Amazon Web Services ブログ
AWS のディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速なリカバリによるバックアップと復元
このブログはSeth Eliot (Principal Reliability Solutions Architect with AWS Well-Architected)によって執筆された内容を⽇本語化したものです。原⽂はこちらを参照して下さい。
前回のブログ記事で、AWS での災害復旧 (DR) に関する4つの戦略を紹介しました。これらの戦略により、災害イベントに備え復旧が可能になります。AWS Well-Architected Reliability Pillar ホワイトペーパーで提供されているベストプラクティスを使用して DR 戦略を設計することで、自然災害、技術的障害、または人的な行為による災害が発生しても、ワークロードを利用し続けることができます。
DR戦略: バックアップと復元の選択
図1に示すように、バックアップと復元はRTO(目標復旧時間)とRPO(目標復旧時点)が一番大きくなる選択と位置付けられています。その結果、災害発生から復旧までの間にダウンタイムが長くなり、データ損失が大きくなります。ただし、バックアップと復元は、実装するのが最も簡単で低コストの戦略であるため、ワークロードによっては適した戦略です。すべてのワークロードでRTOとRPOを数分以内に抑えることを必要とするわけではありません。
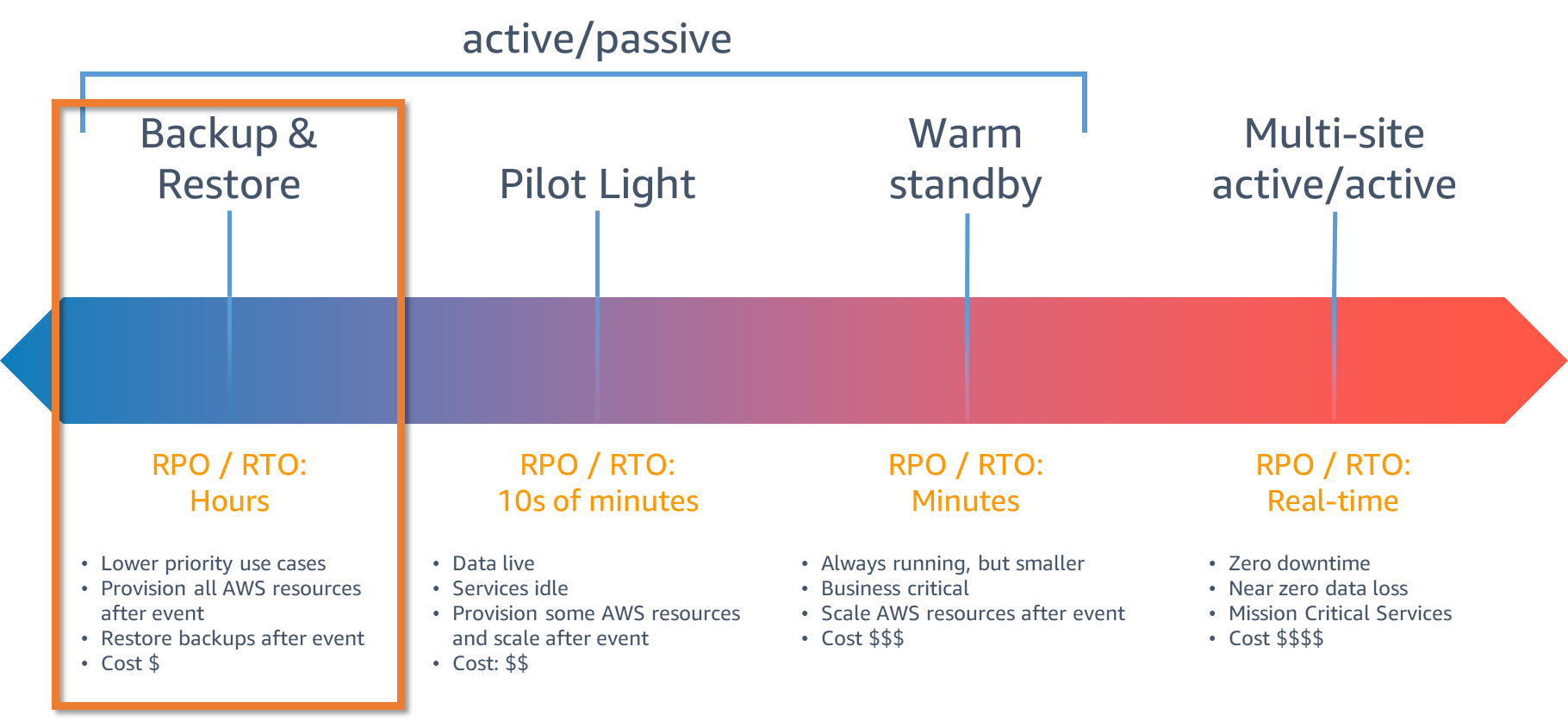
図1. DR戦略
バックアップと復元の実装
図2では、ワークロードによって使用される可能性がある AWS リソースを示しています。
- Amazon Elastic Block Store (Amazon EBS): EBS ボリューム
- Amazon Elastic Compute Cloud (Amazon EC2): EC2 インスタンス
- Amazon Relational Database Service (Amazon RDS): DB インスタンス
- Amazon Elastic File System (Amazon EFS)
AWS Backup は、これらのリソースのバックアップを設定、スケジュール、モニタリングできる一元化されたビューを提供します。RPO は、バックアップの実行頻度によって決まります。
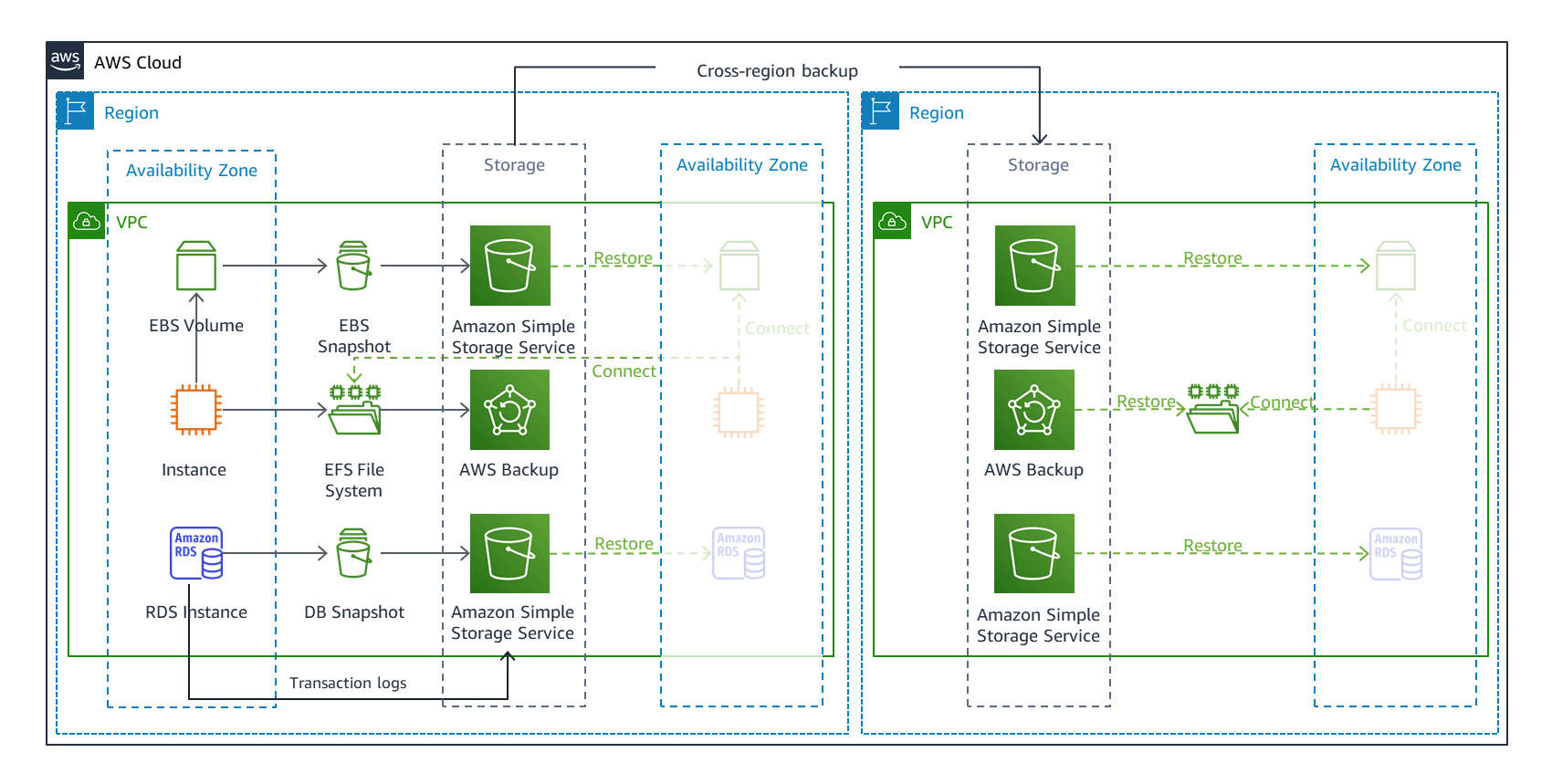
図2. バックアップと復元のDR戦略
AWS リージョン内のバックアップ
すべての AWS リージョンは、複数のアベイラビリティーゾーン (AZ) で構成されています。高可用性 (HA) を提供するには、AZ 間でリソースを複製するマルチ AZ 戦略が必要です。
このHA 戦略は、単一リージョン内の DR に必要なワークロードの多くを提供します。ただし、災害イベントには、データを消去または破損する人的な行為やソフトウェアのバグが含まれます。この場合、HA 戦略はこれらのタイプのデータエラーを複製します。したがって、DR の場合は、リージョン内のデータストアを追加でバックアップする必要があります (図2)。ポイントインタイムリカバリ(Amazon DynamoDB のポイントインタイムリカバリ、RDSの特定の時点へのDB instanceの復元など)を提供するバックアップ、またはバージョニングを有効にする(Amazon Simple Storage Service(Amazon S3)バケットのバージョニングを使用)を使用すると、前回の既知の良好な状態に「巻き戻し」できます。
別の AWS リージョンへのバックアップ
バックアップの一元管理に加えて、AWS Backup では、図2に示すように、リージョンと AWS アカウントを跨いでバックアップをコピーできます。データを別のリージョンにコピーすることで、最大の災害範囲に対処できます。災害イベントによってワークロードがリージョンで動作しなくなった場合は、ワークロードを復旧先リージョン (図3) に復元し、そこから操作できます。
復旧先リージョンでは、プライマリリージョンとは異なる AWS アカウントを使用し、異なる認証情報を使用する必要があります。これにより、あるリージョンでのヒューマンエラーや不正行為がもう一方のリージョンに影響を与えることを防ぐことができます。
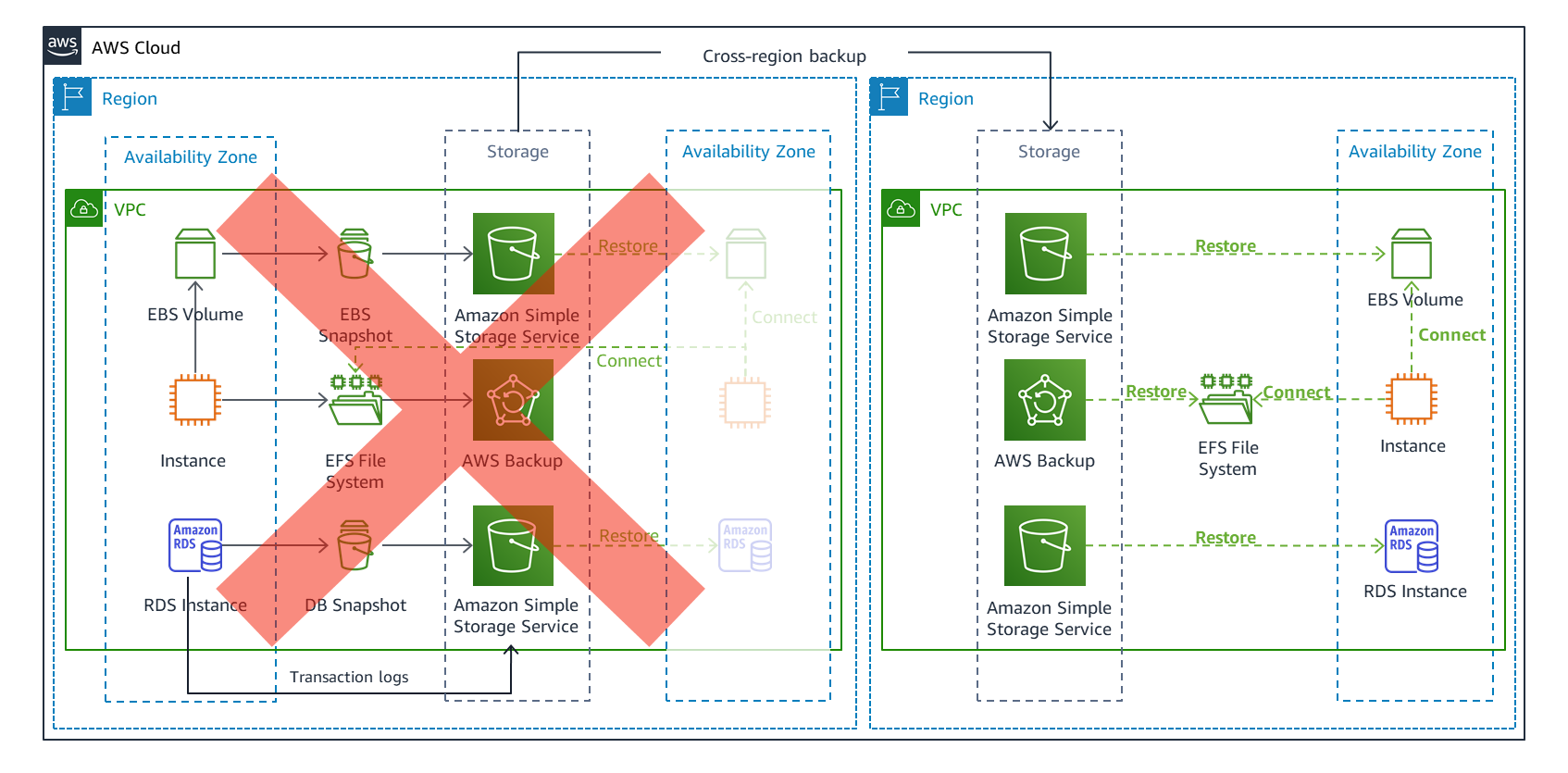
図3.マルチリージョンのバックアップと復元戦略によるフェイルオーバーとクロスリージョンリカバリ
バックアップと復元を最大限に活用する
災害イベントが発生した場合、次の手順を使用して DR 戦略を達成します。
- 災害イベントがワークロードに与える影響を検出
- インフラストラクチャとデータを復元し、これらを再統合してワークロードを運用できるようにする
- フェイルオーバー、復旧先リージョンへのリクエストの再ルーティング
1. 検出
リカバリ時間(およびRTO)は、多くの場合、ワークロードの復元とフェイルオーバーにかかる時間と考えられます。しかし、図4に示すように、検出までの時間とフェイルオーバーの実施を決定する時間は、リカバリ時間の追加要因となります(潜在的に重要な要因となります)。
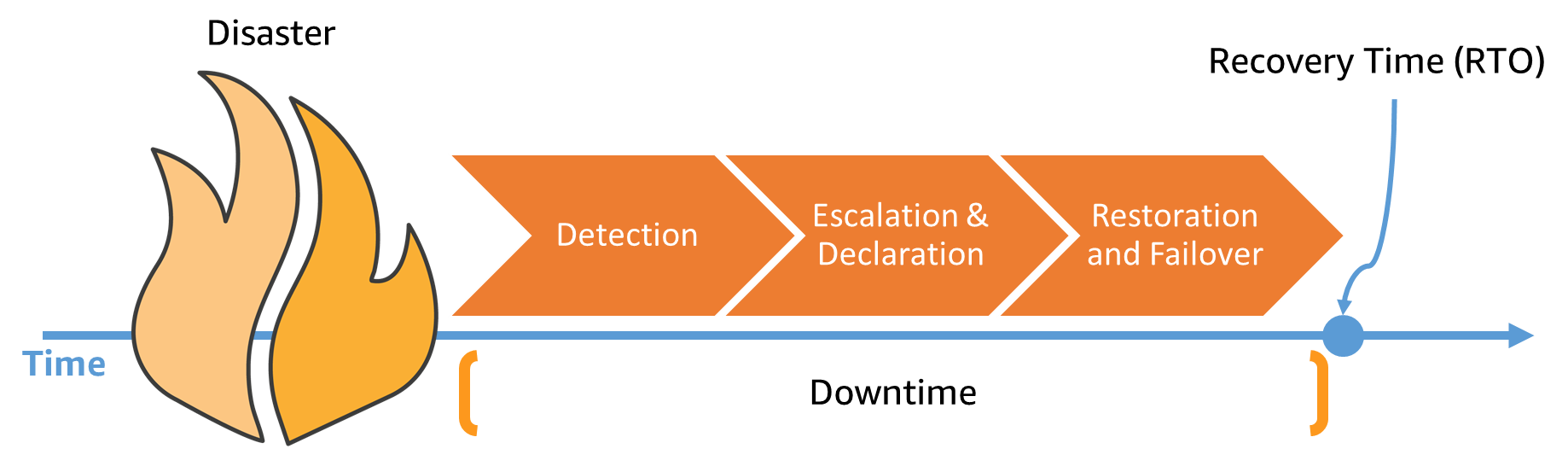
図4.災害イベント発生後のリカバリ時間に関連する要素
リカバリ時間を短縮するには、検出を自動化する必要があります。オペレーターや顧客が問題に気付くまで待つことはありません。
図5に、ワークロードの可用性に影響を与えるイベントを検出して対応するためのアーキテクチャ例を示します。
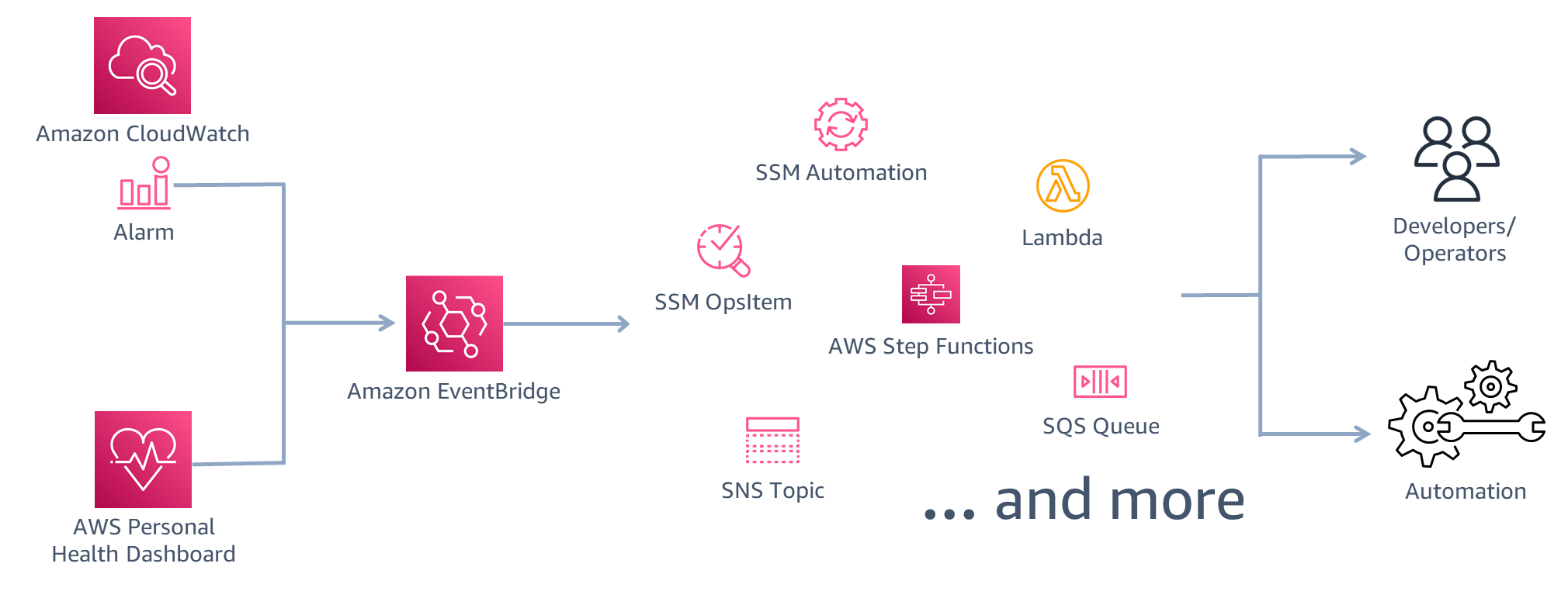
図5.EventBridgeを使用した災害イベントの検出と対応
Amazon EventBridgeは、多くの AWS サービスからのイベントをサポートし、それらのイベントに応答するアクションをターゲットとして指定できます。ここでは、2つのイベントソースが使用されます。
- Amazon CloudWatch は、定義した設定に基づいたメトリクスから有効になる CloudWatch Alarmsを備えています。これは、数式を使用した複数のメトリクスから、または他の複数のアラームに基づく場合があります。その結果、ワークロードの動作に基づいて高度なヘルスチェックを設定できます。さらに、CloudWatch Anomary Detectionを使用して、サイトのエンゲージメント、注文、またはその他の主要パフォーマンス指標が低下したかどうかを検出できます。これは、ワークロードがイベントの影響を受けていることを示す強力な指標です。
- Personal Health Dashboard は、お客様に影響を与える可能性のあるイベントが AWS で発生している場合にアラートを出します。AWS マネジメントコンソールでダッシュボードを表示し、これらのイベントを監視して対応するように EventBridge を設定することができます。次の例では、Amazon S3 での PUT および GET オペレーションでエラーレートの増加を引き起こしているイベントに反応するように EventBridge が設定されています。
{
"source": ["aws.health"],
"detail-type": ["AWS Health Event"],
"detail": {
"service": ["S3"],
"eventTypeCategory": ["issue"],
"eventTypeCode": ["AWS_S3_INCREASED_GET_API_ERROR_RATES", "AWS_S3_INCREASED_PUT_API_ERROR_RATES"]
}
}図5は、これらのイベントの結果として実行できるアクションが多数あることを示しています。AWS Systems Managerで OpsItem を作成することで、イベントを追跡することができます。または、Amazon Simple Notification Service(Amazon SNS)を使用して E メールまたはテキストメッセージを送信することで、開発者やオペレーターにアラートを送信することもできます。自動応答にはいくつかのオプションがあります。AWS Lambda はコードを実行することも、Systems Manager Automationを有効にして、EC2 インスタンスの起動や AWS CloudFormation でのスタックのデプロイなどのタスクを実行する Runbook を開始することもできます。
2.復元
バックアップからデータを復元すると、EBS ボリューム、RDS DB インスタンス、DynamoDB テーブルなど、そのデータのリソースが作成されます。図6は、AWS Backup を使用して復旧リージョン (この場合は EBS ボリューム) のデータを復元できることを示しています。インフラストラクチャの再構築には、Amazon Virtual Private Cloud(Amazon VPC)、サブネット、および必要なセキュリティグループに加えて、EC2 インスタンスなどのリソースの作成が含まれます。
復旧先リージョンのインフラストラクチャを復元するには、Infrastructure as Code (IaC) を使用する必要があります。これには、CloudFormation と AWS Cloud Development Kit (AWS CDK) を使用して、リージョン間で一貫したインフラストラクチャを作成することが含まれます。ワークロードに必要な EC2インスタンスを作成するには、Amazon マシンイメージ(AMI)を使用して、必要なオペレーティングシステムとパッケージを組み込みます。これらの AMI には、一貫性のあるサーバーを立ち上げるために必要なものが正確に含まれているため、これらを「ゴールデン AMI」と呼びます。 Amazon EC2 Image Builder を使用して、ゴールデン AMI を作成し、復旧先リージョンにコピーできます。

図 6.バックアップからのデータの復元と復旧先リージョンのインフラストラクチャの再構築
場合によっては、インフラストラクチャとデータを再統合する必要があります。たとえば、図6では、EBS ボリューム内のステートフルデータをリカバリしています。そのボリュームを EC2 インスタンスに再アタッチします。図 7 に、これを自動化する方法の1つを示します。
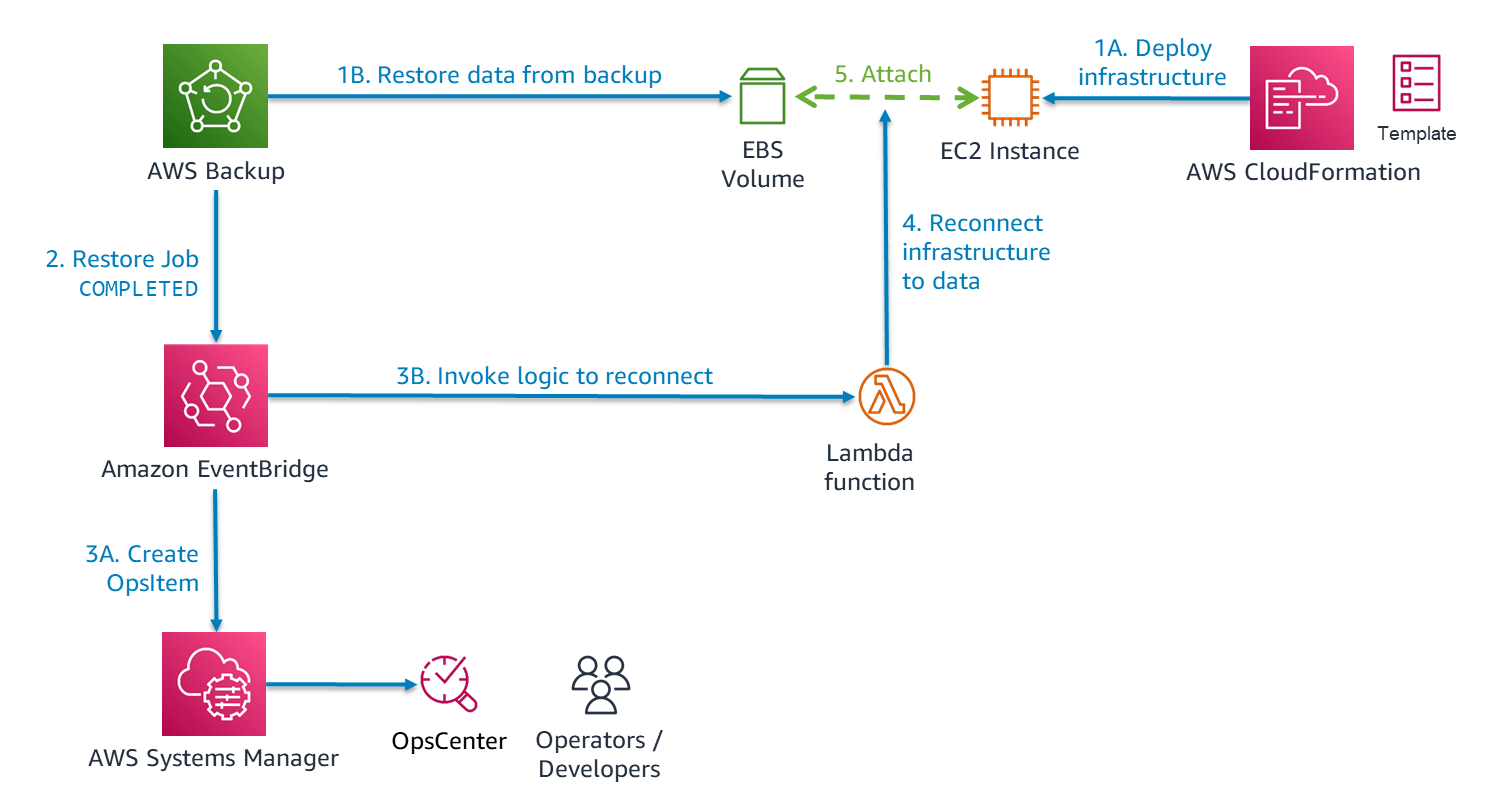
図 7.ワークロードの復元の一環としてインフラストラクチャとデータの統合を自動化
EventBridge を使用して、サーバーレスソリューションを実装します。AWS Backup は、リソースのデータの復元が完了した後にイベントを発行します。これに対応して、EventBridgeは2つのアクションを開始します。3A) 記録のためにOpsCenterでアイテムを作成して、3B) Lambda関数を呼び出します。イベントから、Lambda は復旧先リージョンで作成された新しいリソースの ID と、復旧に使用されたバックアップ (復旧ポイント) の ID を取得します。Lambda 内のコードは API を呼び出し、元のリソース (プライマリリージョン) にあったタグを取得します。これにより、統合の設定をガイドできます。AWS Backup は、リソースから作成したバックアップにタグを自動的にコピーします。CloudFormation への別の API 呼び出しにより、Lambdaは EC2インスタンスの ID を学習できます。その後、Amazon EC2のAPI を呼び出して、EBS ボリュームをアタッチできます。
図7に EBS ボリュームを EC2インスタンスにアタッチする方法を示していますが、自動化したい統合は他にもあります。たとえば、Lambda 関数の代わりに、データの復元イベントによって Systems Manager の Runbook が実行される場合があります。これにより、復元された EFS または Amazon FSx ファイルシステムを、1つ以上の EC2インスタンスに自動的にマウントします。
より包括的な自動化のために、AWS Step Functions を使用してすべてをオーケストレーションできます。これには、CloudFormation を使用したインフラストラクチャのデプロイ、AWS Backup を使用したデータの復元、統合手順が含まれます。Step Functions では、Lambda 関数を実行するステートマシンを設定し、必要な依存関係を持つ必要な順序で各アクティビティを開始およびモニタリングします。
3.フェイルオーバー
フェイルオーバーは、本番トラフィックをプライマリリージョン(ワークロードを実行できなくなったと判断したリージョン)から復旧先リージョンにリダイレクトします。これについては、今後のブログ記事で説明します。
まとめ
ビジネスチームとエンジニアリングチームが協力して DR の目標設定と実装を行う場合は、バックアップと復元戦略を使用して、ワークロードの DR ニーズを満たせるかどうかを検討してください。自動化を使用すると、RTO を最小限に抑えることができるため、災害発生時のダウンタイムの影響を軽減できます。この戦略はコストが低く、実装が比較的容易であるため、多くの AWS ワークロードに適しています。
関連情報
- AWSでのディザスタリカバリ(DR)アーキテクチャ、パートI:クラウドでのリカバリの戦略
- AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ
- AWS のディザスタリカバリ (DR) アーキテクチャ、パート IV: マルチサイトアクティブ/アクティブ
- クラウドのディザスタリカバリのオプションに関するホワイトペーパー
- Automate data recovery validation with AWS Backup
翻訳はソリューションアーキテクトの横井が担当しました。原文はこちらです。