Artificial Intelligence
Speed up YOLOv4 inference to twice as fast on Amazon SageMaker
Machine learning (ML) models have been deployed successfully across a variety of use cases and industries, but due to the high computational complexity of recent ML models such as deep neural networks, inference deployments have been limited by performance and cost constraints. To add to the challenge, preparing a model for inference involves packaging the model in the right format and optimizing the model for each target hardware such as CPU, GPU, or AWS Inferentia. ML acceleration technologies have evolved to close the gap between productivity-focused ML frameworks and performance-oriented and efficiency-oriented hardware backends. However, optimizing a model for target hardware still involves assembling a complex tool chain of framework-specific converters and hardware-specific compilers, each with their own dependencies and configuration choices that can be difficult to understand, and then using it to compile the model.
Amazon SageMaker is a fully managed service that enables data scientists and developers to build, train, and deploy ML models at 50% lower total cost of ownership than self-managed deployments on Amazon Elastic Compute Cloud (Amazon EC2). Amazon SageMaker Neo is a capability of SageMaker that automatically compiles ML models for any ML framework and to any target hardware. With Neo, you don’t need to set up third-party or framework-specific compiler software, or tune the model manually for optimizing inference performance. We’re continually updating Neo to support more operators and expand model coverage for frameworks, including TensorFlow, PyTorch, XGBoost, MXNet, Darknet, and ONNX.
In this post, we show you how to deploy a PyTorch YOLOv4 model on a SageMaker ML CPU-based instance. You download a pre-trained model artifact, compile your pre-trained model using Neo, set up a SageMaker endpoint for both compiled and uncompiled model versions, and benchmark performance to evaluate latency, comparing a compiled and uncompiled YOLOv4 model on the same instance.
In our performance comparison, deploying YOLOv4 with Neo improved performance on SageMaker ML instances. Benchmark testing on a SageMaker ML c5.9xlarge instance revealed improved inference performance compared to a baseline model without Neo optimizations running on the same instance type. The Neo compiled model achieved a speedup in latency twice as fast compared to an uncompiled model on the same SageMaker ML instance.
You Only Look Once
Object detection stands out as a computer vision (CV) task that has seen large accuracy improvements due to deep learning (DL) model architectures. An object detection model tries to localize and classify objects in an image, allowing for applications ranging from real-time inspection of manufacturing defects to medical imaging.
YOLO (You Only Look Once) is part of the DL single-stage object detection model family, which includes models such as Single Shot Detector (SSD) and RetinaNet. These models are built by stacking neural networks (backbone, neck, and head) that together perform detection and classification tasks. The prediction outputs are bounding boxes with confidence scores for identified objects and associated classes.
The backbone network takes care of extracting features of the input image, while the head gets trained on a supervised prediction task to predict the edges of the bounding box and classify its contents. The addition of a neck neural network allows the head network to process features from intermediate steps of the backbone. The whole pipeline processes the images only once, hence the name You Only Look Once.
Single-stage models allow for multiple predictions of the same object in a single image. These predictions get disambiguated by a process called non-maximal suppression (NMS), which takes care of leaving only the highest detection probability bounding boxes that don’t overlap significantly. It’s a less computationally expensive workflow than the two-stage approach and is commonly used in real-time inference. With YOLOv4, you can achieve real-time inference above the human perception of around 30 frames per second (FPS). In this post, you explore ways to push the performance of this model even further using Neo as an accelerator for real-time object detection.
Prerequisites
For this walkthrough, you need an AWS account and an environment running Python 3.x.
Setup
First, we need to ensure we have SageMaker Python SDK 1.x and import the necessary Python packages. If you’re using SageMaker notebook instances, select conda_pytorch_p36 as your kernel. You may have to restart your kernel after upgrading packages. Use the following code to import your packages:
Next, we get the AWS Identity and Access Management (IAM) execution role and a few other SageMaker-specific variables from our notebook environment, so that SageMaker can access resources in your AWS account later:
Import pre-trained YOLOv4
The original pre-trained model is from GitHub. For this post, we provide a traced version of the model artifact packaged in a tarball. Tracing requires no changes to your Python code and converts your PyTorch model to TorchScript, a more portable format for usage with the model server included in SageMaker containers. See the following code:
We upload the model archive to Amazon Simple Storage Service (Amazon S3) with the following code:
Create a SageMaker model and endpoint
Now that the model archive is in Amazon S3, we can create a SageMaker model and deploy it to a SageMaker endpoint. An entry_point script isn’t necessary and can be a blank file. The environment variables in the env parameter are also optional. Create the model and deploy it with the following code:
Use Neo to compile the model
Next, we can compile the model using Neo. The resulting compiled_model is also a SageMaker model and can be deployed to a SageMaker endpoint. When the compiled model is deployed, SageMaker automatically integrates the TVM runtime to interpret the compiled model. Compile the model with the following code:
Deploy the compiled model as an optimized predictor with the following code:
Make predictions using the endpoints
Finally, we can compare the performance between the uncompiled and compiled models. We run 1,000 sequential iterations and calculate the round trip latency for each endpoint request:
Performance comparison
The following graph shows the measured latency speedup of the compiled model compared with a uncompiled model on the same instance. The default SageMaker PyTorch container uses Intel one-DNN libraries for inference acceleration, so any speedup from Neo is on top of what’s provided by Intel libraries. Speedup is specific to the model and instance type, so the performance gain achieved with Neo varies based on your model architecture and target instance type.
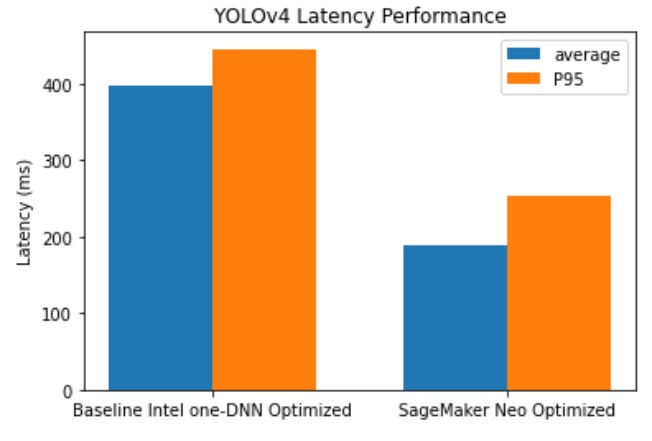
On the ml.c5.9xlarge instance, we see an average latency of 397 milliseconds for the baseline endpoint and 188 milliseconds for the Neo optimized endpoint. Similarly, for the tail latency (95th percentile), we see 446 milliseconds for the baseline endpoint and 254 milliseconds for the Neo optimized endpoint. Optimizing the model with Neo resulted in twice as fast performance.
Speedup across common models and frameworks
As you saw in the preceding section, using Neo for model compilation provides a speedup over an uncompiled model using Intel one-DNN libraries alone. The following table lists latency speedups that you might see from a few other common models across frameworks in CPU and GPU instances.
| Task | Framework | Model | Target | SageMaker Speedup |
| Image Classification | TensorFlow | mobilenetv2 | GPU | 200% |
| Image Classification | TensorFlow | resnet50 | CPU | 286% |
| Image Classification | PyTorch | resnet152 | CPU | 33% |
| Semantic Segmentation | TensorFlow | u-net | CPU | 22% |
These numbers are only benchmarks and vary for your specific model, instance type, and payload. The numbers in the table are measured end to end on SageMaker. Other optimizations such as pruning and quantization are also worth looking into as part of your overall model optimization strategy.
Summary
In this post, we deployed a PyTorch YOLOv4 model on a SageMaker ML CPU-based instance and compared performance between an uncompiled model and a model compiled with Neo. We saw a performance increase in the Neo compiled model—twice as fast compared to an uncompiled model on the same SageMaker ML instance.
We continue to improve Neo’s operator coverage and performance across different frameworks and models. If you have any questions or comments, use the Amazon SageMaker Discussion Forums or send an email to amazon-ei-feedback@amazon.com.
About the Author
 Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
Santosh Bhavani is a Senior Technical Product Manager with the Amazon SageMaker Elastic Inference team. He focuses on helping SageMaker customers accelerate model inference and deployment. In his spare time, he enjoys traveling, playing tennis, and drinking lots of Pu’er tea.
 Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.