Amazon Web Services ブログ
AUMOVIO が Amazon Bedrock 搭載のエージェント型コーディングアシスタントでソフトウェア開発を強化
本記事は2026年1月15日に公開されたAUMOVIO Boosts Software Development with an Agentic Coding Assistant Powered by Amazon Bedrockを翻訳したものです。
本ブログ記事では、AUMOVIO が Amazon Web Services (AWS) のサービスと知見を活用して、Software-Defined Vehicle (SDV) 領域における革新的な自動車向けコーディングアシスタントを開発した事例をご紹介します。AUMOVIO のソリューションは、複数の AI モデルを活用して開発ライフサイクルの各工程を加速させながら、自動車業界の標準と AUMOVIO 独自のコーディングベストプラクティスに準拠しています。可能な限りコードを再利用し、変更を最小限に抑えることで、このアシスタントは V 字モデルの他の工程に必要な作業を大幅に削減します。 AUMOVIO とその AWS 上の SDV ソリューションの詳細については、こちらをご覧ください。
背景
車両がますますソフトウェアにより定義される中、自動車メーカーは複雑化するソフトウェア、イノベーションサイクルの高速化、厳格な品質要件という困難に直面しています。ハードウェア、拠点ごとのチーム、手作業に依存して構築された従来の開発手法は、制約となりつつあります。自動車メーカーは、現在世界中の拠点で勤務する数千人のエンジニアと連携しながら、様々な観点で検証が必要な膨大なコードベースを管理しなければなりません。さらに、開発チームは AUTOSAR、MISRA-C/C++ ガイドラインなどのドメイン固有のソフトウェア開発標準に加え、独自の社内標準にも準拠する必要があります。AUMOVIO の開発チームは、自社の組込みシステムプロセスをこの新しい現実に適応させるというプレッシャーにさらされています。
AUMOVIO は自動車向けのアプリケーションの厳格な基準を維持しながら、チームの生産性を向上させるインテリジェントなソリューションを求めて 、AWS と協業することにしました。
課題設定
自動車のベストプラクティスと規制によりよく適合させるため、AUMOVIO は V 字モデルに従ってソフトウェアを開発しています。各工程に費やされた工数を示す膨大な過去データのおかげで、AUMOVIO は効率化余地が最も高い工程を特定することができました。AWS の支援を受けて、AUMOVIO チームは以下を生成できるコーディングアシスタントの開発に取り組むことにしました:
- システム設計から自動車向けメソッド本体を生成(コーディングアシスタントの第 1 弾)
- システム設計からユニットテストを生成(コーディングアシスタントの第 2 弾)
ソリューションの検討
AIコーディングアシスタントの実現可能性を検証するため、AUMOVIO は AWS の支援の下でハッカソンを開催しました。まず、AUMOVIO チームは RAG ベースのアプローチを試し、コードベースをベクトルストアに保存し、Amazon Bedrock(サードパーティプロバイダーと Amazon の基盤モデルを簡単に使用できるフルマネージドサービス)を使用して、取得したチャンクに基づいてコードを生成しました。しかし、テストの結果、セマンティック検索では単一のクエリで与えられたタスクに関連するコードを取得できないことが判明しました。このアプローチの代わりに、チームはエージェント型アプローチを採用しました。このアプローチでは、コーディングアシスタント(強力な推論能力を持つモデルによって駆動)がコードベースから関連するコードコンテキストを段階的に取得します。言い換えると、エージェントは与えられたタスクに対して複数回検索を行い、各検索の結果を分析して必要な追加のコードコンテキストを決定し、コード生成などのタスクを完了するために必要なすべての関連情報を得るまで再度検索します。
このアプローチを実現するため、チームは Amazon Bedrock でホストされている Claude 3.7 Sonnet を搭載したオープンソースのコーディングアシスタント Cline を統合しました。エージェント型の構成は大きな可能性を示し、以下のような事例が得られました:
- シニア開発者が5日間かけた作業を数分でバグ修正
- 非常に大きなファイルをリファクタリングし、冗長性を削除してサイズを50%削減
同じ構成は既存コードの説明においても非常に優れたパフォーマンスを発揮しました。一方で、これらの標準モデルは、多くの再利用可能な API とベストプラクティスを含む AUMOVIO コードベースでファインチューニングされておらず、自動車特有のドメインにおいては限界も見られました。多くの場合、生成されたコードは良好であっても既存のライブラリを活用しておらず、既存実装の重複やわずかなバリエーションを引き起こしていました。
ワークショップの結果を踏まえて、AUMOVIO と AWS チーム (AWS の Generative AI Innovation Center を含む) は協力して、概念実証 (PoC) の一環としてエージェント型アーキテクチャを考案しました。PoC の目的は、自動車ソフトウェア開発向けの特化型コーディングアシスタントの実現可能性を探ることでした。このプログラムは、AI 駆動のイノベーション可能性を迅速に評価するため、事前に定めた成功基準と指標で評価する構造化されたアプローチを取りました。PoC フレームワークは、スコープ定義、開発、テスト、パフォーマンス評価、技術検証を包含し、期間内に測定可能な成果を提供するように設計されました。
チームは以下で構成されるエージェント型アーキテクチャを設計しました:
- ファインチューニングされたモデルまたはエージェント: コード生成やユニットテスト生成などの特定のV字モデルの工程に対して最先端の精度を提供するために使用。
- オーケストレーターモデル (Claude Sonnet 3.7/4など): アプリケーションの対話ウィンドウで使用され、以下を実行:
- ユーザーからタスクに関する情報を収集
- 該当する場合、ファインチューニングされたモデルにタスクを委任
- ファインチューニングされたモデルでサポートされていないタスクに応答(例: コード説明)
パフォーマンスのベースラインを確立し、エージェントの取りうるさまざまな構成を理解するため、我々は多様な能力を持つ複数のモデルを評価しました。これには、迅速な応答に最適化された Nova Pro のようなプロンプトエンジニアリングのみを使用するモデルや、後に自動車特有のコードでファインチューニングのベースとして使用した Qwen3 32B のようなモデルが含まれています。
ソリューション
この評価フェーズにおいて、柔軟なインフラストラクチャを用いてこれらの異なるモデル機能を統合するアーキテクチャの必要性が明らかになりました。アーキテクチャの概要は、以下の通りです:
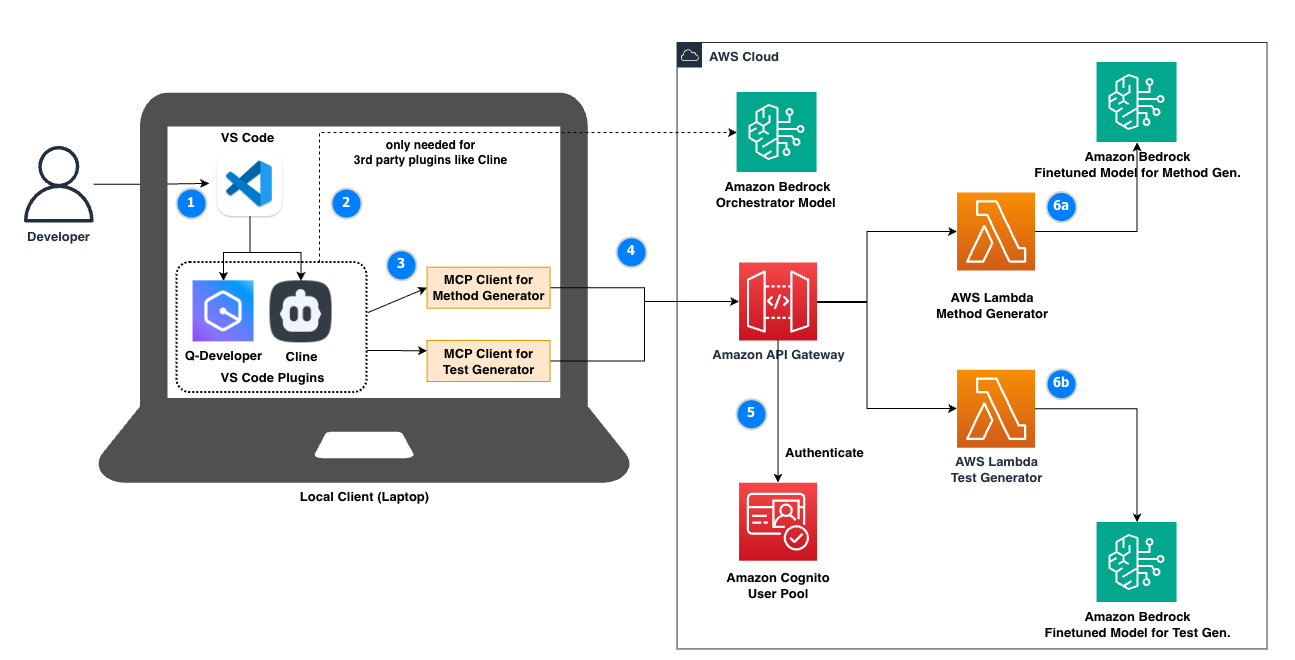
図1:マルチモデル/マルチエージェント コードアシスタント アーキテクチャ
AUMOVIO は、複数の拡張機能を備えた VS Code を標準の統合開発環境 (IDE) として採用しました。この既存の構成を基に、我々のアーキテクチャは Amazon Q Developer や Cline などのコーディング支援拡張機能を使用しています。
Amazon Q Developer は、開発者がアプリケーションを理解、構築、拡張、運用するのを支援する生成 AI アシスタントです。VS Code などの IDE で使用すると、Amazon Q はコードについてチャットし、インラインコード補完を提供し、新しいコードを生成し、セキュリティ脆弱性のためにコードをスキャンし、言語更新、デバッグ、最適化などのコードアップグレードと改善を行うことができます。Amazon Q Developer の推論とエージェント機能は、プレミアムモデルによってサポートされています。執筆時点では、Claude Sonnet 3.7 またはClaude Sonnet 4 で使用するように設定が可能でした。
同様に、オープンソースのプラグインの Cline は、IDE 内でエージェント型コードアシスタントのユースケースを実現するために、多くのエンドポイントをサポートしています。Cline は Claude Sonnet 3.7 や Claude Sonnet 4 など、Amazon Bedrock でホストされているモデルで簡単に設定できます。
さらに、このアーキテクチャは Model Context Protocol (MCP) を活用しています。MCP は、AI アシスタントが外部ツールやサービスと対話できるようにするオープン標準です。Cline と同様に、Amazon Q Developer は MCP をサポートしており、ユーザーはカスタムツールやサービスに接続することで Q の機能を拡張できます。我々のケースでは、ファインチューニングされたモデルを MCP エンドポイントとしてオーケストレーターモデルに公開しています。これにより、オーケストレーターモデルはユーザーから与えられたタスクの初期計画を行い、必要に応じてさらに情報を収集し、最終的に MCP プロトコルを介してファインチューニングされたモデルを呼び出すことができます。
以下は、図の番号付けに沿った Amazon Q Developer を使用した処理フローの例です:
1) 開発者は、 Amazon Q Developer が統合された VS Code に質問を送信します。
2) 基盤となるオーケストレーターモデルを使用して、Amazon Q Developer はタスクがメソッド生成に関するものであることを理解します。次に、オーケストレーターモデルは、関連するコードを生成するために一部の入力が不足していることを識別します。その後、Amazon Q Developer はさらなる入力 (不足している要件ドキュメントなど) を要求します。
3) 開発者とモデル間のメッセージ交換の後、Amazon Q Developer はすべての入力を収集します。次に、Amazon Q Developer は「Method Generator 用 MCP クライアント」を使用して、リクエストを Amazon API Gateway に転送します。Amazon API Gateway は、あらゆる規模で REST、HTTP、WebSocket API を作成、公開、維持、監視、保護するための AWS サービスです。
4) Amazon API Gateway は、クラウドネイティブ認証サービスである Amazon Cognito を使用してユーザーを認証します。
5) Amazon API Gateway は「Method Generator」AWS Lambda 関数に委任します。これは、コードを実行するためのクラウドネイティブサーバーレスコンピューティングエンジンです。
6a) リモート MCP サーバーを立ち上げて、「Method Generator」Lambda 関数は Amazon Bedrock に推論リクエストを行います。Amazon Bedrock は、メソッド生成専用のファインチューニングされたモデルをホストしています。同様に、タスクがユニットテストの生成に関するものであれば、「Test Generator」が呼び出されます (6b)。
7) モデルからの応答は、AWS Lambda → API Gateway → MCP クライアントのパスを介して Amazon Q Developer に返され、ローカル IDE のコードを変更し、ユーザーに確認を求めます(読みやすさを向上させるため、図では番号付けが省略されています)。
別の処理フローでは、ユーザーが既存コードの説明を求める場合があります。この場合、オーケストレーターはタスクを処理するファインチューニングされたモデルがないと結論付け、独自の推論能力を使用して回答を提供します。
現在のソリューションの MCP エンドポイントは、単一のタスクを処理するモデルエンドポイントによってサポートされていることに注意してください。したがって、現在のイテレーションはマルチモデルですが、必ずしもマルチエージェントではありません。推論し、ツールを利用する唯一のエージェントはオーケストレーターモデルだからです。同時に、このアーキテクチャは MCP エンドポイントの背後に追加のエージェント(推論とオーケストレーション機能を持つ) の拡張をサポートしており、これによりマルチエージェントコーディングアシスタントが実現されます。
ファインチューニングの詳細
業界標準を考慮したドメイン特化型の自動車コードを生成するため、我々は人間が書いた高品質なコードで言語モデルをファインチューニングします。このセクションでは、ファインチューニングプロセスの詳細を説明します。
データの準備
効果的なモデルのファインチューニングの基盤は、高品質でドメイン特化型の学習用データです。我々は、生の自動車ソフトウェアリポジトリを、C/C++ コード生成に不可欠な豊富なコンテキストを保持する構造化された学習用データに変換する前処理パイプラインを構築しました。
前処理パイプラインは、AUMOVIO の C/C++ リポジトリを探索して、包括的なコンテキストとともに個々の関数を抽出することから始まります。このコンテキストには以下が含まれます:
- 関数ドキュメント:Doxygen スタイルのコメントとインラインドキュメントの両方が抽出され、対応する関数実装にリンクされます。
- システム要件:パイプラインは DOORS が出力したXML ファイルを解析して、関数ドキュメントで言及されている要件識別子を完全な要件テキストにマッピングします。
- アーキテクチャコンテキスト:ドキュメントで参照されている PlantUML 図が抽出され、挙動の仕様を提供するために含まれます。
- API コンテキスト:関連するヘッダーファイルとその関数シグネチャが収集され、利用可能な API とデータ構造に関する情報を提供します。
前処理を用いたアプローチの重要な工夫は、ヘッダーファイルと実装ファイルのインテリジェントな連携です。システムは各 C/C++ ソースファイルに対応するメインヘッダーファイルを識別し、含まれる依存関係から追加のコンテキストを抽出します。これにより、生成されたコードが既存の API を使用できることが保証されます。
# Example of context aggregation from the preprocessing pipeline
def create_training_example(function_info):
user_message = f"Implement the function: {function_info['signature']}\n\n"
if function_info["documentation"]:
user_message += f"with following specifications:\n{function_info['documentation']}"
if function_info["requirements"]:
user_message += f"\n\nRequirements tests:\n{function_info['requirements']}"
if function_info["uml_diagram"]:
user_message += f"\n\nThe behavior follows this UML diagram:\n{function_info['uml_diagram']}"
return {
"messages": [
{"role": "user", "content": user_message},
{"role": "assistant", "content": function_info["implementation"]},図2:抽出したコンテキストを集約するコード
前処理パイプラインは、いくつかの品質保証メカニズムも実装しています:
- 関数シグネチャの検証:ヘッダーファイルの宣言と照合することで、実装ファイルの関数シグネチャを自動的に修正します。
- ドキュメントの完全性:包括的なドキュメントを持つ関数のみが学習用データセットに含まれます。
- コードコンプライアンス:関数は、自動車の安全性とアーキテクチャパターンを含むカスタムルールセットに準拠しているか検証されます。
様々な複雑さを含むバランスの取れたコードを確保するため、前処理パイプラインは関数の長さと複雑さに基づく層別サンプリングを実装しています。このアプローチにより、一貫した分布特性を持つ学習用データセットとテスト用データセットが作成されます:
# Stratified sampling ensures balanced complexity distribution
stats = stratified_sample_jsonl(
input_file="dataset-7037-funcs.jsonl",
sampled_file="test-set-funcs.jsonl",
remaining_file="train-set-funcs.jsonl",
sample_size=1000,
num_strata=5,
)図3:層別学習用データサンプルの生成
結果として得られたデータセットには、完全なコンテキスト情報を含む約 7,000 の高品質な関数実装が含まれており、複雑さの分布を維持しながら学習用データセットとテスト用データセットに分割されています。
ファインチューニング
ファインチューニングを用いたアプローチは、自動車ソフトウェア開発の計算リソース制約と精度要件に最適化された最先端の技術を活用しています。
プロジェクトチームは、コード生成タスクでの優れたパフォーマンスと適度な計算リソース要件から、Qwen3-32B をベースモデルとして選択しました。ファインチューニングプロセスは、モデルの一般的な能力を維持しながら効率的な学習を実現するために、Low-Rank Adaptation (LoRA) を採用しています:
- LoRA設定: アテンション層とフィードフォワード層に適用されるランク 8 アダプター (alpha=16)
- 量子化: BitsAndBytes を使用した 4 ビット量子化によりメモリ使用量を削減
- ターゲットモジュール: クエリ、キー、バリュー、出力プロジェクション層に加えて、すべてのフィードフォワードネットワークコンポーネントに LoRA アダプターを適用
ファインチューニングでは、Amazon SageMaker の分散学習機能と PyTorch DeepSpeed を利用しており、自動車コードベースでの大規模モデル学習の計算リソースの要件を満たすように特別に設計されています。我々は、 SageMaker の remote デコレーターを使用して、単一インスタンス内の複数の GPU 間で分散学習を構成し、マルチノード構成へのスケーリングのためのサポートを備えています。
@remote(
instance_type="ml.p4d.24xlarge",
volume_size=100,
use_torchrun=True,
pre_execution_commands=[
"pip install torch==2.5.1 transformers==4.51.3",
"pip install peft==0.15.2 deepspeed bitsandbytes",
]
)
def train_model(train_dataset, test_dataset, config):
# Adaptive DeepSpeed configuration based on quantization settings
stage = 2 if use_quantization else 3
deepspeed_config = {
"zero_optimization": {
"stage": stage,
"overlap_comm": True,
"contiguous_gradients": True,
"offload_optimizer": {"device": "cpu", "pin_memory": True}
}
}
if stage == 3:
deepspeed_config["zero_optimization"].update({
"offload_param": {"device": "cpu", "pin_memory": True},
"stage3_prefetch_bucket_size": 1e6,
"stage3_param_persistence_threshold": 1e4,
})
# Training implementation...図4: SageMaker のremoteデコレーターを介した LLM の学習
学習用のインフラストラクチャは、いくつかの重要な最適化を実装しています:
- 適応型メモリ管理: システムは、学習の設定に基づいて DeepSpeed ZeRO-2 と ZeRO-3 の最適化ステージの両方を採用しています。量子化を使用する場合、ZeRO-2 は4ビット量子化モデルとの互換性が優れているため優先され、モデルパラメータを複製したままオプティマイザの状態を GPU 間で分割します。フル精度学習シナリオの場合、システムは自動的に ZeRO-3 に切り替わり、モデルパラメータをデバイス間でさらに分割し、アクティブに必要とされない場合は CPU メモリにオフロードします。この適応型アプローチにより、限られた GPU メモリでも 320 億パラメータのフルモデルの学習が可能になり、各設定で最適なパフォーマンスを維持します。
- 高度なパラメータ管理: ZeRO-3のパラメータ分割機能により、包括的な関数ドキュメントや要件トレーサビリティに必要な大規模なコンテキストウィンドウの処理が可能になります。バケットサイズとパラメータ永続化の閾値を調整することで、過度な通信オーバーヘッドを発生させることなく、効率的なパラメータストリーミングを実現しています。
- 通信最適化: 分散セットアップでは、NVIDIA Collective Communication Library(NCCL)を使用し、最適化されたタイムアウト設定と通信オーバーラップにより、コード生成モデル特有の大規模かつ密な勾配を処理します。
- 耐障害性と信頼性: 長時間の学習を考慮し、インフラストラクチャには、モデルダウンロード時のエクスポネンシャルバックオフを用いた堅牢なエラーハンドリングと、一時的なハードウェア障害に対する自動リトライ機構を組み込んでいます。また、システムは中断時に最後に保存された状態から学習を再開するチェックポイント復旧機能を実装しており、ZeRO-3のパラメータ分割により、より細かい粒度でのチェックポイント戦略が可能になっています。
- 動的リソース割り当て: Amazon SageMaker 統合により、学習の計算負荷に基づく動的スケーリングが可能になり、学習の計算負荷がピークに達した時に追加の計算リソースを自動的にプロビジョニングする機能があります。
分散学習のセットアップは、安定した収束を維持しながら、すべてのデバイスで約 85% の GPU 使用率を達成し、AUMOVIO が効率的なリソース使用を通じてクラウドコンピューティングコストを最適化しながら、開発スプリントの時間軸でファインチューニングサイクルを完了できるようにしています。
学習完了後のモデルは、Amazon Bedrock のカスタムモデルインポート機能を通じてデプロイメント用にパッケージ化され、前述のマルチモデルアーキテクチャとのシームレスな統合が可能になります。ファインチューニングされたモデルは、IDE 統合に必要な会話能力を維持しながら、ドメイン特化型の精度で大幅な改善を達成しています。
評価結果
MCP エンドポイントとしてデプロイされたさまざまなコード生成モデルの有効性を評価するため、C と C++ の両方のコード生成に焦点を当てた包括的な評価を実施しました。このセクションでは、評価方法論と主要な結果について詳しく説明します。
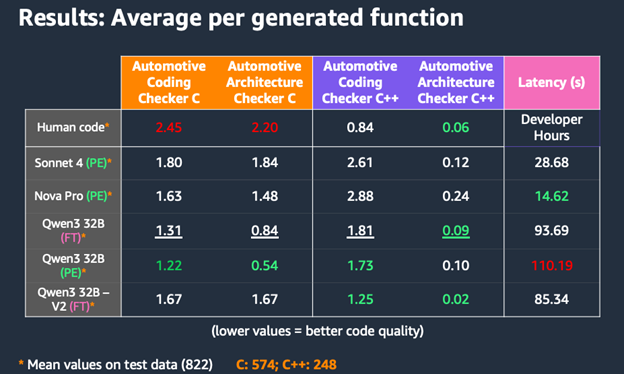
図5:コンプライアンスとレイテンシに関するさまざまなモデルの評価
この表は、ファインチューニングされたモデルと汎用モデルなどさまざまなベースモデルと、人間が作成したコードを比較しています。我々は、プロンプトエンジニアリング (PE) とファインチューニング (FT) 戦略に焦点を当て、複数の評価指標を使用しています:
- カスタム自動車コーディングルールへの適合性: 正規表現ベースのカスタムビルド静的アナライザーを用いて測定 (関数あたりの平均エラー数で測定)
- カスタム自動車アーキテクチャルールへの適合性: 正規表現ベースのカスタムビルド静的アナライザーを用いて測定 (関数あたりの平均エラー数で測定)
- コード生成レイテンシ: 関数あたりの平均秒数
結果は興味深いパターンを示しています。 Qwen3 32B (PE) のような PE 重視のモデルは、C 言語 において Automotive Architecture Checker 準拠スコアで平均 1.22 の違反、Automotive Coding Checker 準拠スコアで 0.54 を示す強力な C コード 品質スコアを達成しましたが、FT 強化バージョンは C++ 生成で競争力のある結果を示しました。特に、Qwen3 32B – V2 (FT) は、C++ において優れた Automotive Architecture Checker 準拠スコア (0.02) と堅実な Automotive Coding Checker 準拠スコア (1.25) を達成し、ファインチューニングとプロンプトエンジニアリングを組み合わせる利点を示しています。
この結果は、MCP を通じて複数のコード生成モデルへの柔軟なアクセスを持つことの戦略的優位性を示しています。それぞれのモデルは異なるシナリオで優れた性能を示します: Nova Pro は 優れた C 準拠スコアと14.62 秒のレイテンシで迅速な生成を提供し、素早いプロトタイピングと C 重視の開発に理想的です。一方、Qwen3 32B 由来のモデルは優れた C++ 準拠スコアを示しています。PE と FT アプローチ間のシームレスな切り替えが可能なため、さらに最適化が可能です。開発者は、プロンプトのカスタマイズが鍵となる単純な API 実装に PE モデルを利用できます。より複雑な C++ コード生成の場合、学習されたパターンがより有益なので、 FT モデルに切り替えることができます。この柔軟性は、各モデルのコストパフォーマンスのトレードオフと組み合わせることで、開発チームがプロジェクト固有の要件に基づいてコード生成を調整できるようにします。
これらのコードの品質改善と標準への準拠は、SDV の複雑性の増大に追随しながらコード品質を維持するという冒頭で述べた課題に直接的に対処しています。
「 AUMOVIO のエンジニアリングアシスタントは、顕著に高速な開発サイクルとコード品質の向上を実現しながら、SDV の複雑化に対応するのに役立っています。このアシスタントは、開発スピードを犠牲にすることなく自動車業界の標準に準拠することが可能です。これはまさに、今日の競争の激しい自動車市場で我々が必要としていたものです。」
– Amir Namazi, AUMOVIO バーチャライゼーション クラウド & AI ソリューションマネージャー
まとめ
この最初のイテレーションで、AUMOVIO はコード生成のためのファインチューニングされたモデルを利用して高度に特化したコーディングアシスタントを開発しました。今後、AUMOVIO はコーディングアシスタントのイテレーションを続け、V 字モデル開発プロセスのさまざまな工程をより効果的にサポートするために機能を拡張していきます。この取り組みをさらに促進するため、AUMOVIO は、現在の構成のエージェント型コーディングアシスタント機能とともに、V 字モデルライフサイクルの複数の工程をカバーする仕様駆動開発をサポートする Kiro に徐々に移行しています。単体テスト生成は引き続き重要な関心領域ですが、AUMOVIO のより大きな目標は、このツールをAUMOVIO 社内チームと外部パートナーの両方に利益をもたらす統合された製品グレードのオファリングに進化させることです。長期的なビジョンとしては、特化したモデルとオーケストレーターが開発ライフサイクル全体でシームレスに連携するマルチエージェントフレームワークへの移行を目指しています。
詳細については、AWS for automotive および Manufacturing ページをご覧いただくか、今すぐ AWS にお問い合わせください。