Amazon Web Services ブログ
AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略
このブログは Seth Eliot (Principal Reliability Solutions Architect with AWS Well-Architected) によって執筆された内容を⽇本語化したものです。原⽂はこちらを参照して下さい。
AWS Well-Architected 信頼性の柱のリードソリューションアーキテクトとして、お客様が AWS で復元力のあるワークロードを構築できるように支援をします。これは、お客様が直面する可能性のある最大の課題の1つである災害イベントに備えるのに役立ちます。このようなイベントには、地震や洪水などの自然災害、電力やネットワークの損失などの技術的な障害、不注意や不正な変更などの人的行為が含まれます。最終的に、ワークロードまたはシステムが主要な場所でビジネス目標を達成するのを妨げるイベントは、災害として分類されます。このブログ投稿では、災害に備えて復旧するプロセスである災害復旧 (DR) の設計方法を示しています。DR は、事業継続計画の重要な部分です。
DR 目標
災害イベントによってワークロードがダウンする可能性があるため、DR の目的は、ワークロードを元に戻すか、ダウンタイムを完全に回避することです。次の目標値を使用します。
- 目標復旧時間 (RTO): サービスの中断からサービスの復旧までの最大許容遅延時間。これにより、サービスのダウンタイムの許容可能な期間が決まります。
- 目標復旧時点 (RPO): 最後のデータ復旧ポイントからの最大許容時間。これにより、許容できるデータの損失と見なされるものが決まります。

図 1.リカバリの目標:RTO と RPO
RTO と RPO は、数値が小さいほど、ダウンタイムとデータ損失が少なくなります。ただし、RTO とRPO が低いほど、リソースへの支出と運用の複雑さという点でコストが高くなります。したがって、ワークロードに適切な価値を提供する RTO および RPO 目標を検討する必要があります。
災害イベントの影響範囲
マルチ AZ 戦略
すべての AWS リージョンは、複数のアベイラビリティーゾーン (AZ) で構成されています。各 AZ は、地理的に離れた場所にある 1 つ以上のデータセンターで構成されています。これにより、単一のイベントが複数の AZ に影響を与えるリスクが大幅に軽減されます。したがって、停電、洪水、その他の地域的な災害などのイベントに耐える DR 戦略を設計している場合は、AWS リージョン内でマルチ AZ DR 戦略を使用することで必要な保護を提供できます。
マルチリージョン戦略
AWS は、ワークロードに対してマルチリージョンアプローチを可能にする複数のリソースを提供します。これにより、別々の異なる場所にある複数のデータセンターに影響を与える可能性のある十分な範囲のイベントに対するビジネス保証が提供されます。このブログ投稿のほとんどの例では、マルチリージョンアプローチを使用して DR 戦略を示しています。ただし、これらをマルチ AZ 戦略またはハイブリッド(オンプレミスワークロード/クラウドリカバリ)戦略に使用することもできます。
DR 戦略
AWS は、ビジネスニーズを満たす DR 戦略を構築するためのリソースとサービスを提供します。

図 2.DR 戦略 — RTO/RPOとコストの間のトレードオフ
図 2 は、 DR ホワイトペーパーで強調されている DR の 4 つの戦略を示しています。この図は、左から右に、DR 戦略で RTO と RPO がどのように異なるかを示しています。
最適な戦略を選択するには、エンジニアリング/ IT からの情報をもとに、ワークロードのビジネスオーナーと一緒にメリットとリスクを分析する必要があります。ワークロードに必要な RTO と RPO、およびお金、時間、労力への投資を決定します。
アクティブ/パッシブおよびアクティブ/アクティブ DR 戦略


図 3.アクティブ/パッシブ DR
図2は、DR 戦略をアクティブ/パッシブまたはアクティブ/アクティブのいずれかに分類しています。図3 に、アクティブ/パッシブがどのように機能するかを示します。ワークロードは単一のサイト(この場合は単一の AWS リージョン)から実行され、すべてのリクエストはこのアクティブなリージョンで処理されます。災害イベントが発生し、アクティブリージョンがワークロード操作をサポートできない場合、パッシブサイトがリカバリサイト(リカバリリージョン)になります。次に、そこからワークロードを実行できるように手順を実行します。これで、すべてのリクエストが「フェイルオーバー」と呼ばれるプロセスでルーティングされるように切り替えられます。より厳しい RTO / RPO の目標を満たすために、データはライブで維持され、フェイルオーバーの前にインフラストラクチャが完全または部分的にリカバリサイトに展開されます。バックアップからデータを復元する必要がある場合、これによりリカバリポイント(およびデータ損失)が増加する可能性があります。インフラストラクチャがライブトラフィックを受け入れる前に追加の操作を必要とする場合、これによりリカバリ時間が長くなる可能性があります。このような RTO と RPO の増加は、ビジネス目標を達成できる限り問題ありません。
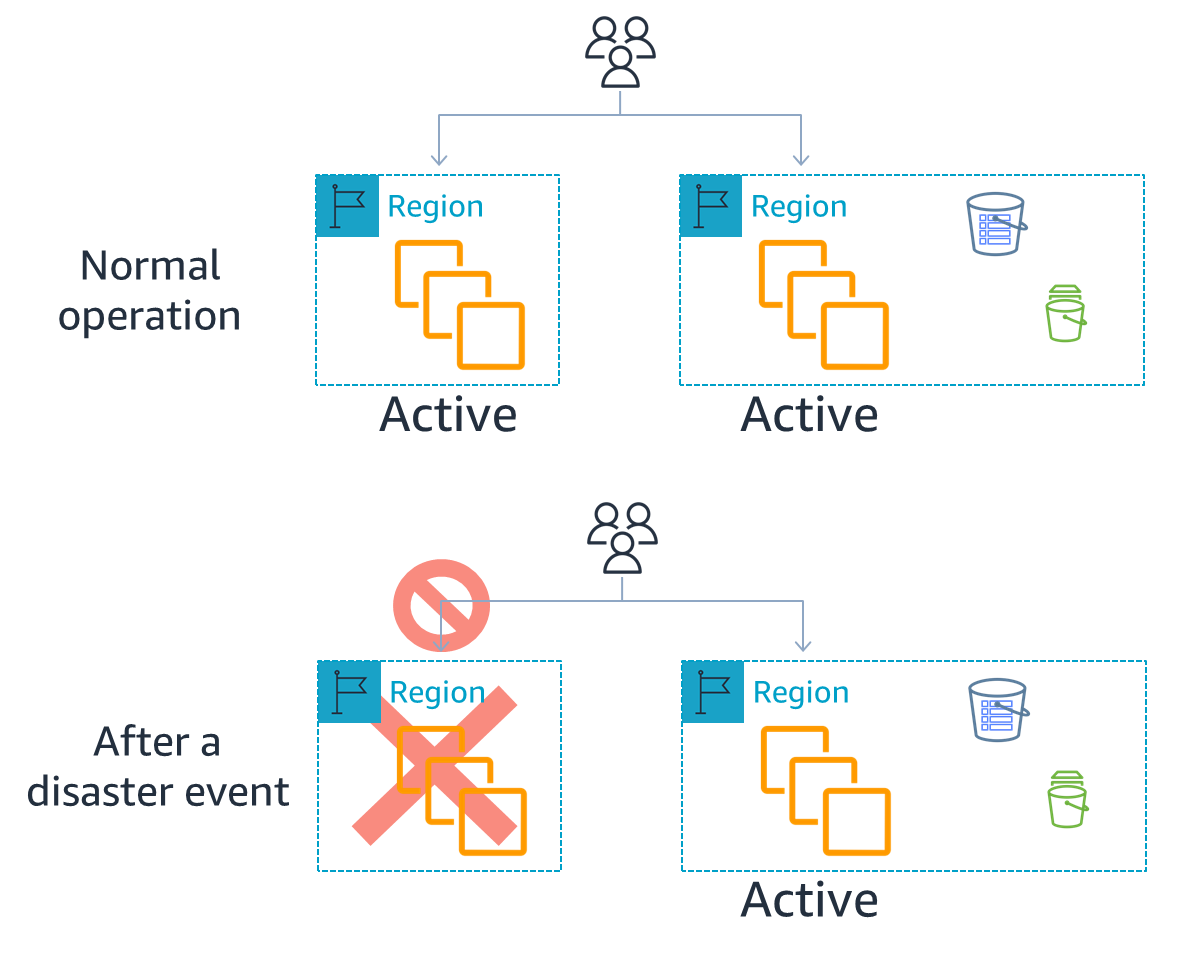
図 4.アクティブ/アクティブ DR
図4は、2 つ以上のリージョンがアクティブにリクエストを受け入れ、それらの間でデータが複製されるアクティブ/アクティブ戦略を示しています。1 つのリージョンが災害イベントの対象となる場合、フェイルオーバーとは、そのリージョンのトラフィックが残りのアクティブなリージョンにルーティングされることを意味します。データがリージョン間で複製される場合でも、DR の一部としてデータをバックアップする必要があります。これにより、「人的行為」や技術的なソフトウェアによる災害を防ぐことができます。このような災害によってデータが削除または破損した場合は、バックアップから最後の既知の良好な状態へのポイントインタイムリカバリを使用する必要があります。
DR 戦略のアーキテクチャ
各 DR 戦略については、今後のブログ投稿で詳しく説明します。次のセクションでは、各戦略を要約します。
バックアップと復元

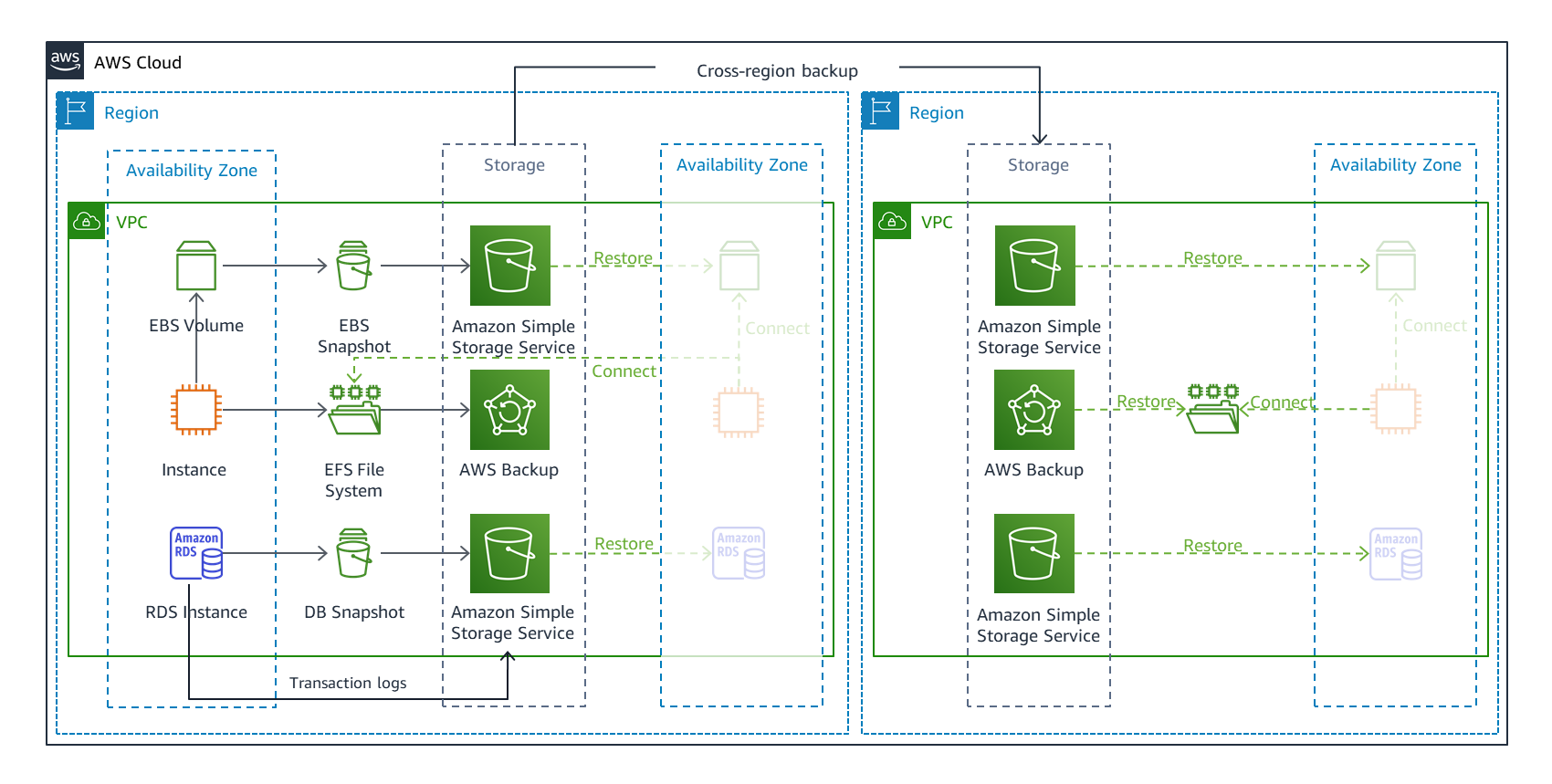
図 5.バックアップと復元 DR アーキテクチャ
図5は、さまざまな AWS データリソースのバックアップを示しています。バックアップは、ソースと同じリージョンで作成され、別のリージョンにもコピーされます。これにより、あらゆる影響範囲の災害から最も効果的に保護できます。リージョンフェイルオーバーの場合、バックアップからのデータリカバリに加えて、リカバリリージョンでインフラストラクチャを復元できる必要もあります。AWS CloudFormation や AWS Cloud Development Kit (AWS CDK) などの Infrastructure as Code を使用すると、リージョン間で一貫したインフラストラクチャをデプロイできます。
バックアップとリカバリの戦略は、RTO にとって最も効率が悪いと考えられています。ただし、 Amazon EventBridge などの AWS リソースを使用してサーバーレス自動化を構築できます。これにより、検出とリカバリが改善され、RTO が削減されます。これについては、今後のブログ投稿でさらに詳しく説明します。
パイロットライト


図 6.パイロットライト DR アーキテクチャ
パイロットライト戦略では、データはライブですが、サービスはアイドル状態です。ライブデータとは、データストアとデータベースがアクティブなリージョンで最新(またはほぼ最新)であり、読み取り操作を処理する準備ができていることを意味します。図6では、Amazon Aurora グローバルデータベースが、リカバリリージョン内のローカルの読み取り専用クラスターにデータを複製しています。ただし、すべての DR 戦略と同様に、バックアップ(図6の Aurora DB クラスタースナップショットなど)も必要です。データを消去または破損する災害イベントの場合、これらのバックアップにより、最後の既知の良好な状態に「巻き戻す」ことができます。
パイロットライト戦略では、図6の Elastic LoadBalancing や Amazon EC2 Auto Scaling のような基本的なインフラストラクチャ要素が配置されていますが、機能要素(コンピューティングなど)は「シャットオフ」されています。クラウドでは、Amazon EC2 インスタンスをシャットオフする最善の方法は、デプロイしないことです。図6は、デプロイされたインスタンスがゼロであることを示しています。これらのインスタンスを「オン」にするには、以前にビルドしてすべてのリージョンにコピーした Amazon マシンイメージ(AMI)を使用します。この AMI は、必要なオペレーティングシステムとパッケージを正確に使用して Amazon EC2 インスタンスを作成します。トリガーされるまで家を暖めることができない炉のパイロットライトのように、パイロットライト戦略は、残りのインフラストラクチャの展開を実行するまでリクエストを処理できません。
ウォームスタンバイ

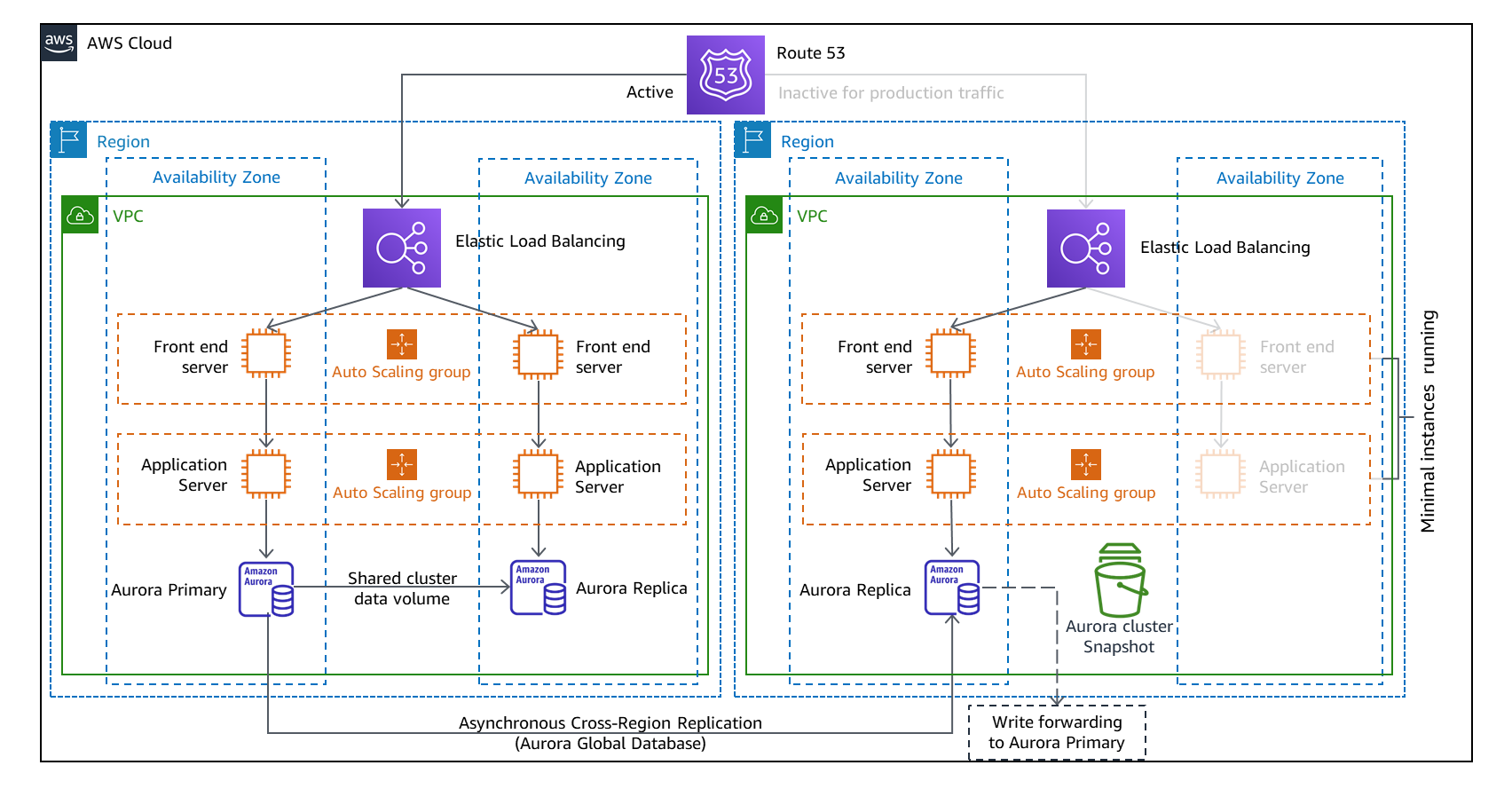
図 7.ウォームスタンバイDR アーキテクチャ
パイロットライト戦略と同様に、ウォームスタンバイ戦略は定期的なバックアップに加えてライブデータを維持します。2 つの戦略の違いは、インフラストラクチャとその上で実行されるコードです。ウォームスタンバイは、リクエストを処理できる最小限の展開を維持しますが、容量は少なくなり、本番レベルのトラフィックを処理できません。これを図7に示します。階層ごとに、1つの Amazon EC2 インスタンスがデプロイされています。これにより、パッシブエンドポイントが合成テストトランザクションを処理するための事前の追加作業が不要になるため、ウォームスタンバイのテストが容易になります。フェイルオーバーの前に、インフラストラクチャは本番環境のニーズを満たすようにスケールアップする必要があります。
マルチサイトアクティブ/アクティブ

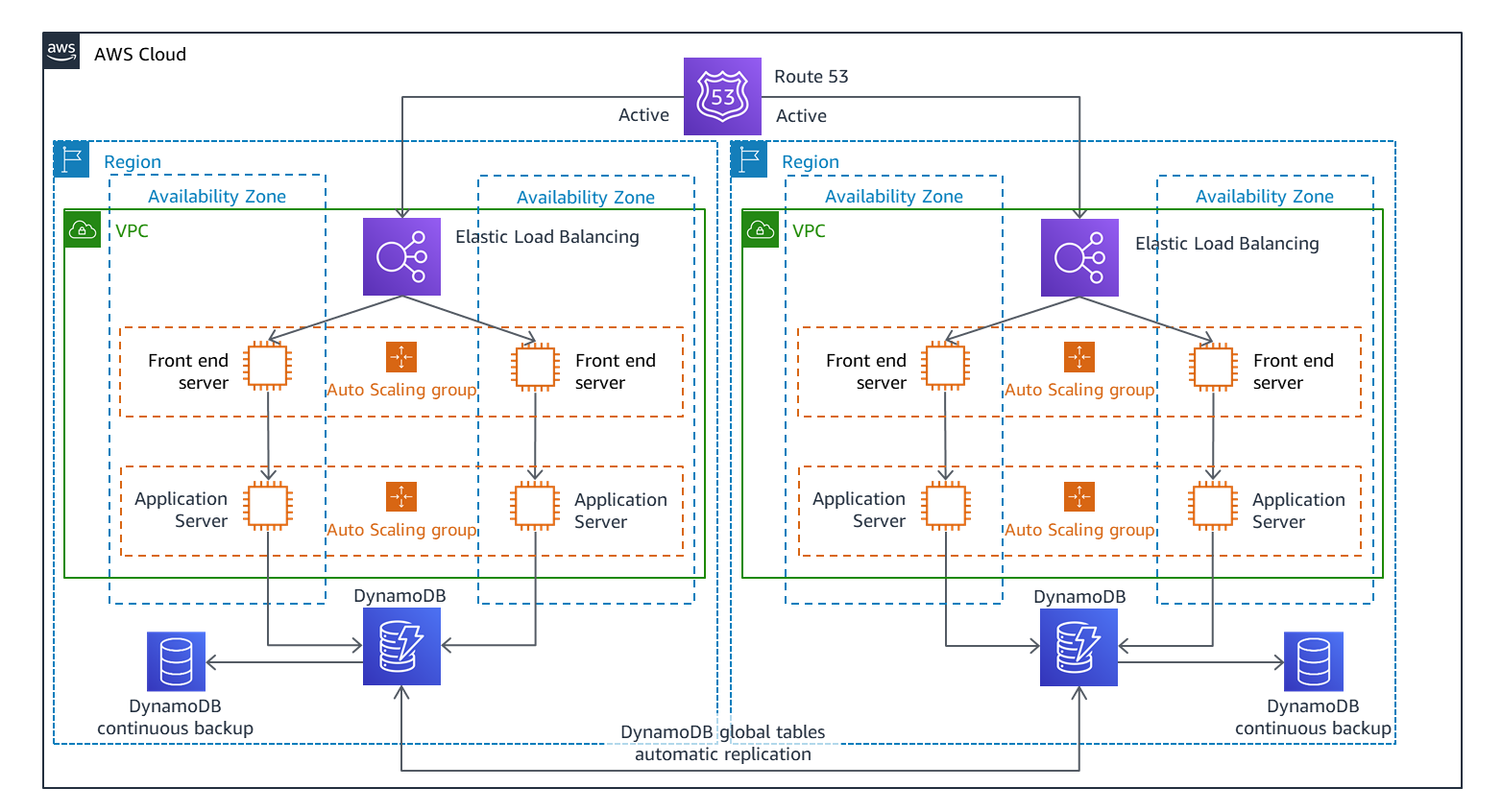
図 8.マルチサイトアクティブ/アクティブ DR アーキテクチャ
マルチサイトアクティブ/アクティブでは、2 つ以上のリージョンがアクティブにリクエストを受け入れています。フェイルオーバーは、リクエストを処理できないリージョンからリクエストを再ルーティングすることで構成されます。ここでは、データはリージョン間で複製され、それらのリージョンで読み取り要求を処理するために積極的に使用されます。書き込み要求の場合、ローカルリージョンへの書き込みや、特定のリージョンへの書き込みの再ルーティングなど、いくつかのパターンを使用できます。これらについては、今後のブログ投稿で詳しく説明します。他の DR 戦略と同様に、偶発的な削除や破損を修正するためにデータを復元する必要がある場合に備えて、データもバックアップされます。図 8 は、データベース層として使用される Amazon DynamoDB グローバルテーブルを示しています。これは、マルチサイトアクティブ/アクティブに最適です。任意のリージョンのテーブルに書き込むことができ、データは通常 1 秒以内に他のすべてのリージョンに伝播されるためです。
まとめ
災害イベントはワークロードの可用性に脅威をもたらしますが、AWS クラウドサービスを使用することで、これらの脅威を軽減または削除できます。最初にワークロードのビジネス要件を理解することで、適切な DR 戦略を選択できます。次に、AWS サービスを使用して、ビジネスに必要な目標復旧時間と目標復旧時点を達成するアーキテクチャを設計できます。
関連情報
- AWS のディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速なリカバリによるバックアップと復元
- AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ
- AWS のディザスタリカバリ (DR) アーキテクチャ、パート IV: マルチサイトアクティブ/アクティブ
- クラウドのディザスタリカバリのオプションに関するホワイトペーパー
翻訳はシニアパートナーソリューションアーキテクトの大場 崇令 (@takaohba) が担当しました。原文はこちらです。