Conseils pour l’intégration et l’analyse de données multiomiques et multimodales sur AWS
Présentation
Fonctionnement
Architecture
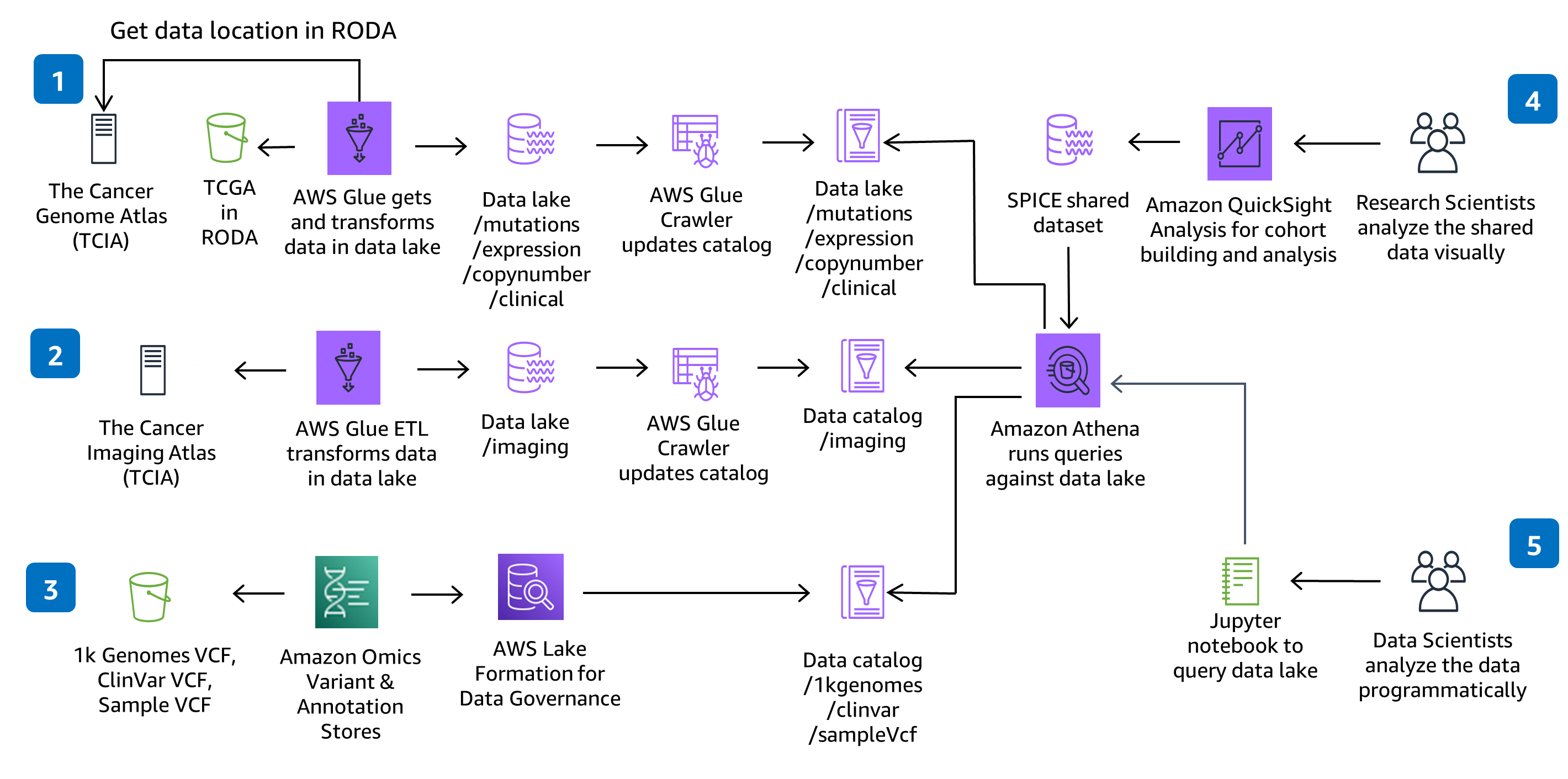
Préparez des données génomiques, cliniques, de mutation, d’expression et d’imagerie pour réaliser des analyses à grande échelle et exécuter des requêtes interactives sur un lac de données.
CI/CD
Préparez des données génomiques, cliniques, de mutation, d’expression et d’imagerie pour réaliser des analyses à grande échelle et exécuter des requêtes interactives sur un lac de données.
Piliers Well-Architected
Le diagramme d'architecture ci-dessus est un exemple de solution créée en tenant compte des bonnes pratiques Well-Architected. Pour être totalement conforme à Well-Architected, vous devez suivre autant de bonnes pratiques Well-Architected que possible.
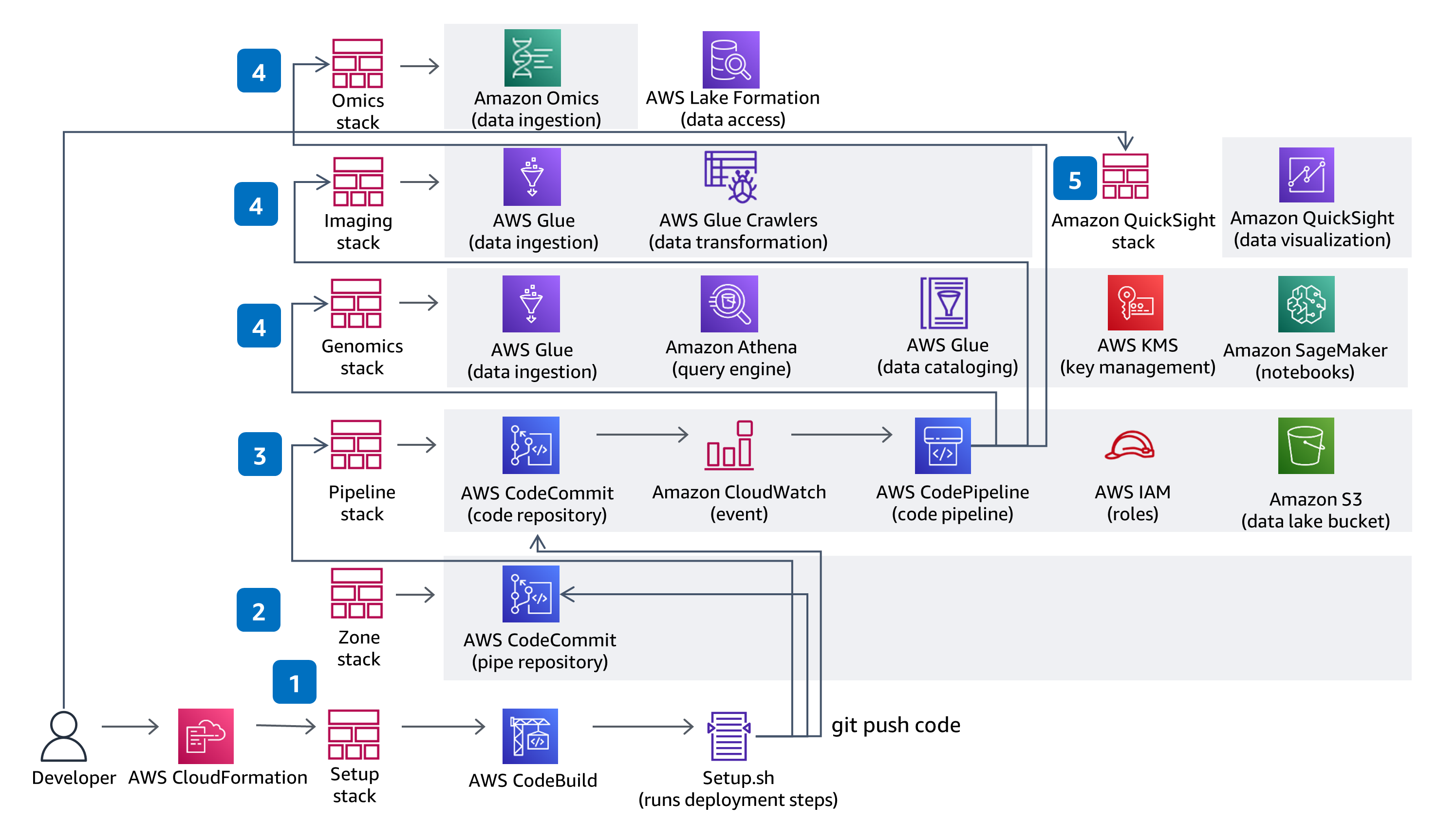
Ce guide utilise CodeBuild et CodePipeline pour créer, empaqueter et déployer tout ce qui est nécessaire dans la solution pour ingérer et stocker des fichiers d’appels de variantes (VCF) et travailler avec des données multimodales et multiomiques provenant des ensembles de données de The Cancer Genome Atlas (TCGA) et The Cancer Imaging Atlas (TCIA). L’ingestion et l’analyse de données génomiques sans serveur sont démontrées à l’aide d’un service entièrement géré, Amazon Omics. Les modifications de code apportées au référentiel CodeCommit de la solution seront déployées via le pipeline de déploiement CodePipeline fourni.
Ce guide utilise un accès basé sur les rôles avec IAM et tous les compartiments sont dotés d’un chiffrement activé, sont privés et bloquent l’accès public. Le cryptage du catalogue de données d’AWS Glue est activé et toutes les métadonnées écrites par AWS Glue dans Amazon S3 sont chiffrées. Tous les rôles sont définis selon le principe du moindre privilège, et toutes les communications entre les services restent dans le compte du client. Les administrateurs peuvent contrôler les données de Jupyter Notebook, d’Amazon Omics Variant Stores et l’accès aux données d’AWS Glue Catalog est entièrement géré à l’aide de Lake Formation, et l’accès aux données d’Athena, de SageMaker Notebook et de QuickSight est géré via les rôles IAM fournis.
AWS Glue, Amazon S3, Amazon Omics et Athena sont tous sans serveur et adapteront les performances d’accès aux données à mesure que votre volume de données augmente. AWS Glue fournit, configure et adapte les ressources nécessaires à l’exécution de vos tâches d’intégration de données. Athena est sans serveur, ce qui vous permet d’interroger rapidement vos données sans avoir à configurer et à gérer des serveurs ou des entrepôts de données. Le stockage en mémoire QuickSight SPICE permettra d’étendre votre exploration des données à des milliers d’utilisateurs.
En utilisant les technologies sans serveur, vous n’allouez exactement que les ressources que vous utilisez. Chaque tâche AWS Glue allouera un cluster Spark à la demande pour transformer les données, et désallouera les ressources une fois la tâche terminée. Si vous choisissez d’ajouter des jeux de données TCGA, vous pouvez ajouter des tâches AWS Glue et des robots AWS Glue qui alloueront également des ressources à la demande. Athena exécute automatiquement les requêtes en parallèle, de sorte que la plupart des résultats sont produits en quelques secondes. Amazon Omics optimise les performances des requêtes de variants à l’échelle en transformant les fichiers en Apache Parquet.
En utilisant des technologies sans serveur qui sont mises à l’échelle à la demande, vous ne payez que les ressources que vous utilisez. Pour optimiser davantage les coûts, vous pouvez arrêter les environnements de bloc-notes dans SageMaker lorsqu’ils ne sont pas utilisés. Le tableau de bord QuickSight est également déployé par le biais d’un modèle CloudFormation distinct. Ainsi, si vous n’avez pas l’intention d’utiliser le tableau de bord de visualisation, vous pouvez ne pas le déployer pour réduire les coûts. Amazon Omics optimise le stockage de données de variants à l’échelle. Les coûts des requêtes sont déterminés par la quantité de données analysées par Athena et peuvent être optimisés en rédigeant des requêtes en conséquence.
En utilisant largement les services gérés et la mise à l’échelle dynamique, vous réduisez l’impact environnemental des services de backend. Un élément essentiel de la durabilité consiste à maximiser l’utilisation des instances de serveur de blocs-notes. Vous devez arrêter les environnements de bloc-notes lorsque vous ne les utilisez pas.
Autres considérations
Transformation des données
Cette architecture utilise AWS Glue pour l’extraction, la transformation et le chargement (ETL) nécessaires à l’ingestion, à la préparation et au catalogage des jeux de données dans la solution pour les requêtes et les performances. Vous pouvez ajouter de nouvelles tâches AWS Glue et de nouveaux robots AWS Glue pour ingérer de nouveaux jeux de données The Cancer Genome Atlas (TCGA) et The Cancer Image Atlas (TCIA), si nécessaire. Vous pouvez également ajouter de nouvelles tâches et de nouveaux crawlers pour ingérer, préparer et cataloguer vos propres jeux de données propriétaires.
Analyse des données
Cette architecture utilise des blocs-notes SageMaker pour fournir un environnement de blocs-notes Jupyter pour l’analyse. Vous pouvez ajouter de nouveaux blocs-notes à l'environnement existant ou créer de nouveaux environnements. Si vous préférez les blocs-notes RStudio au blocs-notes Jupyter, vous pouvez utiliser RStudio on Amazon SageMaker.
Visualisation de données
Cette architecture utilise QuickSight pour fournir des tableaux de bord interactifs pour la visualisation et l’exploration des données. La configuration de tableau de bord QuickSight s’effectue par le biais d’un modèle CloudFormation. Ainsi, si vous ne voulez pas utiliser le tableau de bord vous n’avez pas à le mettre en service. Dans QuickSight, vous pouvez créer votre propre analyse, explorer des filtres ou des visualisations supplémentaires, et partager des jeux de données et des analyses avec vos collègues.
Déployer en toute confiance
Ce référentiel crée un environnement évolutif dans AWS pour préparer les données génomiques, cliniques, de mutation, d’expression et d’imagerie pour exécuter des analyses à grande échelle et effectuer des requêtes interactives sur un lac de données. La solution montre comment 1) utiliser le stockage de variants et le stockage d’annotations Healthomics pour stocker les données de variants et d’annotations génomiques, 2) fournir des pipelines d’ingestion de données sans serveur pour la préparation et le catalogage des données multimodales, 3) visualiser et explorer les données cliniques par le biais d’une interface interactive et 4) exécuter des requêtes analytiques interactives sur un lac de données multimodales à l’aide d’Amazon Athena et d’Amazon SageMaker.
Un guide détaillé d’expérimentation et d’utilisation est fourni dans votre compte AWS. Chaque étape de la construction du guide, y compris le déploiement, l’utilisation et le nettoyage, est examinée pour le préparer au déploiement.
Ouvrez le guide de mise en œuvre
L’exemple de code est un point de départ. Il s’agit d’un document validé par l’industrie, prescriptif mais non définitif, et d’un aperçu pour vous aider à commencer.
Contenu connexe
Guide
Guide pour l’analyse de données multimodales à l’aide des services d’IA et de ML pour la santé sur AWS
Ce guide explique la mise en place d’un cadre de bout en bout pour analyser les données multimodales relatives aux soins de santé et aux sciences de la vie (HCLS).
Contributeurs
Avis de non-responsabilité
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages