Amazon Web Services ブログ
Author: Takayuki Enomoto
OpenSearch Specialist Solutions Architect in AWS Japan.
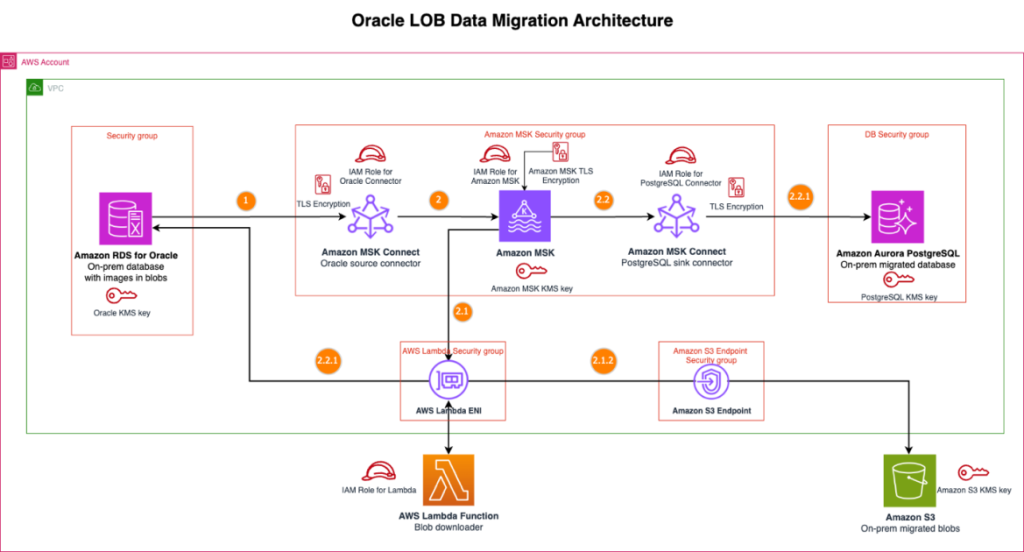
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。

Bazaarvoice が Amazon MSK で Apache Kafka インフラストラクチャをモダナイズした方法
Bazaarvoice は、セルフホスト型 Kafka から Amazon MSK に移行し、運用オーバーヘッドを削減しながら、セキュリティ、信頼性、パフォーマンスを向上させました。この記事では、移行プロセスと得られた教訓を紹介します。

Amazon Redshift フェデレーテッドアクセス許可でマルチウェアハウスのデータガバナンスを簡素化する
Amazon Redshift フェデレーテッドアクセス許可を使用すると、複数の Redshift ウェアハウス間でデータアクセス許可を一度定義するだけで、自動的に適用できます。本記事では、RLS と DDM ポリシーを設定し、ウェアハウス間で一貫したセキュリティを実現する方法を紹介します。

Kiro CLI と Amazon MSK MCP Server を使用した自然言語による Amazon MSK の簡易管理
この記事では、Kiro CLI と Amazon MSK MCP Server を使用して、自然言語コマンドで Apache Kafka クラスターを管理する方法を紹介します。トピック管理、クラスターの健全性監視、設定の最適化など、複雑な Kafka 操作を対話形式で簡単に実行できるようになります。

Amazon Bedrock で TwelveLabs Marengo を使用した動画理解の実現
TwelveLabs Marengo 埋め込みモデルが Amazon Bedrock で利用可能になりました。このモデルはマルチベクトルアーキテクチャにより、動画の視覚、音声、テキスト要素を個別に捉え、従来の単一ベクトルアプローチでは失われていたニュアンスを保持します。Amazon OpenSearch Serverless と組み合わせることで、テキスト、画像、音声を使用したクロスモーダルセマンティック検索が可能になり、インテリジェントな動画コンテンツ発見を実現します。

Amazon OpenSearch Service ベクトルデータベースを自動最適化する
AWS は Amazon OpenSearch Service ベクトルエンジンの自動最適化機能の一般提供を発表しました。この機能により、専門知識やインフラストラクチャ管理なしに、1 時間以内でベクトルデータベースを最適化できます。検索品質、速度、コストのトレードオフを自動評価し、最適なインデックス構成を推奨します。

Amazon OpenSearch Service の GPU アクセラレーションで 10 億規模のベクトルデータベースを 1 時間以内に構築
AWS は Amazon OpenSearch Service での GPU アクセラレーションによるベクトルインデックス作成の一般提供を発表しました。10 億規模のベクトルデータベースを 1 時間以内に構築でき、最大 10 倍高速化しながらコストを 4 分の 1 に削減できます。

Amazon S3 Vectors がスケールとパフォーマンスを向上させて一般提供開始
Amazon S3 Vectors がスケールとパフォーマンスを大幅に向上させて一般提供を開始しました。S3 Vectors は、ベクトルデータの保存とクエリをネイティブにサポートする初のクラウドオブジェクトストレージです。専用のベクトルデータベースソリューションと比較して、ベクトルの保存とクエリの総コストを最大 90% 削減できます。

Amazon OpenSearch Service が GPU アクセラレーションと自動最適化でベクトルデータベースのパフォーマンスとコストを改善
本日、Amazon OpenSearch Service において、サーバーレス GPU アクセラレーションとベクトルインデックスの自動最適化を発表しました。これにより、大規模なベクトルデータベースをより高速かつ低コストで構築でき、検索品質、速度、コストの最適なトレードオフを実現するようにベクトルインデックスを自動的に最適化できます。
本日発表された新機能は以下のとおりです。
GPU アクセラレーション – GPU アクセラレーションを使用しない場合と比較して、最大 10 倍高速にベクトルデータベースを構築でき、インデックス作成コストを 4 分の 1 に削減できます。また、10 億規模のベクトルデータベースを 1 時間以内に作成できます。コスト削減と速度の大幅な向上により、市場投入までの時間、イノベーションの速度、大規模なベクトル検索の導入において優位性を得ることができます。
自動最適化 – ベクトルの専門知識がなくても、ベクトルフィールドの検索レイテンシー、品質、メモリ要件の最適なバランスを見つけることができます。この最適化により、デフォルトのインデックス設定と比較して、コスト削減と再現率の向上を実現できます。手動でのインデックスチューニングには数週間かかることがあります。

Cluster Insights のご紹介: Amazon OpenSearch Service クラスター向け統合モニタリングダッシュボード
Amazon OpenSearch Service クラスターは、CloudWatch や Amazon OpenSearch Service コンソールを通じてアクセスできる豊富な運用メトリクスを提供し、効果的なパフォーマンスモニタリングとアラート作成をサポートします。しかし、クラスター内の回復力やパフォーマンスの課題を特定することは困難な場合があります。リソースを大量に消費するクエリを特定したり、パフォーマンス低下の傾向を把握したりするプロセスには時間がかかることがあります。
これらの課題に対処するため、私たちは Cluster Insights をリリースしました。これは、厳選されたインサイトと実行可能な緩和手順を提供する統合ダッシュボードです。このダッシュボードは、ノード、インデックス、シャードレベルの詳細なメトリクスを表示し、最高の回復力と可用性を維持するためのセキュリティと回復力のベストプラクティスの簡潔なサマリーを提供します。
このブログでは、主要な機能とメトリクスを含む Cluster Insights のセットアップと使用方法について説明します。最後まで読むと、Cluster Insights を使用して OpenSearch Service クラスター内のパフォーマンスと回復力の問題を認識し、対処する方法を理解できるようになります。