Artificial Intelligence
Deploying TensorFlow OpenPose on AWS Inferentia-based Inf1 instances for significant price performance improvements
In this post you will compile an open-source TensorFlow version of OpenPose using AWS Neuron and fine tune its inference performance for AWS Inferentia based instances. You will set up a benchmarking environment, measure the image processing pipeline throughput, and quantify the price-performance improvements as compared to a GPU based instance.
About OpenPose
Human pose estimation is a machine learning (ML) and computer vision (CV) technology supporting many applications, from pedestrian intent estimation to motion tracking for AR and gaming. At its core, pose estimation identifies coordinates on an image (joints and keypoints), that, when connected, form a representation of an individual skeleton. The representation of body orientation enables tasks such as teaching a robot to interact with humans or quantifying how good yoga asanas really are.
Amongst the many methods that can be used for human pose estimation, the deep learning (DL) bottoms-up approach taken by OpenPose—released by the Perceptual Computing Lab of Carnegie Mellon University in 2018—has gained a lot of users. OpenPose is a multi-person 2D pose estimation model that employs a technique called Part Affinity Fields (PAF) to associate body parts and form multiple individual skeletons on the image. In the bottoms-up approach, the model identifies the key points and pieces together the skeleton.
To achieve that, OpenPose uses a two-step process. First, it extracts image features using a VGG-19 model and passes those features through a pair of convolutional neural networks (CNN) running in parallel.
One of the CNNs in the pair computes confidence maps to detect body parts. The other computes the PAF and combines the parts to form the individual’s skeleton. You can repeat these parallel branches many times to refine the predictions of the confidence maps and PAF.
The following diagram shows features F from a VGG feeding the PAF and confidence map branches of the OpenPose model. (Source: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields)
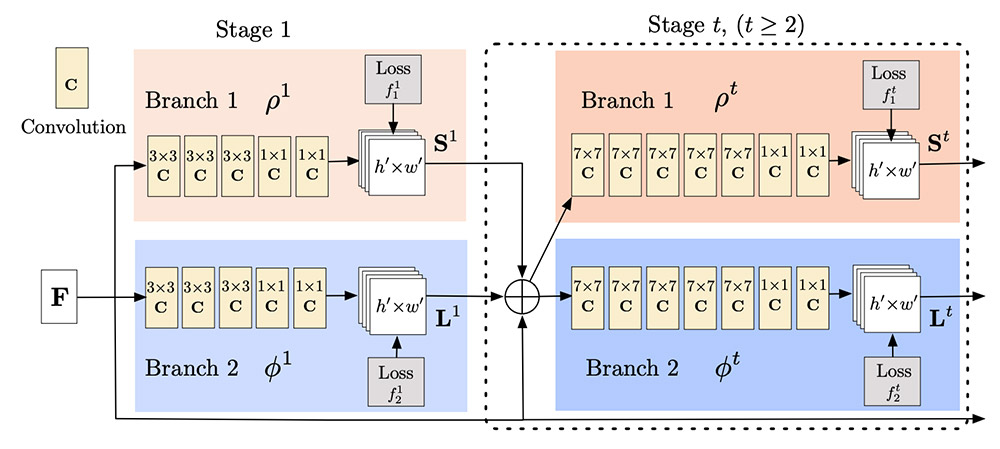
The original OpenPose code relies on a Caffe model and pre-compiled C++ libraries. For ease of use and portability of our walkthrough, we work with a reimplementation of the neural networks of OpenPose using TensorFlow 1.15 from the tf-pose-estimation GitHub repo. This repo also provides ML pipeline scripts to pre- and post-process images and videos using OpenPose.
Prerequisites
For this walkthrough, you need an AWS account with access to the AWS Management Console and the ability to create Amazon Elastic Compute Cloud (Amazon EC2) instances with public-facing IP and Amazon Simple Storage Service (Amazon S3) buckets.
Working knowledge of AWS Deep Learning AMIs and Jupyter notebooks with Conda environments is beneficial, but not required.
About AWS Inferentia and Neuron SDK
AWS Inferentia chips are custom built by AWS to provide high-performance inference, with the lowest cost of inference in the cloud, and make it easy for you to integrate ML as part of your standard application features and capabilities.
AWS Neuron is a software development kit (SDK) consisting of a compiler, runtime, and profiling tools that optimize the ML inference performance for the Inferentia chips. Neuron is integrated with popular ML frameworks such as TensorFlow, PyTorch, and MXNet and comes pre-installed in AWS Deep Learning AMIs. Deploying deep learning models on AWS Inferentia is done in the same familiar environment used in other platforms, and you can enjoy the boost in performance and lowest cost.
The latest Neuron release, available on the AWS Neuron GitHub, adds support for more models like OpenPose, which we focus on in this post. It also upgrades Neuron PyTorch to the latest stable version (1.5.1), which allows for a wider range of models to compile and run on AWS Inferentia.
Compiling a TensorFlow OpenPose model with the Neuron SDK
You can start the compilation process by setting up an EC2 instance in AWS for compiling the model. We recommend a z1d.xlarge, due to its good single-core performance and memory size. Use the AWS Deep Learning AMI (Ubuntu 18.04) Version 29.0—ami-043f9aeaf108ebc37—in the US East (N. Virginia) Region. This AMI comes pre-packaged with the Neuron SDK and the required Neuron runtime for AWS Inferentia.
For more information about running AWS Deep Learning AMIs on EC2 instances, see Launching and Configuring a DLAMI.
When you can connect to the instance through SSH, you activate the aws_neuron_tensorflow_p36 Conda environment and update the Neuron Compiler to the latest release. The compilation script depends on requirements listed in the file requirements-compile.txt. For compilation scripts and requirements files, see the GitHub repo. Download and install them in the environment with the following code:
You can then start working on the compilation process. You compile the tf-pose-estimation network frozen graph, available on the GitHub repo. You can adapt the original download script to a single-line wget command:
When the download is complete, run the convert_graph_opt.py script to compile it for the AWS Inferentia chip. Because Neuron is an ahead-of-time (AOT) compiler, you need to define a specific image size prior to compilation. You can adjust the network input image resolution with the argument --net_resolution (for example, net_resolution=656x368).
The compiled model can accept arbitrary batch size inputs at inference runtime. This property enables benchmarking large-scale deployments of the model; however, the pipeline available for image and video process in the tf-pose-estimation repo utilizes batch size 1.
To start the compilation process, enter the following code:
The compilation process can take up to 20 minutes to complete. During this time, the compiler optimizes the TensorFlow graph operations and provides the AWS Inferentia version of the saved model. During the process you can expect detailed logs such as the following:
Before you can measure the performance of the compiled model, you need to switch to an EC2 Inf1 instance, powered by the AWS Inferentia chip. To share the compiled model between the two instances, create an S3 bucket with the following code:
Benchmarking the inference time with a Jupyter notebook on AWS EC2 Inf1 instances
After you have the compiled graph_model.pb in your S3 bucket, you modify the ML pipeline scripts on the GitHub repo to estimate human poses from images and videos.
To set up the benchmarking Inf1 instance, you can repeat the steps you took to provision the compilation z1d instance. You use the same AMI but change the instance type to inf1.xlarge. A similar setup on a g4dn.xlarge instance might be useful to compare the performance of the base tf-pose-estimation model on GPUs against the compiled model for AWS Inferentia.
Throughout this post, you interact with this instance and the model using a Jupyter Lab server. For more information about provisioning a Jupyter Lab on Amazon EC2, see Set Up a Jupyter Notebook Server.
Setting up the Conda Environment for tf-pose
When you can log in to the Jupyter Lab server, you can clone the GitHub repo containing the TensorFlow version of OpenPose.
On the Jupyter Launcher page, under Other, choose Terminal.

In the terminal, activate the aws_neuron_tensorflow_p36 environment, which contains the Neuron SDK. Activating the environment and cloning are done with the following code:
When the cloning is complete, we recommend following the Package Install instructions to install the repo. From the same terminal screen, you customize the environment by installing opencv-python and dependencies listed on the requirements.txt of the GitHub repo.
You run two pip commands: the first takes care of opencv-python and the second completes the installation of the requirements.txt:
You’re now ready to build the notebooks.
On the repo’s root directory, create a new Jupyter notebook by choosing Notebook, Environment (conda_aws_neuron_tensorflow_p36). On the first cell of the notebook, import the library as defined in the run.py script, which is the reference pipeline for image processing. In the following cell, create a logger to record the benchmarking. See the following code:
Define the main inferencing function main() and a helper plotter function plotter(). These functions directly replicate the OpenPose inference pipeline from run.py. One simple modification is the addition of a repeats argument, which allows you to run many inference steps in sequence and improve the measure of the average model throughput (measured in seconds per image):
Additionally, you can modify the same code structure for inferencing on videos or batches of images, based on the run_video.py or run_directory.py, if you’re feeling adventurous!
The main() function takes as input the same string of arguments as described in the Test Inference section of the GitHub repo. To test the notebook implementation, you use a reference set of arguments (make sure to download the cmu model using the original download script):
The logs show your first multi-person pose analyzed:
This results in lower than one frame per second (FPS) throughput, which is not a great performance. In this use case, you’re running a TensorFlow graph, --model cmu, without a GPU. The performance of such a model isn’t optimal on CPU. If you repeat the setup and run the environment on a g4dn.xlarge instance, with one NVIDIA T4 GPU, the result is quite different:
The result is 5.85 FPS, which is much better.
Using the Neuron compiled CMU model
So far, you’ve used model artifacts that came with the repo. Instead of using the original download script to retrieve the CMU model, copy the Neuron compiled model into ./models/graph/cmu/graph_model.pb and rerun the test:
Make sure to restart the Python kernel on the notebook if you previously ran a test of the non-Neuron compiled model. Restarting the kernel helps make sure all TensorFlow sessions are closed and get a fresh start for the benchmark. Running the same notebook again results in the following log entry:
The results show the same frame rate as compared to the g4dn.xlarge instance, in an environment that costs approximately 30% less on demand. Despite the cost benefit from moving the workload to an AWS Inferentia-based instance, this throughput doesn’t convey the observed large performance gains of other reported results. For example, Amazon Alexa text to speech team has cut their inference cost by 50% when migrating to AWS Inferentia.
We decided to profile our version of the compiled graph and look for opportunities to fine-tune the end-to-end inference performance of the OpenPose pipeline. The integration of Neuron with TensorFlow gives access to native profiling libraries. To profile the Neuron compiled graph, we instrumented the TensorFlow session run command on the estimator method using the TensorFlow Python profiler:
The model_analyzer.profile method prints on StdErr the time and memory consumption of each operation on the TensorFlow graph. With the original code, the Neuron operation and a smoothing operation dominated the total graph runtime. The following output from the StdErr log shows that the total graph runtime took 108.02 milliseconds, of which the smoothing operation took 43.07 milliseconds:
The smoothing method provides a gaussian blur of the confidence maps calculated by OpenPose. By optimizing this operation, we can extract even more performance out of our end-to-end pose estimation. We modified the filter argument of the smoother on the estimator.py script from 25 to 5. This new configuration took down the total runtime to 67.44 milliseconds, of which the smoother now only takes 2.37ms—a 37% reduction! On a g4dn, this same optimization had little effect on the runtime. You can also optimize your version of the end-to-end pipeline by changing the same parameters and reinstalling the tf-pose-estimation repo from your local copy.
We ran the same benchmark across seven different instances types and sizes to evaluate the performance and cost of inference of our optimized end-to-end image processing pipeline. For comparison, we also show the On-Demand instance pricing from Amazon EC2 Pricing.
The throughput on the smallest size Inf1 instance—xlarge—is 2 times higher than that of the largest g4dn instance evaluated —8xlarge—at 12 times less the cost per 1000 images. Comparing the two best options, inf1.xlarge and g4dn.xlarge, inf1 has 72% lower cost per 1000 images, or a 3.57 times better price to performance compared to the lowest cost GPU option. The following table summarizes these findings.
| inf1.xlarge | inf1.2xlarge | inf1.6xlarge | g4dn.xlarge | g4dn.2xlarge | g4dn.4xlarge | g4dn.8xlarge | |
| Image process time [seconds/image] | 0.0703 | 0.0677 | 0.0656 | 0.1708 | 0.1526 | 0.1477 | 0.1427 |
|
Throughput [FPS] |
14.22 | 14.77 | 15.24 | 5.85 | 6.55 | 6.77 | 7.01 |
| 1000 Images processing time [seconds] | 70.3 | 67.7 | 65.6 | 170.8 | 152.6 | 147.7 | 142.7 |
|
On demand cost [$/hr] |
$ 0.368 | $ 0.584 | $ 1.904 | $ 0.526 | $ 0.752 | $ 1.204 | $ 2.176 |
|
Cost per 1000 images [$] |
$ 0.007 | $ 0.011 | $ 0.035 | $ 0.025 | $ 0.032 | $ 0.049 | $ 0.086 |
The chart below summarizes the throughput and cost per 1000 images results for the xlarge and 2xlarge instance sizes.

We further reduced the image-processing cost and increased throughput of the tf-pose-estimation on an Inf1 instance by taking a data parallel approach to the end-to-end pipeline. The values shown in the preceding table relate to the use of a single AWS Inferentia processing core—a Neuron core. The benchmarked instance has four, so it’s wasteful to use only one. Our test with embarrassingly parallel implementation of the main()function call using the Python joblib library showed linear scaling up to four threads. This pattern increased the throughput to 56.88 FPS and decreased the cost per 1000 images to below $0.002. This is a good indication that better batching strategy can further improve the price-performance ratio of OpenPose on AWS Inferentia.
The larger CMU model also provides good pose estimation performance. For example, see the following image of the multi-pose detection using the Neuron SDK compiled model, on a scene with subjects at multiple depths.

Safely shutting down and cleaning up
On the Amazon EC2 console, choose the compilation and inference instances, and choose Terminate from the Actions drop-down menu. You persisted the compiled model in your s3://<MY_BUCKET_NAME> so it can be reused later. If you’ve made changes to the code inside the instances, remember to persist those as well. The instance termination discards data stored only in the instance’s home volume.
Conclusion
In this post, you walked through the steps of compiling an open-source OpenPose TensorFlow model, updating a custom end-to-end image processing pipeline, and identifying tools to profile and further optimize your ML inference time on an EC2 Inf1 instance. When tuned, the Neuron compiled TensorFlow model was 72% less expensive than the cheapest GPU instance, with consistently better performance. The steps described in this post also apply to other ML model types and frameworks. For more information, see the AWS Neuron SDK GitHub repo.
Learn more about the AWS Inferentia chip and the Amazon EC2 Inf1 instances to get started with running your own custom ML pipelines on AWS Inferentia using the Neuron SDK.
About the Authors
 Fabio Nonato de Paula is a Principal Solutions Architect for Autonomous Computing in AWS. He works with large-scale deployments of machine learning and AI for autonomous and intelligent systems. Fabio is passionate about democratizing access to accelerated computing and distributed ML. Outside of work, you can find Fabio riding his motorcycle on the hills of Livermore valley or reading ComiXology.
Fabio Nonato de Paula is a Principal Solutions Architect for Autonomous Computing in AWS. He works with large-scale deployments of machine learning and AI for autonomous and intelligent systems. Fabio is passionate about democratizing access to accelerated computing and distributed ML. Outside of work, you can find Fabio riding his motorcycle on the hills of Livermore valley or reading ComiXology.
 Haichen Li is a software development engineer in the AWS Neuron SDK team. He works on integrating machine learning frameworks with the AWS Neuron compiler and runtime systems, as well as developing deep learning models that benefit particularly from the Inferentia hardware.
Haichen Li is a software development engineer in the AWS Neuron SDK team. He works on integrating machine learning frameworks with the AWS Neuron compiler and runtime systems, as well as developing deep learning models that benefit particularly from the Inferentia hardware.