Artificial Intelligence

Author: Shreyas Subramanian
Shreyas Subramanian is a Principal data scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.

Implementing programmatic tool calling on Amazon Bedrock
In this post, we show three ways to implement Programmatic tool calling (PTC) on Amazon Bedrock: a self-hosted Docker sandbox on ECS for maximum control, a managed solution using Amazon Bedrock AgentCore Code Interpreter, and an Anthropic SDK-compatible path through a proxy for teams that prefer that developer experience.

Reinforcement fine-tuning on Amazon Bedrock with OpenAI-Compatible APIs: a technical walkthrough
In this post, we walk through the end-to-end workflow of using RFT on Amazon Bedrock with OpenAI-compatible APIs: from setting up authentication, to deploying a Lambda-based reward function, to kicking off a training job and running on-demand inference on your fine-tuned model.
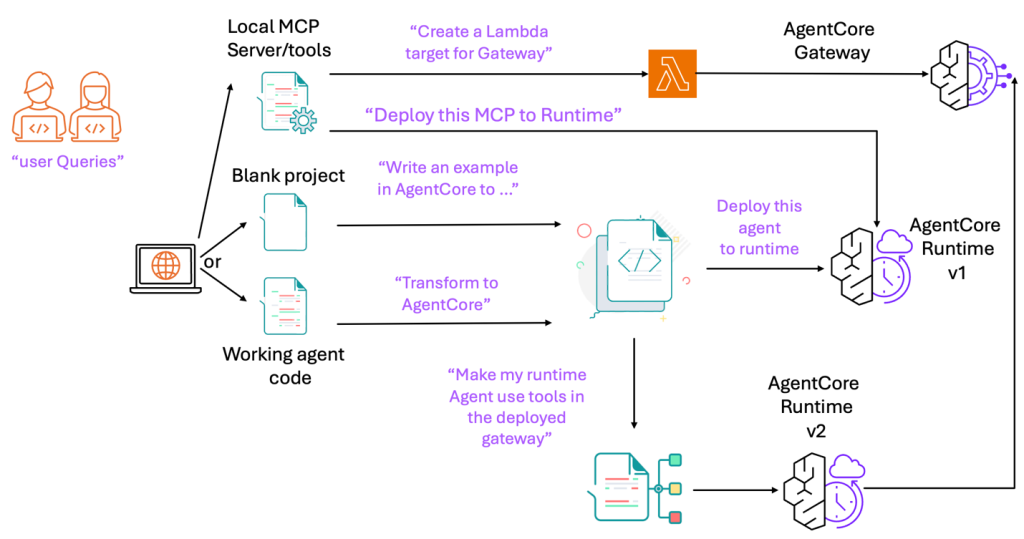
Accelerate development with the Amazon Bedrock AgentCore MCP server
Today, we’re excited to announce the Amazon Bedrock AgentCore Model Context Protocol (MCP) Server. With built-in support for runtime, gateway integration, identity management, and agent memory, the AgentCore MCP Server is purpose-built to speed up creation of components compatible with Bedrock AgentCore. You can use the AgentCore MCP server for rapid prototyping, production AI solutions, […]

Securely launch and scale your agents and tools on Amazon Bedrock AgentCore Runtime
In this post, we explore how Amazon Bedrock AgentCore Runtime simplifies the deployment and management of AI agents.

Use custom metrics to evaluate your generative AI application with Amazon Bedrock
Now with Amazon Bedrock, you can develop custom evaluation metrics for both model and RAG evaluations. This capability extends the LLM-as-a-judge framework that drives Amazon Bedrock Evaluations. In this post, we demonstrate how to use custom metrics in Amazon Bedrock Evaluations to measure and improve the performance of your generative AI applications according to your specific business requirements and evaluation criteria.

Use Amazon Bedrock Intelligent Prompt Routing for cost and latency benefits
Today, we’re happy to announce the general availability of Amazon Bedrock Intelligent Prompt Routing. In this blog post, we detail various highlights from our internal testing, how you can get started, and point out some caveats and best practices. We encourage you to incorporate Amazon Bedrock Intelligent Prompt Routing into your new and existing generative AI applications.

Optimize reasoning models like DeepSeek with Prompt Optimization on Amazon Bedrock
In this post, we demonstrate how to optimize reasoning models like DeepSeek-R1 using prompt optimization on Amazon Bedrock.

Improve the performance of your Generative AI applications with Prompt Optimization on Amazon Bedrock
Today, we are excited to announce the availability of Prompt Optimization on Amazon Bedrock. With this capability, you can now optimize your prompts for several use cases with a single API call or a click of a button on the Amazon Bedrock console. In this post, we discuss how you can get started with this new feature using an example use case in addition to discussing some performance benchmarks.

Build cost-effective RAG applications with Binary Embeddings in Amazon Titan Text Embeddings V2, Amazon OpenSearch Serverless, and Amazon Bedrock Knowledge Bases
Today, we are happy to announce the availability of Binary Embeddings for Amazon Titan Text Embeddings V2 in Amazon Bedrock Knowledge Bases and Amazon OpenSearch Serverless. This post summarizes the benefits of this new binary vector support and gives you information on how you can get started.

Build powerful RAG pipelines with LlamaIndex and Amazon Bedrock
In this post, we show you how to use LlamaIndex with Amazon Bedrock to build robust and sophisticated RAG pipelines that unlock the full potential of LLMs for knowledge-intensive tasks.