Mengotomatiskan deployment yang aman dan tanpa campur tangan
Pengiriman dan Pengoperasian Perangkat Lunak | LEVEL 300
Topik halaman
- Pengantar
- Deployment berkelanjutan dan aman di Amazon
- Perjalanan menuju pengiriman berkelanjutan
- Empat fase pipeline
- Sumber dan build
- Sumber pipeline
- Tinjauan kode
- Bangun dan uji unit
- Deployment uji di lingkungan praproduksi
- Pengujian integrasi
- Kompatibilitas mundur dan pengujian one-box
- Deployment produksi
- Deployment bertahap
- Deployment one-box dan rolling
- Pemantauan metrik dan rollback otomatis
- Waktu menanam
- Mekanisme pemblokiran berdasarkan alarm dan jendela waktu
- Pipeline sebagai kode
- Penutup
- Baca lebih lanjut
Pengantar
Ketika saya menjalani wawancara kerja di Amazon, saya menyempatkan diri untuk bertanya kepada salah satu pewawancara, “Seberapa sering deployment dilakukan pada produksi?” Pada saat itu, saya sedang mengerjakan produk untuk rilis besar sekali atau dua kali setahun, tetapi terkadang saya harus merilis perbaikan kecil di sela rilis besar. Untuk tiap perbaikan yang saya rilis, saya habiskan waktu berjam-jam untuk menggulirkannya dengan hati-hati. Lalu saya dengan panik memeriksa log dan metrik untuk melihat apakah saya telah merusak sesuatu setelah penerapan dan harus mengulang kembali.
Menurut yang saya baca Amazon mempraktikkan penerapan berkelanjutan, jadi ketika saya mewawancarai, saya ingin tahu berapa lama saya perlu untuk mengelola dan memperhatikan penerapan sebagai pengembang di Amazon. Pewawancara mengatakan bahwa perubahan secara otomatis diterapkan pada produksi beberapa kali sehari melalui pipeline penerapan berkelanjutan. Ketika saya bertanya berapa lama dalam sehari dia habiskan untuk dengan cermat mengawasi tiap penerapan dan mengamati log dan metrik untuk mengetahui dampak apa pun seperti yang telah saya lakukan, biasanya tidak ada, katanya. Karena pekerjaan tim dilakukan oleh pipeline, sebagian besar penerapan tidak diawasi secara aktif oleh siapa pun. “Waduh!” Kata saya. Setelah saya bergabung di Amazon, saya sangat antusias untuk mengetahui secara langsung bagaimana deployment otomatis yang “tanpa campur tangan” ini bekerja.
Deployment berkelanjutan dan aman di Amazon
Sejak itu, saya telah melihat langsung cara Amazon menyiapkan pipeline penerapan berkelanjutan untuk membantu kami menerapkan dengan cepat dan aman. Saya tersadar dan menghargai bagaimana praktik keselamatan penerapan berkelanjutan kami membebaskan waktu pengembang dari pekerjaan penerapan. Saat memasukkan kode produksi ke cabang utama repositori kode sumber layanan saya, biasanya saya melupakannya dan melanjutkan ke tugas berikutnya, sementara pipeline tim saya mengambil alih perubahan itu ke produksi. Rilis perubahan kode saya ke layanan produksi sepenuhnya diotomatisasi oleh pipeline, yang berarti bahwa terakhir kali saya atau pengembang lain menyentuh atau meninjau kode itu adalah saat kode itu dilebur ke repositori kode sumber.
Tim saya menyiapkan pipeline ini dengan langkah otomatis yang menerapkan perubahan Anda dengan aman ke produksi, jadi kami tidak perlu mengawasi setiap penerapan. Pipeline menjalankan perubahan terbaru melalui serangkaian pengujian dan pemeriksaan keamanan penerapan. Urutan langkah otomatis ini mencegah cacat yang berdampak pada pelanggan mencapai produksi dan membatasi dampak pada pelanggan jika cacat itu mencapai produksi. Sebagai developer, saya yakin pipeline akan melakukan deployment perubahan ke produksi dengan hati-hati dan aman, tanpa perlu diawasi secara aktif.
Empat fase pipeline
Di artikel ini, kami memandu rangkaian langkah yang dilalui perubahan kode pada suatu pipeline di Amazon menuju proses produksi. Pipeline pengiriman berkelanjutan umumnya memiliki empat fase utama—sumber, bangun, uji, dan produksi (prod). Kami akan membahas secara lebih detail apa saja yang terjadi di tiap fase pipeline ini pada layanan AWS umum, dan memberi contoh bagaimana tim layanan AWS umum dapat menyiapkan salah satu pipeline.
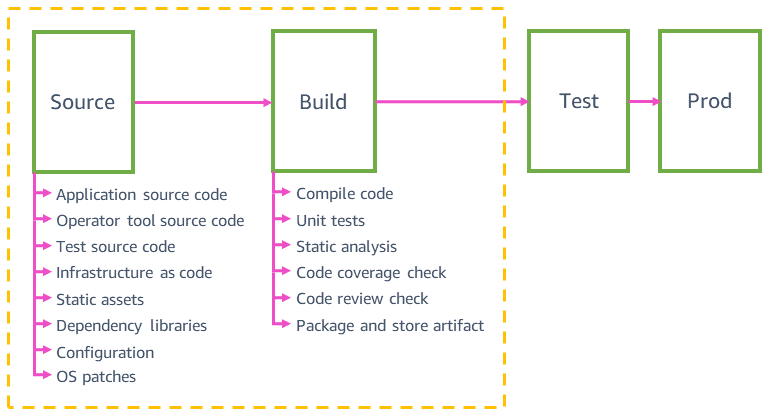
Sumber dan build
Diagram berikut memberi gambaran umum tentang tahapan sumber dan build yang umum ditemukan di pipeline tim layanan AWS.
Sumber pipeline
Pipeline di Amazon secara otomatis memvalidasi dan dengan aman menerapkan semua jenis perubahan sumber ke produksi, tidak hanya perubahan pada kode aplikasi. Pipeline bisa memvalidasi dan menerapkan perubahan ke sumber seperti aset statis situs web, alat, pengujian, infrastruktur, konfigurasi, dan sistem operasi (OS) yang mendasari aplikasi. Semua perubahan ini terkontrol versi di repositori kode masing-masing sumber. Dependensi kode sumber, seperti pustaka, bahasa pemrograman, dan parameter seperti ID AMI, secara otomatis ditingkatkan ke versi terbaru setidaknya setiap minggu.
Sumber ini diterapkan di masing-masing pipeline dengan mekanisme keamanan yang sama (seperti pembatalan otomatis) yang kami gunakan untuk menerapkan kode aplikasi. Misalnya, nilai konfigurasi untuk layanan yang dapat berubah pada waktu proses (seperti kenaikan batas kecepatan API dan tanda fitur) secara otomatis diterapkan pada pipeline konfigurasi khusus. Perubahan sumber akan otomatis dibatalkan jika menyebabkan masalah apa pun dalam produksi bagi layanan (seperti kegagalan mengurai file konfigurasi).
Layanan mikro mungkin umumnya memiliki pipeline kode aplikasi, pipeline infrastruktur, pipeline patching OS, pipeline tanda konfigurasi/fitur, dan pipeline alat operator. Memiliki beberapa pipeline untuk layanan mikro yang sama membantu kami lebih cepat menerapkan perubahan ke produksi. Perubahan kode aplikasi yang gagal dalam pengujian integrasi dan memblokir pipeline aplikasi tidak memengaruhi pipeline lain. Misalnya, tidak memblokir perubahan kode infrastruktur dari mencapai produksi di pipeline infrastruktur. Semua saluran pipa untuk layanan mikro yang sama cenderung terlihat sangat mirip. Misalnya, pipeline tanda fitur menggunakan teknik deployment aman yang sama seperti pipeline kode aplikasi, sebab perubahan konfigurasi tanda fitur yang bermasalah dapat berdampak pada produksi seperti halnya perubahan kode aplikasi yang gagal.
Tinjauan kode
Semua perubahan yang terjadi pada produksi dimulai dengan peninjauan kode dan harus disetujui anggota tim sebelum bergabung dengan cabang jalur utama (versi “utama” atau “pokok” kami), yang secara otomatis memulai jalur pipa. Pipeline memberlakukan persyaratan bahwa semua komit di cabang jalur utama harus melalui tinjauan kode dan harus disetujui anggota tim layanan untuk pipeline tersebut. Pipeline akan memblokir penerapan setiap komit yang belum ditinjau.
Dengan pipeline sepenuhnya otomatis, tinjauan kode adalah tinjauan dan persetujuan manual terakhir yang diterima perubahan kode dari teknisi sebelum diterapkan ke produksi, jadi ini merupakan langkah penting. Peninjau kode mengevaluasi kebenaran kode dan juga mengevaluasi apakah perubahan tersebut dapat diterapkan dengan aman pada produksi. Peninjau mengevaluasi apakah kode memiliki pengujian yang memadai (pengujian unit, pengujian integrasi, dan pengujian kenari), apakah dilengkapi dengan instrumen yang memadai untuk pemantauan penerapan, dan apakah bisa dibatalkan dengan aman. Beberapa tim menggunakan daftar periksa khusus seperti yang ada di contoh berikut, yang secara otomatis ditambahkan ke tiap tinjauan kode tim untuk secara eksplisit memeriksa masalah keamanan penerapan.
Contoh daftar periksa tinjauan kode
## Pengujian
[ ] Apakah Anda menulis pengujian unit baru untuk perubahan ini?
[ ] Apakah Anda menulis pengujian integrasi baru untuk perubahan ini?
Sertakan perintah pengujian yang Anda jalankan secara lokal untuk menguji perubahan ini:
```
mvn test && mvn verify
```
## Pemantauan
[ ] Apakah perubahan ini akan dicakup oleh pemantauan kami yang ada?
(tidak diperlukan canary/metrik/dasbor/alarm baru)
[ ] Apakah perubahan ini tidak berdampak (atau positif) pada sumber daya dan/atau batasan?
(termasuk CPU, memori, sumber daya AWS, panggilan ke layanan lain)
[ ] Apakah perubahan ini bisa di-deploy ke lingkungan Produksi tanpa memicu alarm?
## Peluncuran
[ ] Apakah perubahan ini bisa segera digabungkan ke dalam pipeline setelah disetujui?
[ ] Apakah semua perubahan dependen sudah di-deploy ke lingkungan Produksi?
[ ] Apakah perubahan ini bisa di-rollback tanpa masalah setelah deployment ke lingkungan Produksi?
Bangun dan uji unit
Pada tahap bangun, kode dikompilasi dan unit diuji. Alat bangun dan logika bangun dapat bervariasi dari bahasa ke bahasa dan bahkan dari tim ke tim. Misalnya, tim dapat memilih kerangka kerja uji unit, linter, dan alat analisis statis yang paling cocok. Selain itu, tim dapat memilih konfigurasi alat, seperti cakupan kode minimum yang dapat diterima dalam kerangka kerja uji unitnya. Alat dan jenis uji yang dijalankan juga akan bervariasi tergantung jenis kode yang diterapkan oleh pipeline. Misalnya, uji unit digunakan untuk kode aplikasi dan linter digunakan untuk infrastruktur sebagai templat kode. Semua bangun berjalan tanpa akses jaringan untuk mengisolasi bangun dan mendorong reproduktifitas bangun. Biasanya, uji unit meniru (mensimulasi) semua panggilan API pada dependensi, seperti layanan AWS lainnya. Interaksi dengan dependensi non-tiruan “langsung” nantinya akan diuji di pipeline dalam uji integrasi. Dibandingkan dengan uji integrasi, uji unit dengan dependensi tiruan dapat melakukan kasus edge seperti galat tak terduga yang dikembalikan dari panggilan API dan memastikan penanganan galat yang baik dalam kode. Saat pembangunan selesai, kode yang dikompilasi akan dikemas dan ditandatangani.
Deployment uji di lingkungan praproduksi
Sebelum penerapan pada produksi, pipeline menerapkan dan memvalidasi perubahan di beberapa lingkungan pra-produksi, misalnya, alfa, beta, dan gamma. Alfa dan beta memvalidasi bahwa kode terbaru berfungsi sesuai yang diharapkan dengan menjalankan uji API fungsional dan uji integrasi ujung ke ujung. Gamma memvalidasi bahwa kode berfungsi dan dapat diterapkan dengan aman pada produksi. Gamma semirip mungkin dengan produksi, termasuk konfigurasi penerapan yang sama, pemantauan dan alarm yang sama, dan uji kenari berkelanjutan yang sama dengan produksi. Gamma juga diterapkan di beberapa AWS Region untuk menangkap potensi dampak dari perbedaan wilayah.
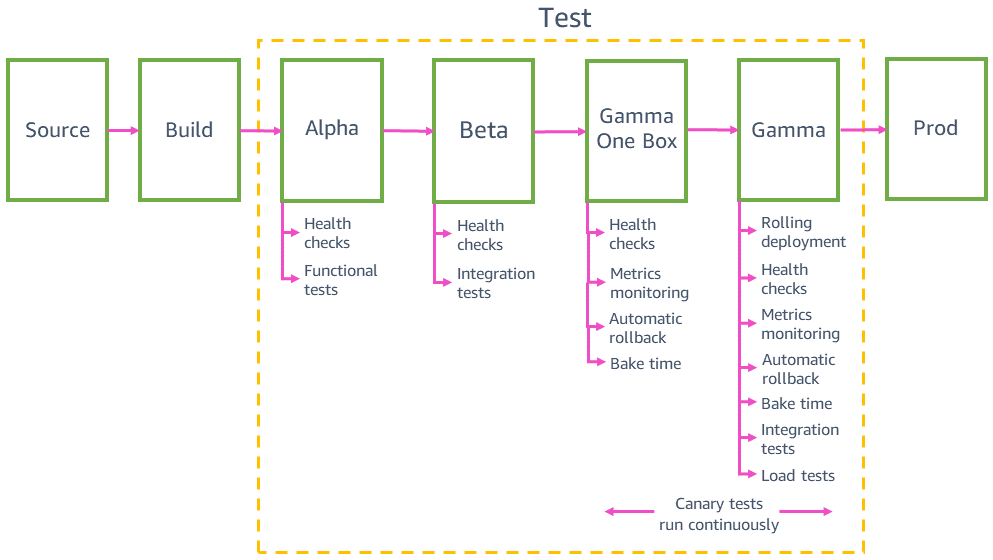
Pengujian integrasi
Uji integrasi membantu kami menggunakan layanan secara otomatis seperti halnya pelanggan sebagai bagian dari pipeline. Uji ini melatih tumpukan penuh ujung ke ujung dengan memanggil API nyata yang berjalan di infrastruktur nyata di setiap tahap praproduksi untuk semua skenario pelanggan yang bermanfaat. Tujuan uji integrasi adalah untuk menangkap perilaku layanan yang tidak terduga atau tidak benar sebelum menerapkan pada produksi.
Jika uji unit dijalankan terhadap dependensi palsu, uji integrasi dijalankan pada sistem pra-produksi yang memanggil dependensi nyata, memvalidasi asumsi tiruan tentang bagaimana dependensi tersebut berperilaku. Uji integrasi memvalidasi perilaku API individu di berbagai input. Selain itu, semua uji itu memvalidasi alur kerja penuh yang menggabungkan beberapa API seperti membuat sumber daya baru, mendeskripsikan sumber daya baru hingga siap, dan kemudian menggunakan sumber daya.
Uji integrasi menjalankan kasus uji positif dan negatif, seperti memberikan masukan tidak valid ke API dan memeriksa bahwa galat “masukan tidak valid” ditanggapi seperti yang diharapkan. Beberapa pipeline menjalankan uji fuzz untuk menghasilkan banyak kemungkinan input API dan memvalidasi bahwa pipeline tidak menyebabkan kegagalan internal apa pun pada layanan. Beberapa pipeline juga menjalankan uji beban singkat dalam tahap praproduksi untuk memastikan bahwa perubahan terbaru tidak menyebabkan latensi atau regresi throughput pada tingkat beban nyata.
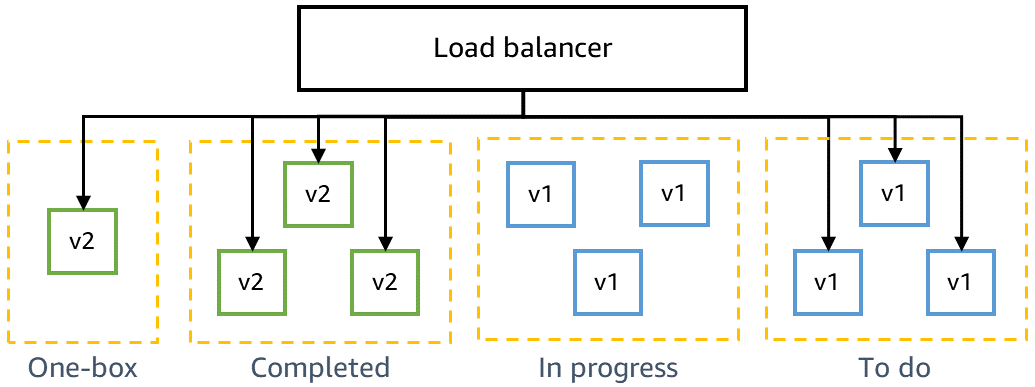
Kompatibilitas mundur dan pengujian one-box
Sebelum menerapkan pada produksi, kami perlu memastikan bahwa kode terbaru kompatibel dengan versi sebelumnya dan bisa diterapkan dengan aman bersama kode saat ini. Misalnya, kita perlu mendeteksi apakah kode terbaru menulis data dalam format yang tidak dapat diurai oleh kode saat ini. Tahap satu kotak dalam gamma menerapkan kode terbaru pada unit penerapan terkecil, seperti pada mesin virtual tunggal atau kontainer tunggal, atau pada sebagian kecil pemanggilan fungsi AWS Lambda. Penerapan satu kotak ini membuat lingkungan gamma lainnya diterapkan dengan kode saat ini selama beberapa lama, seperti 30 menit atau satu jam. Lalu lintas tidak harus diarahkan secara khusus ke satu kotak. Ini dapat ditambahkan ke penyeimbang beban yang sama atau mengumpulkan antrean yang sama seperti lingkungan gamma lainnya. Misalnya, dalam lingkungan gamma yang terdiri dari sepuluh kontainer di belakang penyeimbang beban, satu kotak menerima sepuluh persen lalu lintas gamma yang dihasilkan oleh uji kenari berkelanjutan. Penerapan satu kotak memantau tingkat keberhasilan uji kenari dan metrik layanan untuk mendeteksi dampak apa pun dari penerapan atau dari memiliki armada “campuran” yang diterapkan berdampingan.
Diagram berikut menunjukkan status lingkungan gamma setelah kode baru di-deploy pada tahap one-box, tetapi belum di-deploy ke seluruh armada gamma:
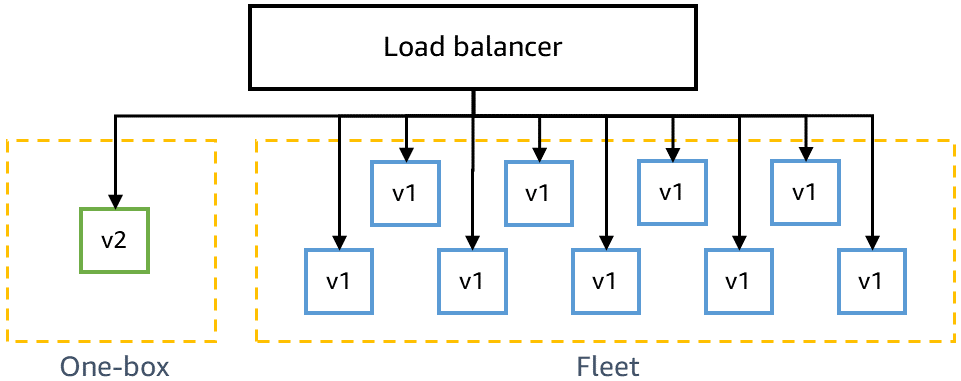
Kita juga perlu memastikan bahwa kode terbaru kompatibel dengan dependensi kita sebelumnya, misalnya jika perubahan perlu dilakukan di seluruh layanan mikro dengan urutan tertentu. Layanan mikro di lingkungan pra-produksi umumnya memanggil titik akhir produksi dari setiap layanan yang dimiliki tim lain, seperti Amazon Simple Storage Service (S3) atau Amazon DynamoDB, tetapi layanan mikro memanggil titik akhir pra-produksi dari layanan mikro tim layanan lain pada tahap yang sama. Misalnya, layanan mikro tim A dalam gamma memanggil layanan mikro tim yang sama B dalam gamma, tetapi memanggil titik akhir produksi untuk Amazon S3.
Beberapa pipeline juga menjalankan uji integrasi lagi dalam tahap kompatibilitas surut terpisah yang kami sebut zeta, yang merupakan lingkungan terpisah di mana setiap layanan mikro hanya memanggil titik akhir produksi, menguji apakah perubahan yang menuju produksi kompatibel dengan kode yang saat ini diterapkan dalam produksi di beberapa layanan mikro. Misalnya, layanan mikro A di zeta memanggil titik akhir produksi layanan mikro B dan titik akhir produksi untuk Amazon S3.
Untuk penjelasan tentang strategi menulis dan melakukan deployment perubahan yang kompatibel dengan versi sebelumnya, lihat artikel Builders’ Library Ensuring rollback safety during deployments.
Deployment produksi
Tujuan #1 kami untuk penerapan produksi di AWS adalah mencegah dampak negatif di beberapa Wilayah secara bersamaan dan di beberapa Availability Zone di Wilayah yang sama. Membatasi ruang lingkup setiap penerapan individual membatasi potensi dampak pada pelanggan dari penerapan produksi gagal dan mencegah dampak multi-Availability-Zone atau multi-Wilayah. Untuk membatasi cakupan penerapan otomatis, kami membagi fase produksi pipeline menjadi banyak tahapan dan banyak penerapan ke masing-masing Wilayah. Tim membagi deployment regional menjadi beberapa deployment dengan cakupan lebih kecil dengan melakukan deployment ke masing-masing Zona Ketersediaan atau ke serpihan (shard) internal layanan (disebut sel) di pipeline mereka, untuk lebih membatasi dampak potensial dari kegagalan deployment produksi.
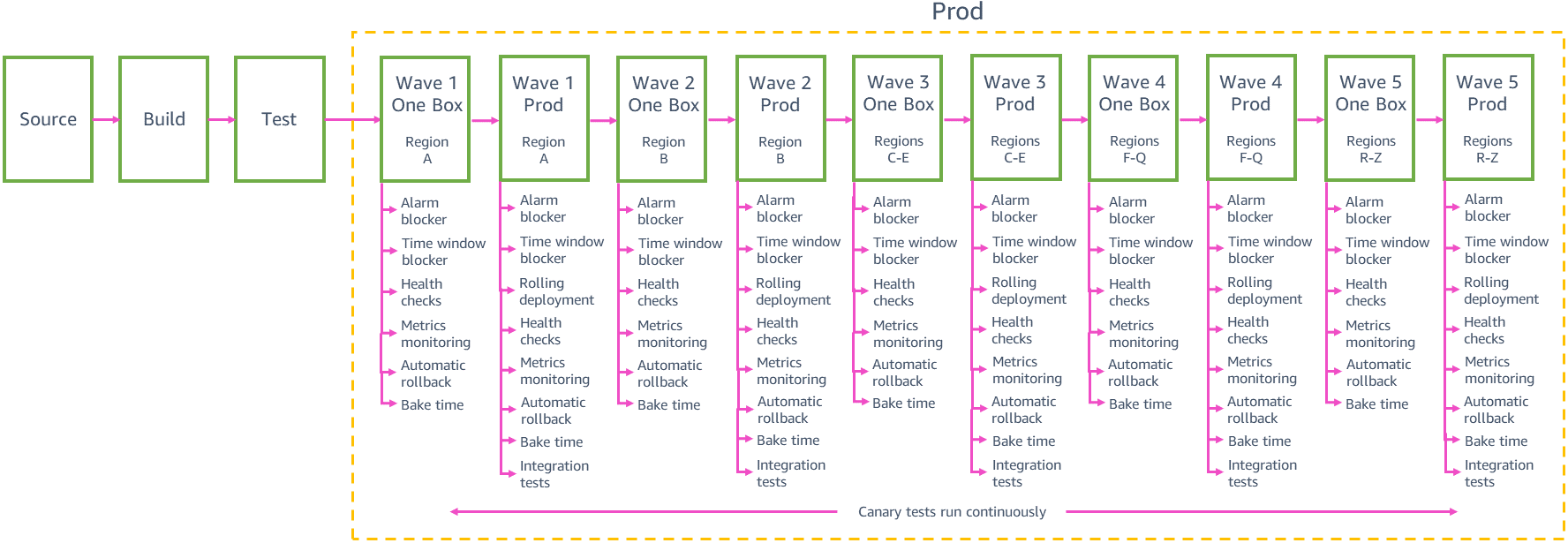
Deployment bertahap
Setiap tim perlu menyeimbangkan keamanan penerapan berskala kecil dengan kecepatan di mana kami dapat mewujudkan perubahan bagi pelanggan di semua Wilayah. Menerapkan perubahan di 24 Wilayah atau 76 Availability Zone melalui pipeline satu per satu memiliki risiko terendah menimbulkan dampak luas, tetapi pipeline akan perlu waktu berminggu-minggu mewujudkan perubahan bagi pelanggan secara global. Kami telah menemukan bahwa mengelompokkan penerapan per “gelombang” dengan ukuran yang semakin besar, seperti yang terlihat pada pipa produk sampel sebelumnya, membantu kami mencapai keseimbangan yang baik antara risiko dan kecepatan penerapan. Setiap tahapan gelombang di jalur pipa mengatur penerapan di sekelompok Wilayah, dengan perubahan didorong dari gelombang ke gelombang. Perubahan baru dapat memasuki fase produksi pipa sewaktu-waktu. Setelah serangkaian perubahan didorong dari langkah pertama ke langkah kedua pada gelombang 1, susunan perubahan berikutnya dari gamma didorong ke langkah pertama gelombang 1, jadi pada akhirnya tidak ada kumpulan besar perubahan yang menunggu digunakan untuk produksi.
Dua gelombang pertama dalam pipeline membangun kepercayaan paling besar pada perubahan: Gelombang pertama diterapkan pada Wilayah dengan jumlah permintaan rendah untuk membatasi kemungkinan dampak penerapan produksi pertama perubahan baru. Gelombang hanya diterapkan pada satu Availability Zone (atau sel) pada satu waktu di Wilayah itu untuk menerapkan perubahan dengan hati-hati di seluruh Wilayah. Gelombang kedua kemudian diterapkan ke satu Availability Zone (atau sel) pada satu waktu di suatu Wilayah dengan jumlah permintaan tinggi di mana kemungkinan besar pelanggan akan menggunakan semua jalur kode baru dan di mana kami memperoleh validasi yang baik atas perubahan itu.
Setelah kami memiliki keyakinan lebih tinggi akan keamanan perubahan dari penerapan gelombang pipa perdana, kami bisa menerapkan ke lebih banyak Wilayah secara paralel dalam gelombang yang sama. Misalnya, pipa prod sampel sebelumnya diterapkan ke tiga Wilayah pada gelombang 3, lalu ke 12 Wilayah pada gelombang 4, lalu ke Wilayah selebihnya pada gelombang 5. Jumlah pasti dan pilihan Wilayah di masing-masing gelombang ini dan jumlah gelombang dalam saluran tim layanan bergantung pada masing-masing pola dan skala penggunaan layanan. Gelombang berikutnya pada pipa masih membantu kami mencapai tujuan kami mencegah dampak negatif terhadap beberapa Availability Zone di Wilayah yang sama. Saat diterapkan di beberapa Wilayah secara paralel, gelombang mengikuti perilaku peluncuran yang sama secara hati-hati untuk setiap Wilayah yang digunakan pada gelombang awal. Setiap tahap pada gelombang hanya di-deploy ke satu Zona Ketersediaan atau sel dari setiap Region pada gelombang tersebut.
Deployment one-box dan rolling
Penerapan pada setiap gelombang produksi dimulai dengan tahap satu kotak. Seperti pada tahapan satu kotak gamma, setiap tahapan satu kotak produksi menerapkan kode terbaru pada satu kotak (mesin virtual tunggal, kontainer tunggal, atau persentase kecil pemanggilan fungsi Lambda) di setiap Wilayah atau Availability Zone gelombang. Penerapan satu kotak prod meminimalkan potensi dampak perubahan pada gelombang dengan pada mulanya membatasi permintaan yang dilayani oleh kode baru pada gelombang itu. Biasanya, satu kotak melayani paling banyak sepuluh persen dari keseluruhan permintaan untuk Wilayah atau Availability Zone. Jika perubahan menyebabkan dampak negatif di satu kotak, pipeline secara otomatis membatalkan perubahan dan tidak mendorongnya ke tahap produksi selanjutnya.
Setelah tahap satu kotak, sebagian besar tim menggunakan penerapan bergulir untuk diterapkan ke armada produksi utama gelombang. Penerapan bergulir memastikan bahwa layanan memiliki cukup kapasitas untuk melayani beban produksi selama penerapan. Ini mengontrol tingkat di mana kode baru difungsikan (yaitu, saat mulai melayani lalu lintas produksi) untuk membatasi dampak perubahan. Dalam penerapan bergulir yang khas di suatu Wilayah, paling banyak 33 persen kotak layanan di Wilayah tersebut (kontainer, permintaan Lambda, atau perangkat lunak yang berjalan pada mesin virtual) diganti dengan kode baru.
Selama penerapan, sistem penerapan pertama-tama memilih batch awal hingga 33 persen kotak untuk diganti dengan kode baru. Selama penggantian, setidaknya 66 persen dari keseluruhan kapasitas sehat dan mampu melayani permintaan. Semua layanan ditingkatkan untuk menahan hilangnya Availability Zone di Wilayah, jadi kami tahu bahwa layanan masih dapat melayani beban produksi pada kapasitas ini. Setelah sistem penerapan menentukan bahwa kotak dalam batch kotak awal lolos cek kesehatan, kotak dari armada selebihnya dapat diganti dengan kode baru, dan seterusnya. Sementara itu, kami masih memiliki minimal 66 persen kapasitas untuk melayani permintaan setiap saat. Untuk lebih membatasi dampak perubahan, beberapa pipeline tim menerapkan sedikitnya lima persen dari kotak yang ada bergantian. Namun, kemudian mereka melakukan pembatalan cepat, di mana sistem mengganti 33 persen kotak sekaligus dengan kode sebelumnya untuk mempercepat pembatalan.
Diagram berikut menunjukkan status lingkungan produksi di tengah penerapan bergulir. Kode baru telah diterapkan ke tahap satu kotak dan ke batch pertama armada produksi utama. Batch lain telah dihapus dari penyeimbang beban dan sedang ditutup untuk penggantian.
Pemantauan metrik dan rollback otomatis
Penerapan otomatis dalam pipeline biasanya tidak memiliki pengembang yang aktif mengawasi setiap penerapan untuk mendorong, memeriksa metrik, dan secara manual melakukan pembatalan jika ada masalah. Penerapan ini benar-benar leluasa. Sistem penerapan secara aktif memantau alarm untuk menentukan apakah alarm perlu membatalkan penerapan secara otomatis. Pembatalan akan mengalihkan lingkungan kembali ke gambar kontainer, paket penerapan fungsi AWS Lambda, atau paket penerapan internal yang sebelumnya diterapkan. Paket penerapan internal kami mirip dengan gambar kontainer, karena paket tersebut tidak dapat diubah dan menggunakan checksum untuk memverifikasi integritasnya.
Setiap layanan mikro di setiap Wilayah umumnya memiliki alarm dengan tingkat keseriusan tinggi yang terpicu pada ambang batas untuk metrik yang memengaruhi pelanggan layanan (seperti tingkat kesalahan dan latensi tinggi) dan pada metrik kesehatan sistem (seperti pemakaian CPU), seperti diilustrasikan dalam contoh berikut. Alarm keparahan tinggi ini digunakan untuk memanggil teknisi panggilan dan secara otomatis membatalkan layanan jika penerapan sedang berlangsung. Seringkali, pembatalan sudah berlangsung pada saat teknisi panggilan telah dihubungi dan mulai bekerja.
Contoh alarm layanan mikro dengan tingkat keparahan tinggi
ALARM("FrontEndApiService_High_Fault_Rate") OR
ALARM("FrontEndApiService_High_P50_Latency") OR
ALARM("FrontEndApiService_High_P90_Latency") OR
ALARM("FrontEndApiService_High_P99_Latency") OR
ALARM("FrontEndApiService_High_Cpu_Usage") OR
ALARM("FrontEndApiService_High_Memory_Usage") OR
ALARM("FrontEndApiService_High_Disk_Usage") OR
ALARM("FrontEndApiService_High_Errors_In_Logs") OR
ALARM("FrontEndApiService_High_Failing_Health_Checks")
Perubahan yang dipicu deployment dapat berdampak pada layanan mikro hulu dan hilir sehingga sistem deployment harus memantau alarm keparahan tinggi untuk layanan mikro yang sedang dalam deployment dan memantau alarm keparahan tinggi untuk layanan mikro tim lain guna menentukan kapan harus melakukan rollback. Perubahan yang diterapkan juga dapat memengaruhi metrik uji kenari berkelanjutan, sehingga sistem penerapan harus memantau uji kenari yang gagal. Untuk secara otomatis membatalkan semua kemungkinan area dampak ini, tim membuat alarm agregat keparahan tinggi untuk dipantau oleh sistem penerapan. Alarm agregat keparahan tinggi mengembalikan status semua alarm layanan mikro individu tim keparahan tinggi dan status alarm kenari menjadi keadaan agregat tunggal, seperti dalam contoh berikut. Jika salah satu alarm keparahan tinggi untuk layanan mikro tim memasuki status alarm, semua penerapan berkelanjutan tim di semua layanan mikro mereka di Wilayah itu secara otomatis dibatalkan.
Contoh alarm rollback agregat tingkat keparahan tinggi
ALARM("FrontEndApiService_High_Severity") OR
ALARM("BackendApiService_High_Severity") OR
ALARM("BackendWorkflows_High_Severity") OR
ALARM("Canaries_High_Severity")
Tahap one-box melayani sebagian kecil dari keseluruhan lalu lintas sehingga masalah yang ditimbulkan oleh deployment pada tahap ini mungkin tidak memicu alarm rollback dengan tingkat keparahan tinggi pada layanan. Untuk menangkap dan membatalkan perubahan penyebab masalah dalam tahapan satu kotak sebelum mencapai tahapan produksi lainnya, tahapan satu kotak juga mengembalikan metrik yang dicakup hanya ke satu kotak. Misalnya, mereka membatalkan tingkat kesalahan permintaan yang dilayani khusus oleh satu kotak, yang merupakan persentase kecil dari keseluruhan jumlah permintaan.
Contoh alarm rollback tahap one-box
ALARM("High_Severity_Aggregate_Rollback_Alarm") OR
ALARM("FrontEndApiService_OneBox_High_Fault_Rate") OR
ALARM("FrontEndApiService_OneBox_High_P50_Latency") OR
ALARM("FrontEndApiService_OneBox_High_P90_Latency") OR
ALARM("FrontEndApiService_OneBox_High_P99_Latency") OR
ALARM("FrontEndApiService_OneBox_High_Cpu_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Memory_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Disk_Usage") OR
ALARM("FrontEndApiService_OneBox_High_Errors_In_Logs") OR
ALARM("FrontEndApiService_OneBox_Failing_Health_Checks")
Selain memicu rollback alarm yang ditentukan tim layanan, sistem deployment kami juga dapat mendeteksi dan secara otomatis melakukan rollback anomali pada metrik umum yang dikeluarkan kerangka layanan web internal kami. Sebagian besar layanan mikro kami mengeluarkan metrik seperti jumlah permintaan, latensi permintaan, dan jumlah kesalahan dalam format standar. Dengan menggunakan metrik standar ini, sistem penerapan dapat melakukan pembatalan otomatis jika ada anomali dalam metrik selama penerapan. Contohnya adalah jika jumlah permintaan tiba-tiba turun menjadi nol, atau jika latensi atau jumlah kesalahan menjadi jauh lebih tinggi dari biasanya.
Waktu menanam
Terkadang dampak negatif yang disebabkan oleh deployment tidak langsung terlihat. Berlangsung lambat, tetapi stabil. Artinya, tidak langsung muncul selama deployment, terutama jika saat itu layanan sedang dalam beban rendah. Mendorong perubahan ke tahap pipeline berikutnya segera setelah penerapan selesai dapat mengakibatkan dampak di banyak Wilayah pada saat dampak muncul di Wilayah pertama. Sebelum mendorong perubahan ke tahap produksi berikutnya, setiap tahap produksi di pipeline memiliki waktu pematangan, yaitu saat pipeline terus memantau alarm agregat keparahan tinggi tim untuk setiap dampak pembakaran lamban setelah penerapan selesai dan sebelum berlanjut ke tahap berikutnya.
Untuk menghitung jumlah waktu yang diperlukan untuk mematangkan penerapan, kami perlu menyeimbangkan risiko yang menyebabkan dampak lebih luas jika kami mendorong perubahan ke beberapa Wilayah terlalu cepat terhadap kecepatan kami dapat mengirimkan perubahan ke pelanggan secara global. Kami mendapati bahwa cara yang baik untuk menyeimbangkan risiko ini adalah agar gelombang sebelumnya pada pipa memiliki waktu pematangan lebih lama sambil kami membangun kepercayaan akan keamanan perubahan, lalu gelombang berikutnya punya waktu pematangan lebih singkat. Tujuan kami adalah meminimalkan risiko dampak yang memengaruhi banyak Wilayah. Karena sebagian besar penerapan tidak dipantau aktif oleh anggota tim, waktu pematangan default pipeline biasanya konservatif dan akan menerapkan perubahan ke semua Wilayah dalam waktu sekitar empat atau lima hari kerja. Layanan yang lebih besar atau sangat vital memiliki waktu pematangan yang lebih konservatif dan waktu agar pipeline-nya menerapkan perubahan secara global.
Pipeline biasanya menunggu setidaknya satu jam setelah setiap tahapan satu kotak, setidaknya 12 jam setelah gelombang wilayah pertama, dan setidaknya dua hingga empat jam setelah setiap gelombang wilayah lainnya, dengan tambahan waktu pematangan untuk masing-masing Wilayah, Availability Zone, dan sel pada setiap gelombang. Waktu pematangan mencakup persyaratan untuk menunggu sejumlah poin data tertentu dalam metrik tim (misalnya, “tunggu setidaknya 100 permintaan ke Buat API”) untuk memastikan bahwa cukup banyak permintaan telah terjadi untuk memungkinkan kode baru dijalankan sepenuhnya. Selama waktu pematangan, penerapan otomatis dibatalkan jika alarm agregat keparahan tinggi tim masuk ke status alarm.
Meski sangat jarang, dalam beberapa kasus, perubahan mendesak (seperti perbaikan keamanan atau mitigasi atas peristiwa skala besar yang memengaruhi ketersediaan layanan) mungkin harus dikirimkan ke pelanggan lebih cepat dari waktu yang biasanya diperlukan oleh pipeline untuk mematangan perubahan dan menerapkan. Dalam hal ini, kami bisa mengurangi waktu pematangan pipeline untuk mempercepat penerapan, tetapi kami perlu pengawasan tingkat tinggi atas perubahan itu untuk melakukannya. Untuk kasus ini, kami memerlukan pengawasan dari Pakar Teknik Utama organisasi. Tim harus meninjau perubahan kode, serta urgensi dan risiko dampaknya, dengan pengembang yang sangat berpengalaman yang ahli di bidang keselamatan operasional. Perubahan ini tetap melalui langkah yang sama dalam pipeline seperti biasa, tetapi didorong ke tahap berikutnya dengan lebih cepat. Kami mengelola risiko deployment yang lebih cepat dengan membatasi perubahan yang diproses di pipeline selama periode ini hanya pada perubahan kode paling minimal yang diperlukan untuk mengatasi masalah saat ini, serta dengan memantau deployment secara aktif.
Mekanisme pemblokiran berdasarkan alarm dan jendela waktu
Pipeline mencegah penerapan otomatis pada produksi saat ada risiko lebih tinggi yang menyebabkan dampak negatif. Pipeline menggunakan susunan “pemblokir” yang mengevaluasi risiko penerapan. Misalnya, otomatis menerapkan perubahan baru pada prod ketika masalah yang saat ini sedang terjadi di lingkungan dapat memperburuk atau memperpanjang dampaknya. Sebelum memulai penerapan baru ke tahap pro apa pun, pipeline akan memeriksa alarm agregat keparahan tinggi tim untuk menentukan apakah ada masalah aktif. Jika alarm saat ini dalam status alarm, pipeline mencegah perubahan bergerak maju. Pipeline juga dapat memeriksa alarm di seluruh organisasi, seperti alarm acara skala besar yang menunjukkan apakah ada dampak luas dalam sistem tim lain, dan mencegah memulai penerapan baru yang dapat menambah dampak keseluruhan. Pemblokir penerapan ini dapat diganti oleh pengembang bila suatu perubahan perlu diterapkan untuk mendorong pemulihan dari masalah keparahan tinggi.
Pipeline juga dikonfigurasi dengan sekumpulan jendela waktu yang menentukan kapan penerapan boleh dimulai. Saat mengonfigurasi jendela waktu, kami harus menyeimbangkan dua penyebab risiko penerapan. Di satu sisi, jendela waktu yang sangat kecil dapat menyebabkan perubahan menumpuk di pipeline selagi jendela waktu ditutup, meningkatkan kemungkinan bahwa salah satu perubahan tersebut pada penerapan berikutnya akan berdampak saat jendela waktu terbuka. Di sisi lain, sangat lamanya jangka waktu yang melampaui jam kerja biasa meningkatkan risiko memperpanjang dampak dari penerapan yang gagal. Selama jam nonaktif, perlu waktu lebih lama untuk melibatkan teknisi panggilan dibanding pada siang hari, ketika teknisi panggilan dan anggota tim lain sedang bekerja. Selama jam kerja reguler, tim dapat lebih cepat dilibatkan setelah penerapan gagal jika langkah-langkah pemulihan manual diperlukan.
Sebagian besar penerapan tidak dipantau aktif oleh anggota tim, jadi kami mengoptimalkan waktu penerapan untuk meminimalkan waktu yang dibutuhkan untuk melibatkan teknisi panggilan, jika ada tindakan manual yang diperlukan untuk pemulihan setelah pembatalan otomatis. Pelibatan teknisi panggilan biasanya perlu waktu lebih lama di malam hari, pada hari libur kantor, dan di akhir pekan, jadi waktu ini dikecualikan dari jendela waktu. Tergantung pola penggunaan layanan, beberapa masalah mungkin tidak muncul selama berjam-jam setelah penerapan, sehingga banyak tim juga mengecualikan penerapan hari Jumat dan sore dari jendela waktu untuk mengurangi risiko keharusan melibatkan teknisi panggilan di malam hari atau selama akhir pekan setelah penerapan. Kami mendapati bahwa pengaturan jendela waktu ini memungkinkan pemulihan cepat bahkan saat diperlukan tindakan manual, mengurangi keterlibatan rekayasawan yang bertugas siaga di jam kerja reguler, dan memastikan perubahan kecil dikumpulkan saat jendela waktu ditutup.
Pipeline sebagai kode
Tim layanan AWS umumnya memiliki banyak pipeline untuk menerapkan beberapa layanan mikro dan jenis sumber (kode aplikasi, kode infrastruktur, patch OS, dll.) bagi tim. Setiap pipeline memiliki banyak tahapan penerapan untuk Wilayah dan Availability Zone yang jumlahnya terus meningkat. Ini beralih menjadi banyak konfigurasi untuk dikelola oleh tim dalam sistem pipeline, dalam sistem penerapan, dan dalam sistem alarm, dan banyak upaya untuk mengikuti praktik terbaik terbaru dan dengan Wilayah dan Availability Zone baru. Dalam beberapa tahun terakhir, kami telah menerapkan praktik “pipeline sebagai kode” sebagai cara untuk lebih mudah dan konsisten mengonfigurasi pipeline yang aman dan terkini dengan memodelkan konfigurasi ini dalam bentuk kode. Alat pipeline sebagai kode internal kami mengambil dari daftar terpusat Wilayah dan Availability Zone untuk dengan mudah menambahkan Wilayah dan Availability Zone baru ke pipeline di seluruh AWS. Alat ini juga memungkinkan tim membuat model pipeline menggunakan warisan, yang menentukan konfigurasi yang umum di seluruh pipeline tim di kelas induk (seperti Region mana yang digunakan di setiap gelombang dan berapa lama waktu pemrosesan untuk setiap gelombang) dan menentukan semua konfigurasi pipeline layanan mikro sebagai subkelas yang mewarisi semua konfigurasi umum.
Penutup
Di Amazon, kami telah membangun praktik penerapan otomatis seiring waktu berdasarkan apa yang membantu kami menyeimbangkan keamanan penerapan dengan kecepatan penerapan. Di saat yang sama, kami ingin meminimalkan jumlah waktu yang dibutuhkan pengembang untuk memikirkan penerapan. Membangun keamanan penerapan otomatis menjadi proses rilis dengan menggunakan pengujian pra-produksi yang ekstensif, pembatalan otomatis, dan penerapan produksi bertahap memungkinkan kami meminimalkan potensi dampak pada produksi yang disebabkan oleh penerapan. Artinya, pengembang tidak perlu aktif mengawasi penerapan pada produksi.
Dengan pipeline yang sepenuhnya otomatis, developer menggunakan tinjauan kode untuk memeriksa kodenya dan juga untuk menyetujui bahwa perubahan tersebut siap untuk diproduksi. Setelah perubahan digabungkan ke dalam repositori kode sumber, pengembang dapat melanjutkan ke tugas berikutnya dan melupakan penerapan, mempercayakan pipeline untuk mengubah produksi dengan aman dan hati-hati. Pipeline otomatis menangani penerapan terus menerus pada produksi beberapa kali sehari, sambil menyeimbangkan keselamatan dan kecepatan. Memodelkan praktik pengiriman berkelanjutan kami dalam bentuk kode memudahkan tim layanan AWS untuk menyiapkan pipeline dalam melakukan deployment perubahan kode secara otomatis dan aman.
Baca lebih lanjut
Untuk informasi selengkapnya mengenai cara Amazon meningkatkan keamanan dan ketersediaan layanan sekaligus meningkatkan kepuasan pelanggan dan produktivitas developer, lihat Going faster with continuous delivery
Untuk penjelasan tentang strategi menulis dan melakukan deployment yang kompatibel dengan versi sebelumnya, lihat artikel Builders’ Library Ensuring rollback safety during deployments
Tentang penulis
Clare Liguori adalah Pakar Perangkat Lunak Utama di AWS. Saat ini, ia berfokus pada pengalaman developer untuk AWS Container Services, membangun alat di persimpangan siklus hidup kontainer dan pengembangan perangkat lunak: pengembangan lokal, infrastruktur sebagai kode, CI/CD, observabilitas, dan operasi.

Konten terkait
Apakah Anda sudah menemukan yang Anda cari?
Beri tahu kami agar kami dapat meningkatkan kualitas konten di halaman kami