Amazon Web Services ブログ
AWS Step Functions で機械学習パイプラインを構築する際の選択肢と、その定義・実行方法
この記事は “Define and run Machine Learning pipelines on Step Functions using Python, Workflow Studio, or States Language” を翻訳したものです。
機械学習(ML)のパイプラインや有向非巡回グラフ(DAG)を定義して実行する際には、様々なツールが利用可能です。一般的な選択肢としては、 AWS Step Functions、Apache Airflow、KubeFlow Pipelines(KFP)、TensorFlow Extended(TFX)、Argo、Luigi、Amazon SageMaker Pipelines などがあります。これらのツールは様々な言語 (JSON、YAML、Python など ) で構築可能です。また、ワークフローオーケストレーターを利用してそれらを表示、実行することもできます。これらのツールの詳細な比較はこの投稿では扱いません。詳細な比較を行うためにはお客様のユースケースに合わせて適切なツールを選択し、ベンチマークを実施する必要があります。
この投稿では、Step Functions でエンドツーエンドの ML パイプラインを作成する方法を 3 つご紹介します。
- Python – Step Functions Data ScienceSDK を使う方法
- ドラッグアンドドロップ – 新しいStep Functions Workflow Studio を使う方法
- JSON – Amazon States Language を使う方法
ソリューション概要
この投稿では、学習、モデルの作成、エンドポイントの構成、モデルのデプロイを含む簡単なワークフローを作成します。

この投稿では扱いませんが、Amazon SageMaker Processing や自動モデルチューニング (HPO) などを含むより複雑なワークフローを作成することもできます。また、Step Functions を用いて他のAWSサービス、例えばAWS Lambda、Amazon DynamoDB、AWS Glue、Amazon EMR、Amazon Athena、Amazon Elastic Kubernetes Service (Amazon EKS)、AWS Fargate との連携も可能です。より詳細な情報については Step Functions がサポートする統合の公式ドキュメントを御覧ください。また、他の類似パイプラインツールについてはこの投稿の後半で説明します。
この投稿では、MNIST データセットを使用します。MNIST は手書き数字の分類に広く使用されているデータセットです。そして手書き数字の 70,000 個のラベル付き 28×28 ピクセルのグレースケール画像で構成されています。さらにこのデータセットは 60,000 の学習用画像と 10,000 のテスト用画像に分割されます。また 0-9 までの 10 個のクラスがあります。ここで使用されるコードは、類似のユースケースを忠実に踏襲しており、タスクは 10 種類の入力画像を分類することです。
メインの学習コードではモデルの定義の際、PyTorch のサンプルを利用しています。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)main で呼び出される学習用に定義された関数は、単一のインスタンスでの学習と分散学習の両方に対応しており、引数の変更により使い分けが可能です。
is_distributed = len(args.hosts) > 1 and args.backend is not None
if is_distributed:
# Initialize the distributed environment.
world_size = len(args.hosts)
os.environ['WORLD_SIZE'] = str(world_size)
host_rank = args.hosts.index(args.current_host)
os.environ['RANK'] = str(host_rank)
dist.init_process_group(backend=args.backend, rank=host_rank, world_size=world_size)
logger.info('Initialized the distributed environment: \'{}\' backend on {} nodes. '.format(
args.backend, dist.get_world_size()) + 'Current host rank is {}. Number of gpus: {}'.format(
dist.get_rank(), args.num_gpus)) ホストの数は Amazon SageMaker の環境変数に保存されます。この変数は引数として渡すこともできます。
parser.add_argument('--hosts', type=list, default=json.loads(os.environ['SM_HOSTS']))
次に、デフォルトのデータディレクトリからデータセットを読み込みます。
train_loader = _get_train_data_loader(args.batch_size, args.data_dir, is_distributed, **kwargs)
test_loader = _get_test_data_loader(args.test_batch_size, args.data_dir, **kwargs)次にメインの学習ループを実行します。
for epoch in range(1, args.epochs + 1):
model.train()最後にモデルを保存します。
def save_model(model, model_dir):
logger.info("Saving the model.")
path = os.path.join(model_dir, 'model.pth')
# recommended way from http://pytorch.org/docs/master/notes/serialization.html
torch.save(model.cpu().state_dict(), path)このコードはmnist.pyというファイルに保存されており、次のステップで使用します (コードの全文は GitHub をご覧ください)。パイプラインについては以下の 2 つの重要ポイントがあります。
- パイプラインの TrainingStep のパラメーターとして、Amazon Simple Storage Service (Amazon S3) 上の場所を指定できます。このデータは学習用コンテナに提供され、そのローカルパスは環境変数 (たとえば
SAGEMAKER_CHANNEL_TRAINING) に保存されます。 - ここで示したモデルは、
model_dirにローカル保存されます。そのディレクトリのローカルパス (/opt/ml/model) は、環境変数 (SM_MODEL_DIR) に格納されています。SageMakerトレーニングジョブが終了すると、モデルは Amazon S3 にコピーされ、モデルとエンドポイントに関連するパイプラインステップがモデルにアクセスできるようになります。
それでは、Step Functions でエンドツーエンドの ML パイプラインを作成する 3 つの方法をご紹介します。
Step Functions Data Science SDKの使用
Step Functions Data Science SDK はワークフローをすべて Python で作成できるオープンソースのライブラリです。この SDK のインストールは次のコードを入力するだけで簡単にできます。
pip install stepfunctionsこの SDK では、以下のことが可能です。
- タスクを達成するためのステップの作成
- ステップ同士をワークフローとしてつなげること
- 並列と条件分岐
- 再試行、成功または失敗として終了させるステップをワークフローに含めること
- ワークフローのグラフィカルな表示と定義の確認
- Step Functions でワークフローを作成
- Step Functions での実行と確認
これらの関数の多くを使用することはありませんが、Step Functions Data Science SDK には以下のものを含めることができます。
- Pass、Fail、Succeed、Waitなどの標準的な状態
- Choice ルール
- AWS Lambda、AWS Batch、AWS Glue、Amazon Elastic Container Service (Amazon ECS) などのCompute 系サービスのステップ
- SageMaker 固有のステップ
- DynamoDB、Amazon Simple Notification Service (Amazon SNS)、Amazon Simple Queue Service (Amazon SQS)、Amazon EMR を始めとする他のAWSサービスとの統合
まず最初に、mnist.py ファイルで PyTorch Estimator を作成します。Estimator の設定をするために、学習用スクリプト、AWS Identity and Access Management (IAM) ロール、トレーニングインスタンスの数、トレーニングインスタンスの種類、ハイパーパラメータをセットします。
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point='mnist.py',
role=sagemaker_execution_role,
framework_version='1.2.0',
py_version='py3',
train_instance_count=2,
train_instance_type='ml.c4.xlarge',
hyperparameters={
'epochs': 6
})Data Science SDK ではパイプラインを定義する方法が 2 つ用意されています。まず個々のステップを使用することができます。例えば、以下のコードで TrainingStep を定義できます。
training_step = steps.TrainingStep("Train Step",estimator=estimator,...)次に、モデルステップを作成します。
model_step = steps.ModelStep("Savemodel", model=training_step.get_expected_model(),...):最後に、次のコードを使ってすべてのステップをつなげます。
workflow_definition = steps.Chain([training_step, model_step, transform_step, endpoint_config_step, endpoint_step])詳細については、「 Step Functionsと SageMaker を使用した機械学習ワークフローの構築」を参照してください。
または、 SDK に組み込まれている標準の TrainingPipeline クラスを使用することもできます。
pipeline = TrainingPipeline(
estimator=estimator,
role=workflow_execution_role,
inputs=inputs,
s3_bucket=bucket
)ワークフローを実行する用のロールでは、Step Functionsでワークフローを作成・実行することができます。以下のコードでは、目的のワークフローを作成し、同じものをレンダリングすることができます。
pipeline.render_graph()
最後に pipeline.create() と pipeline.execute()を使って、ワークフローの作成と実行を行います。
execute() 実行後の出力例は以下のようになり、実行内容を確認および監視できる Step Functions へのリンクが表示されます。
arn:aws:states:us-east-1:account-number:execution:training-pipeline-generated-date:training-pipeline-generated-time
また、以下のコードを使用して、ノートブックから実行されるワークフローの現在の状態をレンダリングすることもできます。
execution.render_progress()Step Functions Workflow Studioを使用する
Step Functions Workflow Studio を使用するには、次の手順で実行します。
- ステップ関数コンソールで、[Create state machine] を選択します。
- [Design you workflow visually] を選択します。
- [Next] を選択します。
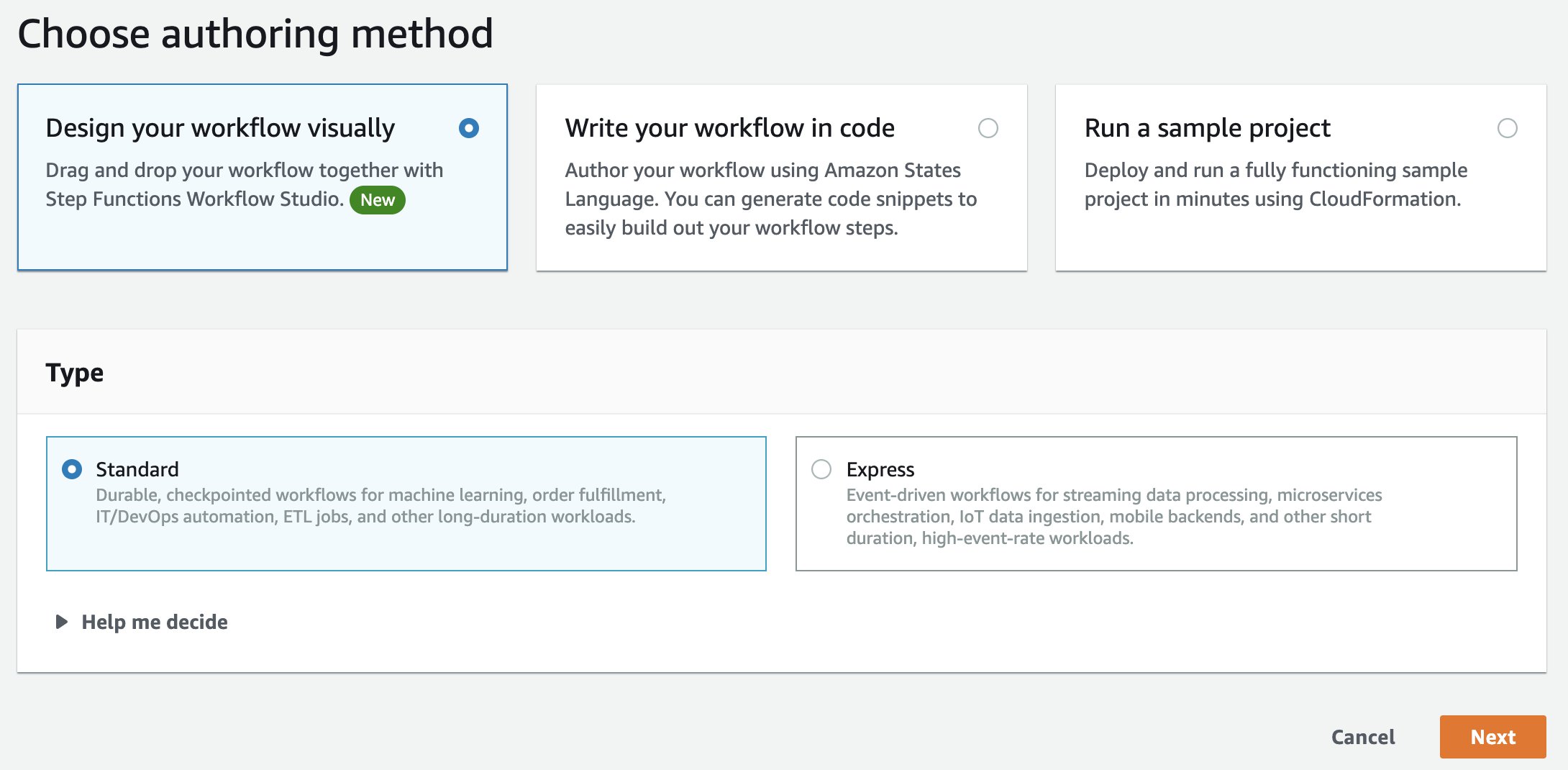
- SageMaker のステップを入力してフィルタリングし、TrainingStep にドラッグアンドドロップします。

- 同様の方法で、次の状態を順番にドラッグアンドドロップします
- モデルの作成
- エンドポイント構成の作成
- エンドポイントの作成
これで、ワークフローは次の図のようになるはずです。
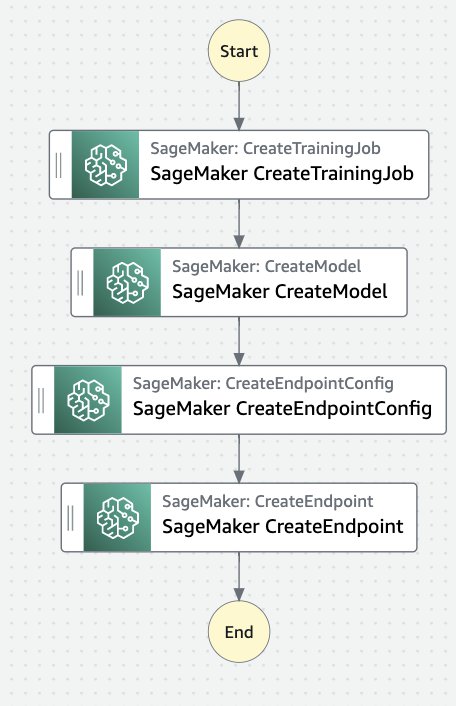
では、それぞれの各ステップを構成してみましょう。 - SageMaker CreateTrainingJob を選択し、[Form] ボックスでAPIパラメーターを編集します。

- この例に従う場合は、次の JSON オブジェクトを使用します。
{ "AlgorithmSpecification": { "TrainingImage": "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-cpu-py3", "TrainingInputMode": "File" }, "HyperParameters": { "epochs": "6", "sagemaker_submit_directory.$": "$$.Execution.Input.sourcedir", "sagemaker_program.$": "$$.Execution.Input.trainfile" }, "InputDataConfig": [ { "ChannelName": "training", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://sagemaker-us-east-1-497456752804/sagemaker/DEMO-pytorch-mnist", "S3DataDistributionType": "FullyReplicated" } } } ], "StoppingCondition": { "MaxRuntimeInSeconds": 1000 }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.xlarge", "VolumeSizeInGB": 30 }, "OutputDataConfig": { "S3OutputPath": "s3://sagemaker-us-east-1-497456752804/stepfunctions-workflow-training-job-v1/models" }, "RoleArn": "arn:aws:iam::497456752804:role/telecomstack-SagemakerExecutionRole-AHSGUPY5EQIK", "TrainingJobName.$": "States.Format('trainingjob-{}',$$.Execution.Name)" } - [Wait for task to complete] を選択します。
CreateModelの API パラメータを編集します。{ "ExecutionRoleArn.$": "$.RoleArn", "ModelName.$": "States.Format('model-{}',$$.Execution.Name)", "PrimaryContainer": { "Image.$": "$.AlgorithmSpecification.TrainingImage", "Environment": { "SAGEMAKER_PROGRAM.$": "$$.Execution.Input.trainfile", "SAGEMAKER_SUBMIT_DIRECTORY.$": "$$.Execution.Input.sourcedir" }, "ModelDataUrl.$": "$.ModelArtifacts.S3ModelArtifacts" } }CreateEndpointConfigの API パラメータを編集します。{ "EndpointConfigName.$": "States.Format('config-{}',$$.Execution.Name)", "ProductionVariants": [ { "InitialInstanceCount": 1, "InitialVariantWeight": 1, "InstanceType": "ml.m4.xlarge", "ModelName.$": "States.Format('model-{}',$$.Execution.Name)", "VariantName": "AllTraffic" } ] }CreateEndpointの API パラメータを編集します。{ "EndpointConfigName.$": "States.Format('config-{}',$$.Execution.Name)", "EndpointName.$": "States.Format('endpoint-{}',$$.Execution.Name)" }- [Next] を選択し、生成されたコードを確認して、[Next] を選択します。Step Functions は、あなたが使用するリソースを調べて、ロール を作成することができます。ただし、次のメッセージが表示される場合があります。
Step Functions cannot generate an IAM policy if the RoleArn for SageMaker is from a Path. Hardcode the SageMaker RoleArn in your state machine definition, or choose an existing role with the proper permissions for Step Functions to call SageMaker.( 訳 : SageMaker の RoleArn が Path からのものである場合、Step Functions は IAM ポリシーを生成できません。ステートマシン定義で SageMaker の RoleArn をハードコードするか、Step Functions が SageMaker を呼び出すための適切な権限を持つ既存ロールを選択してください )
ここでは、Data Science SDK セクションで作成したロールを代わりに使用します。 - [Use existing role]を選択し、
StepFunctionsWorkflowExecutionRoleを使用します。

- [Create state machine] を選択します。
- マシンの作成に成功したというメッセージが表示されたら、次のように入力して実行します。
{ "trainfile":"mnist.py", "sourcedir":"s3://path/to/sourcedir.tar.gz" }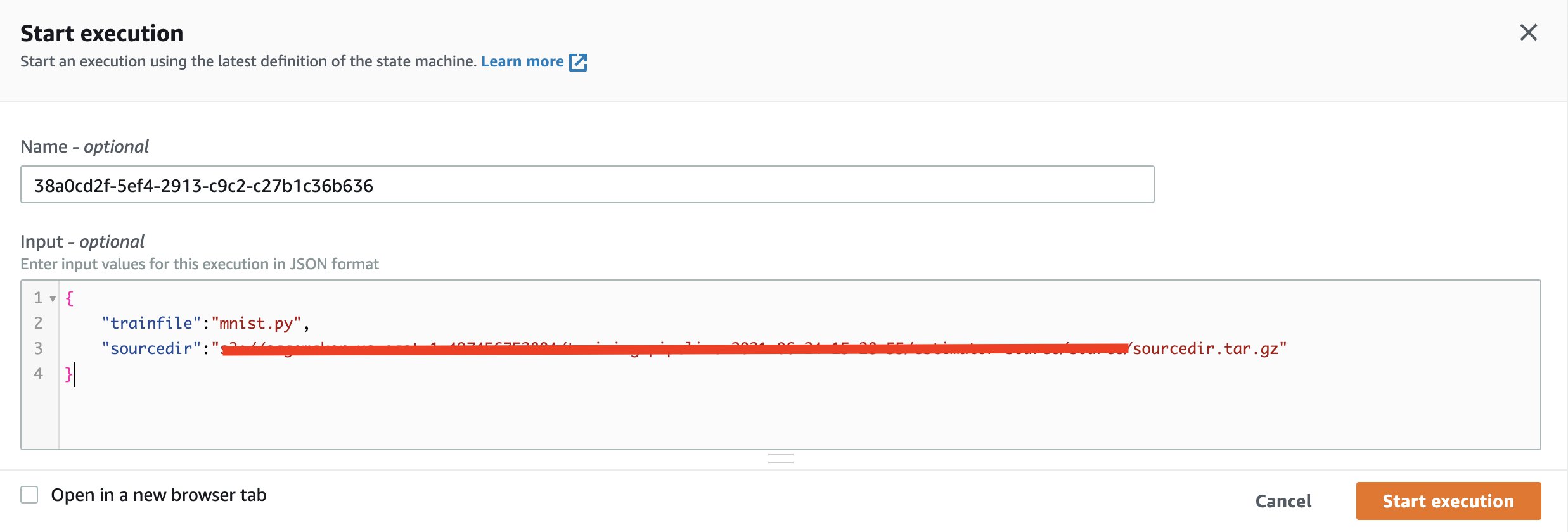
実行が終了するまで待ちます。
Amazon States Language を使用する
先ほど説明した方法はいずれも、Step Functions 上でステートマシンのプロトタイプを素早く作成するのに優れた方法です。Step Functions の定義を直接編集する必要がある場合は、Amazon States Language を使用します。次のコードをご覧ください。
{
"Comment": "This is your state machine",
"StartAt": "SageMaker CreateTrainingJob",
"States": {
"SageMaker CreateTrainingJob": {
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createTrainingJob.sync",
"Parameters": {
"AlgorithmSpecification": {
"TrainingImage": "763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:1.2.0-cpu-py3",
"TrainingInputMode": "File"
},
"HyperParameters": {
"epochs": "6",
"sagemaker_submit_directory.$": "$$.Execution.Input.sourcedir",
"sagemaker_program.$": "$$.Execution.Input.trainfile"
},
"InputDataConfig": [
{
"ChannelName": "training",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://sagemaker-us-east-1-497456752804/sagemaker/DEMO-pytorch-mnist",
"S3DataDistributionType": "FullyReplicated"
}
}
}
],
"StoppingCondition": {
"MaxRuntimeInSeconds": 1000
},
"ResourceConfig": {
"InstanceCount": 2,
"InstanceType": "ml.c4.xlarge",
"VolumeSizeInGB": 30
},
"OutputDataConfig": {
"S3OutputPath": "s3://sagemaker-us-east-1-497456752804/stepfunctions-workflow-training-job-v1/models"
},
"RoleArn": "arn:aws:iam::497456752804:role/telecomstack-SagemakerExecutionRole-AHSGUPY5EQIK",
"TrainingJobName.$": "States.Format('trainingjob-{}',$$.Execution.Name)"
},
"Next": "SageMaker CreateModel"
},
"SageMaker CreateModel": {
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createModel",
"Parameters": {
"ExecutionRoleArn.$": "$.RoleArn",
"ModelName.$": "States.Format('model-{}',$$.Execution.Name)",
"PrimaryContainer": {
"Image.$": "$.AlgorithmSpecification.TrainingImage",
"Environment": {
"SAGEMAKER_PROGRAM.$": "$$.Execution.Input.trainfile",
"SAGEMAKER_SUBMIT_DIRECTORY.$": "$$.Execution.Input.sourcedir"
},
"ModelDataUrl.$": "$.ModelArtifacts.S3ModelArtifacts"
}
},
"Next": "SageMaker CreateEndpointConfig"
},
"SageMaker CreateEndpointConfig": {
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createEndpointConfig",
"Parameters": {
"EndpointConfigName.$": "States.Format('config-{}',$$.Execution.Name)",
"ProductionVariants": [
{
"InitialInstanceCount": 1,
"InitialVariantWeight": 1,
"InstanceType": "ml.m4.xlarge",
"ModelName.$": "States.Format('model-{}',$$.Execution.Name)",
"VariantName": "AllTraffic"
}
]
},
"Next": "SageMaker CreateEndpoint"
},
"SageMaker CreateEndpoint": {
"Type": "Task",
"Resource": "arn:aws:states:::sagemaker:createEndpoint",
"Parameters": {
"EndpointConfigName.$": "States.Format('config-{}',$$.Execution.Name)",
"EndpointName.$": "States.Format('endpoint-{}',$$.Execution.Name)"
},
"End": true
}
}
}Step Functions コンソールで [Write your workflow in code] を選択すると、新しい Step Functions ステートマシンを作成できます。

実行が成功すると、各状態が緑色で表示されます。
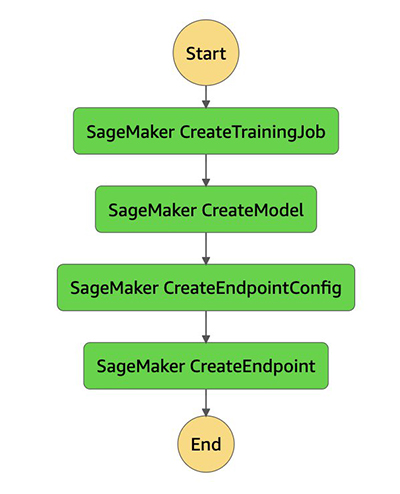
各状態は SageMaker のリソースを指します。次のスクリーンショットにある[Resource] のリンクは、CreateModelステップの結果として作成されたモデルを指しています。

いつ何を使うべきか?
次の表は、サポートされているサービス統合をまとめたものです。
※この表は2021/09/03時点のものであり、今後変更される可能性があります
| サポートする サービス | Amazon States Language | (New) Step Functions Workflow Studio | AWS Step Functions Data Science SDK |
| AWS Lambda | ✓ | ✓ | ✓ |
| AWS Batch | ✓ | ✓ | ✓ |
| Amazon DynamoDB | ✓ | ✓ | ✓ |
| Amazon ECS/AWS Fargate | ✓ | ✓ | ✓ |
| Amazon SNS | ✓ | ✓ | ✓ |
| Amazon SQS | ✓ | ✓ | ✓ |
| AWS Glue | ✓ | ✓ | ✓ |
| Amazon SageMaker | ✓ | ✓ | ✓ |
| Amazon EMR | ✓ | ✓ | ✓ |
| Amazon EMR on EKS | ✓ | ✓ | |
| AWS CodeBuild | ✓ | ✓ | |
| Amazon Athena | ✓ | ✓ | |
| Amazon EKS | ✓ | ✓ | |
| Amazon API Gateway | ✓ | ✓ | |
| AWS Glue DataBrew | ✓ | ✓ | |
| Amazon EventBridge | ✓ | ✓ | |
| AWS Step Functions | ✓ | ✓ |
パイプラインに通常必要なもののほとんどは Step Functions Data Science SDK に含まれていますが、前の表にある一部のサービスには他の方法で統合する必要があるものもあります。
また、既存チームのスキルセットを考慮する必要があります。特定のツールに慣れているチームは生産性を最大化するために同じツールを使用することを好むかもしれません。これは今回紹介したStep Functionsだけでなく AWS Cloud Development Kit (AWS CDK)、AWS Serverless Application Model (AWS SAM)、Airflow、KubeFlow、SageMaker Pipelines などを考慮するときも同様です。特にパイプラインに関しては、データサイエンティストや ML エンジニアは、パイプラインの維持及び実行だけでなく、モデル、エンドポイント、ノートブックなどの管理機能を持つ単一のプラットフォーム上で作業することが有効かもしれません。
最後に、適切なツールを使うためのハイブリッドなサービスを考えてみましょう。例えば
- カスタムコンテナを必要とするMLパイプラインのオーケストレーションには AWS CodePipeline を使用することができます。 CodePipeline は Step Functions を呼び出し、コンテナイメージの URI と固有のコンテナイメージタグをパラメータとして Step Functions に渡します。詳細については Build a CI/CD pipeline for deploying custom machine learning models using AWS services を参照してください。
- Kubeflow Pipelinesを使用して学習パイプラインを定義し、SageMakerを使用して学習済みモデルをクラウド上でホストできます。詳細については Cisco uses Amazon SageMaker and Kubeflow to create a hybrid machine learning workflow を参照してください。
- SageMaker Data Wrangler と SageMaker Feature Store を使用して、特徴量エンジニアリングのパイプラインを自動化できます。これらのパイプラインツールには ML モデルの構築とデプロイを目的とした CI/CD 機能も有しており、ワークフローのオーケストレーションだけでなく、モデルレジストリや、系統追跡 (lineage tracking)、プロジェクトなどの概念にも繋がりがあります。AWS サービスを利用してデータを準備するなど、上流工程ですでに Step Functions を使用している場合は、Step Functions とパイプラインツールの両方を使用するハイブリッドアーキテクチャの採用を検討してください。詳しくは Automate feature engineering pipelines with Amazon SageMaker をご覧ください。
- 開発者やデータサイエンティストが単体テストを使用してインフラストラクチャをコードとして作成する必要がある場合は、Python を使用してエンドツーエンドのアーキテクチャとパイプラインを定義できるため、 AWS Data ScienceSDK や ApacheAirflow などのツールの使用を検討してください。
まとめ
この投稿ではエンドツーエンドの ML ワークフローのための Step Functions パイプラインを、作成および実行する 3 つの異なる方法について説明しました。MLのパイプラインツールを選択することは、チームにとって重要なステップであり、各チームの事情、既存のスキルセット、組織内のこれらのスキルセットをもつ様々な他チームとの連携、利用可能なサービス統合、サービスの制限、および適用可能なクォータを考慮する必要があります。このような決定を行う際にはぜひ AWS にご相談ください。
更に詳しく知りたい方は、以下のサイトをご覧ください。
- New – AWS Step Functions Workflow Studio – A Low-Code Visual Tool for Building State Machines
- The step-functions-data-science-sdk GitHub repo
- Prototyping at speed with AWS Step Functions new Workflow Studio
- Introducing Amazon Managed Workflows for Apache Airflow (MWAA)
- Introducing Amazon SageMaker Components for Kubeflow Pipelines
著者について

Shreyas Subramanian
Shreyas Subramanianは、AI / MLスペシャリストのソリューションアーキテクトです。AWS上で機械学習を使用し、お客様のビジネス上の課題を解決するご支援をしています。
