Tantangan terkait sistem terdistribusi
ARSITEKTUR | TINGKAT 200
Pengantar
Saat kita menambahkan server kedua, sistem terdistribusi menjadi cara kerja utama di Amazon. Saat saya mulai bekerja di Amazon pada 1999, tidak banyak server yang kami miliki hingga kami bisa memberi beberapa di antaranya nama yang mudah dikenali, seperti “fishi” atau “online-01”. Tetapi bahkan pada 1999, komputasi terdistribusi tidaklah mudah. Saat ini tantangan dengan sistem terdistribusi meliputi latensi, penskalaan, pemahaman atas API jaringan, penyusunan dan penghapusan susunan data, serta kompleksitas algoritme, seperti Paxos. Saat sistem dengan cepat bertambah besar dan lebih terdistribusi, yang dulunya menjadi kasus edge teoritis berubah menjadi kejadian rutin.
Mengembangkan layanan komputasi utilitas terdistribusi, seperti jaringan telepon jarak jauh yang andal, atau layanan Amazon Web Services (AWS) tidaklah mudah. Komputasi terdistribusi juga lebih tidak biasa dan kurang intuitif dibandingkan bentuk komputasi lainnya karena dua masalah yang saling terkait. Kegagalan independen dan nondeterminisme menyebabkan masalah yang paling berdampak dalam sistem terdistribusi. Selain kegagalan komputasi umum yang sudah biasa ditangani oleh sebagian besar rekayasawan, sistem terdistribusi dapat mengalami berbagai jenis kegagalan lainnya. Yang lebih parah, tidak mungkin selalu mengetahui apakah sesuatu mengalami kegagalan.
Di seluruh Pustaka Amazon Builders, kami membahas bagaimana AWS menangani masalah pengembangan dan pengoperasian yang rumit yang disebabkan oleh sistem terdistribusi. Sebelum mempelajari teknis ini secara terperinci di artikel lainnya, sebaiknya kita meninjau konsep yang berkontribusi terhadap mengapa komputasi terdistribusi sangat, hmm, aneh. Pertama, mari kita tinjau tipe sistem terdistribusi.
Tipe sistem terdistribusi
Sistem terdistribusi sebenarnya memiliki kesulitan implementasi yang bervariasi. Pada satu sisi spektrum, kita memiliki sistem terdistribusi offline. Ini meliputi sistem pemrosesan batch, klaster analisis big data, farm rendering adegan film, klaster pelipatan protein, dan lain-lain. Meski tidak sederhana penting untuk diterapkan, sistem terdistribusi offline mendapatkan hampir semua manfaat komputasi terdistribusi (skalabilitas dan toleransi kesalahan), dan serta hampir tidak memiliki kelemahannya (mode kegagalan yang kompleks dan tidak deterministik).
Di pertengahan spektrum, kami memiliki sistem terdistribusi waktu nyata dengan batas waktu yang sedikit longgar . Sistem ini bersifat kritis dan harus terus menghasilkan atau memperbarui hasil, tetapi sistem tersebut memiliki rentang waktu yang cukup longgar untuk melakukannya. Contoh dari sistem tersebut meliputi sejumlah builder indeks pencarian, sistem yang mencari sistem yang rusak, peran untuk Amazon Elastic Compute Cloud (Amazon EC2), dan sebagainya. Pengindeks pencarian mungkin offline selama (bergantung pada aplikasinya) mulai dari 10 menit hingga beberapa jam tanpa dampak pelanggan yang tidak terduga. Peran untuk Amazon EC2 harus mendorong kredensial yang diperbarui ke (pada dasarnya) setiap instans EC2, tetapi memiliki jam untuk melakukannya karena kredensial lama tidak kedaluwarsa di waktu yang bersamaan.
Pada ujung spektrum terjauh dan tersulit, kami memiliki sistem terdistribusihard real-time. Sistem ini sering disebut sebagai layanan permintaan/balasan. Di Amazon, saat kami memikirkan tentang membangun sebuah sistem terdistribusi, sistem hard real-time adalah jenis sistem pertama yang terpikir oleh kami. Sayangnya, sistem terdistribusi hard real-time paling sulit mendapatkan hasil yang benar. Yang membuatnya sulit adalah permintaan yang datang tanpa dapat diprediksi dan respons harus diberikan dengan cepat (misalnya, pelanggan aktif menunggu respons). Contoh meliputi server web ujung depan, saluran pesanan, transaksi kartu kredit, setiap API AWS, telefoni, dan sebagainya. Sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat menjadi fokus utama artikel ini.
Sistem waktu nyata dengan batas waktu yang sangat ketat memang tidak biasa
Dalam satu baris plot dari buku komik Superman, Superman berhadapan dengan alter ego bernama Bizarro yang tinggal di sebuah planet (Bizarro World), di mana segalanya berjalan terbalik. Bizarro terlihat mirip dengan Superman, tetapi sebenarnya dia jahat. Sistem terdistribusi hard real-time sama saja. Sistem ini terlihat seperti komputasi biasa, tetapi sebenarnya berbeda, dan sejujurnya, sedikit buruk di satu sisi.
Pengembangan sistem terdistribusi hard real-time tampak tidak jelas karena satu alasan: jaringan permintaan/balasan. Maksud kami bukan detail baru mengenai TCP/IP, DNS, socket, atau protokol lainnya. Subjek tersebut berpotensi sulit dipahami, tetapi mereka mewakili masalah sulit lainnya dalam komputasi.
Hal yang membuat sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat menjadi sulit adalah jaringan memungkinkan pengiriman pesan dari satu domain kesalahan ke domain lainnya. Mengirim pesan mungkin tidak tampak berbahaya. Faktanya, mengirim pesan menjadi titik semua hal mulai menjadi lebih rumit daripada sebelumnya.
Sebagai contoh sederhana, lihat snippet kode berikut dari implementasi Pac-Man. Jika dirancang untuk berjalan pada satu mesin, sistem tersebut tidak dapat mengirimkan pesan apa pun melalui jaringan.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
return
Sekarang, mari kita bayangkan mengembangkan versi kode ini dalam jaringan, tempat status objek papan disimpan dalam server terpisah. Setiap panggilan ke objek papan, seperti findAll(), menghasilkan pengiriman dan penerimaan pesan di antara dua server.
Kapan pun pesan permintaan/balasan dikirim antara dua server, rangkaian delapan langkah yang sama, paling tidak, harus selalu terjadi. Untuk memahami kode Pac-Man dalam jaringan, mari kita tinjau dasar-dasar pemahaman perpesanan permintaan/balasan.
Perpesanan di seluruh jaringan
Perpesanan permintaan/balasan di seluruh jaringan
Tindakan permintaan/balasan dua arah selalu melibatkan langkah yang sama. Seperti yang ditunjukkan dalam diagram berikut, mesin klien CLIENT mengirim permintaan MESSAGE melalui jaringan NETWORK ke mesin server SERVER, yang membalas dengan pesan REPLY, juga melalui jaringan NETWORK
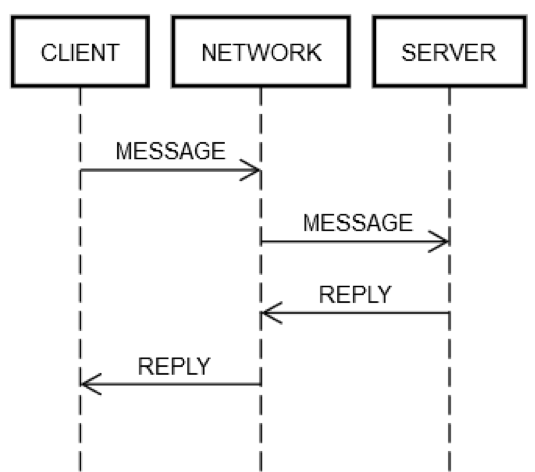
Dalam kondisi normal ketika semuanya berjalan dengan baik, langkah berikut terjadi:
-
POST REQUEST: CLIENT memasukkan permintaan MESSAGE ke dalam NETWORK.
-
DELIVER REQUEST: NETWORK mengirimkan MESSAGE ke SERVER.
-
VALIDATE REQUEST: SERVER memvalidasi MESSAGE.
-
UPDATE SERVER STATE: SERVER memperbarui statusnya, jika diperlukan, berdasarkan MESSAGE.
-
POST REPLY: SERVER memasukkan balasan REPLY ke dalam NETWORK.
-
DELIVER REPLY: NETWORK mengirimkan REPLY kepada CLIENT.
-
VALIDATE REPLY: CLIENT memvalidasi REPLY.
-
UPDATE CLIENT STATE: CLIENT memperbarui statusnya, jika diperlukan, berdasarkan REPLY.
Terdapat banyak langkah untuk sebuah perjalanan dua arah kecil! Tetap saja, langkah-langkah tersebut merupakan definisi komunikasi permintaan/balasan di jaringan; tidak ada cara untuk melewatinya. Misalnya, tidak mungkin Anda melewati langkah 1. Klien harus memasukkan MESSAGE ke jaringan NETWORK. Secara fisik, ini berarti mengirim paket melalui adaptor jaringan, yang menyebabkan sinyal elektrik untuk bepergian melalui kabel melalui serangkaian router yang membangun jaringan antara CLIENT dan SERVER. Ini terpisah dari langkah 2 karena langkah 2 dapat mengalami kegagalan karena alasan terpisah, misalnya SERVER tiba-tiba kehilangan daya dan tidak dapat menerima paket masuk. Logika yang sama dapat diterapkan pada langkah selanjutnya.
Oleh karena itu, satu permintaan/balasan melalui jaringan memecah satu hal (memanggil satu metode) menjadi delapan langkah berbeda. Lebih parahnya lagi, seperti yang telah disebutkan di atas, CLIENT, SERVER, dan NETWORK dapat mengalami kegagalan secara terpisah satu sama lain. Kode rekayasawan harus menangani kegagalan apa pun pada setiap langkah yang telah dijelaskan sebelumnya. Rekayasa umum jarang seperti ini. Untuk melihat alasannya, mari kita tinjau ekspresi berikut dari versi satu mesin kode.
board.find("pacman")
Secara teknis, ada beberapa cara yang tidak biasa bagaimana kode ini bisa gagal pada runtime, bahkan jika implementasi board.find bebas dari bug. Misalnya, CPU dapat secara spontan mengalami kelebihan panas pada runtime. Sumber daya listrik mesin juga dapat mengalami kegagalan secara spontan. Kernel dapat panik. Memori dapat terisi, dan beberapa objek yang board.find coba untuk buat tidak dapat dibuat. Atau, disk pada mesin tempatnya berjalan dapat terisi, dan board.find dapat mengalami kegagalan untuk memperbarui beberapa file statistik kemudian menghasilkan kesalahan, walapun seharusnya tidak demikian. Sinar gamma dapat mengenai server dan menyebabkan bit di RAM. Tetapi, lebih seringnya teknisi tidak mengkhawatirkan hal-hal tersebut. Misalnya, pengujian unit tidak pernah mencakup skenario “bagaimana jika CPU gagal”, dan jarang mencakup skenario di luar memori.
Dalam rekayasa teknis, jenis kegagalan ini terjadi pada satu mesin; yakni domain kesalahan. Misalnya, jika metode board.find mengalami kegagalan karena CPU secara spontan terbakar, dapat diasumsikan bahwa seluruh mesin rusak. Menangani kesalahan tersebut secara konseptual bahkan tidak dapat dilakukan. Asumsi serupa dapat dibuat mengenai jenis kesalahan lainnya yang tercantum sebelumnya. Anda dapat mencoba mengulis pengujian untuk beberapa kasus ini, tetapi tidak terlalu berguna untuk rekayasa umum. Jika kegagalan ini memang terjadi, sebaiknya berasumsi bahwa semua hal akan gagal juga. Secara teknis, menurut kami semuanya bernasib sama. Fate sharing mengurangi secara signifikan berbagai mode kegagalan yang harus ditangani oleh rekayasawan.
Menangani kegagalan
Menangani mode kegagalan dalam sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat
Teknisi yang bekerja pada sistem terdistribusi hard real-time harus menguji semua aspek kegagalan jaringan karena server dan jaringan tidak memiliki nasib yang sama. Tidak seperti kasus satu mesin, jika jaringan mengalami kegagalan, mesin klien akan tetap bekerja. Jika mesin jarak jauh mengalami kegagalan, mesin klien akan tetap bekerja, begitu pula sebaliknya.
Untuk terus-menerus menguji kasus kegagalan langkah permintaan/balasan seperti yang dijelaskan sebelumnya, teknisi harus berasumsi bahwa setiap langkah dapat mengalami kegagalan. Selain itu, mereka harus memastikan bahwa kode (pada klien dan server) selalu berperilaku dengan benar dengan mempertimbangkan kegagalan tersebut.
Mari kita lihat tindakan permintaan/balasan dua arah saat segalanya tidak berjalan dengan baik:
-
POST REQUEST gagal: NETWORK gagal mengirim pesan (misalnya, router langsung mengalami crash pada saat yang tidak tepat), atau SERVER menolaknya secara eksplisit.
-
DELIVER REQUEST gagal: NETWORK berhasil mengirimkan MESSAGE ke SERVER, tetapi SERVER mengalami crash langsung setelah menerima MESSAGE.
-
VALIDATE REQUEST gagal: SERVER memutuskan bahwa MESSAGE tidak valid. Penyebabnya bisa apa saja. Misalnya, paket yang korup, versi perangkat lunak yang tidak kompatibel, atau bug pada klien atau server.
-
UPDATE SERVER STATE gagal: SERVER mencoba memperbarui statusnya, tetapi gagal.
-
POST REPLY gagal: Terlepas dari apakah balasan berisi hasil sukses maupun gagal, SERVER dapat gagal memposting balasan. Misalnya, kartu jaringanya mungkin terbakar pada saat yang tidak tepat.
-
DELIVER REPLY gagal: NETWORK dapat gagal mengirim REPLY ke CLIENT seperti yang diuraikan sebelumnya meskipun NETWORK bekerja di langkah sebelumnya.
-
VALIDATE REPLY gagal: CLIENT memutuskan bahwa REPLY tidak valid.
-
UPDATE CLIENT STATE gagal: CLIENT dapat menerima pesan REPLY, tetapi gagal memperbarui statusnya sendiri, gagal memahami pesan (karena tidak kompatibel), atau mengalami kegagalan karena alasan lainnya.
Mode kegagalan inilah yang membuat komputasi terdistribusi begitu sulit. Saya menyebutnya delapan mode kegagalan apocalypse. Dengan mempertimbangkan mode kegagalan ini, mari kita tinjau ekspresi ini dari kode Pac-Man lagi.
board.find("pacman")
Ekspresi ini diperluas menjadi aktivitas di sisi klien berikut:
-
Posting pesan, misalnya {action: "find", name: "pacman", userId: "8765309"}, ke jaringan, dengan dialamtkan ke mesin Papan.
-
Jika jaringan tidak tersedia, atau koneksi ke mesin Papan ditolak secara eksplisit, ajukan kesalahan. Kasus ini terutama istimewa karena klien mengetahui, secara deterministik, bahwa permintaan tersebut tidak mungkin diterima oleh mesin server.
-
Tunggu balasan.
-
Jika balasan tidak pernah diterima, waktu habis. Dalam langkah ini, batas waktu berarti bahwa hasil permintaan adalah UNKNOWN. Ini mungkin telah atau tidak terjadi. Klien harus menangani UNKNOWN dengan benar.
-
Jika balasan diterima, tentukan apakah balasan adalah balasan keberhasilan, balasan kesalahan, atau balasan yang tidak dapat dimengerti/korup.
-
Jika ini bukan kesalahan, lepaskan respons dan ubah menjadi objek yang dipahami oleh kode.
-
Jika ini adalah kesalahan atau balasan yang tidak dapat dipahami, ajukan pengecualian.
-
Pihak mana pun yang menangani pengecualian harus menentukan apakah akan mencoba ulang permintaan atau menyerah dan menghentikan permainan.
Ekspresi ini juga diawali dengan aktivitas di sisi server berikut:
-
Menerima permintaan (ini mungkin tidak terjadi sama sekali).
-
Memvalidasi permintaan.
-
Melihat pengguna untuk melihat apakah pengguna masih hidup. (Server mungkin telah menyerah pada pengguna karena terlalu lama tidak menerima pesan apa pun dari mereka).
-
Memperbarui tabel keep-alive untuk pengguna agar server tahu bahwa pengguna (mungkin) masih ada.
-
Melihat posisi pengguna.
-
Posting respons yang berisi sesuatu seperti {xPos: 23, yPos: 92, clock: 23481984134}.
-
Setip logika server lanjutan harus menangani efek klien berikutnya dengan benar. Misalnya, kegagalan menerima pesan, bisa menerima pesan tetapi tidak memahaminya, menerima pesan dan mengalami crash, atau berhasil menanganinya.
Ringkasnya, satu ekspresi dalam kode normal akan berubah menjadi lima belas langkah ekstra dalam kode sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat. Perluasan ini disebabkan oleh delapan titik berbeda tempat setiap komunikasi dua arah antara klien dan server dapat mengalami kegagalan. Setiap ekspresi yang mewakili perjalanan dua arah melalui jaringan seperti board.find("pacman"), akan menghasilkan hal berikut.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the only thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatible
Kompleksitas ini tidak terhindarkan. Jika kode tidak menangani semua kasus dengan benar, layanan akan mengalami kegagalan yang aneh pada akhirnya. Bayangkan mencoba menulis tes untuk semua mode kegagalan yang bisa dialami oleh sistem klien/server, seperti contoh Pac-Man!
Pengujian
Menguji sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat
Menguji versi satu mesin snippet kode Pac-Man relatif sangat jelas. Buat beberapa objek Papan berbeda, letakkan ke dalam status berbeda, buat beberapa objek Pengguna dalam status berbeda, dan sebaliknya. Teknisi akan berpikir sangat keras mengenai kondisi edge, dan mungkin menggunakan pengujian generatif, atau fuzzer.
Dalam kode Pac-Man, terdapat empat tempat objek papan digunakan. Dalam Pac-Man teridistribusi, terdapat empat titik dalam kode tersebut yang memiliki lima kemungkinan hasil yang berbeda, seperti yang diilustrasikan sebelumnya (POST_FAILED, RETRYABLE, FATAL, UNKNOWN, atau SUCCESS). Ini akan benar-benar melipatgandakan ruang status pengujian. Sebagai contoh, teknisi sistem terdistribusi hard real-time harus menangani banyak permutasi. Misalnya panggilan ke board.find() gagal dengan POST_FAILED. Kemudian Anda harus menguji apa yang terjadi saat ini gagal dengan RETRYABLE, kemudian Anda harus menguji apa yang terjadi jika ini gagal dengan FATAL, dan seterusnya.
Namun bahkan pengujian tersebut tidaklah cukup. Dalam kode umum, teknisi dapat berasumsi bahwa jika board.find() bekerja, panggilan berikutnya ke board, board.move(), juga akan bekerja. Dalam rekayasa sistem terdistribusi hard real-time, tidak ada jaminan semacam itu. Mesin server bisa gagal secara independen setiap saat. Sebagai akibatnya, teknisi harus menulis pengujian untuk kelima kasus untuk setiap panggilan ke papan. Kita ambil contoh teknisi menghasilkan 10 skenario untuk diuji dalam versi Pac-Man satu mesin. Tetapi dalam versi sistem terdistribusi, mereka harus menguji setiap skenario tersebut sebanyak 20 kali. Yang artinya matriks uji melambung dari 10 ke 200!
Namun, tunggu dulu, masih ada lagi. Rekayasawan mungkin juga memiliki kode server. Berbagai kombinasi kesalahan yang terjadi di sisi klien, jaringan, dan server harus diuji agar klien dan server tidak berakhir dalam kondisi korup. Kode server mungkin tampak seperti berikut.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...
Terdapat empat fungsi sisi server untuk diuji. Mari kita asumsikan setiap fungsi, pada satu mesin, memiliki lima pengujian. Terdapat 20 pengujian di sana. Karena klien mengirimkan beberapa pesan ke server yang sama, pengujian harus menyimulasikan urutan permintaan berbeda untuk memastikan server tetap tangguh. Contoh permintaan meliputi find, move, remove, dan findAll.
Kita andaikan setiap construct memiliki 10 skenario berbeda dengan rata-rata tiga panggilan dalam setiap skenario. Itu berarti 30 pengujian tambahan. Tetapi satu skenario juga perlu menguji kasus kegagalan. Untuk masing-masing dari pengujian tersebut, Anda perlu menyimulasikan apa yang terjadi jika klien menerima salah satu dari empat jenis kegagalan (POST_FAILED, RETRYABLE, FATAL, and UNKNOWN), kemudian memanggil server kembali dengan permintaan yang tidak valid. Sebagai contoh, klien mungkin berhsil memanggil find, tetapi kemudian terkadang mendapatkan UNKNOWN kembali saat memanggil move. Klien kemudian kembali memanggil find karena beberapa alasan. Apakah server menangani kasus ini dengan benar? Mungkin, tetapi Anda tidak akan tahu kecuali Anda mengujinya. Jadi, sama seperti kode di sisi klien, matriks pengujian di sisi server juga menjadi makin rumit.
Menangani hal yang tidak diketahui
Menangani hal yang tidak diketahui
Mempertimbangkan semua permutasi kegagalan yang dapat dihadapi oleh sistem terdistribusi memang merepotkan, terutama pada beberapa permintaan. Salah satu cara yang kami temukan untuk mendekati rekayasa terdistribusi adalah dengan tidak mempercayai semua hal. Setiap baris kode, kecuali tidak mungkin menyebabkan komunikasi jaringan, mungkin tidak melakukan yang seharusnya dikerjakannya.
Mungkin hal tersulit yang harus ditangani adalah jenis kesalahan UNKNOWN yang diuraikan di bagian sebelumnya. Klien tidak selalu tahu apakah permintaan berhasil. Mungkin permintaan berhasil menggerakkan Pac-Man (atau, dalam layanan perbankan, menarik uang dari rekenin bank pengguna), atau mungkin permintaan tidak berhasil. Bagaimana sebaiknya teknisi menangani hal semacam itu? Hal ini sulit karena teknisi manusia biasa, dan manusia cenderung kesulitan menghadapi ketidakpastian yang sesungguhnya. Manusia sudah terbiasa melihat kode seperti berikut.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return false
Manusia memahami kode ini karena kode melakukan apa yang sepertinya kode lakukan. Manusia mengalami kesulitan dengan versi kode terdistribusi, yang mendistribusikan beberapa pekerjaan ke layanan.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?
Hampir mustahil bagi manusia untuk mencari tahu cara menangani UNKNOWN dengan benar. Apa sebenarnya yang dimaksud dengan UNKNOWN? Haruskan kode mencoba ulang? Jika ya, berapa kali? Berapa lama sebaiknya kode mencoba di antara percobaan ulang? Bahkan menjadi semakin buruk jika kode memiliki efek samping. Di dalam aplikasi anggaran yang berjalan pada satu mesin, menarik uang dari sebuah rekening sangatlah mudah, seperti yang ditunjukkan dalam contoh berikut.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
Meski demikian, versi terdistribusi dari aplikasi tersebut menjadi aneh karena UNKNOWN.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?
Mencari tahu cara menangani tipe kesalahan UNKNOWN adalah satu alasan mengapa, dalam rekayasa terdistribusi, banyak hal tidak selalu seperti yang terlihat.
Herd
Herd sistem terdistribusi waktu nyata dengan batas waktu yang sangat ketat
Delapan mode kegagalan apocalypse dapat terjadi pada setiap level abstraksi dalam sistem terdistribusi. Contoh sebelumnya terbatas pada satu mesin klien, sebuah jaringan, dan satu mesin server. Bahkan dalam skenario sederhana tersebut, matriks status kegagalan mengalami lonjakan kompleksitas. Sistem terdistribusi sesungguhnya memiliki matriks status kegagalan yang lebih rumit daripada contoh satu mesin klien. Sistem terdistribusi sesungguhnya terdiri dari beberapa mesin yang dapat dilihat pada beberapa tingkat abstraksi:
-
Mesin individual
-
Grup mesin
-
Grup dari grup mesin
-
Dan seterusnya (kemungkinan)
Sebagai contoh, layanan yang dibangun di AWS dapat mengelompokkan beberapa mesin yang didedikasikan untuk menangani sumber daya yang berada dalam Availability Zone tertentu. Mungkin terdapat dua grup mesin lainnya yang menangani dua Availability Zone lainnya. Kemudian, grup ini dapat dikelompokkan ke dalam grup Wilayah AWS. Dan grup Region tersebut kemudian dapat berkomunikasi (secara logis) dengan grup Region lainnya. Sayangnya, bahkan pada tingkat yang lebih tinggi dan lebih logis ini, semua masalah yang sama tetap terjadi.
Mari kita asumsikan sebuah layanan telah mengelompokkan beberapa server ke dalam satu grup logis, GROUP1. Grup GROUP1 mungkin terkadang mengirimkan pesan kepada grup server lainnya, GROUP2. Ini adalah contoh dari rekayasa terdistribusi rekursif. Semua mode kegagalan jaringan yang dijelaskan sebelumnya berlaku di sini. Misalnya, GROUP1 ingin mengirimkan permintaan kepada GROUP2. Seperti yang ditunjukkan dalam diagram berikut, interaksi permintaan/balasan dua mesin sama seperti satu mesin yang dibahas sebelumnya.
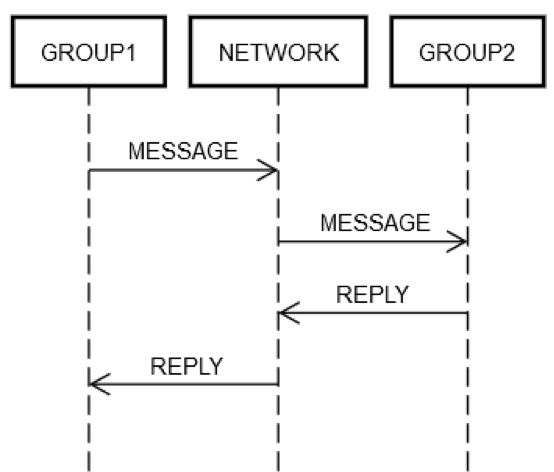
Dalam semua kemungkinan, beberapa mesin dalam GROUP1 telah memasukkan pesan ke jaringan, NETWORK, yang ditujukan (secara logis) ke GROUP2. Beberapa mesin dalam GROUP2 harus memproses permintaan, dan sebaliknya. Fakta bahwa GROUP1 dan GROUP2 terdiri dari beberapa grup mesin tidak mengubah prinsip dasarnya. GROUP1, GROUP2, dan NETWORK masing-masing tetap dapat mengalami kegagalan.
Meski demikian, ini hanya tampilan tingkat grup. Ada juga interaksi tingkat mesin ke mesin dalam grup. Misalnya, GROUP2 mungkin terstruktur seperti yang ditunjukkan pada diagram berikut.
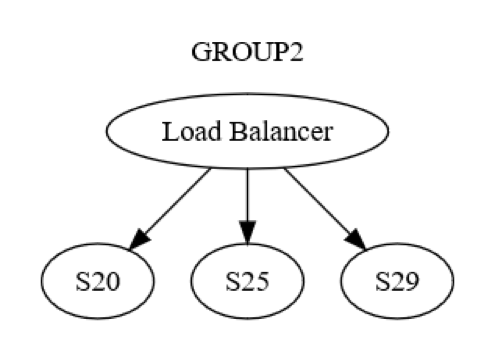
Awalnya, pesan ke GROUP2 dikirim, melalui penyeimbang beban, ke satu mesin (kemungkinan S20) dalam grup. Perancang sistem mengetahui bahwa S20 mungkin mengalami kegagalan saat fase UPDATE STATE. Sebagai akibatnya, S20 mungkin perlu meneruskan pesan ke setidaknya satu mesin lainnya, baik salah satu rekannya atau mesin di grup yang berbeda. Bagaimana sebenarnya S20 melalukan hal tersebut? Dengan mengirim pesan permintaan/balasan ke, misalnya S25, seperti yang ditunjukkan dalam diagram berikut.
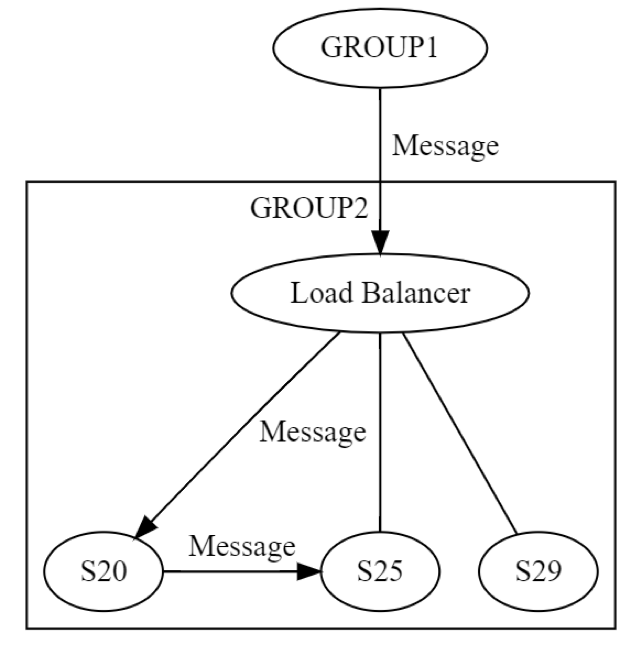
Oleh karena itu, S20 menjalankan jaringan secara berulang. Kedelapan kegagalan dapat terjadi, sekali lagi, secara independen. Rekayasa terdistribusi terjadi dua kali, bukan satu kali. Pesan GROUP1 ke GROUP2, pada tingkat logis, dapat mengalami kegagalan dalam delapan cara. Pesan tersebut dapat menghasilkan pesan lainnya, yang juga dapat mengalami kegagalan, secara terpisah, dalam delapan cara yang dibahas sebelumnya. Menguji skenario ini akan melibatkan setidaknya hal berikut:
-
Pengujian terhadap delapan cara perpesanan tingkat grup GROUP1 ke GROUP2 dapat mengalami kegagalan.
-
Pengujian terhadap delapan cara perpesanan tingkat server S20 ke S25 dapat mengalami kegagalan.
Contoh perpesanan permintaan/balasan ini menunjukkan alasan menguji sistem terdistribusi tetap menjadi masalah yang sangat sulit meskipun telah memiliki pengalaman lebih dari 20 tahun di bidang ini. Pengujian menantang mengingat besarnya kasus edge, tetapi terutama penting dalam sistem ini. Bug dapat memerlukan waktu lama untuk terlihat setelah sistem diterapkan. Selain itu, bug dapat memiliki dampak luas yang tidak dapat diprediksi terhadap sistem dan sistem di sekitarnya.
Bug terdistribusi
Bug terdistribusi sering kali bersifat laten
Jika kegagalan memang tidak terhindarkan, ada anggapan umum bahwa lebih baik kegagalan terjadi lebih cepat. Misalnya, lebih baik menemukan masalah penskalaan pada suatu layanan, yang membutuhkan waktu 6 bulan untuk diperbaiki, setidaknya enambulan sebelum layanan tersebut harus mencapai skala tersebut. Selain itu, lebih baik bug ditemukan sebelum masuk ke tahap produksi. Jika bug mencapai produksi, lebih baik menemukan bug dengan cepat, sebelum memengaruhi banyak pelanggan atau memiliki efek buruk lainnya.
Bug terdistribusi, yang artinya bug yang disebabkan oleh kegagalan menangani semua permutasi kedelapan mode kegagalan apocalypse, seringkali amat buruk. Contoh dari waktu ke waktu menumpuk di sistem terdistribusi besar, dari sistem telekomunikasi hingga sistem internet penting. Pemadaman ini tidak hanya tersebar luas dan mahal, tetapi juga dapat disebabkan oleh bug yang diterapkan pada produksi berbulan-bulan sebelumnya. Selanjutnya butuh waktu beberapa saat untuk bug memicu kombinasi skenario yang sebenarnya menyebabkan bug ini terjadi (dan menyebar ke seluruh sistem).
Bug terdistribusi tersebar secara epidemis
Izinkan saya menjelaskan maslaah lain yang sangat penting untuk bug terdistribusi:
-
Bug terdistribusi pasti melibatkan penggunaan jaringan.
-
Karena itu, bug terdistribusi lebih cenderung tersebar ke mesin lain (atau grup mesin), karena, berdasarkan definisi, bug tersebut telah meliputi satu hal yang menautkan banyak mesin secara bersamaan.
Amazon pernah mengalami bug terdistribusi ini juga. Sebuah contoh lama namun relevan adalah kegagalan yang terjadi di seluruh situs www.amazon.com. Kegagalan tersebut disebabkan oleh kegagalan sebuah server dalam layanan katalog jarak jauh saat disk terisi.
Karena kesalahan penanganan pada kondisi kesalahan, server katalog jarak jauh menghasilkan respons kosong untuk setiap permintaan yang diterimanya. Server juga mulai menghasilkan respons kosong dengan sangat cepat, karena jauh lebih cepat tidak menghasilkan apa pun daripada menghasilkan sesuatu (setidaknya dalam kasus ini). Sementara itu, penyeimbang muatan antara situs web dan layanan katalog jarak jauh tidak menyadari bahwa semua respons tidak memiliki panjang. Tetapi, penyeimbang muatan memang menyadari bahwa mereka jauh lebih cepat daripada server katalog jarak jauh. Jadi penyeimbang muatan mengirim banyak lalu lintas dari www.amazon.com ke satu server katalog jarak jauh yang disknya penuh. Secara efektif, seluruh situs web tidak dapat digunakan karena satu server jarak jauh tidak dapat menampilkan informasi produk apa pun.
Kami dengan cepat menemukan server buruk dan menghapusnya dari layanan untuk memulihkan situs web. Kemudian, kami menindaklanjuti dengan proses biasa kami dalam menentukan akar masalah dan mengidentifikasi masalah untuk mencegah situasi tersebut terjadi kembali. Kami berbagi pelajaran tersebut di seluruh Amazon untuk membantu mencegah sistem lain mengalami masalah yang sama. Selain mempelajari pelajaran tertentu mengenai mode kegagalan ini, insiden ini menjadi contoh yang bagus mengenai cara mode kegagalan menyebar secara cepat dan tidak dapat diprediksi dalam sistem terdistribusi.
Ringkasan
Ringkasan masalah dalam sistem terdistribusi
Singkatnya, rekayasa untuk sistem terdistribusi sulit karena:
-
Teknisi tidak dapat menggabungkan kondisi kesalahan. Sebagai gantinya, mereka harus mempertimbangkan permutasi kegagalan. Sebagian besar kesalahan dapat terjadi kapan pun, terlepas dari (dan karenanya, berpotensi terjadi secara bersamaan) kondisi kesalahan lainnya.
-
Hasil dari pengoperasian jaringan bisa saja menjadi UNKNOWN, dalam hal ini, permintaan mungkin berhasil, gagal, atau telah diterima, tetapi belum diproses.
-
Masalah terdistribusi terjadi di semua tingkat logis dalam sistem terdistribusi, bukan hanya mesin fisik tingkat rendah.
-
Masalah terdistribusi menjadi makin buruk pada tingkat sistem lebih tinggi karena rekursi.
-
Bug terdistribusi sering muncul lama setelah diterapkan di sistem.
-
Bug terdistribusi dapat tersebar di seluruh sistem.
-
Banyak dari masalah di atas diturunkan dari hukum fisika jaringan, yang tidak dapat diubah.
Hanya karena komputasi terdistribusi sulit—dan aneh—tidak berarti tidak ada cara untuk mengatasi masalah ini. Di seluruh Pustaka Builders Amazon, kami membahas bagaimana AWS mengelola sistem terdistribusi. Kami berharap beberapa hal yang telah kita pelajari ini dapat bermanfaat dalam membangun solusi untuk pelanggan Anda.
Tentang penulis
Jacob Gabrielsonr adalah Senior Principal Engineer di Amazon Web Services. Ia telah bekerja di Amazon selama 17 tahun, terutama pada platform layanan mikro internal. Selama 8 tahun terakhir ia telah bekerja di EC2 dan ECS, termasuk sistem penerapan perangkat lunak, layanan plane kendali, Spot market, Lightsail, dan yang terakhir, kontainer. Pemrograman sistem, bahasa pemrograman, dan komputasi terdistribusi menjadi bidang yang diminatinya. Ia paling tidak suka dengan perilaku sistem mode ganda, terutama dalam kondisi kegagalan. Ia meraih gelar sarjana dalam bidang Ilmu Komputer dari University of Washington di Seattle.

Konten terkait
Apakah Anda sudah menemukan yang Anda cari?
Beri tahu kami agar kami dapat meningkatkan kualitas konten di halaman kami