Amazon Web Services ブログ
AWS Graviton2 プロセッサを搭載した AWS Lambda 関数 – Arm で関数を実行し、最大 34% 優れた料金パフォーマンスを実現
多くのお客様 (Formula One、Honeycomb、Intuit、SmugMug、Snap Inc. など) は、ARM ベースの AWS Graviton2 プロセッサをワークロードに使用して、優れた料金パフォーマンスを享受しています。2021 年 9 月 29 日から、AWS Lambda 関数でも同じ利点を享受できるようになります。x86 または Arm/Graviton2 プロセッサ上で実行するように新規および既存の関数を設定できるようになりました。
この選択により、2 つの方法でコストを節約できます。まず、Graviton2 アーキテクチャにより、関数がより効率的に実行されます。第二に、実行する時間に対する支払いが少なくなります。実際、Graviton2 を搭載した Lambda 関数は、20% 低いコストで最大 19% 優れたパフォーマンスを実現するように設計されています。
Lambda では、お客様の関数のリクエスト数とミリ秒単位の時間 (コードの実行に要した時間) に基づいて課金されます。Arm/Graviton2 アーキテクチャを使用する関数の場合、時間料金は x86 の現在の料金よりも 20% 低くなります。同じ 20% の削減は、プロビジョニングされた同時実行を使用する関数の時間料金にも適用されます。
低料金化に加えて、Arm アーキテクチャを使用する関数は、Graviton2 プロセッサに組み込まれたパフォーマンスとセキュリティの恩恵を受けます。マルチスレッドとマルチプロセッシングを使用するワークロード、または多数の I/O 操作を実行するワークロードでは、実行時間が短縮され、その結果、さらにコストが削減されます。これは、最大 10 GB のメモリと 6 つの vCPUs を搭載した Lambda 関数を使用できるようになったため、特に便利です。例えば、ウェブおよびモバイルバックエンド、マイクロサービス、データ処理システムのパフォーマンスを向上させることができます。
関数が依存関係を含め、アーキテクチャ固有のバイナリを使用していない場合は、あるアーキテクチャから別のアーキテクチャに切り替えることができます。これは、Node.js や Python などのインタプリタ型言語を使用する多くの関数や、Java バイトコードにコンパイルされた関数の場合によくあります。
Amazon Linux 2 上に構築されたすべての Lambda ランタイムは、カスタムランタイムを含め、Arm でサポートされます。ただし、Node.js 10 はサポートが終了しています。関数パッケージにバイナリがある場合は、使用するアーキテクチャの関数コードを再構築する必要があります。コンテナイメージとしてパッケージ化された関数は、使用するアーキテクチャ (x86 または Arm) 用に構築する必要があります。
アーキテクチャの違いを測定するために、x86 用と Arm 用の 2 つのバージョンの関数を作成できます。次に、重みを使用してエイリアスを介してトラフィックを関数に送信し、2 つのバージョン間でトラフィックを分散できます。Amazon CloudWatch では、パフォーマンスメトリクスは関数のバージョンごとに収集され、統計を使って主要指標 (期間など) を確認できます。次に、例えば、2 つのアーキテクチャの平均期間とp99 期間を比較できます。
関数バージョンと加重エイリアスを使用して、本番環境でのロールアウトを制御することもできます。例えば、新しいバージョンを少数の呼び出し (1% など) にデプロイしてから、完全なデプロイのために最大 100% に引き上げることができます。ロールアウト中、メトリクスに疑わしいもの (エラーの増加など) が示されている場合は、重みを下げたり、ゼロに設定したりできます。
この新機能が実際にどのように機能するかを、いくつかの例を挙げて見てみましょう。
バイナリへの依存関係のない関数のアーキテクチャの変更
バイナリへの依存関係がない場合、Lambda 関数のアーキテクチャを変更することは、スイッチを切り替えるようなものです。例えば、私は少し前に、Lambda 関数を使用してクイズアプリを作成しました。このアプリでは、ウェブ API を使用して質問や回答を行うことができます。Amazon API Gateway HTTP API を使用して関数をトリガーします。以下に Node.js コードを示します。冒頭にはサンプル質問がいくつか含まれています。
const questions = [
{
question:
"脳には銀河系の星よりも多くのシナプス (神経のつながり) があるでしょうか?",
answers: [
"銀河にはもっと多くの星がある。",
"脳にはもっと多くのシナプス (神経のつながり) がある。",
"ほとんど同数。",
],
correctAnswer: 1,
},
{
question:
"クレオパトラが生きていたのは、iPhone の発売日とギザのピラミッドの建造日のどちらに近い時代でしょうか?",
answers: [
"iPhone の発売日。",
"ギザのピラミッドの建造日。",
"クレオパトラはこの 2 つのイベントのちょうど中間にあたる時代に生きていた。",
],
correctAnswer: 0,
},
{
question:
"ピラミッドの建造時、マンモスはまだ地球を歩き回っていたでしょうか?",
answers: [
"いいえ。マンモスは遥か前に絶滅していた。",
"マンモスはその頃に絶滅したと推定されている。",
"はい。当時まだ生き残っていたマンモスもいた。",
],
correctAnswer: 2,
},
];
exports.handler = async (event) => {
console.log(event);
const method = event.requestContext.http.method;
const path = event.requestContext.http.path;
const splitPath = path.replace(/^\/+|\/+$/g, "").split("/");
console.log(method, path, splitPath);
var response = {
statusCode: 200,
body: "",
};
if (splitPath[0] == "questions") {
if (splitPath.length == 1) {
console.log(Object.keys(questions));
response.body = JSON.stringify(Object.keys(questions));
} else {
const questionId = splitPath[1];
const question = questions[questionId];
if (question === undefined) {
response = {
statusCode: 404,
body: JSON.stringify({ message: "Question not found" }),
};
} else {
if (splitPath.length == 2) {
const publicQuestion = {
question: question.question,
answers: question.answers.slice(),
};
response.body = JSON.stringify(publicQuestion);
} else {
const answerId = splitPath[2];
if (answerId == question.correctAnswer) {
response.body = JSON.stringify({ correct: true });
} else {
response.body = JSON.stringify({ correct: false });
}
}
}
}
}
return response;
};クイズを開始するために、質問 ID のリストを尋ねます。そのためには、/questions エンドポイントで curl と HTTP GET を使用します。
この関数を本番環境で使用する予定です。多くの呼び出しを期待し、コストを最適化するオプションを探します。Lambda コンソールでは、この関数が x86_64 アーキテクチャを使用していることがわかります。

この関数はバイナリを使用していないため、アーキテクチャを arm64 に切り替えて、より低い料金設定の恩恵を受けます。

アーキテクチャの変更は、関数の呼び出し方法やレスポンスの通信方法を変更しません。つまり、API Gateway との統合や、他のアプリケーションやツールとの統合は、この変更の影響を受けず、以前と同様に機能し続けます。
コードを実行するために使用されるアーキテクチャがバックエンドで変更されたというヒントなしでクイズを続けます。前の質問に戻って、質問エンドポイントに回答の番号 (ゼロから始まる) を加えて回答します。
正解です。 クレオパトラは、ギザのピラミッドの建造日よりも、iPhone の発売日に近い時代に生きていました。この情報を消化している間、Arm への関数の移行が完了し、コストを最適化したことに気付きました。
コンテナイメージを使用してパッケージ化された関数のアーキテクチャーを変更する
コンテナイメージを使用して Lambda 関数をパッケージ化およびデプロイする機能を導入したときに、PDFKit モジュールで PDF ファイルを生成する Node.js 関数を使用してデモを行いました。この関数を Arm に移行する方法を見てみましょう。
呼び出されるたびに、関数は faker.js モジュールによって生成されたランダムデータを含む新しい PDF メールを作成します。関数の出力は、Amazon API Gateway の構文を使用して、Base64 エンコーディングで PDF ファイルを返します。便宜上、関数のコード (app.js) をここにレプリケートします。
const PDFDocument = require('pdfkit');
const faker = require('faker');
const getStream = require('get-stream');
exports.lambdaHandler = async (event) => {
const doc = new PDFDocument();
const randomName = faker.name.findName();
doc.text(randomName, { align: 'right' });
doc.text(faker.address.streetAddress(), { align: 'right' });
doc.text(faker.address.secondaryAddress(), { align: 'right' });
doc.text(faker.address.zipCode() + ' ' + faker.address.city(), { align: 'right' });
doc.moveDown();
doc.text('Dear ' + randomName + ',');
doc.moveDown();
for(let i = 0; i < 3; i++) {
doc.text(faker.lorem.paragraph());
doc.moveDown();
}
doc.text(faker.name.findName(), { align: 'right' });
doc.end();
pdfBuffer = await getStream.buffer(doc);
pdfBase64 = pdfBuffer.toString('base64');
const response = {
statusCode: 200,
headers: {
'Content-Length': Buffer.byteLength(pdfBase64),
'Content-Type': 'application/pdf',
'Content-disposition': 'attachment;filename=test.pdf'
},
isBase64Encoded: true,
body: pdfBase64
};
return response;
};このコードを実行するには、pdfkit、faker、get-stream npm モジュールが必要です。これらのパッケージとそのバージョンは、package.json および package-lock.json ファイルに記述されています。
Dockerfile の FROM 行を更新して、Arm アーキテクチャの Lambda 用の AWS ベースイメージを使用します。この機会に、Node.js 14 を使用するようにイメージも更新します (その時は Node.js 12 を使用していました)。これが、アーキテクチャを切り替えるために必要な唯一の変更です。
次のステップについては、前述の記事に従います。今回は、コンテナイメージの名前と Lambda 関数の名前に random-letter-arm を使用します。まず、次のようにイメージを構築します。
次に、以下のように、イメージを検査して、適切なアーキテクチャを使用していることを確認します。
関数が新しいアーキテクチャで動作することを確認するために、コンテナをローカルで実行します。
コンテナイメージには Lambda Runtime Interface Emulator が含まれているため、関数をローカルでテストできます。
上手く行きました! レスポンスは、API Gateway の base64 でエンコードされたレスポンスを含む JSON ドキュメントです。
自分の Lambda 関数が arm64 アーキテクチャで動作することに自信が持てたので、AWS Command Line Interface (CLI) を使用して新しい Amazon Elastic Container Registry リポジトリを作成します。
イメージにタグ付けして、リポジトリにプッシュします。
Lambda コンソールで random-letter-arm 関数を作成し、コンテナイメージから関数を作成するオプションを選択します。

関数名を入力し、ECR リポジトリを参照して random-letter-arm コンテナイメージを選択し、arm64 アーキテクチャを選択します。

関数の作成が完了しました。次に、API Gateway をトリガーとして追加します。わかりやすくするために、API の認証は開いたままにしておきます。

ここで、API エンドポイントを数回クリックし、ランダムなデータで生成された PDF メールをいくつかダウンロードします。

これで、この Lambda 関数の Arm への移行が完了しました。ターゲットアーキテクチャをサポートしない特定の依存関係がある場合、プロセスは異なります。コンテナイメージをローカルでテストできると、プロセスの初期段階で問題を見つけて修正するのに役立ちます。
異なるアーキテクチャの関数のバージョンとエイリアスを比較する
CPU を有意義に利用する関数を作るために、以下の Python コードを使います。パラメータとして渡される制限までのすべての素数を計算します。ここで使用しているのは、可能な限り最高のアルゴリズム (それはエラトステネスの篩です) ではありませんが、メモリを効率的に使用するための良い妥協点です。可視性を高めるために、関数で使用されるアーキテクチャを関数のレスポンスに追加します。
import json
import math
import platform
import timeit
def primes_up_to(n):
primes = []
for i in range(2, n+1):
is_prime = True
sqrt_i = math.isqrt(i)
for p in primes:
if p > sqrt_i:
break
if i % p == 0:
is_prime = False
break
if is_prime:
primes.append(i)
return primes
def lambda_handler(event, context):
start_time = timeit.default_timer()
N = int(event['queryStringParameters']['max'])
primes = primes_up_to(N)
stop_time = timeit.default_timer()
elapsed_time = stop_time - start_time
response = {
'machine': platform.machine(),
'elapsed': elapsed_time,
'message': 'There are {} prime numbers <= {}'.format(len(primes), N)
}
return {
'statusCode': 200,
'body': json.dumps(response)
}異なるアーキテクチャを使用して 2 つの関数バージョンを作成します。

呼び出しを均等に分散するために、x86 バージョンでは 50% の重み付け、Arm バージョンでは 50% の重み付けされたエイリアスを使用します。このエイリアスを通じて関数を呼び出すと、2 つの異なるアーキテクチャで実行されている 2 つのバージョンが同じ確率で実行されます。

関数エイリアスの API Gateway トリガーを作成してから、ノートパソコンの端末を使用して負荷を生成します。各呼び出しは、100 万までの素数を計算します。出力では、関数の実行に 2 つの異なるアーキテクチャがどのように使用されているかがわかります。
これらの実行中に、Lambda は CloudWatch にメトリクスを送信し、関数バージョン (ExecutedVersion) はディメンションの 1 つとして格納されます。
何が起こっているのかをよりよく理解するために、CloudWatch ダッシュボードを作成し、2 つのアーキテクチャの p99 期間をモニタリングします。このようにして、この関数の 2 つの環境のパフォーマンスを比較し、本番環境で使用するアーキテクチャを十分な情報に基づいて決定できます。

この特定のワークロードでは、Graviton2 プロセッサでの関数の実行速度が大幅に向上し、ユーザーエクスペリエンスが向上し、コストが大幅に削減されます。
異なるアーキテクチャの Lambda パワーチューニングを比較する
友人の Alex Casalboni 氏が作成した AWS Lambda Power Tuning オープンソースプロジェクトは、さまざまな設定を使用して関数を実行し、コストを最小限に抑えたり、パフォーマンスを最大化したりするための設定を提案します。このプロジェクトは最近更新され、同じチャートの 2 つの結果を比較できるようになりました。これは、同じ関数の 2 つのバージョンを比較するのに便利です。1 つは x86 を使用し、もう 1 つは Arm を使用するバージョンです。
例えば、次のチャートは、この記事の前半で使用した素数を計算する関数について、x86 と Arm/Graviton2 の結果を比較しています。
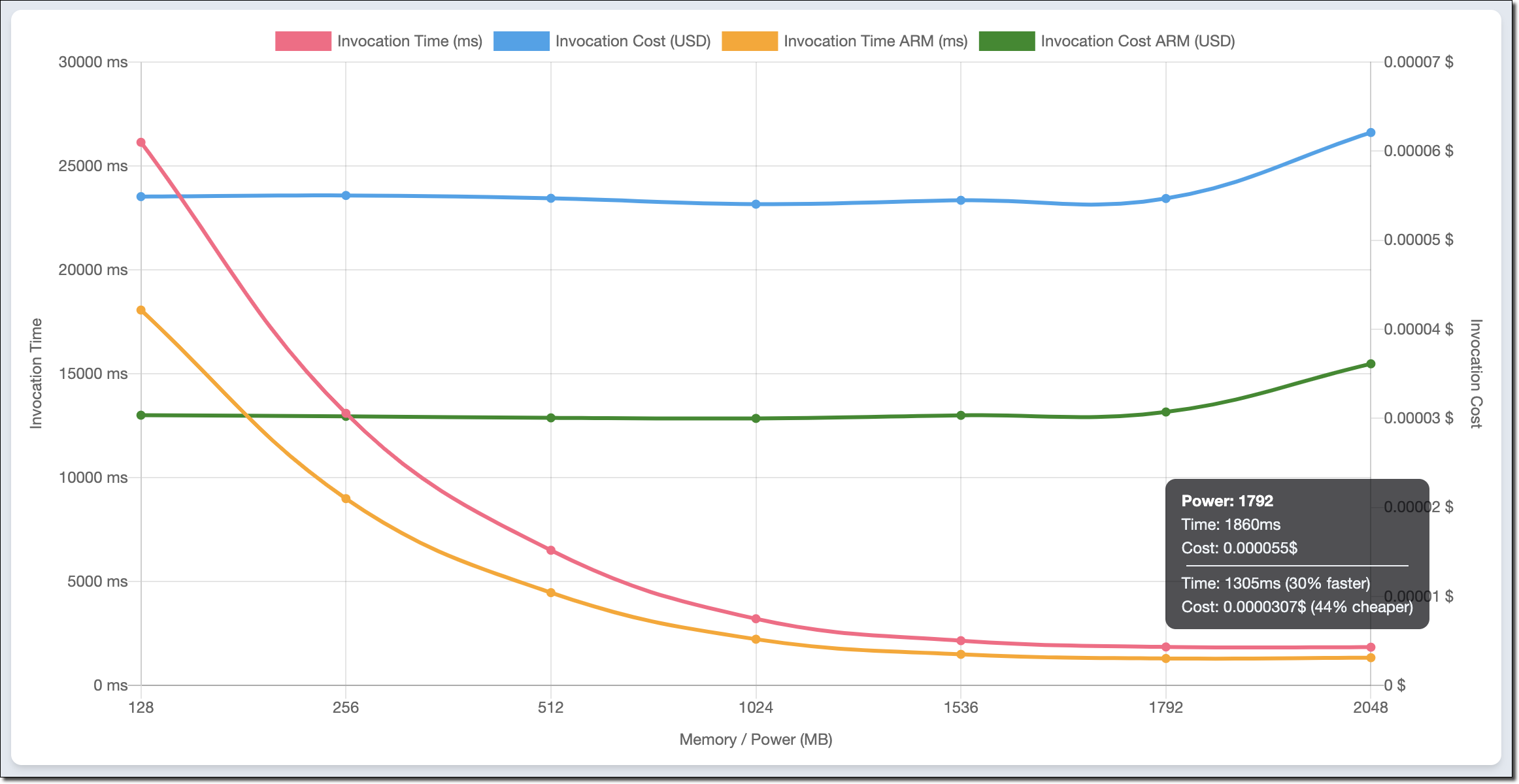
この関数は単一のスレッドを使用しています。実際、メモリが 1.8 GB で設定されている場合、両方のアーキテクチャで最も低い期間が報告されます。それ以上では、Lambda 関数は複数の vCPU にアクセスできますが、この場合、関数は追加のパワーを使用できません。同じ理由で、最大 1.8 GB のメモリでコストは安定しています。メモリが増えると、このワークロードには追加のパフォーマンス上の利点がないため、コストが増加します。
チャートを見て、1.8 GB のメモリと Arm アーキテクチャを使用するように関数を設定します。Graviton2 プロセッサは、この計算負荷の高い機能に対して、優れたパフォーマンスをもたらし、コストを削減していることは明らかです。
利用可能なリージョンと料金
現在、Graviton2 プロセッサを搭載した Lambda Functions は、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、欧州 (フランクフルト)、欧州 (アイルランド)、欧州 (ロンドン)、アジアパシフィック (ムンバイ)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京) の各リージョンでご利用いただけます。
Amazon Linux 2 上で実行される次のランタイムは、Arm でサポートされています。
- Node.js 12 および 14
- Python 3.8 および 3.9
- Java 8 (
java8.al2) および 11 - .NET Core 3.1
- Ruby 2.7
- カスタムランタイム (
provided.al2)
AWS Serverless Application Model (SAM) と AWS Cloud Development Kit (AWS CDK) を使用して、Graviton2 プロセッサを搭載した Lambda 関数を管理できます。また、サポートは、AntStack、Check Point、Cloudwiry、Contino、Coralogix、Datadog、Lumigo、Pulumi、Slalom、Sumo Logic、Thundra、Xerris など、多くの AWS Lambda パートナーを通じてもご利用いただけます。
Arm/Graviton2 アーキテクチャを使用する Lambda 関数は、料金パフォーマンスを最大 34% 向上させます。期間コストの 20% 削減は、プロビジョニングされた同時実行を使用する場合にも適用されます。Compute Savings Plans を使用すると、コストを最大 17% 削減できます。Graviton2 を搭載した Lambda 関数は、既存の制限まで AWS 無料利用枠をご利用いただけます。詳細については、AWS Lambda の料金ページを参照してください。
AWS Graviton2 プロセッサのワークロードを最適化するためのヘルプについては、AWS Graviton の使用開始リポジトリをご覧ください。
– Danilo