Amazon Web Services ブログ
Amazon SageMaker でコンピュータビジョン推論に最適な AI アクセラレータとモデルコンパイルを選択
この記事は、2021 年 10 月 19 日に Davide Gallitelli 、 Hasan Poonawala によって投稿された Choose the best AI accelerator and model compilation for computer vision inference with Amazon SageMaker を翻訳したものです。
AWS のお客様では、コンピュータビジョンモデルによる予測で強化されたアプリケーションを構築するケースが増えています。例えば、フィットネスアプリケーションでは、カメラの前で運動しているユーザーの体の姿勢を監視し、ユーザーにライブフィードバックと定期的なインサイトを提供します。同様に、大規模な倉庫の在庫検査ツールでは、ネットワーク全体で何百万もの画像をキャプチャして処理し、本来あるべき場所にない在庫を発見します。
モデルの学習後、機械学習 (ML) チームは、モデルを本番環境にデプロイするための適切なハードウェアおよびソフトウェア構成を選択するために最大数週間かかることがあります。コンピューティングインスタンスタイプ、AI アクセラレータ、モデルサービングスタック、コンテナパラメータ、モデルコンパイル、モデル最適化など、いくつかの選択肢があります。これらの選択肢は、スループットやレイテンシーなどアプリケーションのパフォーマンス要件、およびコストの制約によって異なります。ML チームは、ユースケースに応じて、低い応答レイテンシー、高いコスト効率、高いリソース使用率、またはこれらの特定の制約の組み合わせを最適化する必要があります。コストパフォーマンスを最適化するために、ML チームはさまざまな組み合わせをチューニングし、負荷テストを行い、与えられた入力データとモデル出力データで比較可能なベンチマークを用意する必要があります。
Amazon SageMaker は、データサイエンティストや開発者が高品質な ML モデルを迅速に準備、ビルド、学習、デプロイできるように、ML 用に構築された幅広い機能をまとめて提供します。 SageMaker は、XGBoost(コンテナ、SDK)、scikit-learn(コンテナ、SDK)、PyTorch(コンテナ、SDK)、TensorFlow(コンテナ、SDK)、Apache MXNet(コンテナ、SDK)に対応した最先端のオープンソースのモデルサービングコンテナを提供しています。SageMaker では、新しいデータで推論するために、学習済み ML モデルをデプロイするための3つのオプションを提供しています。 リアルタイム推論エンドポイントは、低レイテンシーの要件で処理する必要があるワークロードに適しています。SageMaker での推論のために、コンピューティング最適化、メモリ最適化、AWS Inferentia のような AI アクセラレータなど、いくつかのインスタンスを選択することができます。 Amazon SageMaker Neo は SageMaker の機能の一つで、Gluon、Keras、MXNet、PyTorch、TensorFlow、TensorFlow-Lite、ONNX のモデルを自動的にコンパイルし、様々なターゲットハードウェア上で推論することができます。
この記事では、PyTorch ResNet50 の画像分類モデルの負荷テストベンチマークを構築する方法を、SageMaker のプリビルドされた TorchServe コンテナと、Nvidia T4 GPUを搭載した g4dn や AWS Inferentia を搭載した Inf1 などのインスタンス選択の組み合わせ、および Neo によるモデルのコンパイル方法とともに紹介します。
このトピックに関連する記事は以下の通りです。
- 深層学習推論のための AI アクセラレータ完全ガイド — GPU、AWS Inferentia、Amazon Elastic Inference — 著者は、AWS 上での推論に適切な AI アクセラレータを選択する方法について説明しています。コンピューティングの選択肢には、CPU や NVIDIA T4 などの NVIDIA GPU、AWS Inferentia が含まれます。
- リアルタイム推論のために Amazon SageMaker エンドポイントでの TensorFlow パフォーマンスを最大化 — この記事で紹介されているパフォーマンスチューニングには、高いピークスループットと低いレイテンシーを実現するためのモデルとコンテナパラメータの選択が含まれています。
- Amazon SageMaker で YOLOv4 推論を 2 倍に高速化 — この記事ではモデルを Neo でコンパイルし、同じインスタンス上のコンパイルされていないモデルと比較しています。
- AWS Inferentia、AWS Neuron でコンパイルされた YOLOv4 モデルを用いた深層学習ベースの物体検出で 1.85 倍の高パフォーマンスを達成 — 著者は、AWS Inferentia ベースの Amazon EC2 Inf1 で TensorFlow YoLov4 モデルでより高いパフォーマンスを達成する方法について説明しています。このモデルは AWS Neuron でコンパイルされ、g4dn Amazon Elastic Compute Cloud (Amazon EC2) インスタンスでの結果と比較しています。
実験の概要
この記事では、同時クライアント接続を設定し、ピーク時のスループット/秒 (TPS) まで負荷を高めています。この画像分類の CV タスクでは、Neo でコンパイルしたモデルを g4dn インスタンスにデプロイした場合、同じ g4dn インスタンスにモデルをコンパイルせずにデプロイした場合と比較し、スループットが 1.9 倍増加し、レイテンシーが 50% 低くなり、100 万回の推論あたりのコストを 50% 削減できました。さらに、Neo でコンパイルしたモデルを Inf1 インスタンスにデプロイした場合は、スループットが 4.1 倍増加し、レイテンシーが 77% 低くなり、100 万回の推論あたりのコストを 90% 削減できました。AWS Inferentia インスタンスは、Neo でコンパイルしたモデルを用いた g4dn インスタンスと比較し、 5.4 倍高いコストパフォーマンスを達成しています。
次の図は、本実験のアーキテクチャを示しています。
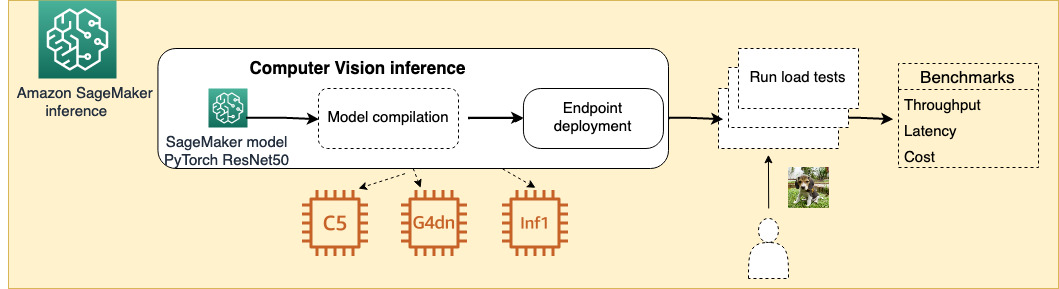
この実験に使用したコードは GitHub リポジトリに含まれています。
AI アクセラレータとモデルのコンパイルの有無
このテストでは、PyTorch Hub から事前学習済みの ResNet50 モデルをデプロイして性能検証を実施しました。モデルは 3 つの異なるインスタンスにデプロイしています。
- CPU インスタンスには、c5.xlarge を選択しました。このインスタンスは、第 1 世代または第 2 世代の インテル Xeon Platinum 8000シリーズプロセッサ (Skylake-SP または Cascade Lake) を搭載し、持続的な全コアターボクロック速度は最大 3.6 GHz です。
- GPU インスタンスには、g4dn.xlarge を選択しました。このインスタンスは NVIDIA T4 GPU を搭載し、CPU に比べて最大 40 倍の低レイテンシースループットを実現し、ML 推論で最もコストパフォーマンスが高くなります。
- AWS Inferentia には、inf1.xlarge インスタンスを選択しました。Inf1 インスタンスは、ML 推論アプリケーションをサポートするため、AWS が新規に開発しました。同等の現行世代の GPU ベースの EC2 インスタンスと比べて、最大 2.3 倍のスループットと推論あたりのコストを最大 70% 削減します。
CPU 及び GPU インスタンスでは、標準モデルと、Neo でコンパイルしたモデルをそれぞれデプロイして性能を比較しています。Inf1 インスタンスでは、コンパイルしたモデルが必須となります。
モデル
ResNet50 は 48 の畳み込み層と、1 つの MaxPool 層、1 つの平均プール層を持つ ResNet モデルの一種で 3.8 x 10^9 の浮動小数点演算 (FLOPS) を必要とします。ResNet は 2015 年に論文「Deep Residual Learning for Image Recognition」(arXiv)で発表されて以来、多くの分類および検出タスクで最先端の結果を提供しています。
テストでは PyTorch の実装を使用しました。ドキュメントは PyTorch Hub ページで公開されており、ImageNet データセットで事前学習済みのモデルを利用します。
入力データ
モデルをテストするために、Wikimedia にある草の上に座っているビーグル犬の子犬の 3 x 224 x 224 JPG 画像を使用します。
{kind=link}
この画像は、SageMaker エンドポイントへのリクエストの本文にバイト列として送信されます。画像のサイズは 21 KB です。エンドポイントではこの画像を読み込み、パースし、Pytorch.Tensor に渡しモデル処理を実行する役割を担います。
実験を実行
まず、ml.c5.4xlarge インスタンスで Amazon SageMaker Studio ノートブックを起動します。これは、モデルをダウンロードし、SageMaker リアルタイムインスタンスにデプロイし、レイテンシーとスループットをテストするためのメインのインスタンスです。この実験の結果を再現する場合は、SageMaker ノートブックインスタンスや、 AWS Lambda 、Amazon EC2 、Amazon Elastic Container Service(Amazon ECS)などのコンピューティング用の他のクラウドサービス、またはローカル IDE を使用することもできるため、Studio ノートブックはオプションです。この記事では、Studio ドメインがすでに稼働していることを前提としています。そうでない場合は、 Studio にオンボード できます。
Studio ドメインを開いたら、 GitHub で公開されているリポジトリをクローンし、resnet50.ipynb ノートブックを開きます。基本となるインスタンスを切り替えるには、詳細を選択し (次のスクリーンショットを参照)、ml.c5.4xlarge を選択してから、カーネルを Python 3 (PyTorch 1.6 Python 3.6 CPU Optimized) オプションに切り替えます。

新しいインスタンスを起動してカーネルをアタッチするプロセスには、約 3 ~ 4 分かかります。完了したら、最初のセルを実行できます。このセルでは、モデルを Amazon Simple Storage Service (Amazon S3) にアップロードする前に、ローカルでモデルをダウンロードします。このセルでは、SageMaker のデフォルトバケットを S3 のバケットとして使用し、用意したプレフィックスを使用します。以下はデフォルトのコードです。
pytorch_resnet50_prefix = 'pytorch/resnet50'
model_data = sess.upload_data('model.tar.gz', bucket, pytorch_resnet50_prefix)download_the_model パラメーターを False に設定したままにすると、モデルはダウンロードされません。これは、同じアカウントでノートブックを再度実行する予定がある場合に最適です。
SageMaker がモデルをリアルタイムエンドポイントにデプロイするためには、SageMakerはどのコンテナイメージがモデルをホストしているかを知る必要があります。SageMaker Python SDK は、よく知られたフレームワークがネイティブにサポートされており、作業を簡素化するためのいくつかの抽象化を提供します。この記事では、PyTorchModel というオブジェクトを使用します。PyTorchModel は、フレームワークのバージョンに応じて正しいイメージ URI を提供し、デプロイするモデルを抽象化します。SageMaker が PyTorch モデルサーバーをデプロイする方法の詳細については、The SageMaker PyTorch Model Server を参照してください。私たちの PyTorchModel は以下のコードでインスタンス化されています。
pth_model = PyTorchModel(model_data=model_data,
entry_point='uncompiled-inference.py',
source_dir='code',
role=role,
framework_version='1.7',
py_version='py3'
)パラメータについて深く掘り下げてみましょう。
- model_data — モデルの入った
.tar.gzファイルを含む S3 パスを表します。 - entry_point — この Python スクリプトには、推論ロジックが含まれており、モデルの読み込み方法 (
model_fn)、推論前のデータの前処理方法 (input_fn)、推論の実行方法 (predict_fn) および推論後のデータの後処理方法 (output_fn) が含まれています。詳細については、The SageMaker PyTorch Model Server を参照してください。 - source_dir — エントリポイントファイルを含むフォルダで、他の依存関係や
requirements.txtファイルなどの有用なファイルも含まれます。 - framework_version, py_version — 使用したい Python と PyTorch のバージョンです。
- role — 異なる AWS リソースにアクセスするためにエンドポイントに割り当てるロールです。
モデルオブジェクトを設定したら、それをリアルタイムエンドポイントにデプロイできます。SageMaker Python SDK は、model.deploy () という関数を使用し、この作業を簡単に行うことができます。この関数は 2 つのパラメータを受け取ります。
- initial_instance_count — リアルタイムエンドポイントで最初に使用するインスタンスの数。設定に応じて、その後自動的にスケーリングできます。詳細については、Automatically Scale Amazon SageMaker Models を参照してください。
- instance_type — デプロイするインスタンスを指定します。
前述の通り、CPUインスタンス(ml.c5.xlarge)を持つマネージド SageMaker エンドポイントと、GPU を搭載したマネージド SageMaker インスタンス(ml.g4dn.xlarge)にモデルをそのままデプロイします。モデルがデプロイされたので、テスト可能です。これは、SageMaker 用の Python SDK とそのメソッド predict () 、または AWS SDK for Python で定義された Boto3 クライアントとそのメソッド invoke_endpoint () のいずれかによって可能になります。このステップでは、どちらの API を使った予測も実行しません。その代わり、後でテストを実行する際に必要となるため、エンドポイント名を保存しています。
Neo でモデルをコンパイル
より高度なユースケースでよく使用される方法は、モデルをコンパイルすることで、レイテンシーとスループットの観点からモデルのパフォーマンスを向上させることです。SageMaker では独自のコンパイラ Neo を提供しており、データサイエンティストは、クラウドの SageMaker やエッジのサポート対象デバイス上で 推論するために ML モデルを最適化することができます。
モデルをコンパイルするためには、いくつかの手順を完了する必要があります。まず、コンパイルしようとしているモデルとそのフレームワークが Neo コンパイラによってサポートされていることを確認してください。SageMaker によって管理されるインスタンスにデプロイするため、サポートされているインスタンスタイプとフレームワークのリストを参照することができます。PyTorch 1.6 上での ResNet50 モデルはサポートされていますので、このまま先に進みます。
次のステップでは、コンパイル用にモデルを準備します。Neo では、モデルが特定の入力データ形状を満たす必要があり、モデルを特定のデータ構造に従って保存する必要があります。PyTorch モデルのディレクトリ構造によれば、 model.tar.gz ファイルの内容は、モデル自体をファイルのルートに置き、推論コードを code/ フォルダの下に置く必要があります。Python で tarfile パッケージを使用して、以下の手順でアーカイブファイルを作成します。
import tarfile
with tarfile.open('model-to-compile.tar.gz', 'w:gz') as f:
f.add('model.pth')
f.add('code/compiled-inference.py', 'code/inference.py')作成したファイルはAmazon S3にアップロードします。その後、新しい PyTorchModel オブジェクトをインスタンス化し、compile() 関数を呼び出してコンパイルします。この関数にはいくつかのパラメータが必要です。
- target_instance_family — コンパイルの対象となるインスタンスです。有効な値のリストについては、TargetDevice を参照してください。
- input_shape — モデルの保存時に設定された、モデルが期待する入力の形状です。
- output_path — コンパイルジョブの出力(コンパイルされたモデル)を保存する場所です。
コンパイルは、以下のコードスニペットを実行することで始まります。
compiled_model = pth_model.compile(
target_instance_family='ml_c5',
input_shape={"input0": [1, 3, 224, 224]},
output_path=output_path,
role=role,
job_name=name_from_base('pytorch-resnet50-c5')
)AWS Inferentia インスタンス用にコンパイル
モデルのパフォーマンスを向上させるためにもう一つ試すことができます。それは、AWS Inferentia インスタンスを使用することです。AWS Inferentia インスタンスでは、コンパイル時のターゲットとして ml_inf1 を選択する際に、すでに Neo コンパイラの一部となっている Neuron SDK でモデルをコンパイルする必要があります。AWS Inferentia と SageMaker でサポートされている深層学習フレームワークとモデルについては、AWS Inferentia を参照してください。また、Neuron SDK の詳細については、サービスページおよび開発者向けドキュメントを参照してください。次のコードを実行して、AWS Inferentia インスタンス用にコンパイルとデプロイを実行します。
# Define the PyTorchModel
pth_model = PyTorchModel(
model_data=model_data,
entry_point='compiled-inference.py',
source_dir='code',
role=role,
framework_version='1.7',
py_version='py3'
)
# Compile it
compiled_model = pth_model.compile(
target_instance_family='ml_inf1',
input_shape={"input0": [1, 3, 224, 224]},
output_path=output_path,
role=role,
job_name=name_from_base('pytorch-resnet50-inf1'),
compile_max_run=1000 # Compilation for inf1 takes slightly longer!
)
# Deploy it
predictor = compiled_model.deploy(1, 'ml.inf1.xlarge')実験結果
スループットとレイテンシーを測定するために、私たちはテストスクリプトを書きました。このテストスクリプトは、リポジトリの load_test.py ファイルに含まれています。負荷テストモジュールは、Python の マルチスレッディングを用いて複数の同時クライアント呼び出しを作成し、1 秒あたりのスループットとエンドツーエンドのレイテンシーを測定します。今回のテストでは、クライアント用のテストインスタンスとして ml.c5.4xlarge を選択しました。このインスタンスには 16 個の vCPU が搭載されているため、16 個の同時スレッドを使用するようにテストスクリプトを設定しました(num_threads=16)。インスタンスの仕様の詳細については、Amazon SageMaker の料金 を参照してください。このテストでは、推論ごとに 1 つのイメージしか使用していません。推論ごとに複数の画像をバッチ処理すると、以下のすべてのインスタンスで異なる結果が得られます。今回のテスト結果は以下の表の通りです。

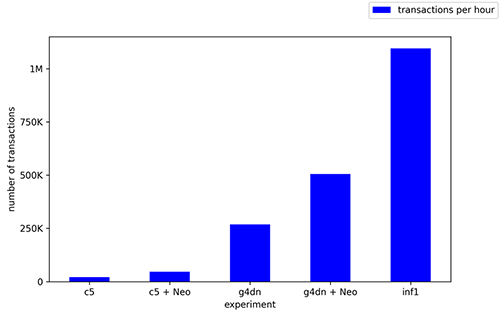
スループットとレイテンシーは、最高のパフォーマンスを発揮するインスタンスとコンパイルの組み合わせを定義するのに十分な 2 つの指標ですが、インスタンスの時間当たりのコストは考慮されていません。そこで、推論の一般的な指標である、100万回の推論あたりのコストを紹介します。以下のグラフは、今回のテストで得られた結果をまとめたものです。AWS Inferentia インスタンスは、CV 推論ワークロードにおいて最もコストパフォーマンスの高いインスタンスです。100 万回の推論あたりのコストを比較すると、g4dn.xlarge インスタンスのコンパイル済みモデルでは 1.62 USD、ml.c5.xlarge インスタンスのコンパイル済みモデルでは 4.95 USD ですが、inf1.xlarge インスタンスでは 0.3 USD です。inf1.xlarge インスタンスではそれぞれ 5.4 倍、16.5 倍とコストパフォーマンスが向上しました。

1 時間あたりのトランザクション数 (TPH) を考慮すると、GPU でコンパイルされたモデルが 50 万 TPH、CPU でコンパイルされたモデルが 4 万 TPH であるのに対し、AWS Inferentia インスタンスは110 万 TPH を達成し、最高のパフォーマンスを示しました。
まとめ
この記事では、PyTorch Vision Hub の事前学習済みの ResNet50 モデルを使用し、SageMaker で複数のインスタンスタイプにデプロイし、コンパイル前後のパフォーマンスを負荷テストしました。モデルは、CPU (ml.c5.xlarge)、GPU (ml.g4dn.xlarge)、AWS Inferentia チップ (ml.inf1.xlarge) の3種類の異なる 推論用 AI アクセラレータにデプロイしました。形状が 3 x 224 x 224 の 1 つの入力画像を使用し、モデルの同時呼び出しによって実施したテストでは、AWS Inferentia インスタンスが 1 秒あたりのスループットが最も高く(304.3 推論/秒)、レイテンシーが最も低く(4.9 ミリ秒)、コストパフォーマンスが最も高い(100 万推論あたり 0.3 USD)結果となりました。
これらの結果は、AWS Inferentia インスタンスが SageMaker 上の CV ワークロードに対して最高のコストパフォーマンスを提供していることを示しています。PyTorch および TensorFlow でサポートされているオペレータを確認することで、AWS Inferentia とのモデルの互換性を確認することができます。Neo は、AWS Inferentia でデプロイされるモデルに加えて、汎用 GPU インスタンスにもモデルのコンパイルを提供します。AWS Inferentia インスタンスでまだサポートされていないモデルは、Neo でコンパイルして GPU インスタンスにデプロイすることで、直接デプロイした場合と比較して TPS とレイテンシーの両方を 2 倍向上させることができます。
Distillation(蒸留)、Pruning(枝刈り)、Quantization(量子化)など、他のモデル最適化手法を試すことも可能です。GitHub リポジトリのベンチマークコードサンプルを使用して、モデル最適化とインスタンスタイプの独自の組み合わせを負荷テストし、その結果をコメントでお知らせください!
________________________________________
翻訳はアンナプルナラボの常世が担当しました。