Dengan Deep Learning, Disney Dapat Menjadi yang Paling Menonjol di Dunia Konten
Apa yang begitu ajaib tentang metadata?
Gambar Atas perkenan Disney
Tim yang memimpin pekerjaan ini awalnya dibentuk pada tahun 2012, sebagai bagian dari Disney & ABC Television Group. Selama bertahun-tahun, metadata telah berkembang, dan sekarang sebagai bagian dari grup Teknologi DTCI Disney, metadata telah menjadi indeks dan basis pengetahuan dari gaya dan konvensi alam semesta Disney (misalnya, dalam percakapan hewan Bambithe—dalam Putri Salju, tidak ada). Agar alat machine learning mereka menghasilkan metadata yang mendeskripsikan konten kreatif secara akurat, tim bergantung pada penulis dan animator untuk menjelaskan fitur gaya yang membuat setiap acara unik.
Anggota tim kreatif ini mendapat manfaat dari kerja sama mereka. Setelah konten diberi etiket dengan metadata yang akurat, mereka dapat menemukan apa yang mereka butuhkan dengan cepat melalui antarmuka pencarian. Misalnya, seorang penulis untuk Grey's Anatomy, untuk menghindari redundansi, mungkin perlu mengetahui berapa kali operasi Whipple telah ditampilkan dalam sebuah episode. Sementara itu, seorang seniman yang menggambar kehidupan bawah laut untuk kartun baru yang berlangsung di bawah laut mungkin ingin mencari pose atau posisi tokoh tertentu di The Little Mermaidor Finding Nemo untuk mendapatkan inspirasi.
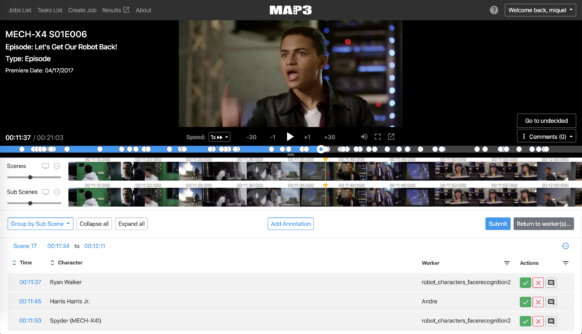
Tetapi memberi etiket semuanya dengan metadata yang tepat dengan cepat menimbulkan masalah tenaga kerja: meskipun pemberian etiket manual adalah bagian penting dari proses tersebut, tim Teknologi DTCI tidak punya waktu untuk mengkategorikan setiap frame secara manual. Itulah sebabnya tim Farré menerapkan machine learning—dan yang lebih baru, deep learning—untuk menghasilkan metadata. Tujuannya adalah untuk membuat algoritma deep learning yang dapat menandai komponen adegan secara otomatis dengan cara yang konsisten dengan basis pengetahuan Disney lainnya. Manusia masih perlu menyetujui etiket algoritma, tetapi proyek tersebut secara bermakna mengurangi pekerjaan yang dilakukan untuk mengurus perpustakaan Disney dan meningkatkan akurasi penelusuran di dalamnya.
Terlebih lagi, kemajuan ini membebaskan engineer untuk lebih fokus pada pengembangan model deep learning menggunakan AWS (Amazon Web Services). Dan sebagai hasilnya, upaya mereka untuk mengotomatiskan pembuatan metadata di berbagai jenis konten Disney terus berjalan.

Deep learning memberikan animasi sebuah identitas
Gambar Atas perkenan Disney
Salah satu proyek deep learning/metadata yang paling sukses adalah memecahkan masalah yang disajikan melalui pengenalan animasi.
Dalam film atau acara TV aksi langsung, untuk sebuah mesin, memisahkan tokoh dari lingkungannya relatif sederhana. Tetapi animasi membuat segalanya lebih rumit. Misalnya, mengambil adegan animasi saat tokoh muncul baik dalam wujud maupun dalam poster (katakanlah tokoh tersebut adalah penjahat, dan rambu Dicari telah dipasang di seluruh kota). "Untuk algoritma, ini sangat kompleks," ujar Farré.
Tahun lalu, tim Farré telah mengembangkan metode deep learning yang dapat membedakan tokoh animasi dari representasi statis mereka, mengidentifikasi mereka dalam kerumunan doppelganger (seperti di DuckTales, tempat banyak tokoh sangat identik), dan mengenali mereka dalam adegan dengan pencahayaan bergaya modern (di Alice in Wonderland, ketika Alice pertama kali bertemu di Cheshire Cat, yang dia ungkapkan hanyalah seringai giginya). Setelah memutuskan sesuatu itu apa, algoritma dapat menandai adegan dengan metadata yang sesuai.
Namun kekuatan sebenarnya dari model ini adalah ini dapat diterapkan pada konten animasi mana pun. Artinya, alih-alih membuat model baru untuk setiap Goofy, Hercules, dan Elsa, tim hanya perlu menggunakan model generik mereka, yang, dengan sedikit penyesuaian, akan berfungsi untuk tokoh apa pun di setiap pertunjukan atau film.
Sebelum tahun ini, tim bekerja dengan algoritma machine learning yang lebih tradisional, yang membutuhkan lebih sedikit data dibandingkan dengan pendekatan deep learning – tetapi juga memberikan hasil yang lebih terbatas dan tidak fleksibel. Dengan masukan data yang lebih sedikit, algoritma tradisional bekerja dengan baik. Namun jika Anda memiliki lebih banyak data secara eksponensial, maka deep learning dapat membuat perbedaan besar.
Sekarang, kata Farré, model deep learning bisa mendapatkan keuntungan dari jaringan yang sudah terlatih dan menyesuaikan untuk kasus penggunaan tertentu. Dalam kasus tokoh animasi tertentu, Disney menyempurnakan jaringan saraf dengan ribuan gambar untuk memastikan pemahaman terhadap konsep "tokoh animasi". Selanjutnya, untuk setiap pertunjukan tertentu, jaringan saraf disesuaikan kembali hanya menggunakan beberapa ratus gambar dari beberapa episode untuk mempelajari bagaimana "tokoh animasi" harus dideteksi dan diinterpretasikan dalam pertunjukan tertentu.
AWS telah menjadi partner utama dalam transisi Disney dari machine learning tradisional ke deep learning, terutama dalam hal eksperimen. Instans EC2 komputasi cloud yang elastis memungkinkan tim menguji model versi baru dengan cepat. (Untuk proyek pengenalan animasi, Disney menggunakan kerangka kerja PyTorch dengan model terlatih.) Karena ada banyak penelitian yang dilakukan dalam deep learning, tim ini terus bereksperimen dengan metode yang baru dan unik.
Penelitian metadata telah begitu sukses sehingga departemen di seluruh Disney mendapatkan angin segar. Farré mengatakan timnya belum lama ini terlibat dengan tim personalisasi ESPN untuk memberikan metadata mendetail tentang semua artikel dan video yang ada di aplikasi digital dan situs web industri terkemuka. Jika produk mengetahui bahwa Anda adalah penggemar Los Angeles Dodgers, Steph Curry, Minnesota Vikings, dan Manchester United, semakin banyak metadata yang dimilikinya tentang setiap artikel dapat memastikan Anda akan disajikan konten yang paling sesuai dengan preferensi Anda. Selain itu, algoritma machine learning, dan metadata yang mereka berikan, dapat mendukung kecerdasan buatan (AI) yang lebih canggih untuk mendorong personalisasi implisit lebih lanjut (berdasarkan hubungan data dan perilaku) dari waktu ke waktu.
Menurut Farré, aplikasi metadata tidak terbatas, terutama mengingat perpustakaan konten, tokoh, dan berbagai produk dari Disney yang luas dan terus berkembang. "Saya pikir kami tidak akan bosan," ujarnya.