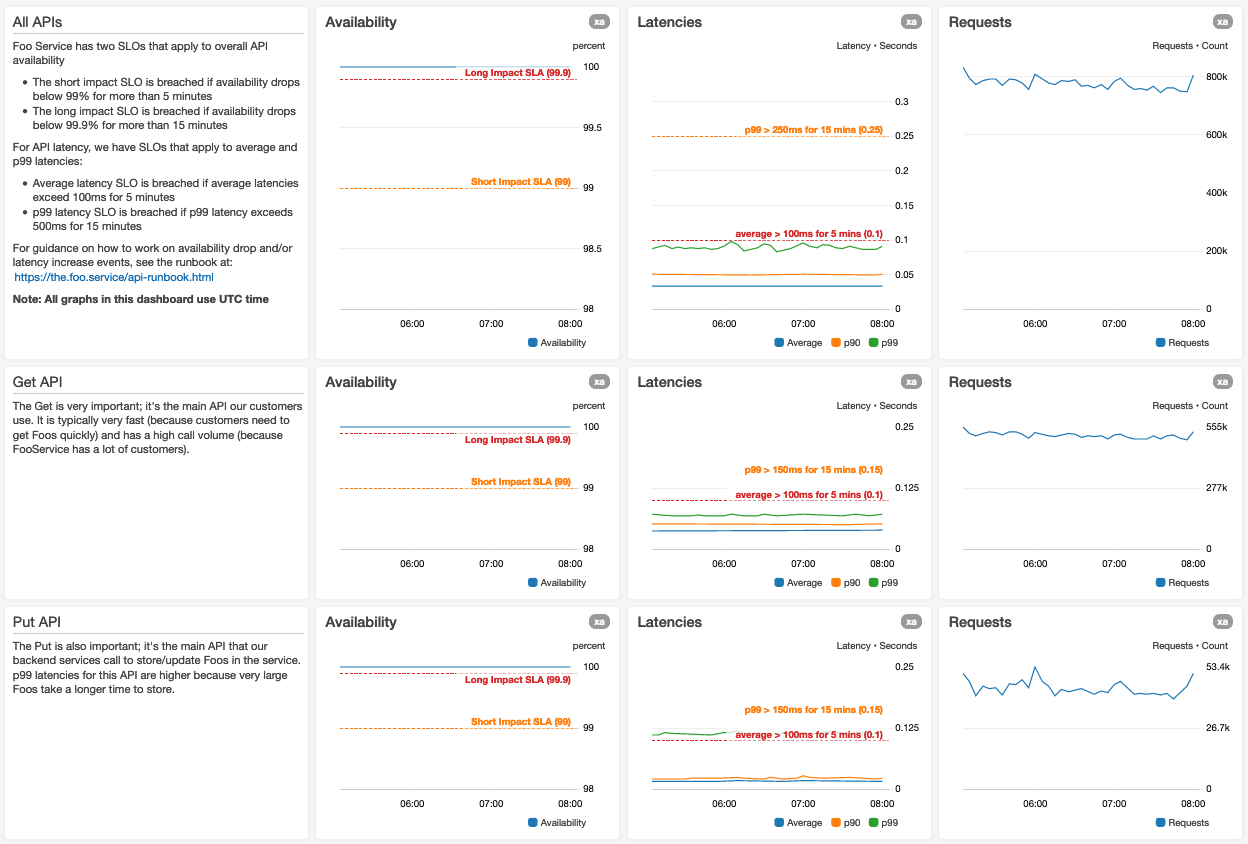
Utilizamos gráficos más grandes para las métricas más importantes
Si tenemos muchas métricas en un gráfico, garantizamos que las leyendas no reduzcan vertical u horizontalmente los datos del gráfico visible. Si usamos consultas de búsqueda en los gráficos, nos aseguramos de permitir que haya un conjunto de resultados de métricas más grande de lo normal.
Presentamos gráficos para la resolución de pantalla mínima esperada
Esto evita que los usuarios se vean obligados a desplazarse de manera horizontal. Un operador de guardia en un ordenador a las 3 h puede que no note la barra de desplazamiento horizontal sin una indicación visual obvia de que hay más gráficos a la derecha.
Mostramos la zona horaria
Para los paneles que muestran la fecha y la hora, nos aseguramos de que la zona horaria relacionada sea visible. Para los paneles que los operadores en diferentes zonas horarias utilizan al mismo tiempo, establecemos de forma predeterminada una zona horaria (UTC) con la que todos los usuarios se puedan relacionar. De esta manera los usuarios se pueden comunicar entre ellos con una zona horaria única, lo que ahorra el tiempo y el esfuerzo de hacer excesivas traducciones mentales de zonas horarias.
Utilizamos el periodo de punto de datos e intervalo de tiempo más corto
Establecemos de forma predeterminada el periodo de punto de datos e intervalo de tiempo relevante a los casos de uso más comunes. Garantizamos que todos los gráficos en el panel muestren en principio los datos para la misma resolución y rango de tiempo. Descubrimos que es beneficioso si todos los datos dentro de una sección del panel tienen el mismo tamaño horizontal. Esto permite una fácil correlación de tiempo entre gráficos.
También, evitamos trazar demasiados puntos de datos en los gráficos porque ralentiza el tiempo de carga del panel. Además, observamos que si al usuario se le muestran excesivos puntos de datos, en realidad puede reducir la visibilidad de las anomalías. Por ejemplo, un gráfico de un intervalo de tres horas de puntos de datos de resolución de un minuto con solo 180 valores por métrica se representará claramente incluso en widgets de paneles pequeños. Este número de puntos de datos además les provee suficiente contexto a los operadores que prueban eventos operativos continuos.
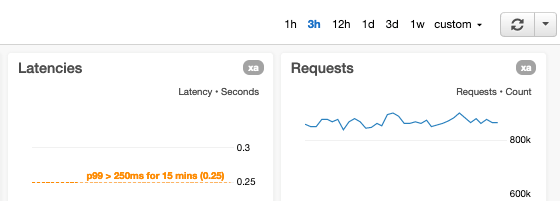
Habilitamos la capacidad de ajustar el intervalo de tiempo y el periodo de métricas
Nuestros paneles proporcionan controles para ajustar rápidamente el intervalo de tiempo y el periodo de métricas para todos los gráficos. Otras relaciones comunes de intervalo y resolución que usamos en nuestros paneles son:
- 1 hora x 1 minuto (60 puntos de datos): útil para hacer zoom y observar los eventos en curso
- 12 horas x 1 minuto (720 puntos de datos)
- 1 día x 5 minutos (288 puntos de datos): útil para ver las tendencias diarias
- 3 días x 5 minutos (864 puntos de datos)
- 1 semana x 1 hora (168 puntos de datos): útil para ver tendencias semanales
- 1 mes x 1 hora (744 puntos de datos)
- 3 meses x 1 día (90 puntos de datos): útil para ver tendencias trimestrales
- 9 meses x 1 día (270 puntos de datos)
- 15 meses x 1 día (450 puntos de datos): útil para revisiones de capacidad a largo plazo
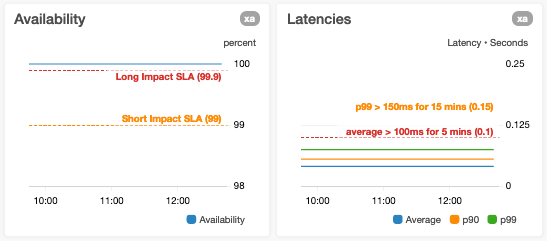
Anotamos gráficos con umbrales de alarma
Cuando graficamos métricas que tienen alarmas automatizadas asociadas, si los umbrales de alarma son estáticos, anotamos gráficos con líneas horizontales. Si los umbrales de alarma son dinámicos, es decir, si están basados en pronósticos o predicciones generadas mediante inteligencia artificial (IA) o aprendizaje automático (ML), mostramos tanto las métricas reales como las de umbral en el mismo gráfico. Si un gráfico muestra una métrica que mide un aspecto del servicio que tiene límites conocidos (como un límite “máximo probado” o un límite de recurso duro), anotamos el gráfico con una línea horizontal que indica dónde están los límites conocidos o probados. Para las métricas que tienen objetivos, agregamos líneas horizontales para que estos sean inmediatamente visibles para el usuario.
Evitamos agregar líneas horizontales a los gráficos que ya usan un eje y derecho e izquierdo
Si agrega líneas horizontales a estos gráficos, los usuarios pueden tener dificultades para saber con qué eje y se relaciona la línea horizontal. Para evitar esta ambigüedad, dividimos los gráficos como este en dos que usan un solo eje horizontal y agregamos las líneas horizontales solo al gráfico apropiado.
Evitamos sobrecargar un eje y con múltiples métricas que tienen rangos de valores muy dispares
Evitamos esta situación porque puede generar una visibilidad reducida de la variación de una o más métricas. Un ejemplo de esto es cuando trazamos las latencias p0 (mínima) y p100 (máxima) en el mismo gráfico donde los valores de los puntos de datos p100 pueden ser órdenes de magnitud mayores que los puntos de datos p0.
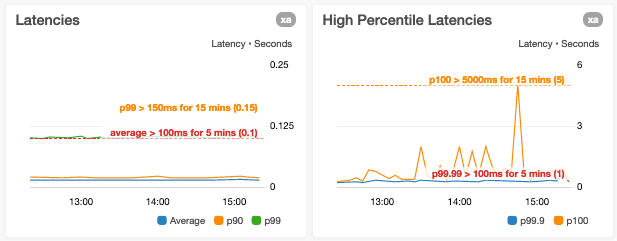
Somos precavidos y reducimos los límites del eje y al rango de valores del punto de datos actual únicamente
Un vistazo casual a un gráfico con un rango del eje y limitado a valores del punto de datos puede hacer que una métrica parezca mucho más variable de lo que realmente es.
Evitamos sobrecargar los gráficos individuales
Queremos asegurarnos de que no tengamos demasiadas estadísticas o métricas no relacionadas en un solo gráfico. Por ejemplo, al agregar gráficos para el procesamiento de solicitudes, normalmente creamos gráficos adyacentes separados en el panel para lo siguiente:
- % de disponibilidad (fallos/solicitudes * 100)
- p10, promedio, latencias p90
- p99.9 y latencias máximas (p100)
No asumimos que el usuario conoce exactamente lo que significa cada métrica o widget
Esto se aplica en particular a las métricas específicas de implementación. Queremos proporcionar suficiente contexto en el texto del panel, por ejemplo, con texto descriptivo al lado o debajo de cada gráfico. El operador puede leer este texto para comprender el significado de la métrica. Luego, el operador puede interpretar cómo se ve el gráfico “normal” y qué podría significar que no sea “normal”. En este texto, proporcionamos enlaces a recursos relacionados que un operador puede usar para determinar la causa raíz. A continuación, se muestran algunos ejemplos de los tipos de enlaces que brindamos:
- Para runbooks. Para los expertos en la materia, el panel puede ser el runbook.
- Para paneles relacionados de “análisis profundo”.
- Para paneles equivalentes a otros clústeres o particiones.
- Para implementar canalizaciones.
- Para información de contacto de dependencias.
Usamos estados de alarma, números simples o widgets de gráficos de series temporales cuando corresponde
Según los casos de uso del panel, consideramos que mostrar un widget que contiene un solo número (por ejemplo, el último valor de una métrica) o el estado de alarma suele ser más apropiado que mostrar un gráfico complejo de series temporales con todos los puntos de datos recientes.

Evitamos basarnos en gráficos que muestran métricas dispersas
Las métricas dispersas son métricas que se emiten solo cuando existen determinadas condiciones de error. Si bien puede resultar eficiente instrumentar los servicios para que emitan estas métricas solo cuando sea necesario, los usuarios del panel pueden confundirse con gráficos total o parcialmente vacíos. Cuando nos encontramos con tales métricas al diseñar paneles, comúnmente modificamos el servicio para que emita continuamente valores seguros (es decir, cero) para estas métricas frente a la ausencia de la condición de error. Los operadores pueden comprender fácilmente que la ausencia de datos significa que el servicio no está emitiendo telemetría de forma correcta.
Agregamos gráficos adicionales que muestran métricas por modo
Hacemos esto cuando mostramos gráficos para métricas que agregan el comportamiento de varios modelos en nuestros sistemas. Algunas circunstancias en las que podríamos hacer esto incluyen:
- Si un servicio admite solicitudes de tamaño variable, podríamos crear un gráfico para las latencias generales de las solicitudes. Además, también podemos crear gráficos que muestren métricas para solicitudes pequeñas, medianas y grandes.
- Si un servicio ejecuta solicitudes de distintas formas según los valores (o combinaciones) de los parámetros de entrada, podríamos agregar gráficos para las métricas que capturan cada modo de ejecución.
Mantenimiento de los paneles
La creación de paneles que presentan muchas vistas de nuestros sistemas es el primer paso. Sin embargo, nuestros sistemas evolucionan y se escalan continuamente y los paneles deben evolucionar junto con ellos a medida que se agregan nuevas funciones y se mejoran las arquitecturas. Mantener y actualizar los paneles es parte de nuestro proceso de desarrollo. Antes de completar los cambios y durante las revisiones del código, nuestros desarrolladores se preguntan: “¿Necesito actualizar algún panel?” Están facultados para realizar cambios en los paneles antes de implementar los cambios subyacentes. Esto evita la situación en la que un operador tiene que actualizar los paneles durante o después de la implementación de un sistema para validar el cambio que se está implementando.
Si un panel contiene mucha más información detallada de lo habitual, podría indicar que los operadores se basan en ese panel para la detección manual de anomalías en lugar de las alarmas y las soluciones automatizadas. Auditamos continuamente nuestros paneles para determinar si podemos reducir este esfuerzo manual mediante la mejora de la instrumentación de nuestros servicios y el perfeccionamiento de nuestras alarmas automatizadas. También simplificamos o actualizamos activamente los gráficos que ya no agregan valor a los paneles.
Al permitir que nuestros desarrolladores actualicen los paneles, nos aseguramos de tener un conjunto completo e idéntico de paneles para nuestros entornos de preproducción (alfa, beta o gamma). Nuestras canalizaciones automatizadas de implementación realizan primero los cambios en los entornos de preproducción. Por lo tanto, nuestros equipos deben poder validar fácilmente los cambios en estos entornos de prueba utilizando los paneles asociados (y las alarmas automatizadas) de una manera que sea coherente con la forma en que se validarán cuando los cambios se implementen en nuestros entornos de producción.
La mayoría de los sistemas evolucionan continuamente a medida que se actualizan los requisitos, se agregan nuevas funciones y las arquitecturas de software cambian para adaptarse al escalado a lo largo del tiempo. Nuestros paneles son un componente esencial de nuestros sistemas, por lo que seguimos el proceso de Infraestructura como código (Infrastructure-as-Code, IaC) para mantenerlos. Este proceso garantiza que nuestros paneles se mantengan en los sistemas de control de versiones y que los cambios se implementen en nuestros paneles con las mismas herramientas que nuestros desarrolladores y operadores utilizan para nuestros servicios.
Cuando realizamos un análisis posterior de un evento operativo inesperado, nuestros equipos revisan si las mejoras en los paneles (y las alarmas automatizadas) podrían haber anticipado el evento, identificado la causa raíz más rápido o reducido el tiempo promedio de recuperación. Por lo general, nos preguntamos: “En retrospectiva, ¿los paneles mostraron claramente el impacto en el cliente, ayudaron a los operadores a triangular para determinar la causa raíz final y ayudaron a medir el tiempo de recuperación?” Si la respuesta a cualquiera de estas preguntas es no, nuestros análisis posteriores incluyen acciones para ajustar esos paneles.
Conclusión
En Amazon, operamos servicios a gran escala en todo el mundo. Nuestros sistemas automatizados monitorean, detectan, alertan y solucionan constantemente cualquier problema que se presente. Necesitamos la capacidad de monitorear, analizar de manera profunda, auditar y revisar estos servicios y sistemas automatizados. Para lograr esto, creamos y mantenemos paneles que proporcionan muchas vistas diferentes de nuestros sistemas. Diseñamos estos paneles para audiencias generales y específicas trabajando retrospectivamente desde los usuarios del panel. A fin de facilitar la comprensión de los paneles para los operadores y los propietarios de servicios, utilizamos un conjunto coherente de expresiones y convenciones de diseño para garantizar la facilidad de uso y la utilidad del panel.
Nuestros paneles brindan muchas perspectivas y vistas diferentes sobre cómo funcionan los servicios de AWS. Desempeñan un papel fundamental en la entrega de una excelente experiencia del cliente al ayudar a los equipos de Amazon a comprender, operar y escalar nuestros servicios. Esperamos que este artículo lo ayude a diseñar, crear y mantener sus propios paneles. Si desea ver un ejemplo de cómo crear paneles con los servicios de AWS, aquí hay un video breve y una guía de autoservicio.
Acerca del autor
John O'Shea es ingeniero jefe en Amazon Web Services. Actualmente se centra en Amazon CloudWatch y otros servicios internos de monitoreo y observabilidad de Amazon.

Contenido relacionado
¿Encontró lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios