Cos'è l'apprendimento per rinforzo?
Cos'è il consolidamento dell'apprendimento?
Il reinforcement learning (RL) è una tecnica di machine learning (ML) che addestra il software a prendere decisioni per ottenere i risultati più ottimali. Imita il processo di apprendimento basato su tentativi ed errori utilizzato dagli esseri umani usano per raggiungere i propri obiettivi. Le operazioni software che mirano a raggiungere l'obiettivo ricevono un rinforzo, mentre le operazioni che deviano dall'obiettivo vengono ignorate.
Gli algoritmi di RL utilizzano un paradigma di ricompensa e penalità durante l'elaborazione dei dati. Imparano dal feedback di ogni operazione e scoprono da soli i migliori percorsi di elaborazione per raggiungere i risultati finali. Gli algoritmi sono anche in grado di ritardare la gratificazione. La strategia complessivamente ottimale può richiedere sacrifici a breve termine, quindi l'approccio migliore che scoprono può includere alcune penalità o fare marcia indietro lungo il percorso. RL è un metodo potente per aiutare i sistemi di intelligenza artificiale (AI) a raggiungere risultati ottimali in ambienti invisibili.
Quali sono i vantaggi dell'apprendimento per rinforzo?
L'apprendimento per rinforzo (RL) offre molti vantaggi. Tuttavia, i tre di seguito spesso sono i più apprezzati.
È eccellente negli ambienti complessi
Gli algoritmi di RL possono essere utilizzati in ambienti complessi che presentano molte regole e dipendenze. Nello stesso ambiente, un essere umano potrebbe non essere in grado di determinare il percorso migliore da intraprendere, anche con una conoscenza avanzata dell'ambiente. Invece, gli algoritmi di RL senza modelli si adattano rapidamente agli ambienti in continua evoluzione e trovano nuove strategie per ottimizzare i risultati.
Richiede una minore interazione umana
Negli algoritmi di ML tradizionali, gli esseri umani devono etichettare le coppie di dati per dirigere l'algoritmo. Quando si utilizza un algoritmo di RL, ciò non è necessario poiché apprende autonomamente. Allo stesso tempo, offre meccanismi per integrare il feedback umano, permettendo di avvalersi di sistemi che si adattano alle preferenze, alle competenze e alle correzioni umane.
Consente di ottimizzare per gli obiettivi nel lungo termine
L'RL si concentra intrinsecamente sulla massimizzazione della ricompensa nel lungo termine, il che lo rende adatto a scenari in cui le operazioni hanno conseguenze dall'effetto prolungato. Grazie alla capacità di apprendere dalle ricompense posticipate, è particolarmente adatto per le situazioni del mondo reale in cui il feedback non è immediatamente disponibile per ogni passaggio.
Ad esempio, le decisioni sul consumo o sull'accumulo dell'energia potrebbero avere conseguenze nel lungo termine. L'RL può essere utilizzato per ottimizzare l'efficienza energetica e i costi nel lungo termine. Con architetture appropriate, gli agenti di RL possono anche generalizzare le strategie apprese su attività simili ma non identiche.
Quali sono i casi d'uso dell'apprendimento per rinforzo?
L'apprendimento per rinforzo (RL) può essere applicato a un'ampia gamma di casi d'uso reali. Di seguito riportiamo alcuni esempi.
Personalizzazione del marketing
Nelle applicazioni come i sistemi di raccomandazione, l'RL può personalizzare i suggerimenti per i singoli utenti in base alle loro interazioni. Questo consente di offrire esperienze più personalizzate. Ad esempio, un'applicazione può mostrare a un utente annunci appositamente scelti sulla base di alcune informazioni demografiche. Con ogni interazione pubblicitaria, l'applicazione apprende quali annunci mostrare all'utente per ottimizzare le vendite dei prodotti.
Soluzioni di ottimizzazione
I metodi di ottimizzazione tradizionali risolvono i problemi valutando e confrontando le possibili soluzioni sulla base di determinati criteri. Al contrario, l'RL implica l'utilizzo delle interazioni per individuare, nel corso del tempo, le soluzioni di livello ottimale o che vi si avvicinano maggiormente.
Ad esempio, un sistema di ottimizzazione della spesa nel cloud applica l'RL per adattarsi alle mutevoli esigenze di risorse e per selezionare i tipi, le quantità e le configurazioni di istanze ottimali. Prende decisioni in base a fattori come l'infrastruttura cloud attuale e disponibile, la spesa e l'utilizzo.
Previsioni finanziarie
Le dinamiche dei mercati finanziari sono complesse, con proprietà statistiche che cambiano nel tempo. Gli algoritmi di RL possono ottimizzare i rendimenti nel lungo termine valutando i costi delle transazioni e consentendo l'adattamento ai cambiamenti del mercato.
Ad esempio, un algoritmo potrebbe osservare le regole e gli schemi del mercato azionario prima di testare le operazioni e registrare le ricompense associate. Quindi, potrebbe creare dinamicamente una funzione di valore e sviluppare una strategia per massimizzare i profitti.
Come funziona l'apprendimento per rinforzo?
Il processo di apprendimento per rinforzo (RL) degli algoritmi è simile all'apprendimento per rinforzo animale e umano nel campo della psicologia comportamentale. Ad esempio, un bambino scopre che potrebbe ricevere le lodi dei genitori se aiuta un fratello o pulisce. Se invece lancia giocattoli oppure urla, potrebbe ottenere reazioni negative. Presto, il bambino impara quale combinazione di attività porta alla ricompensa finale.
Un algoritmo RL imita un processo di apprendimento simile. Sperimenta diverse attività per apprendere i valori negativi e positivi associati, utili ad ottenere la ricompensa finale.
Concetti chiave
Per capire l'apprendimento per rinforzo, è quindi importante familiarizzare con alcuni concetti chiave:
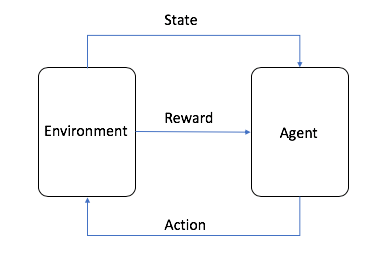
- L'agente è l'algoritmo ML (o il sistema autonomo)
- L'ambiente è lo spazio problematico adattivo con attributi come variabili, valori limite, regole e azioni valide
- L'azione è un passaggio che l'agente RL compie per navigare nell'ambiente
- Lo stato è l'ambiente in un determinato momento
- La ricompensa è il valore positivo, negativo o zero, in altre parole, la ricompensa o la punizione per aver intrapreso un'azione
- La ricompensa cumulativa è la somma di tutte le ricompense o il valore finale
Nozioni di base sull'algoritmo
L'apprendimento per rinforzo si basa sul processo decisionale di Markov, un modello matematico del processo decisionale che utilizza fasi temporali discrete. In ogni fase, l'agente esegue una nuova azione che si traduce in un nuovo stato dell'ambiente. Allo stesso modo, lo stato attuale viene attribuito alla sequenza di azioni precedenti.
Attraverso tentativi ed errori durante lo spostamento nell'ambiente, l'agente crea una serie di regole o policy if-then. Le policy lo aiutano a decidere quale azione intraprendere successivamente per ottenere una ricompensa cumulativa ottimale. L'agente deve anche scegliere tra un'ulteriore esplorazione dell'ambiente per apprendere nuove ricompense stato-azione o selezionare azioni note ad alto rendimento da un determinato stato. Questo processo si chiama equilibrio tra esplorazione e sfruttamento.
Quali sono i tipi di algoritmi dell'apprendimento per rinforzo?
Nell'apprendimento per rinforzo (RL) vengono utilizzati vari algoritmi, come il Q-learning, i metodi di gradiente delle policy, i metodi Monte Carlo e l'apprendimento delle differenze temporali. Il deep RL è l'applicazione di reti neurali profonde all'apprendimento per rinforzo. Un esempio di algoritmo di deep RL è il Trust Region Policy Optimization (TRPO).
Tutti questi algoritmi possono essere raggruppati in due grandi categorie.
RL basato su modelli
Generalmente, l'RL basato su modelli viene impiegato laddove gli ambienti sono ben definiti e immutabili, e qualora sia difficile effettuare test in ambienti reali.
L'agente parte dal creare una rappresentazione interna (modello) dell'ambiente. Per creare questo modello utilizza il seguente processo:
- Compie operazioni all'interno dell'ambiente e prende nota del nuovo stato e del valore della ricompensa.
- Associa la transizione tra operazione-stato al valore della ricompensa.
Una volta completato il modello, l'agente simula sequenze di operazioni basandosi sulla probabilità di ricompense cumulative ottimali. Quindi, assegna ulteriormente valori a tali sequenze di operazioni. A questo punto l'agente sviluppa varie strategie all'interno dell'ambiente per raggiungere l'obiettivo finale desiderato.
Esempio
Prendiamo il caso di un robot che impara a navigare all'interno di un edificio sconosciuto al fine di raggiungere una stanza specifica. Inizialmente, il robot esplora liberamente gli ambienti e crea un modello interno (o mappa) dell'edificio. Ad esempio, potrebbe scoprire che spostandosi in avanti di 10 metri dall'ingresso principale incontra un ascensore. Una volta realizzata la mappa, può creare una serie di sequenze di percorsi più brevi tra gli ambienti che visita frequentemente nell'edificio.
RL senza modelli
Quando l'ambiente è ampio, complesso e non facilmente descrivibile, è preferibile utilizzare l'RL senza modelli. Tale apprendimento è ideale anche quando l'ambiente è sconosciuto e in evoluzione, e i test basati sull'ambiente non presentano svantaggi rilevanti.
L'agente non crea un modello interno dell'ambiente e delle sue dinamiche. Al contrario, utilizza un approccio basato su tentativi ed errori all'interno dell'ambiente. Per sviluppare una policy, assegna punteggi alle coppie di operazione-stato (e alle sequenze di coppie di operazione-stato) e ne prende nota.
Esempio
Prendiamo il caso di un'auto a guida autonoma che deve destreggiarsi nel traffico cittadino. Strade, schemi di traffico, comportamento dei pedoni e innumerevoli altri fattori possono rendere l'ambiente estremamente dinamico e complesso. Nelle fasi iniziali, i team specializzati nell'intelligenza artificiale addestrano il veicolo in un ambiente simulato. Il veicolo agisce in base al suo stato attuale e ottiene ricompense o penalità.
Con il passare del tempo e percorrendo milioni di chilometri in diversi scenari virtuali, il veicolo impara a capire quali operazioni sono le migliori per ogni stato, senza bisogno di modellare esplicitamente le dinamiche del traffico nella loro interezza. Quando viene introdotto nel mondo reale, il veicolo utilizza la policy acquisita pur continuando a perfezionarla con nuovi dati.
Qual è la differenza tra machine learning per rinforzo, supervisionato e non supervisionato?
L'apprendimento supervisionato, l'apprendimento non supervisionato e l'apprendimento per rinforzo (RL), pur essendo tutti algoritmi di ML nel campo dell'IA, presentano alcune differenze.
Ulteriori informazioni sull'apprendimento supervisionato e non supervisionato »
Confronto tra apprendimento per rinforzo e apprendimento supervisionato
Nell'apprendimento supervisionato, l'utente definisce sia l'input sia l'output associato previsto. Ad esempio, dopo aver fornito una serie di immagini etichettate come cani o gatti, l'algoritmo dovrebbe essere in grado di identificare una nuova immagine di animale come cane o gatto.
Gli algoritmi di apprendimento supervisionato apprendono i modelli e le relazioni esistenti tra le coppie di input e di output. Quindi, prevedono i risultati sulla base dei nuovi dati di input. Questo tipo di apprendimento richiede un supervisore, in genere un essere umano, che etichetti ogni record di dati in un set di dati di addestramento sotto forma di un output.
Al contrario, l'RL ha un obiettivo finale ben definito sotto forma di un risultato desiderato, ma richiede che un supervisore etichetti in anticipo i dati associati. Durante l'addestramento, invece di provare a mappare gli input con gli output noti, mappa gli input con i possibili risultati. Premiando i comportamenti desiderati, consente di dare maggior peso ai risultati migliori.
Confronto tra apprendimento per rinforzo e apprendimento non supervisionato
Gli algoritmi di apprendimento non supervisionato ricevono input senza che vengano definiti output specifici durante il processo di addestramento. Individuano modelli e relazioni nascosti all'interno dei dati utilizzando mezzi statistici. Ad esempio, se si fornisce una serie di documenti, l'algoritmo potrebbe raggrupparli in categorie che individua in base alle parole presenti nei testi. Non si ottengono risultati specifici, bensì una serie di intervalli.
Al contrario, l'RL ha un obiettivo finale predeterminato. Sebbene adotti un approccio esplorativo, le esplorazioni vengono continuamente convalidate e migliorate per aumentare la probabilità di raggiungere l'obiettivo finale. Può insegnare a sé stesso a raggiungere risultati molto specifici.
Quali sono le sfide dell'apprendimento per rinforzo?
Sebbene le applicazioni di apprendimento per rinforzo (RL) abbiano le potenzialità di cambiare il mondo, i loro algoritmi non sono di facile implementazione.
Fattibilità
Sperimentare sistemi di ricompensa e penalità potrebbe non essere pratico nella realtà. Ad esempio, testare un drone nel mondo reale senza averlo prima provato in un simulatore potrebbe comportare la rottura di un numero significativo di velivoli. Gli ambienti del mondo reale cambiano spesso, in modo significativo e con un preavviso limitato: ciò può rendere più difficile, per l'algoritmo, dimostrarsi efficace nella pratica.
Interpretabilità
Come ogni campo della scienza, anche la data science conduce ricerche e persegue risultati conclusivi per stabilire standard e procedure. A fini di dimostrabilità e replica, i data scientist preferiscono sapere come è stata raggiunta una determinata conclusione.
In presenza di algoritmi di RL complessi, può essere difficile stabilire i motivi per cui i passaggi sono stati eseguiti in una particolare sequenza. Quali delle operazioni della sequenza hanno portato al risultato finale ottimale? Può essere difficile stabilirlo, il che causa problemi di implementazione.
In che modo AWS può supportare l'apprendimento per rinforzo?
Amazon Web Services (AWS) offre molte soluzioni che semplificano lo sviluppo, l'addestramento e l'implementazione di algoritmi di apprendimento per rinforzo (RL) per applicazioni del mondo reale.
Con Amazon SageMaker, sviluppatori e data scientist possono sviluppare modelli RL scalabili in modo rapido e semplice. È possibile combinare un framework di deep learning, come TensorFlow o Apache MXNet, un kit di strumenti di RL, come RL Coach o RLlib, e un ambiente in cui imitare uno scenario reale, per poi utilizzarlo per creare e testare i vari modelli.
Con AWS RoboMaker, gli sviluppatori possono eseguire, scalare e automatizzare la simulazione con algoritmi RL per la robotica senza requisiti di infrastruttura.
Fai esperienza pratica con AWS DeepRacer, l'auto da corsa completamente autonoma in scala 1/18. Vanta un ambiente cloud completamente configurato utilizzabile per addestrare i propri modelli di RL e specifiche configurazioni di rete neurale.
Inizia a usare il reinforcement learning su AWS creando un account oggi stesso.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages