Cos'è l'etichettatura dei dati?
Cos'è l'etichettatura dei dati?
Nell'apprendimento automatico, l'etichettatura dei dati è il processo di identificazione dei dati grezzi (immagini, file di testo, video, ecc.) e l'aggiunta di una o più etichette significative e informative per fornire un contesto in modo che un modello di apprendimento automatico possa imparare da essi. Ad esempio, le etichette potrebbero indicare se una foto contiene un uccello o un'auto, quali parole sono state pronunciate in una registrazione audio o se una radiografia contiene un tumore. L‘etichettatura dei dati può essere utilizzata per vari casi d'uso, tra cui visione artificiale, elaborazione del linguaggio naturale e riconoscimento vocale.
Come funziona l'etichettatura dei dati?
Oggi, la maggior parte dei modelli pratici di machine learning utilizza l'apprendimento supervisionato, che applica un algoritmo per mappare un input su un output. Affinché l'apprendimento supervisionato funzioni, è necessario un set di dati etichettato da cui il modello possa apprendere informazioni per prendere decisioni corrette. L'etichettatura dei dati inizia in genere chiedendo agli umani di esprimere giudizi su un determinato dato non etichettato. Ad esempio, agli etichettatori potrebbe essere chiesto di taggare tutte le immagini in un set di dati in cui l'affermazione «la foto contiene un uccello» è vera. L'etichettatura può essere approssimativa come un semplice sì/no o granulare come l'identificazione dei pixel specifici nell'immagine associata all'uccello. Il modello di machine learning utilizza etichette fornite dall'uomo per apprendere i modelli sottostanti in un processo chiamato «addestramento dei modelli». Il risultato è un modello addestrato che può essere utilizzato per fare previsioni su nuovi dati.
Nel machine learning, un set di dati correttamente etichettato che si utilizza come standard oggettivo per addestrare e valutare un determinato modello viene spesso chiamato «ground truth». L'accuratezza del modello addestrato dipenderà dall'accuratezza della ground truth, quindi è essenziale dedicare tempo e risorse per garantire un'etichettatura dei dati estremamente accurata.
Quali sono alcuni tipi comuni di etichettatura dei dati?
Visione computerizzata
Quando crei un sistema di visione artificiale, bisogna prima etichettare immagini, pixel o punti chiave o creare un bordo che racchiuda completamente un'immagine digitale, noto come riquadro di delimitazione, per generare il set di dati di addestramento. Ad esempio, è possibile classificare le immagini in base al tipo di qualità (come le immagini del prodotto rispetto alle immagini dello stile di vita) o al contenuto (cosa c'è effettivamente nell'immagine stessa) oppure puoi segmentare un'immagine a livello di pixel. È quindi possibile utilizzare questi dati di addestramento per creare un modello di visione artificiale che può essere utilizzato per classificare automaticamente le immagini, rilevare la posizione degli oggetti, identificare i punti chiave di un'immagine o segmentare un'immagine.
Servizio di elaborazione di linguaggio naturale
L'elaborazione del linguaggio naturale richiede innanzitutto di identificare manualmente le sezioni di testo importanti o di contrassegnare il testo con etichette specifiche per generare il set di dati di addestramento. Ad esempio, potresti voler identificare il sentimento o l'intento di un testo, identificare parti del discorso, classificare i nomi propri come luoghi e persone e identificare il testo in immagini, PDF o altri file. A tale scopo, è possibile disegnare riquadri di delimitazione attorno al testo e quindi trascrivere manualmente il testo nel set di dati di addestramento. I modelli di elaborazione del linguaggio naturale vengono utilizzati per l'analisi delle emozioni, il riconoscimento delle entità nominali e il riconoscimento ottico dei caratteri.
Elaborazione audio
L'elaborazione audio converte tutti i tipi di suoni come il parlato, i rumori della fauna selvatica (latrati, fischi o cinguettii) e i suoni di costruzione (vetri rotti, scansioni o allarmi) in un formato strutturato in modo da poter essere utilizzato nel machine learning. L'elaborazione audio spesso richiede la trascrizione manuale in testo scritto. Da lì, è possibile scoprire informazioni più approfondite sull'audio aggiungendo tag e classificando l'audio. Questo audio classificato diventa il tuo set di dati di addestramento.
Quali sono alcune best practice per l'etichettatura dei dati?
Esistono molte tecniche per migliorare l'efficienza e l'accuratezza dell'etichettatura dei dati. Alcune di queste tecniche includono:
- Interfacce di attività intuitive e semplificate per ridurre al minimo il carico cognitivo e il cambio di contesto per gli etichettatori umani.
- Il consenso dell'etichettatore per aiutare a contrastare gli errori/le distorsioni dei singoli annotatori. Il consenso dell'etichettatore prevede l'invio di ciascun oggetto del set di dati a più annotatori e il consolidamento delle loro risposte (chiamate «annotazioni») in un'unica etichetta.
- Il controllo delle etichette per verificare l'accuratezza delle etichette e aggiornarle se necessario.
- L'apprendimento attivo per rendere più efficiente l'etichettatura dei dati utilizzando il machine learning e per identificare i dati più utili da etichettare dagli umani.
Come è possibile eseguire l'etichettatura dei dati in modo efficiente?
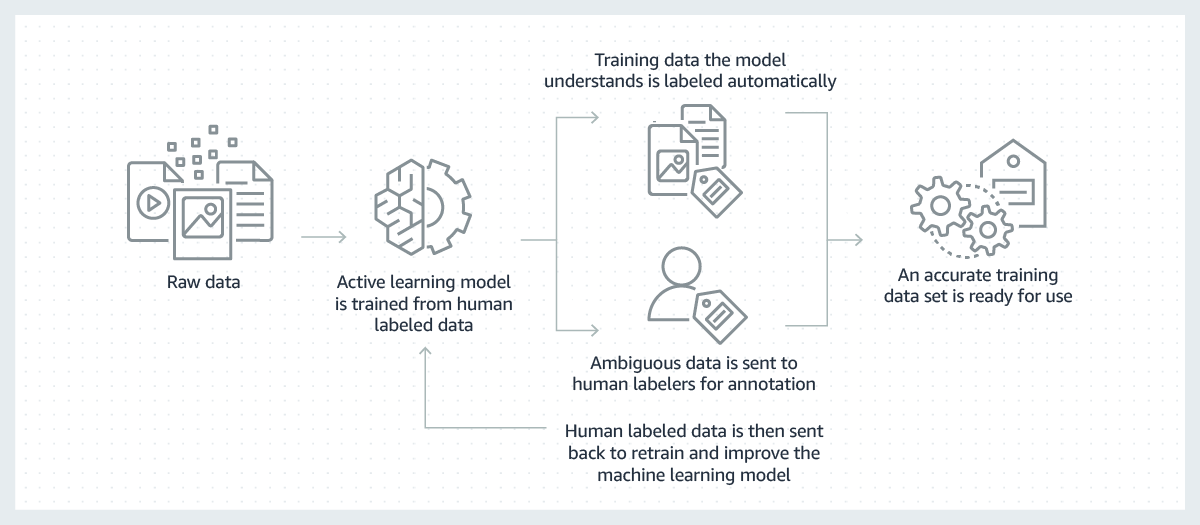
I modelli di machine learning di successo sono creati sulla base di grandi volumi di dati di formazione di alta qualità. Tuttavia, il processo di creazione di dati di addestramento necessari alla formazione di questi modelli è spesso oneroso, articolato e richiede molto tempo. Oggi, la maggior parte dei modelli formati richiede un'etichetta manuale da parte di un umano che consente al modello di imparare a fare scelte corrette. Per superare questa sfida, l'etichettatura può essere resa più efficiente utilizzando un modello di machine learning per etichettare automaticamente i dati.
In questo processo, un modello di machine learning per l'etichettatura dei dati viene prima addestrato su un sottoinsieme dei dati non elaborati che sono stati etichettati dagli esseri umani. Se il modello di etichettatura ha un alto livello di confidenza nei risultati raggiunti, sulla base della capacità di apprendimento mostrato finora, applicherà etichette ai dati grezzi in modo automatico. Qualora invece il modello non confidasse molto nei risultati, passerà i dati a lavoratori umani affinché li etichettino. Le etichette generate dall'uomo vengono quindi restituite al modello di etichettatura affinché possa imparare e migliorare la sua capacità di etichettare automaticamente il successivo set di dati grezzi. Nel tempo, il modello è stato ed è in grado di etichettare sempre più dati in modo automatico e dunque accelerare la creazione di set di dati di addestramento.
In che modo AWS può supportare i tuoi requisiti di etichettatura dei dati?
Amazon SageMaker Ground Truth riduce in modo significativo il tempo e gli sforzi necessari per la creazione di set di dati addestrati. SageMaker Ground Truth offre accesso a etichettatori umani pubblici e privati e fornisce loro flussi di lavoro e interfacce integrati per attività comuni di etichettatura. Iniziare a usare SageMaker Ground Truth è facile. Il tutorial Getting Started può essere utilizzato per creare il tuo primo processo di etichettatura in pochi minuti.
Inizia oggi stesso a utilizzare l'etichettatura dei dati su AWS creando un account.
Fasi successive su AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages