Amazon Web Services ブログ
【お客様事例】株式会社 NTTPC 様 Amazon EC2 Inf1 インスタンス、姿勢推定推論サービスのコストパフォーマンス最適化の取り組み
2021 年 10 月 14 日にAmazon EC2をテーマとしたイベント「Amazon EC2 大活用 ~最新ラインナップ、コストパフォーマンス最適化、先進顧客事例などご紹介~」を開催いたしました。2006 年の EC2 サービス開始から 15 年という節目を迎え、AWS が提供する EC2 インスタンスの種類は多岐にわたっておりますが、コストパフォーマンスを最適化する上で、AWS では独自設計の ARM プロセッサ AWS Graviton2 や AWS Inferentia 推論チップを搭載したインスタンスを提供しています。本イベントでは Graviton2、Inferentia をご活用頂いたお客様の事例として、株式会社サイバーエージェント様、株式会社 NTTPC コミュニケーションズ様にそれぞれご登壇いただきました。
イベント全体に関しては 【開催報告】「 Amazon EC2 大活用 ~ 最新ラインナップ、コストパフォーマンス最適化、先進顧客事例などご紹介~」セミナー のブログも併せてご参照ください。
本ブログではイベントの発表の中から、株式会社 NTTPC コミュニケーションズ様による、姿勢推定API サービス(AnyMotion)におけるコスト最適化の目的のもと、Amazon EC2 Inf1 インスタンスに焦点を当て、他のEC2 インスタンスとの比較検証を行った取り組みについて紹介させて頂きます。
姿勢推定 API サービス(AnyMotion)における推論用 Inf1 インスタンスの検証について
株式会社 NTTPC コミュニケーションズ 栁澤利紀 様
登壇資料: [Slide]

NTTPC コミュニケーションズ様は姿勢推定 API サービス(AnyMotion)を提供しており、インフラには AWS を用いています。今回、推論モデルを動作させるインスタンスとして Inf1 インスタンスに焦点を当て、GPU 搭載インスタンスである Amazon EC2 P3 インスタンス や Amazon EC2 G4 インスタンス、Amazon Elastic Inference と比較検証いただき、検証内容をご報告いただきました。
姿勢推定 API サービス AnyMotion
AnyMotion はカメラで撮影した動画や画像から AI が人間の関節の位置を推定し、骨格データを解析する機能を通じて身体動作を見える化するためのサービスです。これまで人の感覚や目視に頼っていた領域において、定量的なデータに基づくコーチングや姿勢チェックなどのレポーティングが可能となります。本サービスをアプリケーションを開発する企業向けに API として提供することで、アプリケーション側で解析結果を用いた評価・判定を行い、エンドユーザへレポートやフィードバックを返すような利用が可能となるため、スポーツ、ヘルスケア、エンタメ、リハビリなど様々な業界で検討頂いているとのことでした。
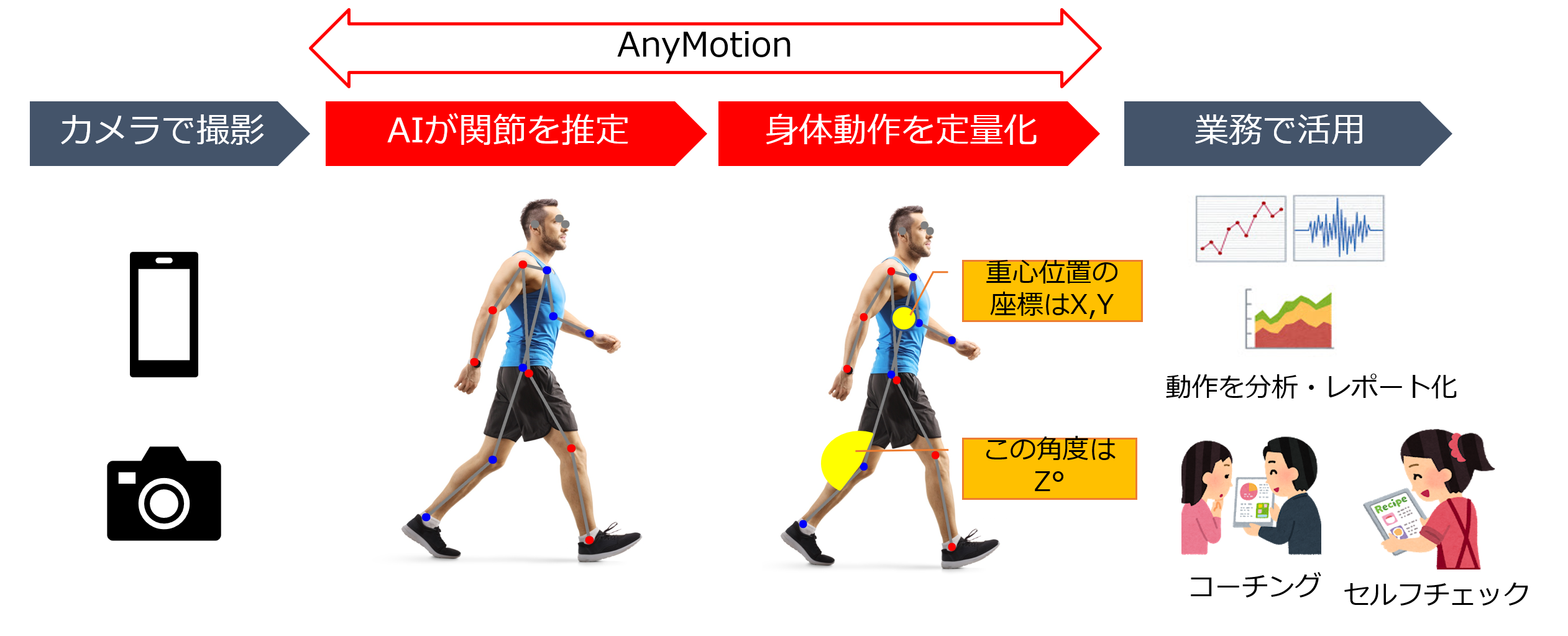
AI サービス運用における課題
AI サービスを運用するにあたり、運用コストの低減は重要な検討項目です。サービスのスケーリングを考えた場合、推論部分のコストがインフラコスト全体の 50% 以上を占め、特に大きくなることが予想されたため、AWS が提供している推論インスタンス Amazon EC2 Inf1インスタンスの検証を実施頂きました。AWS で提供している推論用インスタンスは様々ありますが、運用時のコストパフォーマンスの最適化が期待できる Inf1 インスタンスを中心に、GPU(g4dn及びp3)インスタンス、CPU(Amazon EC2 C5)インスタンス、Amazon Elastic Inference との比較検証を実施頂きました。
Amazon EC2 Inf1 及び AWS Inferentia とは
Amazon EC2 Inf1 インスタンスは、機械学習推論のワークロードを高速化し、コストを最適化するために AWS が独自設計した機械学習推論チップ AWS Inferentia を搭載したインスタンスです。Inf1 インスタンスは GPU インスタンスと比較し、最大 2.3 倍のスループット向上、推論処理当たり最大 70% の低価格を実現しています。AWS Inferentia チップには 4 つの Neuronコアが含まれています。Neuronコアは高性能なシストリックアレイ行列乗算エンジンを実装しているため、畳み込みや変換などの一般的な深層学習のオペレーションを大幅に高速化します。Neuronコアには大きなオンチップキャッシュが搭載されており、Neuronコア内での演算結果や推論処理で必要となる重みのパラメータなどをキャッシュ内に留める事で外部メモリアクセスを削減し、レイテンシーを低減、スループットを向上させることができます。

AWSが独自設計した機械学習推論チップ AWS Inferentia
AWS Inferentia に対応したソフトウェア開発キットである AWS Neuron は、TensorFlow、PyTorch、Apache MXNet などの機械学習フレームワークからネイティブに利用可能です。コンパイラ、ランタイム、プロファイリングツールで構成され、高いパフォーマンスと低レイテンシーの推論を実行することができます。Inf1 インスタンスでは、事前に学習済みモデルを Neuronコアで実行できる形式にコンパイルする必要がありますが、数行のコードの変更のみでコンパイル可能です。Inf1 インスタンスは、Amazon が提供するクラウドベースの音声サービス Amazon Alexa や、広告ソリューションを提供する Amazon Advertising を支えるインフラストラクチャーとしても利用されており、コストパフォーマンスの最適化に寄与しています。
検証内容
NTTPC 様での検証では、実際に AnyMotion サービスで利用している TensorFlow のモデルを使用しました。256 x 192 の入力画像データに対して、人間の関節位置を推定し、その座標を返す姿勢推定のカスタムモデルです。Inf1 インスタンスでは Neuron コンパイラによって、学習済みモデルを事前にコンパイルする必要がありますが、カスタムモデル内の一部に Neuron コンパイラで対応していないノードが見つかったため、そのノードに関しては CPU 上で処理する形で検証を進めて頂きました。
機械学習の推論処理では一般的にアプリケーションのユースケースに応じた2つの異なる要件が存在します。一つは高いリアルタイム性が求められるケースで、与えられたレイテンシーの条件を満たすことが要件として求められます。もう一つはバッチ推論と呼ばれる、より大きなデータ群を効率よく、高いスループットで処理するケースです。
今回比較検証頂いたインスタンスとそれぞれの検証結果は以下の通りです。
高いリアルタイム性能が求められるケース
| インスタンス | 推論バッチサイズ | スループット [Images/秒] | レイテンシー [ミリ秒] | 時間単価
[USD]※2 |
コストパフォーマンス
[Images/0.0001 USD] |
||
| P50 | P90 | ||||||
| Inf1 | Inf1.xlarge | 1 | 517.80 | 7.38 | 7.68 | 0.308 | 604.05 |
| Inf1.2xlarge | 1 | 568.97 | 7.46 | 7.80 | 0.489 | 418.87 | |
| GPU | g4dn.xlarge | 1 | 113.46 | 10.06 | 10.32 | 0.71 | 57.53 |
| p3.2xlarge | 1 | 170.88 | 8.40 | 8.66 | 4.194 | 14.67 | |
| Elastic Inference※1 | eia1.medium | 1 | 32.15 | 36.01 | 36.41 | 0.220 | 52.61 |
| eia1.large | 1 | 65.76 | 19.17 | 19.46 | 0.450 | 52.61 | |
| eia1.xlarge | 1 | 85.89 | 15.51 | 15.86 | 0.890 | 34.74 | |
| CPU | c5.2xlarge | 1 | 18.43 | 75.73 | 77.12 | 0.428 | 15.50 |
※1 m5.xlarge に GPU アクセラレータとしてアタッチ ※2 2021 年 10 月時点の東京リージョンにおける料金
リアルタイム性能を重視し、推論バッチサイズを1とした条件下での検証では、inf1インスタンスで8ミリ秒以下のレイテンシーを達成しました。その際のコストパフォーマンスは他のインスタンスを大きく引き離す結果となり、g4dn インスタンスと比較した場合では、4.5 倍のスループット、推論レイテンシーが 25% 短縮され、コストも 90% 削減できています。
高いスループット性能が求められるケース
| インスタンス | 推論バッチサイズ | スループット [Images/秒] | レイテンシー [ミリ秒] | 時間単価
[USD]※2 |
コストパフォーマンス
[Images/0.0001 USD] |
||
| P50 | P90 | ||||||
| Inf1 | Inf1.xlarge | 8 | 1011.87 | 38.24 | 39.38 | 0.308 | 1182.71 |
| Inf1.2xlarge | 8 | 1147.46 | 39.25 | 40.81 | 0.489 | 844.76 | |
| GPU | g4dn.xlarge | 64 | 224.63 | 464.14 | 496.92 | 0.71 | 113.90 |
| p3.2xlarge | 64 | 736.92 | 264.85 | 272.09 | 4.194 | 63.25 | |
| Elastic Inference※1 | eia1.medium | 8 | 67.79 | 148.56 | 150.70 | 0.220 | 110.93 |
| eia1.large | 32 | 201.2 | 304.06 | 446.77 | 0.450 | 160.96 | |
| eia1.xlarge | 32 | 300.69 | 238.69 | 244.39 | 0.890 | 121.63 | |
| CPU | c5.2xlarge | 16 | 20.59 | 868.74 | 896.24 | 0.428 | 17.32 |
※1 m5.xlarge に GPU アクセラレータとしてアタッチ ※2 2021 年 10 月時点の東京リージョンにおける料金
スループット性能を重視するバッチ推論では、一般的に大きなバッチサイズを用いることで GPU やInferentia 等のハードウェアアクセラレータは利用効率を高める事が可能です。GPU(g4dn 及び p3)インスタンスではバッチサイズを 64 にした場合にスループットが最大の値となったのに対し、Inf1インスタンスでは、バッチサイズが 8 の段階で Inferentia 内の Neuronコアの利用率が 100% に近い値まで達し、スループットの最大値を達成しています。g4dn インスタンスと比較した場合、こちらも 4.6 倍のスループット、 90% 以上のコスト削減を達成しています。
なお今回発表頂きました NTTPC 様の検証結果はこちらのブログで詳細を公開しておりますので合わせてご参照ください。
まとめ
機械学習ワークロードに求められる要件は様々です。扱うモデルが XGBoost、ランダムフォレストのような従来型の機械学習モデルなのか、ハードウェアアクセラレータが必要となる深層学習モデルなのか、またリアルタイム性能が求められるのか、バッチ推論でまとめて処理し、処理後はインスタンスを落としても問題ないのか。推論リクエストは常時発生するのか、散発的に発生するのか。Time-to-Market の観点での開発容易性や運用に至るまでの開発コストも気になる点だと思います。今回、NTTPC 様には運用コストの占める割合が大きい推論処理のコストパフォーマンスの最適化に注力して Inf1 インスタンスを中心に各種インスタンスを検証頂き、Inf1 インスタンスのコストパフォーマンスの高さを改めて確認いただきました。
※ 機械学習ワークロードに求められる様々な要件においての Amazon EC2 の選択肢に関しては、同イベント内、Amazon EC2 機械学習ワークロードの選択肢 のセッションも併せてご参照ください。
Snap、Airbnb、Sprinklr などのAWSの多くのお客様が Amazon EC2 Inf1 インスタンスを利用し、高いパフォーマンスを低いコストで実現しています。本イベント及びブログをご覧いただいた AWS のお客様にとって、今後、推論ワークロードのコストパフォーマンス最適化を図る上でのヒントとなれば幸いです。
最後に本イベントにご協力いただいた株式会社 NTTPC コミュニケーションズ様には改めて感謝を申し上げます。またイベントに参加いただいた皆様 誠にありがとうございました。
このブログはアンナプルナラボの常世が担当しました。
________________________________________
Amazon EC2 Inf1インスタンス 参考コンテンツ
- Amazon EC2 Inf1 インスタンス (製品ページ)
- AWS Inferentia (製品ページ)
- AWS Neuron (ドキュメント)
- AWS Inferentia Workshop (日本語版)
- Amazon SageMaker でコンピュータビジョン推論に最適な AI アクセラレータとモデルコンパイルを選択 (AWSブログ)
- AWS Inferentiaを使用して Amazon EKS で 3,000種類のディープラーニングモデルを 1 時間あたり 50 USD 以下で提供 (AWSブログ)
- 機械学習と AWS Inferentia を使用した広告検証のスケーリング (AWSブログ)
- AWS Inferentia上のPyTorch自然言語処理アプリケーションにおいて、12倍のスループットと最小のレイテンシーを実現 (AWSブログ)
- 【お客様事例】株式会社朝日新聞社様 自然言語処理の取り組みとEC2 Inf1インスタンスの検証 (AWSブログ)
- Alexa の大部分で、より高速でコスト効率の高い Amazon EC2 Inf1 インスタンスによる実行を開始 (AWSブログ)
- Achieving 1.85x higher performance for deep learning based object detection with an AWS Neuron compiled YOLOv4 model on AWS Inferentia (AWS Blog)
- Deploying TensorFlow OpenPose on AWS Inferentia-based Inf1 instances for significant price performance improvements (AWS Blog)