Estabilidad estática con zonas de disponibilidad
ARQUITECTURA | NIVEL 300
Introducción
En Amazon, los servicios que desarrollamos deben cumplir objetivos de disponibilidad en extremo altos. Es decir, tenemos que considerar detenidamente las dependencias que adoptan nuestros sistemas. Diseñamos nuestros sistemas para que permanezcan resilientes incluso cuando esas dependencias están dañadas. En este artículo, definiremos un patrón denominado estabilidad estática que usamos para alcanzar este nivel de resiliencia. Le mostraremos cómo aplicamos este concepto a las zonas de disponibilidad, un componente clave de la infraestructura de AWS y, por lo tanto, una dependencia fundamental en la que se basan todos nuestros servicios.
En un modelo con estabilidad estática, el sistema global continúa funcionando incluso cuando falla una dependencia. Quizás el sistema no ve ninguna información actualizada (como componentes nuevos, borrados o modificados) que debería haber proporcionado la dependencia. Sin embargo, todas las acciones que se realizaban antes de que la dependencia fallara siguen funcionando a pesar del daño en ella. A continuación, describiremos cómo creamos Amazon Elastic Compute Cloud (EC2) para que logre la estabilidad estática. Luego, proporcionaremos, a modo de ejemplo, dos arquitecturas estáticamente estables, que han resultado útiles a la hora de crear sistemas regionales con alta disponibilidad sobre zonas de disponibilidad.
Por último, analizaremos en mayor detalle la filosofía de diseño en la que se basa Amazon EC2, incluida la forma en que este servicio está estructurado para ofrecer zonas de disponibilidad independientes a nivel de software. Además, explicaremos algunas de las compensaciones que implica crear un servicio con esta forma de arquitectura.
El rol de las zonas de disponibilidad
Las zonas de disponibilidad son secciones lógicamente aisladas de una región de AWS. Cada una de las regiones tiene múltiples zonas de disponibilidad que están diseñadas para operar de manera independiente. Estas zonas están separadas en el plano físico por una distancia significativa para protegerse del impacto correlativo con origen en posibles problemas, como rayos, tornados y terremotos. No comparten recursos energéticos ni ninguna otra forma de infraestructura, pero están conectadas entre sí a través de redes privadas de fibra óptica que son rápidas y están cifradas, lo que permite a las aplicaciones realizar una conmutación por error de forma rápida y sin interrupciones. En otras palabras, las zonas de disponibilidad proporcionan una capa de abstracción sobre el aislamiento de nuestra infraestructura. Los servicios que requieren una zona de disponibilidad permiten al intermediario indicar a AWS dónde aprovisionar físicamente la infraestructura dentro de la región, de modo que pueda beneficiarse de esta independencia. En Amazon, hemos creado servicios de AWS regionales que aprovechan esta independencia entre zonas para alcanzar sus propios objetivos de alta disponibilidad. Algunos ejemplos de estos servicios regionales son Amazon DynamoDB, Amazon Simple Queue Service (Amazon SQS) y Amazon Simple Storage Service (S3).
Cuando se interactúa con un servicio de AWS que aprovisiona infraestructura de nube dentro de una Amazon Virtual Private Cloud (VPC), muchos de estos servicios requieren que el intermediario especifique no solo una región sino también una zona de disponibilidad. Por lo general, la zona de disponibilidad se especifica de manera implícita en un argumento de subred obligatorio, por ejemplo, cuando se lanza una instancia EC2, cuando se aprovisiona una base de datos de Amazon Relational Database Service (RDS) o cuando se crea un clúster de Amazon ElastiCache. Aunque es común tener varias subredes en una zona de disponibilidad, una sola subred se ubica por completo en una única zona de disponibilidad, por lo que, cuando proporciona un argumento de subred, el intermediario también está brindando de forma implícita una zona de disponibilidad para su uso.
Estabilidad estática
Cuando creamos sistemas sobre zonas de disponibilidad, una de las lecciones que hemos aprendido es que debemos estar preparados para las fallas antes de que ocurran. Un enfoque menos efectivo podría ser la implementación en múltiples zonas de disponibilidad con la expectativa de que, en caso de que se produzca una falla en alguna de ellas, el servicio se ampliará (tal vez mediante AWS Auto Scaling) en otras zonas de disponibilidad y se restaurará a su estado correcto plenamente. Este enfoque es menos efectivo porque depende de la capacidad para reaccionar ante las fallas a medida que se producen, en lugar de estar preparado para ellas antes de que ocurran. Dicho de otro modo, carece de estabilidad estática. Por el contrario, un servicio más eficaz y estáticamente estable aprovisionaría en exceso su infraestructura hasta el punto de que continuaría funcionando correctamente sin tener que lanzar nuevas instancias EC2, incluso en el caso de que se dañara una zona de disponibilidad.
Para ilustrar mejor la propiedad de la estabilidad estática, veamos Amazon EC2, que está diseñado de acuerdo con esos principios.
El servicio Amazon EC2 consta de un plano de control y uno de datos. “Plano de control” y “plano de datos” son términos específicos del ámbito de las redes, pero los utilizamos ampliamente dentro de AWS. El plano de control es la maquinaria involucrada a la hora de realizar cambios a un sistema, como agregar recursos, eliminarlos o modificarlos, y lograr que se propaguen a donde sea necesario a fin de que surtan efecto. El plano de datos, en cambio, es el trabajo diario de esos recursos, es decir, lo que se necesita para que funcionen.
En Amazon EC2, el plano de control representa todo lo que sucede cuando EC2 lanza una nueva instancia. La lógica del plano de control reúne todo lo necesario para una nueva instancia EC2 a través de numerosas tareas. Los siguientes son algunos ejemplos:
- Encuentra un servidor físico para el cálculo, a la vez que respeta los requisitos de la tenencia de la VPC y del grupo de ubicación.
- Asigna una interfaz de red desde la subred de VPC.
- Prepara un volumen de Amazon Elastic Block Store (EBS).
- Genera credenciales para el rol de AWS Identity and Access Management (IAM).
- Instala las reglas del grupo de seguridad.
- Almacena los resultados en los almacenes de datos correspondientes a los distintos servicios posteriores.
- Propaga las configuraciones necesarias al servidor en la VPC y al borde de la red, según corresponda.
Por otro lado, el plano de datos de Amazon EC2 mantiene las instancias EC2 existentes en funcionamiento como es de esperar y realiza tareas como las siguientes:
- Direcciona los paquetes de acuerdo con las tablas de rutas de la VPC.
- Realiza lecturas y escrituras a partir de los volúmenes de Amazon EBS.
- Realiza otras tareas adicionales.
Como suele ocurrir con los planos de datos y de control, el primero que corresponde a Amazon EC2 es mucho más sencillo que el segundo. Como resultado de su relativa simplicidad, el diseño del plano de datos de Amazon EC2 apunta a una mayor disponibilidad que la del plano de control de este mismo servicio.
Es importante destacar que el plano de datos de Amazon EC2 se diseñó con cuidado para que sea estáticamente estable frente a los eventos de disponibilidad del plano de control (tales como deficiencias en la capacidad de lanzar instancias EC2). Por ejemplo, para evitar interrupciones en la conectividad de la red, el plano de datos de Amazon EC2 está diseñado para que el equipo físico en el que se ejecuta una instancia EC2 tenga acceso local a toda la información que necesita para direccionar los paquetes a puntos dentro y fuera de la VPC. Si se produce una falla en el plano de control de Amazon EC2, significa que, durante el evento, es posible que el servidor físico no vea actualizaciones, como una nueva instancia EC2 agregada a una VPC o una nueva regla para el grupo de seguridad. Sin embargo, el tráfico que se pudo enviar y recibir antes del evento continuará funcionando.
Los conceptos de planos de control, planos de datos y estabilidad estática se pueden aplicar ampliamente, incluso más allá de Amazon EC2. La capacidad de desmontar un sistema en su plano de control y de datos puede ser una herramienta conceptual útil a la hora de diseñar servicios con alta disponibilidad, por diversas razones:
- Es normal que la disponibilidad del plano de datos sea aún más crítica que la del plano de control para que los clientes de un servicio tengan éxito. Por ejemplo, la disponibilidad continua y el funcionamiento correcto de una instancia EC2, después de que se empieza a ejecutar, son aún más importantes para la mayoría de los clientes de AWS que la capacidad de lanzar instancias EC2 nuevas.
- Es normal que el plano de datos funcione a un volumen más alto (a menudo por órdenes de magnitud) que el plano de control. Por lo tanto, es mejor mantenerlos separados para que cada uno pueda expandirse de acuerdo con sus propias dimensiones de escalado relevantes.
- A lo largo de los años, hemos descubierto que el plano de control de un sistema tiende a tener más partes móviles que el plano de datos, por lo que es estadísticamente más probable que falle por esa sola razón.
Si combinamos todos esos factores, nuestra práctica recomendada es separar los sistemas a lo largo del límite entre el plano de control y el plano de datos.
Para lograr esta separación en la práctica, aplicamos los principios de la estabilidad estática. En general, un plano de datos depende de los datos que lleguen del plano de control. Sin embargo, para lograr un objetivo más alto de disponibilidad, el plano de datos mantiene su estado actual y continúa trabajando, incluso frente a una falla en el plano de control. Es posible que el plano de datos no reciba actualizaciones durante el periodo de fallas, pero todo lo que había estado funcionando antes continuará de esta manera.
Anteriormente, observamos que una estrategia que solicita el reemplazo de una instancia EC2 como respuesta a una falla en la zona de disponibilidad es un enfoque menos efectivo. No es porque no se puede lanzar la nueva instancia EC2. Se debe a que, en respuesta a una falla, el sistema tiene que tomar una dependencia inmediata para la ruta de recuperación en el plano de control de Amazon EC2, además de todos los sistemas específicos de la aplicación que son necesarios para que una instancia nueva comience a realizar un trabajo útil. Según el tipo de aplicación, estas dependencias pueden incluir pasos, como la descarga de la configuración del tiempo de ejecución, el registro de la instancia en los servicios de detección, la adquisición de credenciales, entre otros. Los sistemas del plano de control son necesariamente más complejos que los del plano de datos. Además, tienen una mayor probabilidad de no comportarse de manera adecuada cuando falla el sistema global.
Patrones de estabilidad estática
En esta sección, presentaremos dos patrones de alto nivel que utilizamos en AWS para diseñar sistemas de alta disponibilidad al aprovechar los beneficios de la estabilidad estática. Cada uno de ellos se aplica a su propio conjunto de situaciones, pero ambos aprovechan la abstracción de la zona de disponibilidad.
Ejemplo del patrón activo/activo en zonas de disponibilidad: un servicio con carga equilibrada
Varios servicios de AWS están compuestos internamente por contenedores de Amazon Elastic Container Service (ECS) o por una flota de instancias EC2, que se puede someter a escalado horizontal y que no tiene estado. Estos servicios se ejecutan en un grupo de Auto Scaling en tres o más zonas de disponibilidad. Además, aprovisionan en exceso la capacidad de modo que, incluso si fallara una zona de disponibilidad entera, los servidores en las zonas de disponibilidad restantes podrían soportar la carga. Por ejemplo, si se utilizan tres zonas de disponibilidad, se supera el aprovisionamiento normal en un 50 %. Dicho de otra manera, se aprovisiona en exceso de tal manera que cada zona de disponibilidad opera solo a un 66 % del nivel para el cual se ha probado su capacidad de carga.
El ejemplo más común es un servicio HTTPS con carga equilibrada. El siguiente diagrama muestra un balanceador de carga de aplicaciones orientado al público que presta un servicio HTTPS. El destino del balanceador de carga es un grupo de Auto Scaling que abarca las tres zonas de disponibilidad correspondientes a la región eu-west-1. Este es un ejemplo de alta disponibilidad con el patrón activo-activo que usa zonas de disponibilidad.
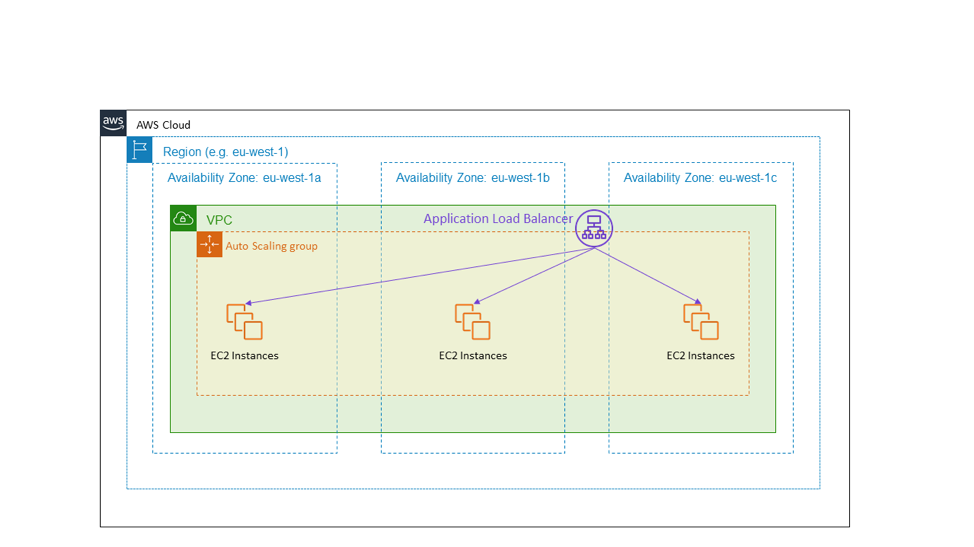
En el caso de un fallo en la zona de disponibilidad, la arquitectura que se muestra en el diagrama anterior no requiere llevar a cabo ninguna acción. Las instancias EC2 en la zona de disponibilidad dañada no superarán las próximas comprobaciones de estado, y el balanceador de carga de aplicaciones desviará el tráfico hacia otras zonas. De hecho, el servicio Elastic Load Balancing está diseñado conforme a este principio. Dispone de suficiente capacidad de balanceo de carga para soportar una falla en la zona de disponibilidad sin necesidad de escalado.
También utilizamos este patrón incluso cuando no hay un balanceador de carga o un servicio HTTPS. Por ejemplo, una flota de instancias EC2 que procesa mensajes de una cola de Amazon Simple Queue Service (Amazon SQS) también puede seguir este patrón. Las instancias se implementan en un grupo de Auto Scaling en múltiples zonas de disponibilidad, con un aprovisionamiento en exceso adecuado. En el caso de una zona de disponibilidad dañada, el servicio no realiza ninguna acción. Las instancias dañadas dejan de llevar a cabo su trabajo, y otras se encargan de compensar esa inactividad.
Ejemplo del patrón activo/en espera en zonas de disponibilidad: una base de datos relacional
Algunos de los servicios que creamos tienen estado y requieren un solo nodo principal o líder para coordinar el trabajo. Un ejemplo de esto es un servicio que utiliza una base de datos relacional, como Amazon RDS con un motor de base de datos MySQL o Postgres. Una configuración de alta disponibilidad típica para este tipo de base de datos relacional tiene una instancia principal, que es aquella a la que deben dirigirse todas las escrituras, y un candidato en espera. Es posible que también existan réplicas de lectura adicionales, las cuales no se muestran en el siguiente diagrama. Cuando se trabaja con una infraestructura con estado como esta, habrá un nodo en espera semiactiva en una zona de disponibilidad diferente a la del nodo principal.
El siguiente diagrama muestra una base de datos de Amazon RDS. Cuando se aprovisiona una base de datos con Amazon RDS, se necesita un grupo de subredes. Un grupo de subredes es un conjunto de subredes que abarcan varias zonas de disponibilidad en las que se aprovisionarán las instancias de la base de datos. Amazon RDS coloca el candidato en espera en una zona de disponibilidad diferente a la del nodo principal. Este es un ejemplo de alta disponibilidad con el patrón activo/en espera que usa zonas de disponibilidad.
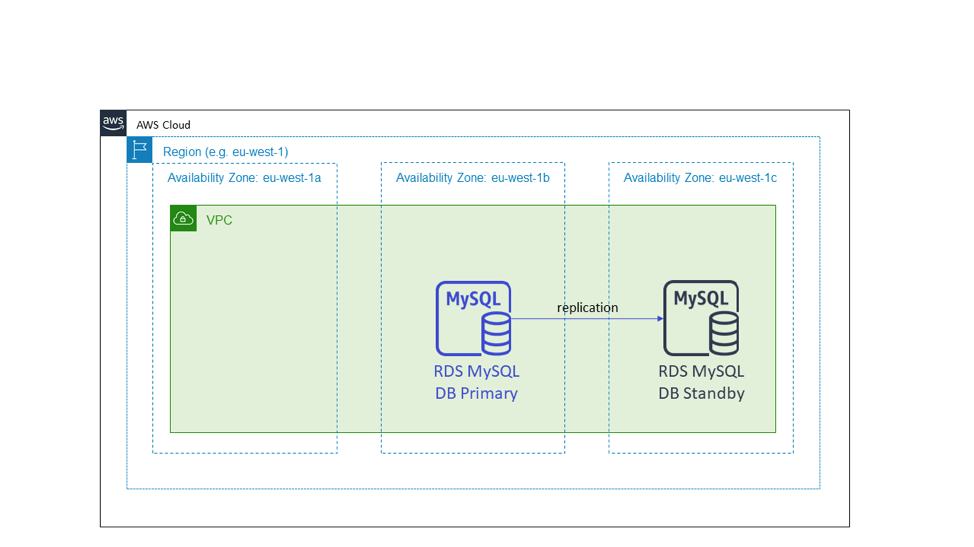
Al igual que en el caso del ejemplo sin estado con el patrón activo-activo, cuando falla la zona de disponibilidad con el nodo principal, el servicio con estado no interviene en la infraestructura. Para los servicios que utilizan Amazon RDS, este último administrará la conmutación por error y volverá a asignar el nombre del DNS al nuevo nodo principal en la zona de disponibilidad en funcionamiento. Este patrón también se aplica a otras configuraciones en modo activo/en espera, incluso si no utilizan una base de datos relacional. Concretamente, se aplica a sistemas con una arquitectura de clústeres que tiene un nodo líder. Estos clústeres se implementan en distintas zonas de disponibilidad y se elige el nuevo nodo líder a partir de un candidato en espera en lugar de activar un reemplazo “justo a tiempo”.
Lo que estos dos patrones tienen en común es que ambos ya habían aprovisionado la capacidad que necesitarían en caso de que fallara una zona de disponibilidad mucho antes de que se produjera cualquier falla real. En ninguno de estos casos, el servicio toma dependencias deliberadas en el plano de control, como el aprovisionamiento de infraestructura nueva o la aplicación de modificaciones, en respuesta a un fallo en la zona de disponibilidad.
Detrás de bastidores: estabilidad estática en Amazon EC2
En esta última sección del artículo, se profundizará un poco más en las arquitecturas de las zonas de disponibilidad resilientes y se cubrirán algunas de las formas en las que seguimos el principio de independencia en las zonas de disponibilidad para Amazon EC2. Comprender algunos de estos conceptos resulta útil a la hora de crear un servicio que no solo debe estar altamente disponible por sí solo, sino que también tiene que proporcionar una infraestructura en la que otros puedan tener alta disponibilidad. Amazon EC2, como proveedor de infraestructura AWS de bajo nivel, es la infraestructura que las aplicaciones pueden utilizar para ofrecer una disponibilidad alta. En ocasiones, es posible que otros sistemas también deseen adoptar esa estrategia.
Seguimos el principio de independencia en las zonas de disponibilidad en Amazon EC2 con nuestras prácticas de implementación. En Amazon EC2, el software se implementa en los servidores físicos que alojan instancias EC2, dispositivos de borde, solucionadores de DNS, componentes del plano de control en la ruta de lanzamiento de la instancia EC2 y muchos otros componentes de los que dependen las instancias EC2. Estas implementaciones siguen un calendario de implementación zonal. Es decir, dos zonas de disponibilidad en la misma región recibirán una implementación determinada en días diferentes. En todo AWS, se utilizan las implementaciones por etapas. Por ejemplo, seguimos la práctica recomendada (independientemente del tipo de servicio en el que implementamos) de implementar primero una solución de caja única y, luego, 1/N de servidores, etc. Sin embargo, en el caso específico de servicios como los de Amazon EC2, las implementaciones van un paso más allá y se alinean deliberadamente con el límite de la zona de disponibilidad. De esta forma, un problema en una implementación afecta a una zona de disponibilidad y se restaura y corrige. No afecta a otras zonas de disponibilidad, que siguen funcionando de manera normal.
Otra forma de utilizar el principio de las zonas de disponibilidad independientes cuando creamos en Amazon EC2 es diseñar todos los flujos de paquetes para que permanezcan dentro de la zona de disponibilidad en lugar de que crucen los límites. Conviene explorar con más detalle este segundo punto, es decir, que el tráfico de red debe mantenerse de forma local en la zona de disponibilidad. Se trata de un ejemplo interesante sobre cómo pensamos de manera diferente a la hora de crear un sistema regional de alta disponibilidad que utiliza zonas de disponibilidad independientes (es decir, usa las garantías de independencia en las zonas de disponibilidad como base para la creación de un servicio de alta disponibilidad), en contraste con lo que ocurre cuando proporcionamos una infraestructura de zonas de disponibilidad independientes a otros, que les permitirá lograr una alta disponibilidad.
En el siguiente diagrama, se muestra un servicio externo de alta disponibilidad, en color anaranjado, que depende de otro servicio interno, en color verde. Un diseño sencillo considera estos dos servicios como consumidores de zonas de disponibilidad de EC2 independientes. Hay balanceador de carga de aplicaciones por cada uno de los servicios de color anaranjado y verde, y cada servicio tiene una flota bien aprovisionada de alojamientos backend repartidos entre tres zonas de disponibilidad. Un servicio regional de alta disponibilidad llama a otro servicio regional de alta disponibilidad. Este es un diseño simple, y para muchos de los servicios que hemos creado, es un buen diseño.
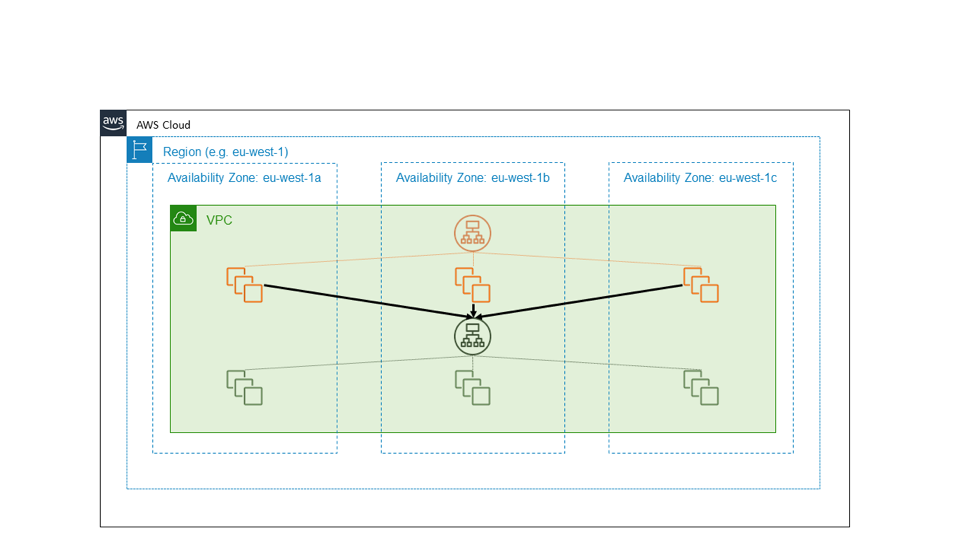
Pero supongamos que el servicio de color verde es un servicio básico. Es decir, supongamos que debe no solo tener un nivel alto de disponibilidad, sino que también debe servir de base para ofrecer la independencia en las zonas de disponibilidad. En ese caso, podríamos mejor diseñarlo como tres instancias de un servicio de zona local, en el que seguimos las prácticas de implementación que tienen en cuenta las zonas de disponibilidad. En el siguiente diagrama, se muestra el diseño en el que un servicio regional de alta disponibilidad llama a un servicio zonal de alta disponibilidad.
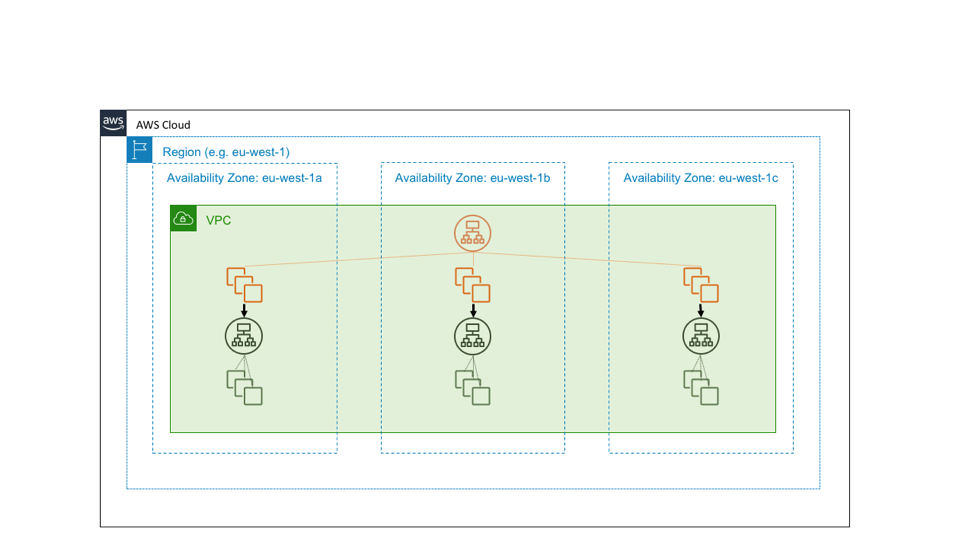
Las razones por las que diseñamos nuestros servicios fundamentales para que tengan independencia en las zonas de disponibilidad se reducen a una simple aritmética. Supongamos que falla una zona de disponibilidad. Para los errores graves o los insignificantes, el balanceador de carga de aplicaciones generará un error para alejarse de los nodos afectados. Sin embargo, no todos errores son tan obvios. Es posible que se produzcan errores sutiles, como en el software, que el balanceador de carga no podrá reconocer en su comprobación de estado ni podrá gestionar correctamente.
En el ejemplo anterior, donde un servicio regional de alta disponibilidad llama a otro servicio regional de alta disponibilidad, si se envía una solicitud a través del sistema, entonces con algunas suposiciones simplificadoras, la probabilidad de que la solicitud evite la zona de disponibilidad dañada es de 2/3 * 2/3 = 4/9. Es decir, la solicitud tiene peores probabilidades de evitar el evento. Por el contrario, si creamos el servicio de color verde para que sea un servicio zonal como en el ejemplo actual, los alojamientos del servicio de color anaranjado podrán llamar al punto de enlace verde en la misma zona de disponibilidad. Con esta arquitectura, las probabilidades de evitar la zona de disponibilidad dañada son de 2/3. Si N cantidad de servicios forma parte de esta ruta de llamada, estos números se generalizan a (2/3)^N para N servicios regionales frente a la constante restante de 2/3 para N servicios zonales.
Por esta razón, creamos la gateway de NAT de Amazon EC2 como un servicio zonal. La gateway de NAT es una característica de Amazon EC2 que permite el tráfico saliente de Internet desde una subred privada y no aparece como una gateway regional para todo la VPC, sino como un recurso zonal, en el que los clientes crean una instancia por separado por cada zona de disponibilidad, tal y como se muestra en el diagrama que aparece a continuación. La gateway de NAT se sitúa en la ruta de conectividad a Internet para la VPC y, por lo tanto, es parte del plano de datos de cualquier instancia EC2 dentro de esa VPC. Si hay una falla de conectividad en una zona de disponibilidad, queremos mantener esa falla dentro de esa zona, en lugar de propagarla a otras. En definitiva, queremos que un cliente que creó una arquitectura similar a la mencionada anteriormente en este artículo (es decir, mediante el aprovisionamiento de una flota en tres zonas de disponibilidad con capacidad suficiente en cualquier par de ellas para tolerar la carga completa) sepa que las otras zonas de disponibilidad no se verán afectadas en absoluto por ningún evento que ocurra en la zona de disponibilidad dañada. La única forma de lograrlo es asegurarnos de que todos los componentes básicos, como la puerta de enlace de NAT, permanezcan realmente dentro de la zona de disponibilidad.
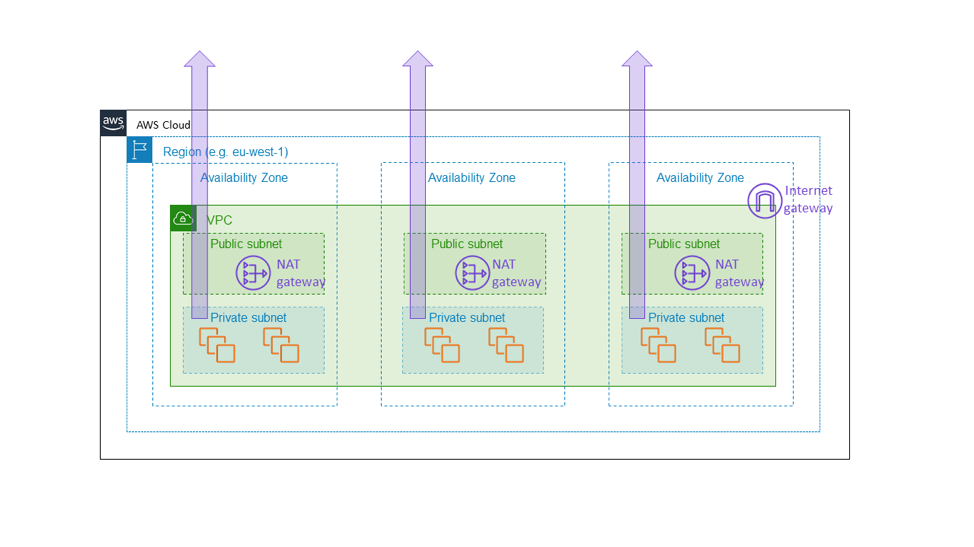
Esta elección conlleva el costo de una complejidad adicional. Para nosotros, en Amazon EC2, la complejidad adicional consiste en la forma de administrar los entornos de servicio zonales, en lugar de regionales. Para los clientes de la gateway de NAT, la complejidad adicional consiste en tener múltiples gateways de NAT y tablas de rutas, para su uso en las diferentes zonas de disponibilidad de la VPC. La complejidad adicional es adecuada porque la gateway de NAT es de por sí un servicio básico, parte del plano de datos de Amazon EC2 que se supone que proporciona garantías de la disponibilidad zonal.
Existe un asunto más que debemos considerar cuando creamos servicios con independencia en las zonas de disponibilidad: la durabilidad de los datos. Aunque cada una de las arquitecturas zonales descritas anteriormente presenta la pila completa dentro de una única zona de disponibilidad, replicamos cualquier estado sin cambios en varias zonas de disponibilidad para fines de recuperación de desastres. Por ejemplo, normalmente almacenamos copias de seguridad periódicas de la base de datos en Amazon S3 y conservamos réplicas de lectura de nuestros almacenes de datos que trascienden los límites de la zona de disponibilidad. Estas réplicas no son necesarias para que funcione la zona de disponibilidad principal. Por el contrario, garantizan que almacenemos los datos importantes para el cliente o la empresa en varias ubicaciones.
Cuando diseñamos una arquitectura orientada a servicios para que se ejecute en AWS, aprendimos a usar uno de estos dos patrones o una combinación de ambos:
- El patrón más simple implica que el servicio regional llame a otro regional. Por lo general, esta es la mejor opción para los servicios orientados al exterior y también es adecuada para la mayoría de los servicios internos. Por ejemplo, cuando creamos servicios de aplicaciones de mayor nivel en AWS, como tecnologías sin servidor de AWS y Amazon API Gateway, utilizamos este patrón para ofrecer una alta disponibilidad, incluso en caso de fallas en la zona de disponibilidad.
- El patrón más complejo implica que el servicio regional llame a otro zonal o el servicio zonal llame a otro zonal. Cuando se diseñan componentes del plano de datos internos y, en algunos casos, externos dentro de Amazon EC2 (por ejemplo, dispositivos de red u otra infraestructura que se sitúa directamente en la ruta de datos crítica), seguimos el patrón de independencia en la zona de disponibilidad y utilizamos las instancias que se encuentran aisladas en las zonas de disponibilidad, de modo que el tráfico de la red permanezca dentro de su misma zona de disponibilidad. Este patrón no solo ayuda a mantener los fallos aislados en una zona de disponibilidad, sino que también tiene características favorables respecto al costo del tráfico de red en AWS.
Conclusión
En este artículo, hemos analizado algunas estrategias simples que utilizamos en AWS para tomar con éxito las dependencias en las zonas de disponibilidad. Hemos aprendido que la clave para la estabilidad estática es anticipar las fallas antes de que ocurran. Independientemente de si un sistema se ejecuta en una flota con escalabilidad horizontal activa/activa, o si se trata de un patrón con estado activo/en espera, podemos utilizar las zonas de disponibilidad para alcanzar altos niveles de disponibilidad. Implementamos nuestros sistemas de manera que toda la capacidad que será necesaria en caso de una falla ya esté totalmente aprovisionada y lista para su uso. Por último, examinamos en mayor nivel de detalle la forma en que el propio servicio Amazon EC2 utiliza conceptos de estabilidad estática para mantener las zonas de disponibilidad independientes entre sí.
Acerca de los autores
Becky Weiss
 Becky Weiss es una ingeniera principal sénior en Amazon Web Services. Actualmente, se centra en Identity and Access Management en AWS y, por lo general, en proporcionar controles de seguridad flexibles, integrales y autoritarios para clientes en la nube. Anteriormente, trabajó en Amazon Virtual Private Cloud (redes) y AWS Lambda, y también colaboró con Servicios profesionales de AWS para ayudar a los clientes empresariales a proteger sus entornos en AWS de manera correcta. Becky también es la mayor entusiasta de AWS y, en su tiempo libre, crea todo tipo de inventos útiles e inútiles en AWS. Antes de ingresar a AWS, Becky trabajó para Microsoft en Windows y Windows Phone.
Becky Weiss es una ingeniera principal sénior en Amazon Web Services. Actualmente, se centra en Identity and Access Management en AWS y, por lo general, en proporcionar controles de seguridad flexibles, integrales y autoritarios para clientes en la nube. Anteriormente, trabajó en Amazon Virtual Private Cloud (redes) y AWS Lambda, y también colaboró con Servicios profesionales de AWS para ayudar a los clientes empresariales a proteger sus entornos en AWS de manera correcta. Becky también es la mayor entusiasta de AWS y, en su tiempo libre, crea todo tipo de inventos útiles e inútiles en AWS. Antes de ingresar a AWS, Becky trabajó para Microsoft en Windows y Windows Phone.
Mike Furr
 Mike Furr es un ingeniero principal en Amazon Web Services. Se unió a Amazon en 2009 después de completar su doctorado en Ciencias Informáticas en la Universidad de Maryland, College Park. Durante su tiempo en Amazon, ha trabajado en la nube virtual privada (VPC), AWS Direct Connect, así como en la pila de medición y facturación de AWS. Ahora dedica su tiempo a EC2, donde ayuda a los equipos a expandir la nube.
Mike Furr es un ingeniero principal en Amazon Web Services. Se unió a Amazon en 2009 después de completar su doctorado en Ciencias Informáticas en la Universidad de Maryland, College Park. Durante su tiempo en Amazon, ha trabajado en la nube virtual privada (VPC), AWS Direct Connect, así como en la pila de medición y facturación de AWS. Ahora dedica su tiempo a EC2, donde ayuda a los equipos a expandir la nube.
Contenido relacionado
¿Encontró lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios