Utilizzo della riduzione del carico per evitare sovraccarichi
Consegna e funzionamento del software | LIVELLO 400
Introduzione
Per alcuni anni, ho lavorato nel team di Service Frameworks presso Amazon. Il nostro team ha scritto strumenti che hanno aiutato i proprietari dei servizi AWS, quali Amazon Route 53 e Elastic Load Balancing, a costruire i loro servizi più rapidamente e i client dei servizi a chiamare tali servizi più facilmente. Altri team Amazon hanno fornito ai proprietari di servizi funzionalità quali la misurazione, l'autenticazione, il monitoraggio, la generazione di librerie client e la generazione di documentazione. Invece di far integrare manualmente ad ogni team di servizio tali funzionalità nei loro servizi, il team di Service Frameworks ha eseguito tale integrazione una volta e ha esposto la funzionalità a ciascun servizio attraverso la configurazione.
Una delle sfide che abbiamo dovuto affrontare è stata quella di determinare come fornire impostazioni predefinite ragionevoli, in particolare per le funzionalità correlate alle prestazioni o alla disponibilità. Ad esempio, non è stato facile impostare un timeout predefinito sul lato client, poiché il nostro framework non aveva idea di quali potrebbero essere le caratteristiche di latenza di una chiamata API. Non sarebbe stato più facile capirlo neanche per i proprietari dei servizi o per i client stessi, quindi abbiamo continuato a provare e abbiamo acquisito alcune informazioni utili lungo il percorso.
Una domanda comune che ci ha creato difficoltà riguardava la determinazione del numero predefinito di connessioni che il server avrebbe consentito di aprire contemporaneamente ai client. Questa impostazione è stata progettata per impedire a un server di prendere in carico troppo lavoro e di sovraccaricarsi. Più specificamente, volevamo configurare le impostazioni del numero massimo di connessioni per il server in proporzione al numero massimo di connessioni per il sistema di bilanciamento del carico. Questo era prima dei giorni di Elastic Load Balancing, quindi i sistemi di bilanciamento del carico basati su hardware erano ampiamente utilizzati.
Abbiamo deciso di aiutare i proprietari dei servizi Amazon e i relativi client a capire il valore ideale per il numero massimo di connessioni da impostare sul sistema di bilanciamento del carico e il valore corrispondente da impostare nei framework forniti. Decidemmo che se avessimo potuto capire come usare il giudizio umano per fare una scelta, avremmo potuto quindi scrivere un software per emulare quel giudizio.
Determinare il valore ideale ha finito per essere molto impegnativo. Quando il numero massimo di connessioni era impostato su un valore troppo basso, il sistema di bilanciamento del carico poteva interrompere gli aumenti del numero di richieste, anche quando il servizio disponeva di capacità sufficiente. Quando il numero massimo di connessioni era impostato su un valore troppo alto, i server diventavano lenti e non rispondevano. Quando il numero massimo di connessioni era impostato giusto per un carico di lavoro, il carico di lavoro scorreva o le prestazioni della dipendenza cambiavano. Quindi i valori erano nuovamente sbagliati, con conseguenti interruzioni o sovraccarichi non necessari.
Alla fine, abbiamo scoperto che il concetto di numero massimo di connessioni era troppo impreciso per fornire la risposta completa al puzzle. In questo articolo, descriveremo altri approcci, ad esempio la riduzione del carico, che abbiamo trovato funzionanti.
L’anatomia del sovraccarico
In Amazon evitiamo il sovraccarico progettando i nostri sistemi per ricalibrare in modo proattivo, prima che si verifichino situazioni di sovraccarico. Tuttavia, la protezione dei sistemi avviene tramite la protezione per livelli. Questo inizia con la scalabilità automatica, ma include anche meccanismi per eliminare il carico in eccesso normalmente, la capacità di monitorare tali meccanismi e, soprattutto, test continui.
Quando testiamo il carico dei nostri servizi, scopriamo che la latenza di un server a basso utilizzo è inferiore alla sua latenza ad alto utilizzo. Sotto carico pesante, il conflitto di thread, il cambio di contesto, la garbage collection e il conflitto I/O diventano più pronunciati. Alla fine, i servizi raggiungono un punto di flesso in cui le loro prestazioni iniziano a peggiorare ancora più rapidamente.
La teoria alla base di questa osservazione è nota come la Legge universale sulla scalabilità, che è una derivazione della legge di Amdahl. Questa teoria specifica che mentre il throughput di un sistema può essere aumentato usando la parallelizzazione, alla fine è limitato dal throughput dei punti di serializzazione (cioè dai task che non possono essere parallelizzati).
Sfortunatamente, il throughput non è limitato solo dalle risorse di un sistema, ma il throughput, in genere, si riduce quando il sistema è sovraccarico. Quando un sistema riceve più lavoro di quanto supportano le sue risorse, diventa lento. I computer prendono in carico lavoro anche quando sono sovraccarichi, ma trascorrono quantità crescenti del loro tempo cambiando contesto e diventano troppo lenti per essere utili.
In un sistema distribuito in cui un client sta parlando con un server, il client in genere diventa impaziente e dopo qualche tempo smette di attendere che il server risponda. Questa durata è nota come timeout. Quando un server diventa sovraccaricato in modo tale che la sua latenza superi il timeout del client, le richieste iniziano a fallire. Il grafico seguente mostra come aumenta il tempo di risposta del server all’aumentare del throughput effettivo offerto (in transazioni al secondo) e il tempo di risposta alla fine raggiunge un punto di flesso in cui le cose si deteriorano rapidamente.
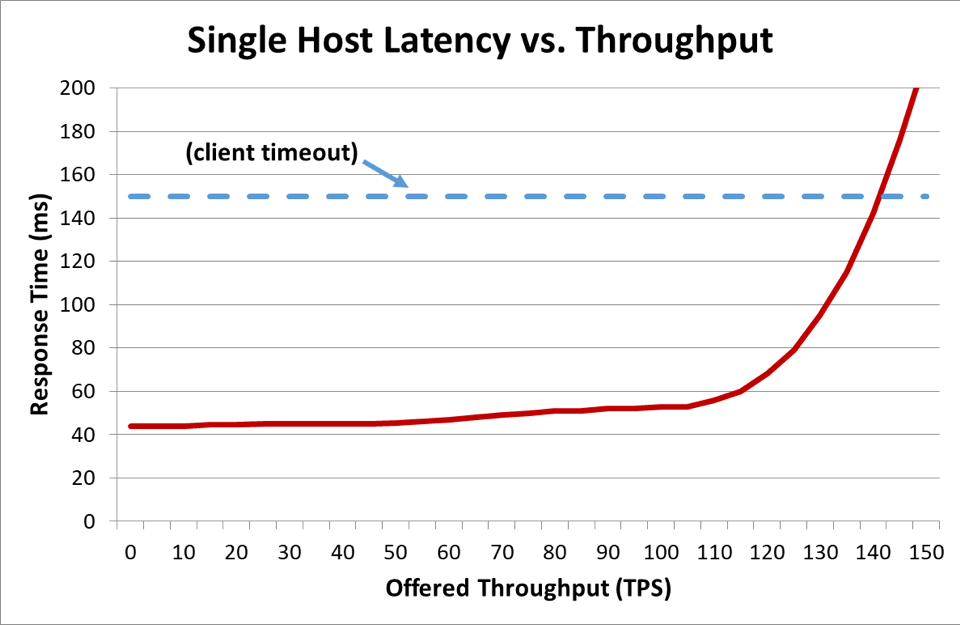
Nel grafico precedente, quando il tempo di risposta supera il timeout del client, è chiaro che le cose vadano male, ma il grafico non mostra quanto male. Per illustrare questo, possiamo tracciare la disponibilità percepita dal client insieme alla latenza. Invece di utilizzare una misurazione del tempo di risposta generica, possiamo passare all'utilizzo del tempo di risposta mediano. Il tempo di risposta mediano significa che il 50 percento delle richieste era più veloce del valore mediano. Se la latenza mediana del servizio è uguale al timeout del client, la metà delle richieste raggiunge il timeout, quindi la disponibilità è del 50 percento. È qui che un aumento di latenza trasforma un problema di latenza in un problema di disponibilità. Ecco un grafico di ciò che sta accadendo:
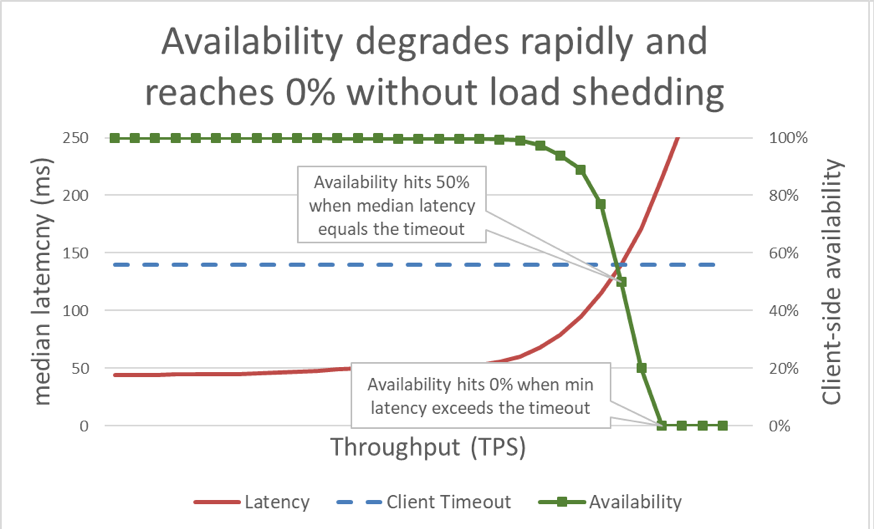
Sfortunatamente, questo grafico è difficile da leggere. Un modo più semplice per descrivere il problema di disponibilità è quello di distinguere fra goodput e throughput. Il throughput è il numero totale di richieste al secondo che viene inviato al server. Il goodput è il sottoinsieme del throughput che viene gestito senza errori e con una latenza sufficientemente bassa da consentire al client di utilizzare la risposta.
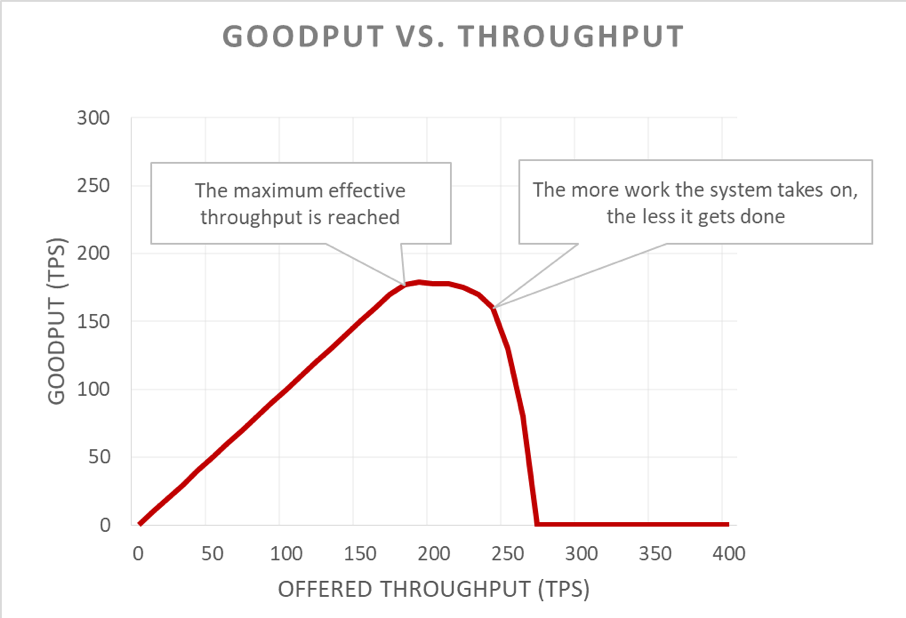
Loop di feedback positivi
La parte insidiosa di una situazione di sovraccarico è il modo in cui si amplifica in un loop di feedback. Quando un client raggiunge il timeout, è abbastanza grave che il client abbia ricevuto un errore. Ciò che è ancora peggio è che tutti i progressi che il server ha fatto finora su quella richiesta vadano sprecati. E l'ultima cosa che un sistema dovrebbe fare in una situazione di sovraccarico, in cui la capacità è limitata, è lo spreco di lavoro.
Ciò che rende peggiori le cose è che i client spesso ritrasmettono la richiesta. Questo moltiplica il carico offerto sul sistema. E se esiste un grafico delle chiamate abbastanza profondo in un'architettura orientata ai servizi (ovvero, un client chiama un servizio, che chiama altri servizi, che chiamano altri servizi) e se ogni livello esegue un numero di tentativi, un sovraccarico nel livello inferiore provoca tentativi a cascata, che amplificano esponenzialmente il carico offerto.
Quando questi fattori vengono combinati, un sovraccarico crea il proprio loop di feedback che si traduce in sovraccarico come uno stato stabile.
Impedire che il lavoro vada sprecato
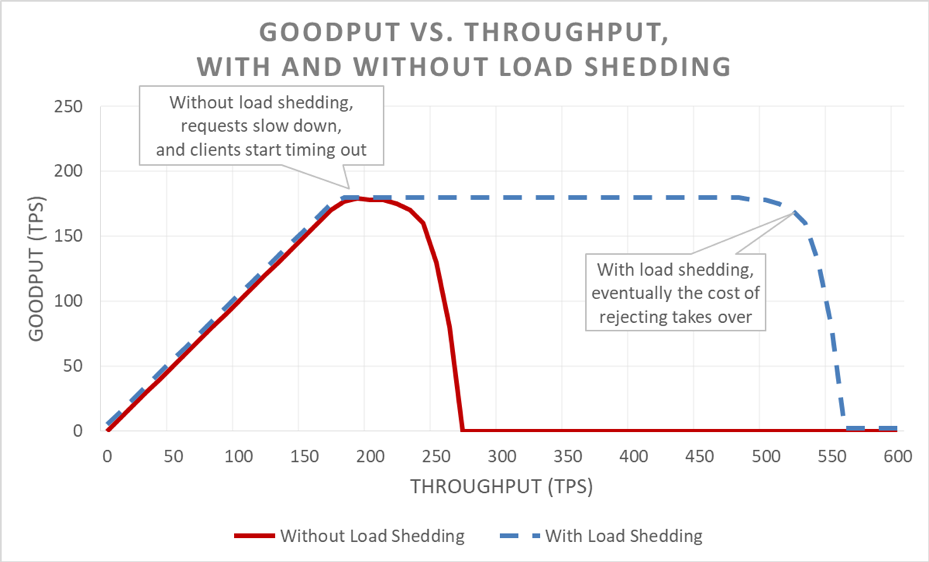
In superficie, la riduzione del carico è semplice. Quando un server si avvicina al sovraccarico, dovrebbe iniziare a rifiutare le richieste in eccesso in modo che possa concentrarsi sulle richieste che decide di far entrare. L'obiettivo della riduzione del carico è mantenere bassa la latenza per le richieste che il server decide di accettare, in modo che il servizio risponda prima che il client raggiunga il timeout. Con questo approccio, il server mantiene l’elevata disponibilità per le richieste che accetta e solo la disponibilità del traffico in eccesso è influenzata.
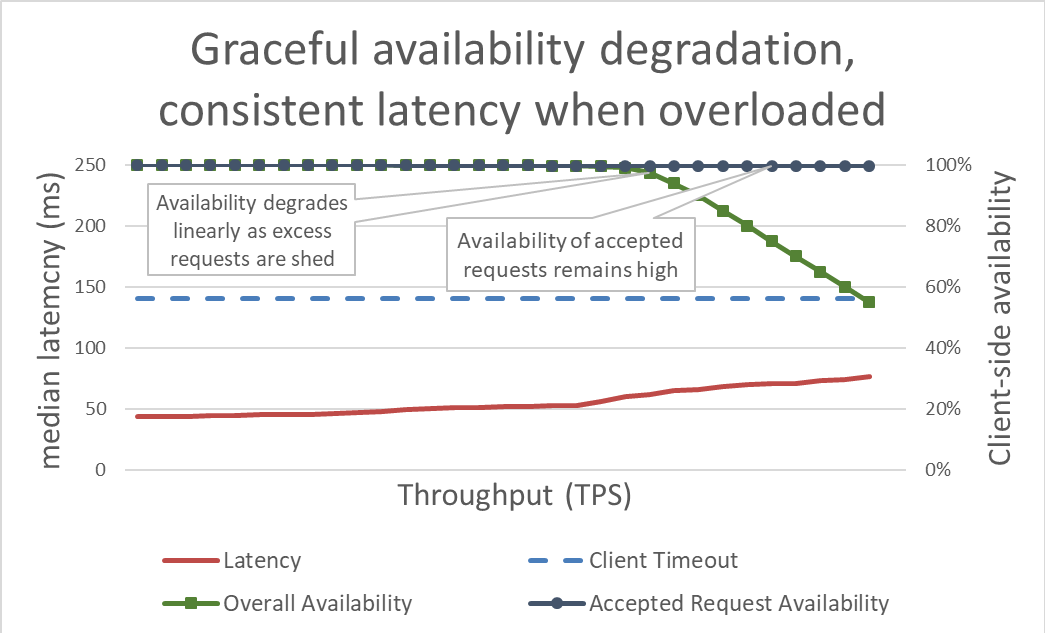
Tenere sotto controllo la latenza tramite la riduzione del carico in eccesso rende il sistema più disponibile. Ma i vantaggi di questo approccio sono difficili da visualizzare nel grafico precedente. La linea di disponibilità complessiva si sposta ancora verso il basso, il che sembra negativo. La chiave è che le richieste che il server ha deciso di accettare rimangono disponibili perché sono state servite rapidamente.
La riduzione del carico consente a un server di mantenere il proprio goodput e di completare il maggior numero possibile di richieste, anche se il throughput offerto aumenta. Tuttavia, l’atto di ridurre il carico non è gratuito, quindi alla fine il server è vittima della legge di Amdahl e il goodput diminuisce.
Test
Quando parlo della riduzione del carico con altri ingegneri, mi piace sottolineare che se non hanno testato il carico del loro servizio fino al punto in cui si interrompe, e ben oltre il punto in cui si interrompe, dovrebbero presumere che il servizio fallirà nel modo meno desiderabile possibile. In Amazon dedichiamo molto tempo a testare il carico dei nostri servizi. La generazione di grafici, come quelli precedenti in questo articolo, ci aiuta a prevedere le prestazioni di sovraccarico e a tenere traccia di come evolviamo nel tempo man mano che apportiamo modifiche ai nostri servizi.
Esistono diversi tipi di test di carico. Alcuni test di carico assicurano che un parco istanze si dimensioni automaticamente all'aumentare del carico, mentre altri utilizzano una dimensione fissa del parco istanze. Se, in un test di sovraccarico, la disponibilità di un servizio diminuisce rapidamente fino a zero all'aumentare del throughput, è un buon segno che il servizio necessiti di ulteriori meccanismi di riduzione del carico. Il risultato ideale del test di carico è che il goodput rimanga a un livello stabile quando il servizio è quasi completamente utilizzato e che rimanga piatto anche quando viene applicato un throughput maggiore.
Strumenti come Chaos Monkey aiutano a eseguire test di ingegneria del caos sui servizi. Ad esempio, possono sovraccaricare la CPU o introdurre la perdita di pacchetti per simulare le condizioni che si verificano durante un sovraccarico. Un'altra tecnica di test che utilizziamo è quella di prendere un test di generazione del carico o un test canary esistente, guidare il carico sostenuto (anziché aumentare il carico) verso un ambiente di test e iniziare a rimuovere i server da quell'ambiente di test. Ciò aumenta il throughput offerto per istanza, quindi può testare il throughput dell'istanza. Questa tecnica per aumentare artificialmente il carico diminuendo le dimensioni del parco istanze è utile per testare un servizio in isolamento, ma non è un sostituto completo per i test di carico completo. Un test di carico completo end-to-end aumenterà anche il carico alle dipendenze di quel servizio, ciò che potrebbe scoprire altri colli di bottiglia.
Durante i test, ci assicuriamo di misurare la disponibilità e la latenza percepite dal client, oltre alla disponibilità e alla latenza sul lato server. Quando la disponibilità sul lato client inizia a diminuire, spingiamo il carico ben oltre quel punto. Se la riduzione del carico funziona, il goodput rimarrà costante anche se il throughput offerto aumenta ben oltre le capacità ridimensionate del servizio.
Il test di sovraccarico è fondamentale prima di esplorare i meccanismi per evitare il sovraccarico. Ogni meccanismo introduce complessità. Ad esempio, considera tutte le opzioni di configurazione nei framework del servizio che ho citato all'inizio dell'articolo e quanto è difficile determinare le impostazioni predefinite. Ogni meccanismo per evitare il sovraccarico aggiunge diverse protezioni e ha un'efficacia limitata. Attraverso i test, un team può rilevare i colli di bottiglia del proprio sistema e determinare la combinazione di protezioni di cui ha bisogno per gestire il sovraccarico.
Visibilità
In Amazon, indipendentemente dalle tecniche che utilizziamo per proteggere i nostri servizi dal sovraccarico, pensiamo attentamente ai parametri e alla visibilità di cui abbiamo bisogno nel momento in cui queste contromisure di sovraccarico diventano operative.
Quando la protezione in caso di brownout rifiuta una richiesta, tale rifiuto riduce la disponibilità di un servizio. Quando il servizio sbaglia e rifiuta una richiesta sebbene abbia capacità (ad esempio, quando il numero massimo di connessioni è impostato troppo basso), genera un falso positivo. Ci impegniamo a mantenere il tasso di falsi positivi di un servizio a zero. Se un team rileva che il tasso di falsi positivi del proprio servizio sia regolarmente diverso da zero, allora o il servizio è sintonizzato in modo troppo sensibile, o i singoli host vengono costantemente e legittimamente sovraccaricati e potrebbe esserci un problema di dimensionamento o di bilanciamento del carico. In casi come questo, potrebbe essere necessario ottimizzare le prestazioni delle applicazioni oppure passare a tipi di istanze di dimensioni più grandi, in grado di gestire gli squilibri di carico in modo più liscio.
In termini di visibilità, quando la riduzione del carico rifiuta le richieste, ci assicuriamo di disporre di strumenti adeguati per sapere chi era il client, quale operazione stava chiamando e qualsiasi altra informazione che ci aiuterà a ottimizzare le nostre misure di protezione. Utilizziamo anche allarmi per rilevare se le contromisure rifiutino eventuali volumi significativi di traffico. In caso di brownout, la nostra priorità è quella di aggiungere capacità e di affrontare l'attuale collo di bottiglia.
C'è un'altra considerazione sottile, ma importante, in merito alla visibilità nella riduzione del carico. Abbiamo scoperto che è importante non inquinare i parametri di latenza dei nostri servizi con la latenza delle richieste non riuscite. Dopotutto, la latenza della riduzione del carico di una richiesta dovrebbe essere estremamente bassa rispetto ad altre richieste. Ad esempio, se un servizio riduce il carico del suo traffico del 60 percento, la latenza mediana del servizio potrebbe sembrare piuttosto sorprendente, anche se la sua latenza di richieste riuscite è pessima, perché è sottostimata a causa delle richieste con esito negativo.
Effetti della riduzione del carico sulla scalabilità automatica e sugli errori nella zona di disponibilità
Se configurata in modo errato, la riduzione del carico può disabilitare la scalabilità automatica reattiva. Prendiamo il seguente esempio: un servizio è configurato per il dimensionamento reattivo basato sulla CPU e ha anche la riduzione del carico configurata per rifiutare le richieste a una destinazione CPU simile. In questo caso, il sistema di riduzione del carico ridurrà il numero di richieste per mantenere basso il carico della CPU e il dimensionamento reattivo non riceverà né otterrà mai un segnale ritardato per avviare nuove istanze.
Teniamo presente anche la logica della riduzione del carico quando impostiamo i limiti di scalabilità automatica per la gestione degli errori nella zona di disponibilità. I servizi sono dimensionati a un punto in cui il valore della capacità di una zona di disponibilità può diventare non disponibile, preservando al contempo i nostri obiettivi di latenza. I team di Amazon guardano spesso a parametri di sistema come la CPU per approssimare la vicinanza di un servizio al raggiungimento del limite di capacità. Tuttavia, con la riduzione del carico, un parco istanze potrebbe essere molto più vicino al punto in cui le richieste verrebbero rifiutate rispetto a quanto indicato dai parametri di sistema e potrebbe non disporre della capacità in eccesso assegnata per gestire un errore nella zona di disponibilità. Con la riduzione del carico, dobbiamo essere assolutamente sicuri di testare i nostri servizi in caso di rottura per comprendere la capacità effettiva e la capacità aggiuntiva del nostro parco istanze in qualsiasi momento.
In effetti, possiamo utilizzare la riduzione del carico per risparmiare sui costi modellando il traffico non di punta e non critico. Ad esempio, se un parco istanze gestisce il traffico del sito Web per amazon.com, potrebbe decidere che il traffico del crawler di ricerca non valga la spesa di essere dimensionato per la ridondanza completa della zona di disponibilità. Tuttavia, siamo molto attenti a questo approccio. Non tutte le richieste hanno lo stesso costo e la dimostrazione che un servizio dovrebbe fornire ridondanza della zona di disponibilità per il traffico umano e allo stesso tempo per ridurre il traffico del crawler in eccesso richiede un'attenta progettazione, test continui e buy-in da parte delle aziende. E se i client di un servizio non sanno che un servizio è configurato in questo modo, il suo comportamento durante un errore nella zona di disponibilità potrebbe apparire come un enorme calo critico della disponibilità invece di una riduzione non critica del carico. Per questo motivo, in un’architettura orientata al servizio, proviamo a spingere questo tipo di modellatura il più presto possibile (ad esempio nel servizio che riceve la richiesta iniziale dal client) invece di cercare di prendere decisioni di assegnazione di priorità globali in tutto lo stack.
Meccanismi di riduzione del carico
Quando si discute della riduzione del carico e di scenari imprevedibili, è anche importante concentrarsi sulle molte condizioni prevedibili che portano al brownout. Su Amazon, i servizi mantengono una capacità in eccesso sufficiente per gestire gli errori nella zona di disponibilità senza dover aggiungere ulteriore capacità. Usano il throttling per garantire l'equità tra i client.
Tuttavia, nonostante queste protezioni e pratiche operative, un servizio ha una certa capacità in determinato momento nel tempo e può quindi sovraccaricarsi per una serie di motivi. Questi motivi includono: aumenti imprevisti del traffico, improvvisa perdita della capacità del parco istanze (per cattive distribuzioni o altro), client che passano da richieste economiche (come letture memorizzate nella cache) a richieste costose (come mancati riscontri nella cache o scritture cache). Quando un servizio diventa sovraccarico, deve terminare le richieste che ha preso in carico; cioè, i servizi devono proteggersi dal brownout. Nel resto di questa sezione, discuteremo alcune delle considerazioni e delle tecniche che abbiamo usato negli anni per gestire il sovraccarico.
Comprendere il costo di rimozione delle richieste
Ci assicuriamo di testare il carico dei nostri servizi ben oltre il punto in cui il goodput rimane a un livello stabile. Uno dei motivi principali di questo approccio è quello di garantire che, quando eliminiamo le richieste durante la riduzione del carico, il costo di rimozione della richiesta sia il più basso possibile. Abbiamo visto che è facile perdere un'istruzione di registro accidentale o un'impostazione del socket, che potrebbe rendere la rimozione di una richiesta molto più costosa di quanto debba essere.
In casi rari, la rimozione rapida di una richiesta può essere più costosa del mantenimento della richiesta. In questi casi, rallentiamo le richieste respinte affinché corrispondano (almeno) alla latenza delle risposte riuscite. Tuttavia, è importante farlo quando il costo del mantenimento delle richieste è il più basso possibile; per esempio, quando non stanno legando un thread dell'applicazione.
Assegnare priorità alle richieste
Quando un server è sovraccarico, ha l'opportunità di valutare le richieste in arrivo per decidere quali accettare e quali rifiutare. La richiesta più importante che un server riceverà è una richiesta di ping da un sistema di bilanciamento del carico. Se il server non risponde alle richieste di ping in tempo, il sistema di bilanciamento del carico smetterà di inviare nuove richieste a quel server per un certo periodo di tempo e il server rimarrà inattivo. E in uno scenario di brownout, l'ultima cosa che vogliamo fare è ridurre le dimensioni dei nostri parchi istanze. Oltre alle richieste di ping, le opzioni di assegnazione di priorità alle richieste variano da servizio a servizio.
Prendiamo l'esempio di un servizio web che fornisce dati per il rendering di amazon.com. È probabile che una chiamata di servizio che supporti il rendering di pagine Web per un crawler dell'indice di ricerca sia meno critica rispetto a una richiesta proveniente da un essere umano. Le richieste del crawler sono importanti da servire, ma idealmente possono essere spostate in un momento non di punta. Tuttavia, in un ambiente complesso come amazon.com in cui un gran numero di servizi collabora, se i servizi utilizzano euristiche di priorità in conflitto, la disponibilità a livello di sistema potrebbe essere compromessa e il lavoro potrebbe essere sprecato.
L'assegnazione di priorità e il throttling possono essere utilizzati insieme per evitare rigidi limiti di throttling pur proteggendo un servizio dal sovraccarico. Su Amazon, nei casi in cui consentiamo ai client di superare i limiti massimi configurati, le richieste in eccesso da parte di questi client potrebbero avere una priorità inferiore rispetto alle richieste all'interno della quota di altri client. Dedichiamo molto tempo a concentrarci sugli algoritmi di posizionamento per ridurre al minimo la probabilità che la capacità di ottimizzazione non sia disponibile, ma dati i compromessi, privilegiamo il carico di lavoro assegnato prevedibile rispetto al carico di lavoro imprevedibile.
Tenere d'occhio l'orologio
Se un servizio è riuscito a soddisfare parzialmente una richiesta e si accorge che il client abbia raggiunto il timeout, può saltare il resto del lavoro e interrompere la richiesta a quel punto. Altrimenti, il server continua a lavorare sulla richiesta e la sua risposta tardiva è come un albero che cade nella foresta. Dal punto di vista del server, ha restituito una risposta corretta. Ma dal punto di vista del client che ha raggiunto il timeout, si è verificato un errore.
Un modo per evitare questo spreco di lavoro è che i client includano suggerimenti di timeout in ogni richiesta, che indichino al server quanto tempo sono disposti ad aspettare. Il server può valutare questi suggerimenti e rimuovere a basso costo le richieste scadute.
Questo suggerimento del timeout può essere espresso come tempo assoluto o come durata. Sfortunatamente, i server nei sistemi distribuiti non sanno notoriamente concordare l'ora esatta. Servizio di sincronizzazione oraria di Amazon compensa sincronizzando gli orologi delle istanze Amazon Elastic Compute Cloud (Amazon EC2) con un parco di orologi atomici e controllati via satellite ridondanti in ciascuna regione AWS. Gli orologi ben sincronizzati sono importanti su Amazon anche ai fini della registrazione. Il confronto tra due file di log su server con orologi non sincronizzati rende la risoluzione dei problemi ancora più difficile di quanto non sia all'inizio.
L'altro modo di "guardare l'orologio" è misurare una durata su una singola macchina. I server possono misurare localmente le durate trascorse perché non hanno bisogno di ottenere consenso con altri server. Sfortunatamente, anche l'espressione dei timeout in termini di durate ha i suoi problemi. Per uno, il timer che usi deve essere monotonico e non deve tornare indietro quando il server si sincronizza con il Network Time Protocol (NTP). Un problema molto più difficile è che per misurare una durata, il server deve sapere quando avviare un cronometro. In alcuni scenari di sovraccarico estremo, enormi volumi di richieste possono essere messi in coda nei buffer TCP (Transmission Control Protocol), quindi al momento in cui il server legge le richieste dai suoi buffer, il client ha già raggiunto il timeout.
Ogni volta che i sistemi di Amazon esprimono suggerimenti di timeout del client, proviamo ad applicarli in modo transitorio. Nei luoghi in cui un'architettura orientata al servizio include più passaggi, propaghiamo la scadenza del "tempo rimanente" tra ciascun passaggio, in modo che un servizio a valle alla fine di una catena di chiamate possa essere consapevole di quanto tempo ha a disposizione per la sua risposta.
Una volta che un server conosce la scadenza del client, c'è la questione di dove applicarla nell'implementazione del servizio. Se un servizio ha una coda di richieste, utilizziamo tale opportunità per valutare il timeout dopo aver rimosso ciascuna richiesta dalla coda. Ma questo è ancora piuttosto complicato, perché non sappiamo quanto tempo potrebbe richiedere la richiesta. Alcuni sistemi mantengono una stima del tempo impiegato dalle richieste API e rimuovono le richieste in anticipo se la scadenza dichiarata dal client supera la stima di latenza. Tuttavia, le cose raramente sono così semplici. Ad esempio, i riscontri nella cache sono più veloci dei mancati riscontri nella cache e lo stimatore non sa se si tratti di un riscontro o di un mancato riscontro anticipato. Oppure le risorse di back-end del servizio potrebbero essere partizionate e solo alcune partizioni potrebbero essere lente. Ci sono molte opportunità di intelligenza, ma è anche possibile che quell'intelligenza si ritorca contro in una situazione imprevedibile.
Per la nostra esperienza, è ancora meglio applicare i timeout dei client sul server piuttosto che non farlo, nonostante le complessità e gli svantaggi. Invece di accumulare richieste e far lavorare il server su richieste che probabilmente non contano più per nessuno, abbiamo trovato utile imporre una durata ("time-to-live") per richiesta e scartare le richieste scadute.
Finire ciò che è stato iniziato
Non vogliamo che alcun lavoro utile vada sprecato, specialmente in un sovraccarico. L'eliminazione del lavoro crea un loop di feedback positivo che aumenta il sovraccarico, poiché i client spesso ritrasmettono una richiesta se un servizio non risponde in tempo. Quando ciò accade, una richiesta che consuma risorse si trasforma in molte richieste che consumano risorse, moltiplicando il carico sul servizio. Quando i client raggiungono il timeout e ritrasmettono la richiesta, spesso smettono di attendere una risposta sulla prima connessione mentre effettuano una nuova richiesta su una connessione separata. Se il server termina la prima richiesta e risponde, il client potrebbe non essere in ascolto, poiché ora è in attesa di una risposta alla sua richiesta ritrasmessa.
Questo problema dello spreco di lavoro è il motivo per cui proviamo a progettare servizi per eseguire lavori limitati. Nei luoghi in cui esponiamo un'API che può restituire un set di dati di grandi dimensioni (o in realtà qualsiasi elenco), lo esponiamo come un'API che supporta la paginazione. Queste API restituiscono risultati parziali e un token che il client può utilizzare per richiedere più dati. Abbiamo scoperto che è più semplice stimare il carico aggiuntivo su un servizio quando il server gestisce una richiesta che ha un limite superiore per la quantità di memoria, la CPU e la larghezza di banda della rete. È molto difficile eseguire il controllo di ammissione quando un server non ha idea di cosa servirà per elaborare una richiesta.
Un'opportunità più sottile per dare priorità alle richieste riguarda il modo in cui i client utilizzano le API di un servizio. Ad esempio, supponiamo che un servizio abbia due API: start() e end(). Per completare il proprio lavoro, i client devono essere in grado di chiamare entrambe le API. In questo caso, il servizio dovrebbe dare la priorità alle richieste end() rispetto alle richieste start(). Se desse la priorità a start(), i client non sarebbero in grado di completare il lavoro che hanno iniziato, dando luogo a brownout.
La paginazione è un altro posto dove si verifica lo spreco di lavoro. Se un client deve fare diverse richieste sequenziali per impaginare i risultati da un servizio e vede un errore dopo la pagina N-1 e scarta i risultati, sta sprecando N-2 chiamate del servizio e tutti i tentativi che ha eseguito lungo il percorso. Ciò suggerisce che, come per le richieste end(), le richieste della prima pagina dovrebbero essere prioritarie rispetto alle richieste di paginazione della pagina successiva. Sottolinea inoltre perché progettiamo servizi per eseguire lavori limitati e non per impaginare all'infinito attraverso un servizio che chiamano durante un'operazione sincrona.
Fare attenzione alle code
È inoltre utile esaminare la durata della richiesta durante la gestione delle code interne. Molte architetture moderne di servizi utilizzano code in memoria per connettere pool di thread per elaborare richieste durante varie fasi del lavoro. È probabile che un framework di servizi Web con un esecutore abbia una coda configurata di fronte. Con qualsiasi servizio basato su TCP, il sistema operativo mantiene un buffer per ciascun socket e tali buffer possono contenere un volume enorme di richieste represse.
Quando estraiamo il lavoro dalle code, sfruttiamo questa opportunità per esaminare per quanto tempo il lavoro è rimasto in coda. Come minimo, proviamo a registrare tale durata nelle metriche del nostro servizio. Oltre a limitare la dimensione delle code, abbiamo scoperto che è estremamente importante stabilire un limite superiore per il periodo di tempo in cui una richiesta in arrivo rimane in una coda e la scartiamo se è troppo vecchia. Ciò consente al server di lavorare su richieste più recenti che hanno maggiori possibilità di successo. Come versione estrema di questo approccio, cerchiamo invece modi per utilizzare una coda LIFO (last in, first out), se il protocollo la supporta. (Il pipelining HTTP/1.1 delle richieste su una determinata connessione TCP non supporta le code LIFO, ma l'HTTP/2 generalmente lo fa.)
I sistemi di bilanciamento del carico possono anche mettere in coda le richieste o le connessioni in arrivo quando i servizi sono sovraccarichi, utilizzando una funzione chiamata code di sovraccarico. Queste code possono portare al brownout, perché quando un server riceve finalmente una richiesta, non ha idea di quanto tempo sia rimasta nella coda. Un'impostazione predefinita generalmente sicura è l'uso di una configurazione spillover, che fallisce rapidamente invece di mettere in coda le richieste in eccesso. Su Amazon, questo apprendimento è stato inserito nella prossima generazione del servizio Elastic Load Balancing (ELB). Il Classic Load Balancer ha utilizzato una coda di sovraccarico, ma Application Load Balancer rifiuta il traffico in eccesso. Indipendentemente dalla configurazione, i team di Amazon monitorano i relativi parametri del sistema di bilanciamento del carico, come la profondità della coda di sovraccarico o il conteggio degli spillover, per i loro servizi.
Per la nostra esperienza, l'importanza di fare attenzione alle code non è mai sopravvalutata. Sono spesso sorpreso di trovare code in memoria dove non ho intuitivamente pensato di cercarle, ad esempio in sistemi e librerie da cui dipendo. Quando esamino i sistemi, trovo che sia utile supporre che ci siano da qualche parte code che non ho scoperto ancora. Ovviamente, i test di sovraccarico forniscono informazioni più utili rispetto all'analisi del codice, purché riesca a trovare i casi di test realistici giusti.
Proteggere da sovraccarico nei livelli inferiori
I servizi sono costituiti da diversi livelli: dai sistemi di bilanciamento del carico, ai sistemi operativi con funzionalità netfilter e iptables, ai framework del servizio e al codice, e ogni livello offre alcune funzionalità per proteggere il servizio.
I proxy HTTP, come NGINX, spesso supportano una funzionalità del numero massimo di connessioni (max_conns) per limitare il numero di richieste o connessioni attive che passeranno al server back-end. Questo può essere un meccanismo utile, ma abbiamo imparato a usarlo come ultima risorsa invece dell'opzione di protezione predefinita. Con i proxy, è difficile dare priorità al traffico importante e il monitoraggio del numero di richieste in esecuzione non elaborate a volte fornisce informazioni inesatte sul fatto che un servizio sia effettivamente sovraccarico.
All'inizio di questo articolo, ho descritto una sfida del mio periodo di lavoro nel team di Service Frameworks. Stavamo provando a fornire ai team di Amazon un valore predefinito consigliato per il numero massimo di connessioni da configurare sui loro sistemi di bilanciamento del carico. Alla fine, abbiamo suggerito ai team di impostare il numero massimo di connessioni per il sistema di bilanciamento del carico e il proxy ad un livello elevato e di consentire al server di implementare algoritmi per la riduzione del carico più accurati, basati sulle informazioni locali. Tuttavia, era anche importante che il valore massimo delle connessioni non superasse il numero di thread del listener, di processi del listener o di descrittori di file su un server, in modo che il server disponesse delle risorse per gestire le richieste critiche di controllo dello stato dal sistema di bilanciamento del carico.
Le funzionalità del sistema operativo per limitare l'utilizzo delle risorse del server sono potenti e possono essere utili da adoperare in situazioni di emergenza. E poiché sappiamo che può verificarsi un sovraccarico, ci assicuriamo di prepararci utilizzando i runbook giusti con comandi specifici pronti. L'utilità iptables può porre un limite superiore al numero di connessioni che il server accetterà e può rifiutare le connessioni in eccesso in modo molto più conveniente rispetto a qualsiasi processo del server. Può anche essere configurata con controlli più sofisticati, ad esempio consentire nuove connessioni a una velocità limitata o addirittura consentire una velocità di connessione limitata o un numero di connessioni limitato per indirizzo IP di origine. I filtri IP di origine sono potenti, ma non si applicano con i sistemi di bilanciamento del carico tradizionali. Tuttavia, un Network Load Balancer ELB conserva l'IP di origine dell'intermediario anche a livello di sistema operativo attraverso la virtualizzazione della rete, facendo funzionare le regole di iptables e i filtri IP di origine come previsto.
Proteggere per livelli
In alcuni casi, un server esaurisce le risorse persino per rifiutare le richieste senza rallentare. Tenendo questo in mente, osserviamo tutti i passaggi tra un server e i suoi client per vedere come possono cooperare e aiutare a ridurre il carico in eccesso. Ad esempio, diversi servizi AWS includono opzioni di riduzione del carico per impostazione predefinita. Quando gestiamo un servizio con Amazon API Gateway, possiamo configurare una percentuale massima di richieste accettabile da qualsiasi API. Quando i nostri servizi sono supportati da API Gateway, un Application Load Balancer o Amazon CloudFront, possiamo configurare AWS WAF per eliminare il traffico in eccesso su un numero di dimensioni.
La visibilità crea una tensione difficile. Il rifiuto anticipato è importante perché è il modo più economico per eliminare il traffico in eccesso, ma ha un costo per la visibilità. Questo è il motivo per cui proteggiamo per livelli: lasciare che un server prenda in carico più di quello che può lavorare ed elimini l'eccesso e registrare abbastanza informazioni per sapere quale traffico sta eliminando. Dal momento che il server può eliminare solo un volume elevato di traffico, ci affidiamo al livello che lo precede per proteggerlo da volumi estremi di traffico.
Pensare al sovraccarico in modo diverso
In questo articolo, abbiamo discusso di come la necessità di ridurre il carico derivi dal fatto che i sistemi diventano più lenti man mano che ricevono più lavoro simultaneo, mentre forze come i limiti delle risorse e il conflitto entrano in gioco. Il loop di feedback del sovraccarico è guidato dalla latenza, che alla fine provoca sprechi di lavoro, l'amplificazione della frequenza della richiesta e ancora più sovraccarico. È importante evitare questa forza, guidata dalla Legge universale sulla scalabilità e dalla legge di Amdahl, riducendo il carico in eccesso e mantenendo prestazioni prevedibili e coerenti di fronte al sovraccarico. Concentrarsi su prestazioni prevedibili e coerenti è un principio di progettazione chiave su cui sono basati i servizi di Amazon.
Ad esempio, Amazon DynamoDB è un servizio di database che offre prestazioni e disponibilità prevedibili su vasta scala. Anche se un carico di lavoro esplode rapidamente e supera le risorse assegnate, DynamoDB mantiene una latenza del goodput prevedibile per quel carico di lavoro. Fattori come il dimensionamento automatico di DynamoDB e la capacità adattativa e on demand reagiscono rapidamente per aumentare i tassi di goodput per adattarsi all’aumento del carico di lavoro. Durante quel periodo, il goodput rimane costante, mantenendo un servizio nei livelli sopra DynamoDB con prestazioni prevedibili e migliorando la stabilità dell'intero sistema.
AWS Lambda fornisce un esempio ancora più ampio di attenzione alle prestazioni prevedibili. Quando utilizziamo Lambda per implementare un servizio, ogni chiamata API viene eseguita nel proprio ambiente di esecuzione con quantità consistenti di risorse di calcolo assegnate ad esso e quell'ambiente di esecuzione lavora in quel momento solo su quella richiesta. Ciò differisce da un paradigma basato su server, in cui un determinato server funziona su più API.
L'isolamento di ciascuna chiamata API alle proprie risorse indipendenti (calcolo, memoria, disco, rete) eluderà in qualche modo la legge di Amdahl, poiché le risorse di una chiamata API non saranno in contrasto con le risorse di un'altra chiamata API. Pertanto, se il throughput supera il goodput, il goodput rimarrà piatto invece di diminuire come avviene in un ambiente basato su server più tradizionale. Questa non è una panacea, poiché le dipendenze possono rallentare e causare un aumento della concorrenza. Tuttavia, in questo scenario, almeno i tipi di conflitto di risorse sull'host discussi in questo articolo non verranno applicati.
Questo isolamento delle risorse è un vantaggio piuttosto sottile, ma importante, degli ambienti di elaborazione moderni e senza server come AWS Fargate, Amazon Elastic Container Service (Amazon ECS) e AWS Lambda. In Amazon, abbiamo scoperto che l'implementazione della riduzione del carico richiede molto lavoro, dall'ottimizzazione dei pool di thread, alla scelta della configurazione perfetta per il numero massimo di connessioni del sistema di bilanciamento del carico. I valori predefiniti sensibili per questi tipi di configurazioni sono difficili o impossibili da trovare, poiché dipendono dalle caratteristiche operative uniche di ciascun sistema. Questi ambienti di elaborazione più recenti e senza server forniscono l'isolamento delle risorse di livello inferiore ed espongono manopole di livello superiore, come i controlli del throttling e della concorrenza, per la protezione da sovraccarico. In un certo senso, invece di inseguire il valore di configurazione predefinito perfetto, siamo in grado di eludere completamente quella configurazione e di proteggere da categorie di sovraccarico senza alcuna configurazione.
Ulteriori letture
- Legge universale sulla scalabilità
- Legge di Amdahl
- Architettura guidata dagli eventi (SEDA, Staged event-driven architecture)
- Legge di Little (descrive la concorrenza in un sistema e come determinare la capacità dei sistemi distribuiti)
- Racconti sulla legge di Little, il blog di Marc
- Presentazione di Elastic Load Balancing Deep Dive e Best Practice a re:Invent 2016 (descrive l’evoluzione di Elastic Load Balancing per smettere di accodare le richieste in eccesso)
- Burgess, Thinking in Promises: Designing Systems for Cooperation, O’Reilly Media, 2015
Informazioni sull’autore
David Yanacek è un ingegnere capo che lavora su AWS Lambda. David è stato sviluppatore software presso Amazon dal 2006 e ha lavorato in precedenza su Amazon DynamoDB e AWS IoT, oltre che su framework di servizi web interni e sui sistemi di automazione delle operazioni di flotta. Una delle attività preferite di David al lavoro è l’analisi dei log e il vaglio dei parametri operativi per scoprire come rendere sempre più fluida l’esecuzione dei sistemi nel tempo.

Hai trovato quello che cercavi?
Facci sapere la tua opinione per aiutarci a migliorare la qualità dei contenuti delle nostre pagine