Falaise Burns et collines Columbia, cratères Endeavour et Bonneville… Ces noms vous évoquent des paysages lointains ? Vous avez entièrement raison. Il s'agit de quelques-unes des zones géographiques visitées par les robots d'exploration de Mars de la NASA. Au fil des ans, les robots nous transmettent de précieuses données sur la planète rouge, dont de superbes images en haute résolution. Amazon Simple Workflow Service (Amazon SWF) figure désormais dans la panoplie de technologies informatiques déployées dans le cadre de ces missions, en permettant aux scientifiques de la NASA de mener des opérations critiques et de traiter efficacement les montagnes d'informations recueillies sur notre univers.
Robot d'exploration de Mars
Le laboratoire JPL (Jet Propulsion Laboratory) de la NASA intègre Amazon SWF à plusieurs de ses missions, y compris les missions MER (Mars Exploration Rover) et CARVE (Carbon in the Arctic Reservoir Vulnerability Experiment). Ces missions génèrent continuellement d'énormes volumes de données qui doivent être traitées, analysées et stockées de manière efficace et fiable. Les pipelines de traitement de données utilisés pour l'analyse scientifique et les opérations tactiques supposent l'exécution d'étapes dans un ordre bien précis et à grande échelle, avec une réelle opportunité de parallélisation sur plusieurs machines. Citons, comme exemples, la génération de données stéréoscopiques à partir de paires d'images, l'assemblage de panoramas de plusieurs gigapixels pour plonger le scientifique dans le monde martien et le découpage de ces mêmes images pour que les données puissent être chargées à la demande. Ces données sont exploitées par une communauté d'opérateurs et de scientifiques à travers le monde. Pour mener leurs opérations tactiques, ces personnes doivent faire face à des délais serrés, parfois de l'ordre de quelques heures. Pour répondre à ces besoins, les ingénieurs du JPL se sont fixés comme objectif de traiter et de diffuser les images martiennes en quelques minutes seulement.
Le laboratoire JPL stocke et traite des données dans AWS depuis longtemps déjà. La plupart de ces opérations sont effectuées avec l'infrastructure Polyphony, l'implémentation de référence de l'architecture COA (Cloud Oriented Architecture) du JPL. Cette dernière assure la prise en charge du dimensionnement, du stockage, de la surveillance et de l'orchestration des tâches de traitement des données dans le cloud. Aux fins de l'analyse et du traitement des données, le jeu d'outils de Polyphony se composait d'Amazon EC2 pour la capacité de calcul, d'Amazon S3 pour le stockage et la distribution de données, ainsi que d'implémentations Amazon SQS et MapReduce, telles que Hadoop, pour la distribution et l'exécution des tâches. Cependant, il manquait un élément essentiel, à savoir : un service d'orchestration permettant de gérer, de manière fiable, les tâches relatives à de vastes flux de travail complexes.
Bien que les files d'attente constituent une méthode efficace pour distribuer des tâches massivement parallèles, les ingénieurs en ont rapidement découvert les limites. Les files d'attente ne sont pas adaptées aux flux de travail complexes, compte tenu de l'impossibilité d'y exprimer l'ordonnancement et les dépendances. De plus, les ingénieurs du JPL ont dû composer avec la duplication des messages lors de l'utilisation de files d'attente. Par exemple, lors de l'assemblage d'images, une tâche en double se traduit par un coûteux traitement redondant et, partant, un calcul onéreux dans la mesure où le pipeline s'exécute inutilement jusqu'à la fin. Nombre de cas d'utilisation du JPL vont bien au-delà du traitement brut des données et nécessitent des mécanismes pour piloter le flux de commande. Alors que les ingénieurs étaient en mesure de mettre en œuvre aisément leurs flux orientés données avec MapReduce, il leur était difficile d'exprimer chaque étape du pipeline au sein de la sémantique de l'infrastructure. En particulier, à mesure qu'augmentait la complexité du traitement des données, ils étaient confrontés à des difficultés sur le plan de la représentation des dépendances entre les étapes de traitement et lors de la gestion des erreurs de calcul distribué.
Les ingénieurs du JPL ont reconnu la nécessité de disposer d'un service d'orchestration présentant les caractéristiques suivantes :
- Haute disponibilité : Pour la prise en charge des opérations critiques à la mission
- Evolutivité : Pour faciliter l'exécution parallèle et simultanée de centaines d'instances Amazon EC2
- Cohérence : Une tâche planifiée doit être exécutée à une reprise avec une probabilité très élevée
- Expressivité : Une expression simple de flux de travail complexes afin d'accélérer le développement
- Souplesse : L'exécution des flux de travail ne doit pas être limitée à Amazon EC2 et les tâches doivent être routables
- Performances : Les tâches doivent être planifiées avec un temps de latence minimum
Les ingénieurs du JPL ont utilisé Amazon SWF et intégré le service dans les pipelines Polyphony en charge du traitement des images de Mars pour les opérations tactiques. Ils ont ainsi pu acquérir une maîtrise et une visibilité sans précédent de l'exécution distribuée de leurs pipelines. Mieux encore, ils ont eu la possibilité d'exprimer des flux de travail complexes de manière succincte, sans être obligés d'exprimer le problème dans un paradigme spécifique.
En vue du Fast Motion Field Test pour le robot Curiosity, connu également sous le nom de Mars Science Laboratory (MSL), les ingénieurs du JPL ont dû traiter des images, générer de l'imagerie stéréoscopique et effectuer des panoramas. L'imagerie stéréoscopique nécessite l'acquisition simultanée d'une paire d'images. Elle génère des données télémétriques qui indiquent à l'opérateur tactique la direction et la distance entre le robot et les pixels sur les images. Les images gauche et droite peuvent être traitées en parallèle. Cependant, le traitement vidéo ne peut pas démarrer tant que chacune d'elles n'a pas été traitée. Le flux de travail de division/assemblage classique s'avère difficile à exprimer avec un système basé sur des files d'attente. En revanche, pour l'exprimer avec SWF, il suffit de quelques simples lignes de code Java avec des annotations AWS Flow Framework.


La génération de panoramas est également mise en œuvre sous la forme d'un flux de travail. A des fins tactiques, des panoramas sont générés à chaque endroit où le robot stationne et prend des clichés. Ainsi, chaque fois qu'une nouvelle photo d'un site est prise, ces informations enrichissent le panorama. En raison de la vaste étendue des panoramas et de la nécessité de les générer aussi vite que possible, il a fallu diviser le problème et l'orchestrer sur plusieurs machines. L'algorithme employé par les ingénieurs divise le panorama en plusieurs rangées de grande taille. La première tâche du flux de travail consiste à générer chacune des rangées sur la base d'images disponibles sur le site. Dès que les rangées ont été générées, une mise à l'échelle descendante est réalisée selon différentes résolutions et les rangées sont mosaïquées en vue d'être exploitées par les clients distants. Les ingénieurs du JPL ont utilisé le jeu de fonctionnalités étendu fourni par Amazon SWF pour exprimer ce flux d'application sous la forme d'un flux de travail Amazon SWF.
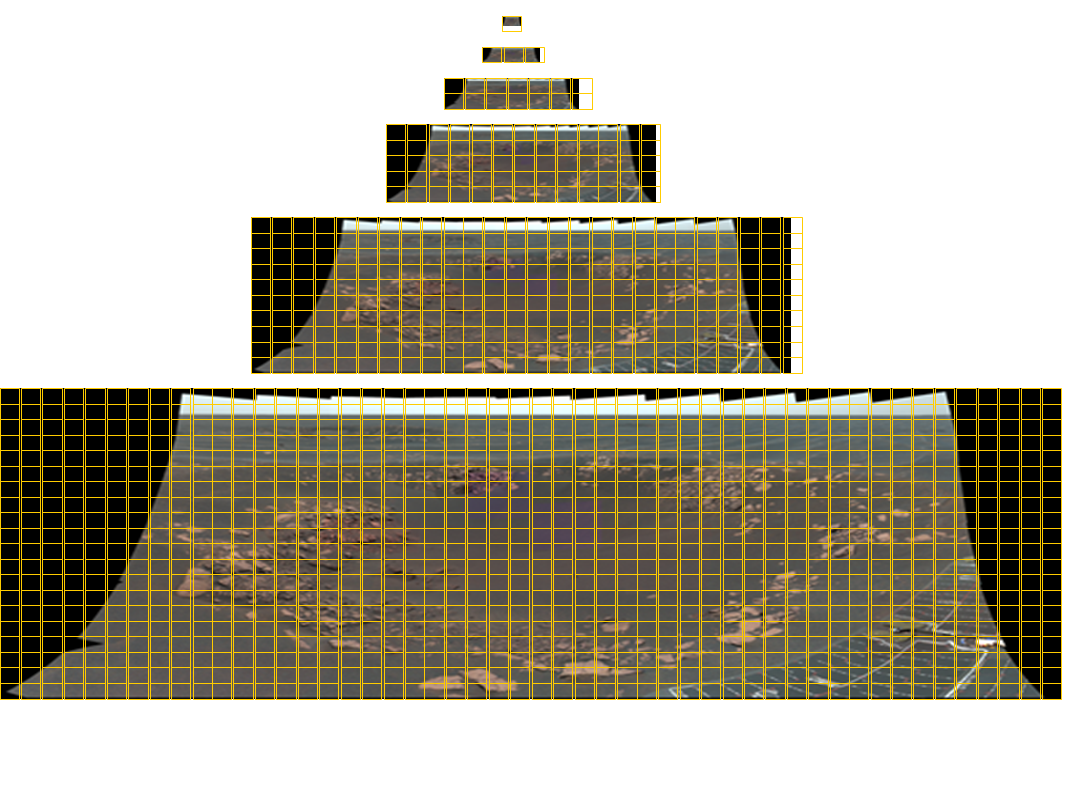
Mosaïque de la caméra panoramique du robot Opportunity, taille totale de 11 280 × 4 280 pixels, composée de 77 images couleur. Pour que cette image puisse être visualisée dans tout format, les mosaïques doivent comporter six niveaux de détails. Les lignes du quadrillage de couleur jaune indiquent les mosaïques requises pour chaque image. Les panoramas obtenus à l'aide des instruments MastCam du MSL sont constitués de 1 296 images et présentent une résolution d'environ 2 gigapixels. L'image panoramique correspondante est illustrée ci-dessous.

En permettant l'orchestration dans le cloud, Amazon SWF donne la possibilité au JPL d'exploiter les ressources situées à l'intérieur et à l'extérieur de son environnement et de répartir en toute transparence l'exécution des applications dans le cloud public, ce qui permet à ses applications d'évoluer de manière dynamique et de s'exécuter dans un environnement réellement distribué.
De nombreux pipelines de traitement de données du JPL sont structurés comme des programmes exécutants automatisés chargés du chargement des données filtrées par le pare-feu, du traitement des données en parallèle et du téléchargement des résultats. Les programmes exécutants en charge du chargement et du téléchargement s'exécutent sur des serveurs locaux, tandis que ceux qui traitent les données peuvent s'exécuter à la fois sur des serveurs locaux et sur les nœuds Amazon EC2. Les développeurs du JPL ont utilisé les fonctionnalités de routage d'Amazon SWF pour incorporer, de manière dynamique, des programmes exécutants dans le pipeline, tout en tirant parti de leurs caractéristiques, telles que la localisation des données. Cette application de traitement se distingue également par une disponibilité élevée. En effet, même en cas de défaillance des programmes exécutants internes, les exécutants dans le cloud prennent le relais. Dans la mesure où Amazon SWF n'impose aucune contrainte quant à la localisation des nœuds d'exécutant, le JPL exécute des tâches dans plusieurs régions, ainsi que dans ses centres de données internes, afin de parvenir à une disponibilité maximale des systèmes critiques. Le JPL compte intégrer le basculement automatique vers SWF dans les différentes régions où Amazon SWF sera disponible.

Les ingénieurs du JPL ne se sont pas limités à utiliser Amazon SWF pour les applications de traitement des données. Ils ont, en effet, exploité ses fonctionnalités de planification pour créer un système de tâches Cron distribuées qui a permis d'exécuter, de manière fiable et opportune, des opérations critiques. Les fonctionnalités de visibilité d'Amazon SWF disponibles dans AWS Management Console leur ont, en outre, permis de bénéficier d'une vue centralisée sur ces tâches distribuées. Les ingénieurs ont même développé une application pour sauvegarder les données vitales du robot sur Amazon S3. Grâce aux tâches Cron distribuées, ils mettent à jour les sauvegardes et contrôlent l'intégrité des données aussi souvent que l'exige le projet. Toutes les étapes de cette application, y compris le chiffrement, le chargement sur S3, la sélection aléatoire des données à contrôler et l'audit proprement dit comparant les données sur site avec S3, sont orchestrées de manière fiable via Amazon SWF. De plus, plusieurs équipes du JPL ont rapidement fait migrer leurs applications existantes afin d'utiliser l'orchestration dans le cloud en tirant parti de la prise en charge de la programmation via AWS Flow Framework.
Le JPL continue à utiliser Hadoop pour les pipelines de traitement de données simples. Toutefois, Amazon SWF apparaît désormais comme incontournable pour la mise en œuvre d'applications présentant des dépendances complexes entre les étapes de traitement. De plus, les développeurs utilisent fréquemment les fonctionnalités de diagnostic et d'analyse disponibles via AWS Management Console pour déboguer les applications au cours du développement et dans le cadre du suivi des exécutions distribuées. Avec AWS, quelques jours suffisent pour développer, tester et déployer des applications essentielles, alors qu'il fallait auparavant plusieurs mois.