Artificial Intelligence
Automatically detect sports highlights in video with Amazon SageMaker
July 2023: Please refer to the Media Replay Engine (MRE) solution presented in this Github repo instead, for the latest and more efficient solution for this use case. MRE is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live and video-on-demand (VOD) content.
Extracting highlights from a video is a time-consuming and complex process. In this post, we provide a new take on instant replay for sporting events using a machine learning (ML) solution for automatically creating video highlights from original video content. Video highlights are then available for download so that users can continue to view them via a web app.
We use Amazon SageMaker to analyze a full-length sports video (in our case, a soccer match) and tag segments of the original video that are highlights (penalty kicks). We also show how to apply our end-to-end architecture to not only other sports, but other types of videos, given the availability of appropriate training data.
Architecture overview
The following diagram depicts our solution architecture.
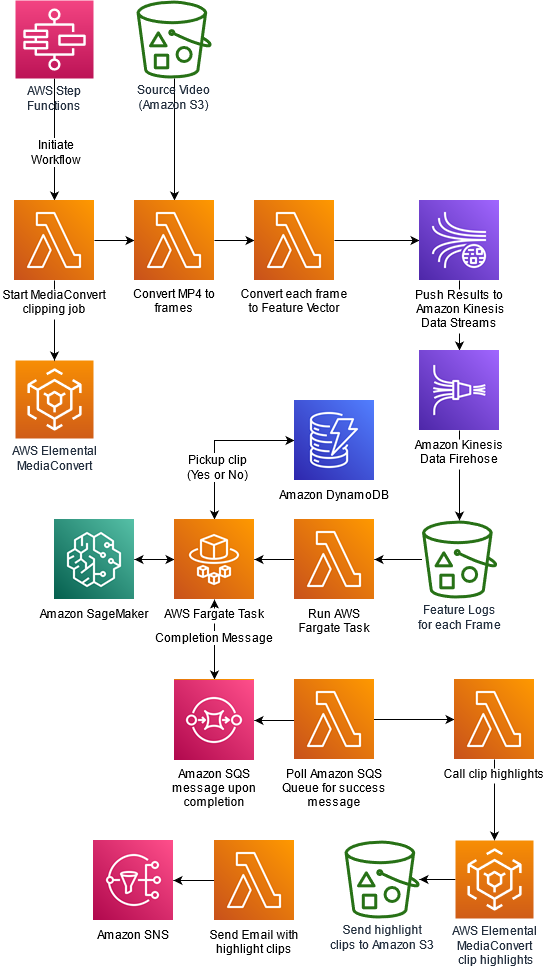
Orchestration overview
We use AWS Lambda functions as part of the following AWS Step Functions workflow to orchestrate a series of AWS Lambda functions for each step of the process.
The first step of the workflow is to start a MediaConvert job that breaks down the video into individual frames. Once the MediaConvert job completes, a Lambda Function converts each frame to a feature vector. The Lambda function generates feature vectors by passing individual images through a pretrained model (Inception V3). These feature vectors are then sent as topics via Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose, and are finally stored in Amazon S3. Next step of the workflow is to invoke a machine learning model to infer if a video segment is interesting enough to pick up based on the sequence of feature vectors. The model determines what actions defined in the UCF101 labels are seen in the video. Here, AWS Fargate acts as a driver that loops through all sequences of feature vectors, prepares them for inference, performs inference using a SageMaker endpoint, and then collates results in an Amazon DynamoDB table. After the Fargate task completes, a message is placed in an Amazon SQS queue. A Lambda function periodically polls this Amazon SQS queue. When a completion message is detected, the Lambda function triggers a MediaConvert job to prepare highlight segments based on the results of machine learning inference. Finally, an email containing links to highlight clips is sent to the email address specified by the user.
Methodology
We use deep learning techniques to identify an activity in a given video. We use a deep Convolutional Neural Network (CNN) based on a pretrained Inception V3 model—to generate features from images extracted from video, and use a LSTM (Long Short-Term memory) network for predicting actions from sequences of features. Both CNN and LSTM are types of neural networks used in ML-based computer vision solutions. Let’s briefly discuss neural networks and related terms before we jump into 2D-CNN and LSTM.
Neural networks
Neural networks are computer systems vaguely inspired by biological neural networks that constitute animal brains. Just like how the basic unit of the brain is the neuron, the building block of an artificial neural network is a perceptron. Perceptrons do very simple processing. Perceptrons are connected to a large meshed network, which forms a neural network. The neural networks are organized into layers and connections between them are weighted. A neural network isn’t an algorithm, it’s a framework that multiple different ML algorithms can use. We describe different layers in a CNN later in this post when we build a model for extracting features from images extracted from videos.
A neural network is a supervised learning technique in ML. This means that model get better and better as it sees more similar objects, so more training samples results in a better accuracy.
Let’s break down the terms in deep CNNs and understand why this technique is effective in an image recognition. Together with LSTM, we use this technique later for activity identification in a given video.
Deep Convolutional Neural Networks
Deep Convolutional Neural Networks such as Inception V3 and YOLOV5 have proven to be a very effective technique for image recognition and other downstream fine-tuning tasks. More recent vision-transformer based models are also currently being used for state-of-the-art image classification, object detection and segmentation masks. Image recognition has many applications. Something that started as a technique to improve the accuracy of human written digits has evolved to solve more complex problems such as identifying and labeling specific objects and backgrounds in an image.
Although deep CNNs have made the problem of image classification and identification simple and improved the accuracy of results significantly, the implementation of an end-to-end solution from scratch is not a simple task. We recommend using services such as Amazon Rekognition, which provides a state-of-the-art API-based solution for image classification and image recognition solutions. If a custom model is required for solving computer vision problem for either image or video, SageMaker provides a framework for training and inference. SageMaker provides support for multiple ML frameworks using BYOC (bring your own container). We use BYOC in SageMaker for Keras to develop a model for activity recognition and deploy the model for inference.
The convolution technique makes the output of neural networks more robust and accurate because instead of processing every image as a single tile of pixels, it breaks an image into multiple tiles using a sliding window of fixed size. Each tile activates the next layer separately, and all tiles of an image are aggregated in successive layers to generate an output. For example, this allows the digit 8 in the left corner of an image to be identified as the same digit 8 in the right corner of an image. This is a called translation invariance.
LSTM
LSTM networks are types of Recurrent Neural Networks (RNNs), which contain special cells or neurons that allow information to persist due the existence of loops or special memory units. LSTMs in particular are useful in learning tasks involving time sequences of data (like our use case of video classification, which is a time sequence of static frames), especially when there is a need to remember information for long periods of time.
Challenges with video processing
It’s important to keep in mind that videos are like a flip book. The static image on each page when flipped generates the perception of motion. The faster you flip, the better the quality of motion perception you get.
Images are stored as a stream of pixels in a 2D spatial arrangement. This is how a computer program reads images. As an extension of images, videos have an extra dimension of time. Videos are a time series of static images. This makes videos a 3D spatial and temporal arrangement of pixels.
The extra dimension requires more compute and memory to develop an ML model. A lot of preprocessing is required before we can feed video input into CNNs and LSTM.
Apart from increased complexity in preprocessing and processing, there is also the lack of open datasets available for research on video data.
In this post, we use samples provided in the UCF101 dataset for building a model and deploying an endpoint for inference.
Reading a video and extracting frames
Assume that the video source that we’re analyzing in order to extract highlights is in Amazon Simple Storage Service (Amazon S3). We use AWS Elemental MediaConvert to split the video into individual frames, and this MediaConvert job is triggered from the following Lambda function:
Line 22 uses the AWS SDK for Python (Boto3) to initiate the MediaConvert client using the following JSON template. You can specify codec settings, width, height, and other parameters specific to your video format.
While the MediaConvert job is running, another Lambda function checks for job completion. This function is written as follows:
Collect feature vectors for training
Each frame is passed through a pre-trained InceptionV3 model to extract features. The model is small enough to be packaged within the Lambda function along with an ML framework that was used to train the model (MXNet). We don’t describe the image classification model training here, but the overall procedure to do this is as follows:
- Train the InceptionV3 network on MXNet using ILSVRC 2012 data. For details about the network architecture and the dataset, see Rethinking the Inception Architecture for Computer Vision.
- Load the trained model into a Lambda function (
model.jsonandmodel.paramsfiles) and pop the final layer. We’re left with an output layer that doesn’t perform classification, but provides us with a feature vector of size 1024×1. - Each time a frame is passed through the Lambda function, it outputs this feature vector into a data stream, via Amazon Kinesis Data Streams.
- Topics from this stream are collected using Amazon Kinesis Data Firehose and output into another S3 bucket.
- An AWS Fargate job orders the files based on the original order in which the frames appear. Because we trigger 1,000 instances of this Lambda function in parallel with one frame per function, the outputs can be slightly out of order. You can also use SageMaker processing instead of Fargate. This gives us our final training data, which we can use in our SageMaker custom video classification model that can identify groups of frames as highlights. In our example, the highlights in our soccer video are penalty kicks.
The code for this Lambda function is as follows:
Label the images for training the model
As mentioned earlier, we use the UCF101 action recognition dataset, which you can obtain from within a Jupyter notebook instance using the following command:
We extract the same feature vectors from InceptionV3 for all action recognition datasets contained within the .rar file downloaded (it contains several examples of 101 different actions, including ones relevant for our soccer example, such as the soccer penalty and soccer juggling labels.
We construct a custom LSTM model in TensorFlow and use features extracted in the previous step to train the model. The LSTM model is structured as follows:
- Layer 1 – 2048 LSTM cells
- Layer 2 – 512 Dense cells
- Layer 3 – Drop out layer (p=0.5)
- Layer 4 – Softmax layer for 101 classes
Model.summary() provides the following summary:
With a more relevant dataset, you should only include the classes you require in the classification task. Due to the nature of the problem selected, we only had access to this open dataset. However, for extracting highlights from custom videos, you can use your own labeled video datasets.
We save the model using the following code in the notebook:
We create a container containing the following code and Dockerfile, to host the model using SageMaker. The following is the Python entry point code for inference:
We containerize and push the Docker image to Amazon Elastic Container Registry (Amazon ECR):
Lastly, we host the model on SageMaker:
SageMaker provides us with an endpoint to call for predictions where the input is a set of feature vectors (example, 10 frames or images corresponds to a 10×1024 feature matrix), and the output is a probability distribution across the 101 UCF101 classes. We’re only interested in the soccer penalty class. For the purposes of this blog, we use the UCF101 dataset but for your own use cases, do take the time to research relevant action recognition datasets or pretrained models.
Extract highlights
In our architecture, the Fargate job calls the SageMaker estimator sequentially with a set of feature vectors and stores the decision to pick up a set of frames or not in an Amazon DynamoDB table. When the Fargate job is complete, another Lambda function (see the following code) uses the DynamoDB table to edit a clipping job definition and submit the same to a MediaConvert job. This MediaConvert job splits the original video into smaller sections where the desired class of action was identified. In our case, this was the soccer penalty kicks. These extracted videos are then made public for access from outside the account using a Boto3 command from within the same Lambda function.
Deployment Prerequisites
To deploy this solution, you will need to create an Amazon S3 bucket and designate it as an ARTIFACT-BUCKET. This bucket will be used for storing the video file as well as the model artifacts. You could run the follow AWS CLI command to create an Amazon S3 bucket:
Next, un the following command to copy required artifacts to the artifact bucket.
Deploy the solution using AWS CloudFormation
We provide an AWS CloudFormation template for creating resources and setting up the workflow for this post. AWS CloudFormation enables you to model, provision, and manage AWS resources by treating infrastructure as code.
The CloudFormation template requires you to provide an email address that is used for sending links to highlight clips at the end of the workflow. The stack sets up the following resources:
- Step Functions workflow
- Lambda functions
- SageMaker model and endpoint to use for prediction
- Fargate container and service definition
- Amazon VPC and subnet resources for deploying Fargate
- DynamoDB table
- Amazon Simple Queue Service (Amazon SQS) queue
- Amazon Simple Notification Service (Amazon SNS) topic
- Kinesis data stream and Firehose delivery stream
- AWS Identity and Access Management (IAM) roles and policies
Follow these steps to deploy this in your own account:
- Choose Launch Stack:

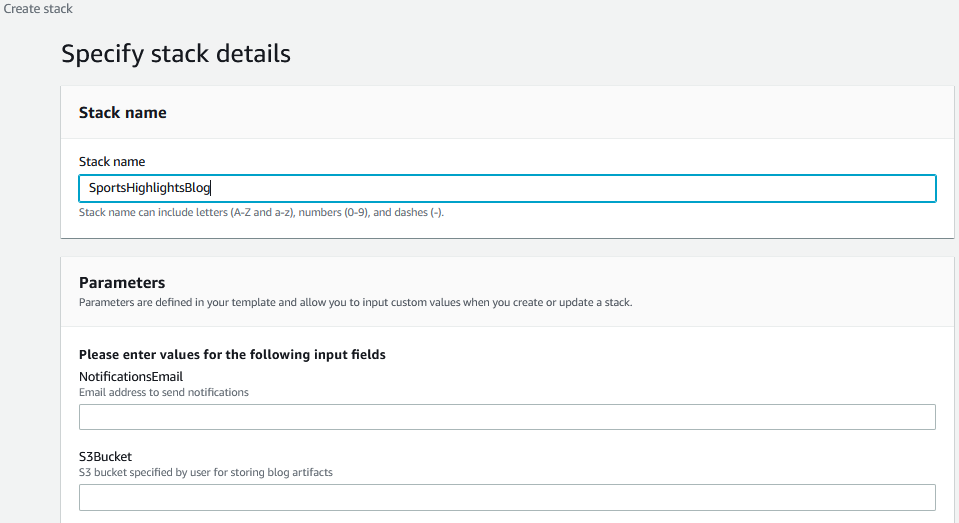
- Enter a name for the stack.
- Enter an email address where you choose to receive notifications from the Step Functions workflow.
- For S4Bucket, enter the name of the
ARTIFACT-BUCKETthat you created earlier. - Choose Next.
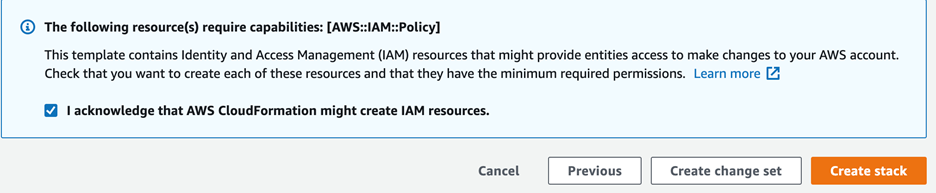
- On the Review page, select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.
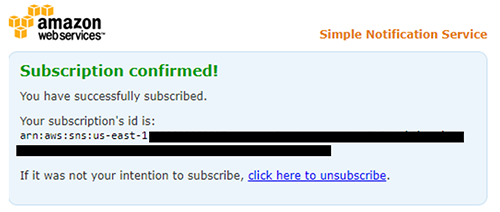
After the stack is successfully created, you will receive an email with a request to subscribe to the topic. Chose ‘Confirm subscription’.

- From the AWS CloudFormation console, navigate to the resources tab for the stack you created. Click on the hyperlink (Physical ID) for the MLStateMachine resource.
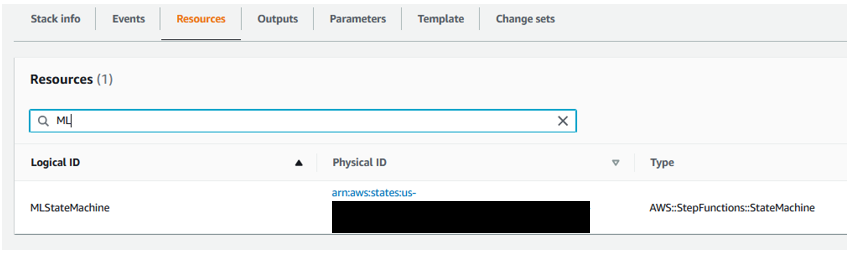
This should navigate you to the Step Functions console. Select ‘Start Execution’.

- Enter a name, select defaults for input and select ‘Start Execution’.
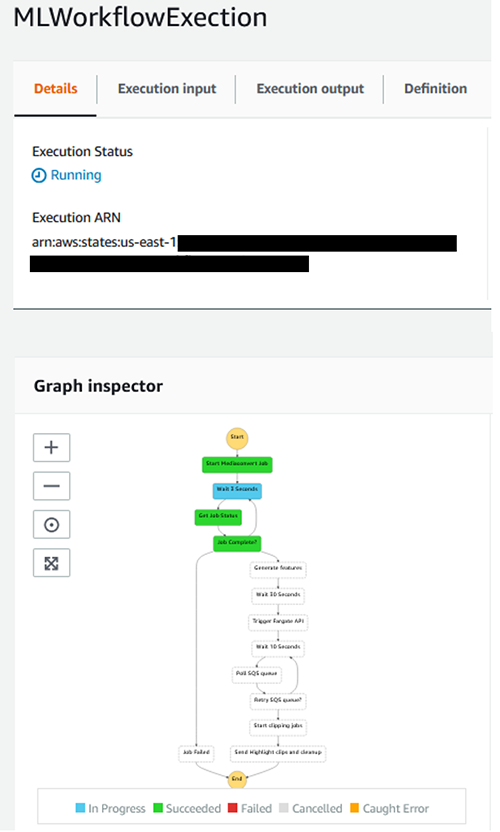
You can monitor progress of the Step Functions execution by navigating to the ‘Graph Inspector’.
Wait for the Step Functions workflow to complete.
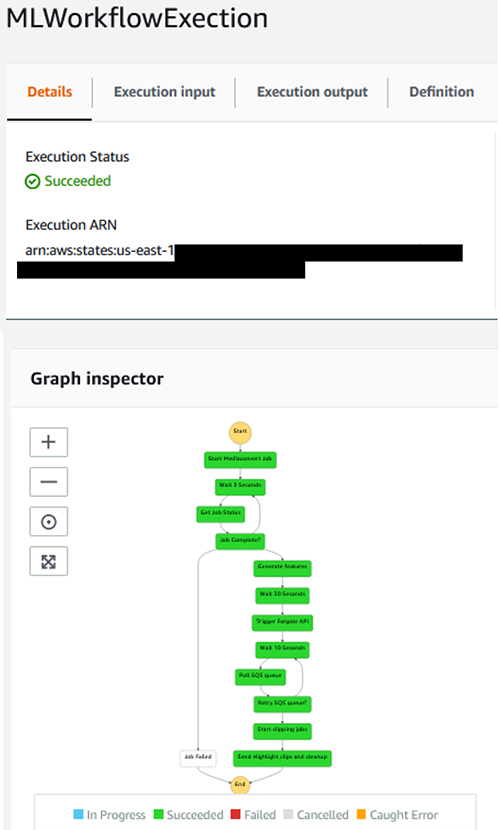
After the Step Functions execution completes, you should receive an email with Amazon S3 files representing the highlight clips from the original video. Following best practices, we do not expose these highlight clips publicly. You could navigate to the Amazon S3 bucket you created and will find the clips in a folder named HighLightclips.

At the end of the process, you should see that the following input video:
generates the following output highlight clip of a penalty kick:
Clean up
To avoid incurring ongoing charges, clean up your infrastructure by deleting the stack from the AWS CloudFormation console.
Empty the artifact bucket that you created for the blog. You could run the following AWS CLI command:
After this, navigate to AWS CloudFormation in AWS Management Console, select the stack you created and select ‘Delete’.
Conclusion
In this post, we showed you how to use a custom SageMaker model to generate sports highlights from full-length sports videos. You can extend this solution to generate highlights containing slam dunks, touch downs, home runs or sixers from your favorite sports videos, or from other shows, movies, meetings, and any other content in a video format – as long as you have a pretrained model, or you train a model specific to your use case.
For more information about how to make preprocessing easier, check out Amazon SageMaker Processing.
For more information about how to fine-tune state-of-the-art action recognition models like PAN Resnet 101, TSM, and R2+1D BERT, or host them on SageMaker as endpoints, see Deploy a Model in Amazon SageMaker.
About the Authors
 Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
Shreyas Subramanian is an AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges on the AWS Cloud.
 Mohit Mehta is a leader in the AWS Professional Services Organization with expertise in AI/ML and Big Data technologies. Mohit holds a M.S in Computer Science, all 12 AWS certifications, MBA from College of William and Mary and GMP from Michigan Ross School of Business.
Mohit Mehta is a leader in the AWS Professional Services Organization with expertise in AI/ML and Big Data technologies. Mohit holds a M.S in Computer Science, all 12 AWS certifications, MBA from College of William and Mary and GMP from Michigan Ross School of Business.
 Vikrant Kahlir is Principal Architect in the Solutions Architecture team. He works with AWS strategic customers product and engineering teams to help them with technology solutions using AWS services for Managed Databases, AI/ML, HPC, Autonomous Computing, and IoT.
Vikrant Kahlir is Principal Architect in the Solutions Architecture team. He works with AWS strategic customers product and engineering teams to help them with technology solutions using AWS services for Managed Databases, AI/ML, HPC, Autonomous Computing, and IoT.