Éviter les solutions de secours dans les systèmes distribués
ARCHITECTURE | NIVEAU 300
Introduction
Les défaillances critiques empêchent un service de produire des résultats utiles. Par exemple, dans un site Web de commerce électronique, si une requête de base de données pour obtenir les informations d'un produit échoue, le site ne peut pas afficher la page du produit. Les services Amazon doivent gérer la majorité des échecs critiques pour pouvoir fonctionner correctement. Il existe quatre grandes catégories de stratégies pour gérer les échecs critiques :
- Essayer à nouveau : faites un nouvel essai, immédiatement après le premier ou après un certain temps.
- Essayer à nouveau en anticipant le problème : faites plusieurs essais simultanés en parallèle et utilisez la première tentative à fonctionner pour terminer ce que vous faisiez.
- Basculement : faites un nouvel essai sur une autre copie du point de terminaison ou, de préférence, effectuez plusieurs copies en parallèle de ce que vous faisiez pour augmenter les chances qu’au moins l’une d’entre elles fonctionne
- Solution de secours : essayez un autre moyen qui vous permettrait d’arriver au même résultat.
Cet article traite des stratégies de secours et explique pourquoi elles ne sont pratiquement jamais utilisées chez Amazon. Cela peut surprendre. Après tout, les ingénieurs s'inspirent du monde réel pour leurs conceptions. Et dans le monde réel, les stratégies de secours doivent être pensées à l'avance et utilisées lorsque nécessaire. Imaginons que, dans un aéroport, les tableaux d'affichage cessent de fonctionner. Il faut bien qu'il y ait un plan B pour gérer cette situation, car les passagers, eux, ont toujours besoin de prendre leur avion. Du personnel pourrait par exemple communiquer les informations de vol par écrit, sur des tableaux. Mais cette solution est loin d'être idéale : les informations ne seront pas forcément lisibles pour tous, il sera difficile de les actualiser en permanence et il existe un risque d'erreurs humaines en recopiant les informations. Cette stratégie est nécessaire, mais elle comporte de nombreux défauts.
Dans un monde où les systèmes distribués sont omniprésents, les stratégies de secours font partie des défis les plus difficiles à gérer, en particulier pour les services pour lesquels la rapidité d'exécution est cruciale. Pour ne rien arranger, les répercussions des stratégies de secours peuvent mettre du temps (parfois des années) avant de se faire sentir, et la différence entre une bonne stratégie et une mauvaise stratégie est subtile. Dans cet article, nous verrons principalement pourquoi les stratégies de secours peuvent parfois causer plus de problèmes qu'elles n'en résolvent. Nous verrons également quelques exemples de situations dans lesquelles des stratégies de secours ont nui à Amazon. Enfin, nous aborderons les alternatives qui ont été adoptées chez Amazon.
L’analyse des stratégies de secours n’a rien d’intuitif et leurs répercussions dans les systèmes distribués sont difficiles à prévoir. C’est pourquoi nous allons commencer avec des stratégies de secours pour une application exécutée sur un seul appareil.
Solutions de secours pour un seul appareil
Prenons l'extrait de code suivant. Il est en langage C. Il s'agit d'un schéma courant pour gérer les échecs d'allocation de la mémoire. On le retrouve dans de nombreuses applications. Ce code permet d’allouer de la mémoire à l’aide de la fonction malloc(). Un tampon d’image est ensuite copié dans cette mémoire le temps d’effectuer les modifications voulues :
pixel_ranges = malloc(image_size); // alloue de la mémoire
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}
Le code ne peut pas être récupéré si la fonction malloc aboutit à un échec. Dans les faits, les problèmes avec cette fonction sont rares. C'est pourquoi les développeurs les ignorent souvent lorsqu'ils codent. Pourquoi cette stratégie est-elle si communément utilisée ? La raison est que, sur un appareil unique, si la fonction malloc aboutit à un échec, c'est que la machine manque probablement de mémoire. Le problème n'est donc pas tant que la fonction malloc a abouti à un échec, mais que l'appareil pourrait planter bientôt. Et la plupart du temps, lorsqu'il n'y a qu'un seul appareil concerné, le problème n'est pas pris au sérieux. De nombreuses applications ne sont pas essentielles au point de consacrer du temps et de l'énergie à résoudre ce type de problème épineux. Mais que se passerait-il si l'erreur n'était pas gérée ? Il n'est pas évident de savoir quoi faire dans ce genre de situation. Imaginons maintenant que nous implémentons une deuxième méthode que nous appellerons malloc2. Cette fonction alloue de la mémoire de manière différente et nous l’utiliserons si la fonction par défaut (malloc) aboutit à un échec :
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}
À première vue, ce code a tout pour fonctionner. Pourtant, il n’est pas exempt de problèmes, certains étant plus évidents que d’autres. Premier point : la logique de secours est difficile à tester. Nous pourrions bloquer l'utilisation de la fonction malloc et créer un échec, mais rien ne dit que cela permettrait d'avoir une image fidèle de ce qu'il se passerait dans l'environnement de production. En production, si la fonction malloc aboutit à un échec, cela signifie que l'appareil manque probablement de mémoire. Comment simuler ces problèmes plus larges de mémoire ? Même si, pour exécuter le test, il était possible de générer un environnement dans lequel la mémoire venait à manquer (avec un conteneur Docker, par exemple), comment pourrait-on faire coïncider cette condition de faible mémoire avec l'exécution du code de secours malloc2 ?
Autre problème : la solution de secours pourrait elle-même échouer. Le code de secours précédent ne gère pas les échecs de malloc2. Le programme n'est donc pas aussi intéressant qu'on pourrait le penser. Avec la stratégie de secours, le risque d'échec complet serait réduit, mais pas impossible. Chez Amazon, nous avons découvert que dépenser des ressources d'ingénierie pour fiabiliser le premier code (c.-à-d. pas le code de secours) augmentait plus nos chances de succès que d'investir dans une stratégie de secours utilisée à l'occasion.
En outre, si la disponibilité est notre plus grande priorité, la stratégie de secours pourrait ne pas en valoir la chandelle. À quoi sert la fonction malloc si la fonction malloc2 a plus de chance de fonctionner ? En toute logique, si la fonction malloc2 est plus disponible, elle doit aussi avoir ses défauts. Elle alloue peut-être de la mémoire dans un stockage sur SSD plus important et à latence plus élevée. Cela soulève une autre question : pourquoi les inconvénients de la fonction malloc2 ne sont-ils pas un problème ? Imaginons une séquence d'événements qui pourraient se produire dans cette stratégie de secours. Pour commencer, le client utilise l'application. Tout à coup (parce que la fonction malloc a abouti à un échec), la fonction malloc2 entre en action et fait ralentir l'application. Les ralentissements sont-ils une bonne chose ? Pas vraiment. Et ce n'est pas tout. Imaginons que l'appareil manque probablement de mémoire. Le client a maintenant deux problèmes au lieu d'un : le ralentissement de l'application et celui de l'appareil. Les effets secondaires induits par l'activation de la fonction malloc2 pourraient en fait même aggraver le problème. D'autres sous-systèmes pourraient, par exemple, avoir du mal à accéder au même stockage sur SSD.
La logique de secours peut aussi provoquer des charges imprévisibles sur le système. Même une logique simple et courante comme l'écriture d'un message d'erreur dans un fichier d'historique avec trace de pile est inoffensive à la surface. Mais s'il se produit soudainement un quelconque changement qui provoque cette erreur à fréquence élevée, une application liée au processeur pourrait d'un seul coup se transformer en application liée aux E/S. Et si le disque n’a pas été dimensionné pour gérer l’écriture à cette fréquence ou pour stocker cette quantité de données, l’application peut finir par ralentir ou planter.
Si non seulement la stratégie de secours peut aggraver le problème, elle pourrait en plus prendre la forme d’un bogue latent. Développer des stratégies de secours qui sont rarement utilisées en production n’a rien de compliqué. Il peut se passer des années avant que l'appareil d'un client manque de mémoire pile au moment où se déclenche la ligne de code qui contient la solution de secours de la fonction malloc2 dont nous avons parlé plus haut. Si d'aventure un bogue dans la logique de secours ou un effet secondaire quelconque venait à aggraver le problème dans son ensemble, les ingénieurs qui ont écrit le code auront probablement oublié comment il fonctionne et il leur sera plus difficile de régler le problème. Dans le cas d'une application sur un seul appareil, ce problème peut être toléré par l'entreprise, mais dans les systèmes distribués, les conséquences sont bien plus importantes, comme nous le verrons plus tard.
Tous ces problèmes sont épineux en soi, mais d'après notre expérience, ils peuvent bien souvent être ignorés sans risque pour les applications impliquant un seul appareil. La solution la plus courante est celle qui a été mentionnée plus haut : il suffit de laisser les erreurs d'allocation de la mémoire planter l'application. Le code qui alloue la mémoire subit le même sort que le reste de la machine, à savoir l'échec dans le cas présent. Et même si ce n'était pas le cas, l'application devrait, à ce stade, être dans un état qui n'a pas été anticipé, et l'échec rapide constitue une bonne stratégie. C'est un compromis acceptable pour une entreprise.
Pour les applications exécutées sur un seul appareil qui doivent fonctionner en situation d'échec de l'allocation de la mémoire, une des solutions serait d'allouer par avance la mémoire de tas au démarrage et de ne jamais réutiliser la fonction malloc, même en cas d'erreur. Amazon a mis en œuvre cette stratégie plusieurs fois, pour la surveillance des démons qui sont exécutés sur les serveurs de production et pour ceux d’Amazon Elastic Compute Cloud (Amazon EC2) qui surveillent les pics d’activité des processeurs des clients.
Solutions de secours pour un système distribué
Chez Amazon, nous n'acceptons pas les mêmes compromis pour les systèmes distribués, et en particulier pour les systèmes qui sont censés répondre en temps réel, que pour les applications exécutées sur un seul appareil. L'une des raisons à cela est la dissociation (« shared fate ») d'avec le client : son système et le nôtre ne plantent pas ensemble. Nous pouvons partir du principe que les applications sont exécutées sur des appareils devant lesquels se tiennent les clients. Si l'application manque de mémoire, le client ne s'attendra probablement pas à ce qu'elle continue de fonctionner. Les services ne sont pas exécutés sur l'appareil que le client utilise directement. Les attentes sont donc différentes. Qui plus est, les clients préfèrent en général utiliser les services, précisément parce qu'ils sont plus disponibles qu'une application à exécuter sur un serveur unique. C'est pourquoi nous devons tout faire pour garantir cette disponibilité. En théorie, cela devrait nous conduire à mettre en œuvre des solutions de secours afin de garantir la disponibilité du service. Malheureusement, les solutions de secours pour les systèmes distribués présentent toutes les mêmes problèmes, voire plus, lorsqu’elles débouchent sur des échecs critiques du système.
Les solutions de secours pour les systèmes distribués sont plus difficiles à tester. Les solutions de secours sont plus complexes lorsqu’elles concernent les services que les applications exécutées sur un seul appareil, car plusieurs machines et services en aval jouent un rôle dans les échecs. Les défaillances elles-mêmes, comme les cas de surcharge, sont difficiles à reproduire lors d'un test, même si son orchestration entre plusieurs appareils est rapidement disponible. L’analyse combinatoire augmente également le nombre de cas à tester. Dès lors, il est nécessaire d’effectuer plus de tests et ceux-ci sont d’autant plus difficiles à organiser.
Les stratégies de secours pour les systèmes distribués peuvent échouer elles aussi. Bien que l’on puisse croire que les stratégies de secours garantissent le succès, nous estimons, d’après notre expérience, qu’en général elles ne font qu’augmenter les chances de réussite.
Les stratégies de secours pour les systèmes distribués aggravent souvent les pannes. Toujours selon notre expérience, les stratégies de secours ont pour effet d’augmenter la portée de l’impact des échecs, ainsi que les délais de récupération.
Les stratégies de secours pour les systèmes distribués ne valent en général pas la chandelle. Comme pour la fonction malloc2, la stratégie de secours présente souvent des avantages et des inconvénients, ce qui explique pourquoi on ne l’utilise pas tout le temps. Pourquoi utiliser une solution de secours qui aggrave une situation déjà problématique à la base ?
Les stratégies de secours pour les systèmes distribués contiennent souvent des bogues latents que l'on découvre lorsqu'une improbable série de coïncidences se produit, potentiellement des mois ou des années plus tard.
Tous ces problèmes se sont produits lors d'une panne majeure provoquée par un mécanisme de secours intégré au site Web commercial d'Amazon. La panne s'est produite aux alentours de l'année 2001 et a été causée par une nouvelle fonctionnalité qui permettait d'afficher les délais de livraison actualisés pour tous les produits présentés sur le site Web. Cette nouvelle fonctionnalité ressemblait à peu près à ceci :

À cette époque, l’architecture du site Web ne comprenait que deux parties et, comme ces données étaient stockées dans une base de données de la chaîne d’approvisionnement, les serveurs Web devaient envoyer les requêtes directement à la base de données. Malheureusement, la base de données ne parvenait pas à suivre le rythme par rapport au volume de requêtes émanant du site Web. Le site Web enregistrait un trafic important et certaines pages affichaient 25 produits, voire plus, chacun avec un délai de livraison différent. Nous avons donc décidé d’ajouter une couche de mise en cache dans un processus séparé sur chaque serveur Web (quelque chose comme Memcached) :
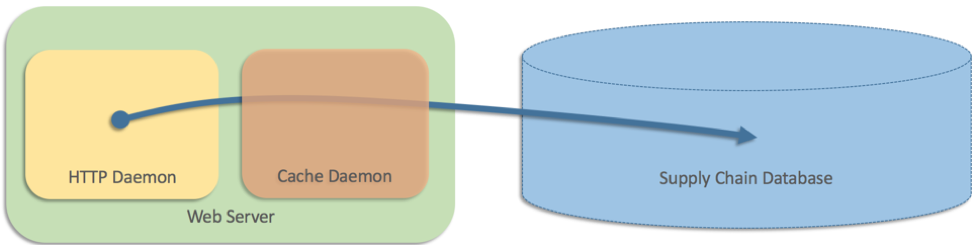
Cela a plutôt bien fonctionné, mais notre équipe a voulu prévoir le cas où il y aurait un échec avec le cache (c.-à-d. le processus séparé). Dans ce cas de figure, les serveurs Web devaient envoyer de nouveau les requêtes directement à la base de données. En pseudo-code, nous avions écrit quelque chose comme cela :
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}
Cette solution, qui consistait à revenir aux envois directs de requêtes à la base de données, était intuitive et a parfaitement fait l'affaire pendant plusieurs mois. Puis, un jour, tous les caches ont cessé de fonctionner à peu près en même temps, ce qui veut dire que tous les serveurs Web se sont adressés à la base de données directement. Le volume de requêtes a été tel qu'elle a été complètement bloquée. Le site Web tout entier est tombé en panne, car tous les processus des serveurs Web étaient bloqués sur la base de données. La base de données de la chaîne d'approvisionnement était également essentielle pour les centres de traitement. La panne a fait tache d'huile et tous les centres de traitement dans le monde ont dû s'arrêter jusqu'à ce que le problème soit réglé.
L'ensemble des problèmes dont nous avons parlé lorsque nous avons abordé le cas de figure d'un appareil seul se sont déclarés dans un contexte de système distribué, avec des conséquences catastrophiques. Il était difficile de tester cette solution de secours. Même si nous avions simulé l'échec du cache, nous n'aurions pas détecté le problème, car il aurait fallu un échec sur plusieurs machines pour qu'il se manifeste. Et dans ce cas précis, la stratégie de secours a amplifié le problème et s'est avérée pire que si nous n'avions rien fait pour prévenir le problème. La solution de secours a transformé une petite panne sur un élément du site Web (qui empêchait d'afficher les délais de livraison) en panne majeure de l'ensemble du site (qui empêchait de charger les pages tout entières) et a mis à l'arrêt la totalité de réseau de traitement d'Amazon.
La réflexion sur laquelle s'est appuyée notre stratégie était, dans ce cas précis, illogique. S'il était plus fiable d'envoyer les requêtes directement à la base de données que de passer par le cache, pourquoi utiliser celui-ci en premier ? Nous avons eu peur que la base de données soit surchargée. Mais dans ce cas, pourquoi avoir écrit le code de secours si celui-ci était potentiellement si dangereux ? Nous aurions très bien pu détecter notre erreur plus tôt, mais ce bogue était latent, et il a fallu des mois après le lancement pour que les conditions qui ont provoqué la panne soient réunies.
Comment Amazon évite les solutions de secours
Compte tenu des problèmes que nous avons rencontrés avec nos solutions de secours pour les systèmes distribués, nous préférons désormais presque toujours les éviter. Voici les alternatives que nous avons trouvées.
Améliorer la fiabilité des situations qui ne relèvent pas de solutions de secours
Comme indiqué précédemment, les stratégies de secours réduisent à peine la probabilité d'un échec complet. Un service peut être bien plus disponible avec un code principal (c.-à-d. pas le code de secours) plus robuste. Par exemple, au lieu d'implémenter une logique de secours entre deux magasins de données, une équipe pourrait faire en sorte d'utiliser une base de données dotée d'une disponibilité inhérente plus importante, comme Amazon DynamoDB. Cette stratégie a de nombreuses fois porté ces fruits chez Amazon. Ce discours, par exemple, fait référence à l’utilisation de DynamoDB pour alimenter le site amazon.com lors du Prime Day 2017.
Laisser la fonction d’appel gérer les erreurs
L'une des solutions pour régler les problèmes d'échec critique du système consiste à ne pas appliquer de solution de secours, mais à laisser le système à l'origine de l'appel gérer l'échec (en réessayant, par exemple). Il s'agit de la stratégie de prédilection des services AWS, pour lesquels nos kits de développement logiciel (SDK) et nos interfaces de ligne de commande (CLI) sont déjà dotés d'une logique de réitération intégrée. C'est la stratégie que nous privilégions, en particulier lorsque nous avons investi une certaine quantité d'énergie à lier les systèmes entre eux (« fate sharing ») et à réduire la probabilité d'échec du cas principal (et il serait très étonnant que la logique de secours améliore sensiblement la disponibilité).
Transmettre les données de manière anticipée
Afin d'éviter le recours aux solutions de secours, nous employons également une approche qui consiste à réduire le nombre d'éléments mobiles dans le traitement des requêtes. Si, par exemple, un service a besoin de données pour traiter une requête, et que ces données sont déjà disponibles sur place (si elles n’ont pas besoin d’être récupérées), il n’est dès lors pas nécessaire d’adopter une stratégie de basculement. Cette stratégie a par exemple bien fonctionné lors de l’implémentation des rôles AWS Identity and Access Management (IAM) pour Amazon EC2. Le service IAM est chargé de fournir des informations d’identification signés et alternés pour le code exécuté sur des instances EC2. Pour éviter tout recours à des solutions de secours, les identifiants sont transmis à l'avance à chaque instance et restent valides plusieurs heures. Cela permet de s'assurer que les requêtes liées aux rôles IAM continuent de fonctionner dans l'éventualité improbable où le mécanisme de transmission serait hors service.
Convertir les solutions de secours en basculements
L'un des principaux inconvénients des solutions de secours est qu'elles ne sont pas utilisées régulièrement. La probabilité d'erreur ou son impact sont par conséquent plus importants lorsqu'elles sont employées au cours d'une panne. Il faut parfois attendre des mois, voire des années, pour que les conditions impliquant l'utilisation d'une solution de secours soient réunies ! Pour savoir régler les problèmes d'échec latents des stratégies de secours, il est important de s'exercer régulièrement en production. Un service doit exécuter à la fois la logique de secours et logique principale de manière continue. Il ne doit pas se contenter d'exécuter la situation impliquant la solution de secours, il doit aussi la traiter comme une source de données tout aussi valide. Un service pourrait par exemple choisir de manière aléatoire entre une réponse qui implique des solutions de secours et une réponse qui n'en implique pas (lorsqu'il récupère les deux) afin de s'assurer que les deux donnent les résultats escomptés. Mais à ce stage, la stratégie ne peut plus être considérée comme une solution de secours, mais doit être vue comme appartenant à la catégorie des basculements.
S'assurer que les nouvelles tentatives et les délais d'expiration ne deviennent pas des solutions de secours
Les nouvelles tentatives et les délais d'expiration sont traités dans l'article Délais d'expiration, nouvelles tentatives et interruption avec gigue. Dans cet article, les nouvelles tentatives sont décrites comme de puissants mécanismes qui permettent une disponibilité importante malgré des erreurs passagères et aléatoires. En d'autres termes, les nouvelles tentatives et les délais d'expiration constituent de bonnes protections contre les échecs occasionnels compte tenu de leurs inconvénients mineurs, comme les fausses pertes de paquets, les échecs non corrélés sur les appareils individuels et d'autres problèmes similaires. On peut cependant facilement faire fausse route avec les nouvelles tentatives et les délais d'expiration. Il peut se passer des mois voire plus sans que les services aient besoin d'effectuer de nouvelles tentatives, pour finalement devoir utiliser cette méthode dans des situations jamais testées. C'est pour cette raison que nous contrôlons toujours la fréquence des nouvelles tentatives à l'aide de métriques et que nos équipes sont informées, grâce à des alarmes, si cette fréquence dépasse un certain seuil.
Il existe un autre moyen d'éviter que les nouvelles tentatives ne deviennent des solutions de secours : il consiste à les exécuter continuellement avec une nouvelle tentative proactive (c'est ce que l'on appelle des requêtes de couverture ou des requêtes parallèles). Cette technique est par nature intégrée dans les systèmes qui effectuent un quorum en lecture ou en écriture, pour lequel un système peut avoir besoin d'une réponse de deux serveurs sur trois avant de pouvoir répondre. La méthode des nouvelles tentatives proactives suit le modèle de conception du travail constant. Étant donné que les requêtes redondantes sont sans arrêt répétées, les nouvelles tentatives n’ajoutent aucune charge supplémentaire au système alors que la nécessité de requêtes redondantes augmente.
Conclusion
Chez Amazon, nous évitons les solutions de secours dans nos systèmes, car il est difficile de prouver leur efficacité et de les tester. Les stratégies de secours font entrer un système dans un mode opérationnel uniquement dans les moments les plus critiques, lorsque la situation est sur le point d'échapper à tout contrôle, et basculer sur ce mode ne fait qu'ajouter du chaos au chaos. Les délais sont souvent longs entre le moment où la stratégie de secours est implémentée et celui où l'on peut voir ses effets dans l'environnement de production.
Nous préférons nous appuyer sur des codes appliqués de manière continue en production plutôt que sur des codes utilisés de temps en temps. Nous avons pour priorité d'améliorer la disponibilité de nos principaux systèmes. Pour ce faire, nous utilisons des modèles comme la transmission des données vers des systèmes qui en ont besoin au lieu de les extraire et de risquer l'échec d'un appel distant à un moment critique. Pour finir, nous sommes attentifs à la moindre réaction de notre code, en particulier à ce qui pourrait le transformer en mode de fonctionnement pouvant s'apparenter à des solutions de secours, comme le fait de réessayer les mêmes opérations trop souvent.
Si une solution de secours est essentielle dans un système, nous la mettons en pratique aussi souvent que possible en production, afin que ses résultats soient aussi fiables et prévisibles que le principal mode de fonctionnement.
À propos de l’auteur
Jacob Gabrielson est ingénieur principal senior chez Amazon Web Services. Il travaille chez Amazon depuis 17 ans, principalement sur des plateformes internes de microservices. Ces huit dernières années, il a travaillé sur EC2 et ECS, notamment sur les systèmes de déploiement de logiciels, les services de plan de contrôle, le marché des instances Spot, Lightsail et, plus récemment, les conteneurs. Jacob est passionné par la programmation des systèmes, les langages de programmation et l'informatique distribuée. Le comportement bimodal des systèmes est ce qui le rebute le plus, en particulier en cas d'échec. Il a obtenu une licence en informatique à l'université de Washington de Seattle.

Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages