Amazon Web Services ブログ
AI を具現化するブログ: パート1 AWS Batch でロボット学習を開始する
本記事は 2025/12/02 に公開された “Embodied AI Blog Series, Part 1: Getting Started with Robot Learning on AWS Batch | AWS Spatial Computing Blog” を翻訳したものです。
私たちは技術的進化の転換点を迎えました:高度な AI モデルを使用して、デジタル世界だけでなく物理的な世界にも影響を与える能力です。AI は、テキストを生成する AI から、原子を動かす AI へと移行しつつあります。衣服を折りたたみ、物流を整理し、複雑な物理的タスクを通じて推論を行うことで、日常生活を拡張しつつあります。しかし、非構造的で動的な物理世界と相互作用する技術をうまく統合するには、それを実現するコードだけでなく、再現性、大規模性、そして緻密な研究が必要です。
解決策はロボット学習の中にあります:古典的なモデルベースの制御から、データ駆動型のパラダイムへの移行により、自律システムに前例のない能力が解き放たれます。これは多層にわたるライフサイクルで、物理およびシミュレートされたハードウェア統合、統合された遠隔操作と制御、データセットの収集と拡張、ポリシーのトレーニングと評価、そして推論の最適化が含まれます。

図は人間のオペレーターとロボットが TWIST2 の遠隔操作インターフェースを通じて首の動きを同調させ、ハードウェアの統合、制御、データ収集を行うプロセスを示しています
過去 2 年間で、ロボット学習コミュニティは転換点を迎えました。Diffusion Policy や Action Chunking Transformers(ACT)のような模倣学習フレームワークは、実演データから操作タスクを学習するのに効果的であることが証明されました。一方、π0(Pi Zero)、NVIDIA Isaac GR00T、Molmo-Act などの汎用的なビジョン・言語・アクション(VLA)モデルは、視覚と自然言語理解を組み合わせて、様々なタスクや実装を超えた汎化を提供しています。こうした方法論的な飛躍と共に、NVIDIA Cosmos Predict のようなワールドモデリングアプローチは、ロボットが行動する前に将来の状態をシミュレートし予測することを可能にし、HIL-SERL のような強化学習方法 (Reinforced Learning, RL) は、人間のフィードバックと RL を組み合わせて、現在の状態に基づいてサンプル効率の高い学習やタスク報酬モデルを実現します。重要なことに、Hugging Face の LeRobot のようなオープンソースプロジェクトは、このスタックを民主化し、開発に貢献するために必要な標準化されたデータセット、トレーニングパイプライン、評価ベンチマークを提供しています。
NVIDIA Isaac GR00T は、ロボット学習のための汎用基盤モデルとして際立っています。オープンソースであり、開発者は独自のデータで事前トレーニングまたはファインチューニングすることができます。特に、GR00T N1.5 3B は、実世界のデモンストレーション、Isaac Lab からの合成データ、インターネット規模のビデオからなる広大な「データピラミッド」でトレーニングされました。様々なタスクと実装を超えた強力な汎化能力を提供します。GR00T N1.5 をファインチューニングすることで、事前トレーニングされた知識を活用して、大幅に少ない実演回数で高いパフォーマンスを達成できます。トレーニング時間を数ヶ月から数時間に短縮しつつ、エッジまたはクラウドのいずれかにデプロイする柔軟性を維持します。事前トレーニングされた GR00T ベースのモデルの商用利用については、NVIDIA の最新のライセンス要件を参照してください。

シミュレーションされた SO-ARM101 を用いて 60 未満の実演データでファインチューニングされた GR00T N1.5 モデルが、leisaac キッチンシーンで視覚によるガイドを元に操作を行い、スムーズな動きとフォールトトレランス性を備え、ボウルの位置を正確に把握してオレンジを配置します
このブログシリーズのパート 1 では、AWS 上で Isaac GR00T N1.5 3B を簡単にファインチューニングするためのスケーラブルなインフラストラクチャを構築する方法を示します。クラウドの弾力性と NVIDIA の先進的なロボット学習スタックを組み合わせることで、開発サイクルを加速し、ポリシーを迅速に反復し、大規模なデータセットを管理し、高忠実度シミュレーションでパフォーマンスを検証することができます。
ソリューションの概要
以下のアーキテクチャ図は、デプロイする内容を示しています。これは、セキュアな Amazon VPC 内のスケーラブルなエンドツーエンド VLA ファインチューニングパイプラインです。ワークフローは、Amazon S3、HuggingFace、またはローカルストレージに保存された生データセットとベースモデルから始まります。一貫性を確保するために、AWS CodeBuild はトレーニング環境をコンパイルし、NVIDIA Isaac GR00T の依存関係を Docker イメージにカプセル化し、Amazon ECR に保存します。
ファインチューニングジョブが送信されると、AWS Batch は、コスト効率の高い Amazon EC2 インスタンスを GPU で動的にプロビジョニングし、コンテナをプルしてトレーニングワークロードを実行します。これらのインスタンスは、モデルのチェックポイントとログをリアルタイムで保持するために、共有の Amazon Elastic File System (Amazon EFS) ボリュームをマウントします。
トレーニングと並行して、Amazon DCV 対応の EC2 インスタンスがシミュレーションと評価のために NVIDIA Isaac Lab を実行します。同じ EFS ボリュームをマウントすることで、このインスタンスはトレーニングメトリクス(TensorBoard 経由)をすぐに可視化し、最新のチェックポイントを使用したポリシー評価を可能にし、シームレスなフィードバックループを作り出します。
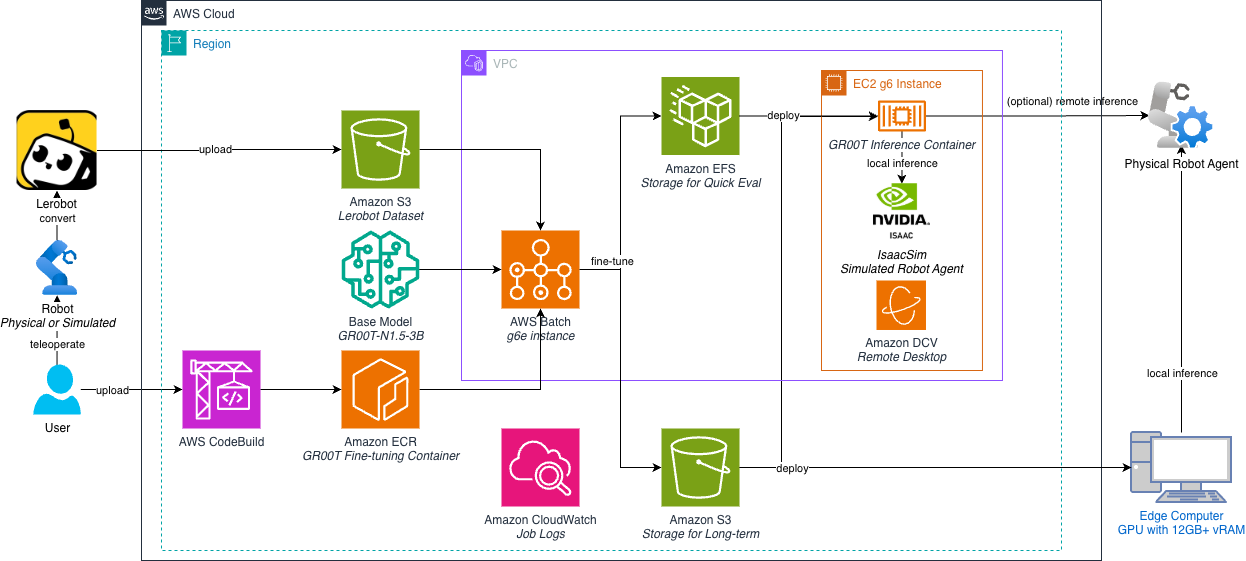
このファインチューニングパイプラインをデプロイし、シミュレーションでファインチューニングされたポリシーをトレーニングおよび評価する手順を見ていきましょう。
前提条件
この投稿では、AWS CDK(AWS Cloud Development Kit、使い慣れたプログラミング言語を使用してクラウドインフラストラクチャを定義するためのフレームワーク)を使用して AWS Batch リソースをデプロイします。
- AWS CDK をインストールする
npm install -g aws-cdk - リポジトリをクローンする
git clone https://github.com/aws-samples/sample-embodied-ai-platform.gitcd sample-embodied-ai-platform - CDK アプリの Python 依存関係をインストールする:
cd training/gr00t/infra pip install -r requirements.txt - CDK をブートストラップする(このアカウント/リージョンですでに行った場合はスキップ可能)
注:
YOUR_AWS_PROFILEとYOUR_AWS_REGIONをあなたの認証プロファイルとターゲットリージョンに置き換えてください。cdk bootstrap --profile YOUR_AWS_PROFILE --region YOUR_AWS_REGION
1. 模倣学習のための Lerobot データセットを確認する
シミュレートされた SO-ARM101 をリモート操作し、オレンジを拾い上げて皿に置くというデータセットがリポジトリに提供されています。Git LFS を使用して提供されているシミュレーションデータセットをダウンロードして確認できます。
Git LFS をインストールするには、このウェブサイトの説明をご覧ください。
git lfs pull
サンプルデータセットはtraining/sample_datasetディレクトリで利用可能になります。
あるいは、別の Lerobot 互換データセットがある場合は、Lerobot データセットビジュアライザで確認できます。カスタムエンボディメントの場合は、metaフォルダにmodality.jsonファイルがあることを確認してください。カスタムエンボディメントの要件の詳細については、Isaac GR00T ファインチューニングドキュメントを参照してください。
提供された トレーニングスクリプトでは、データセットに
modality.jsonファイルが欠けている場合、SO-ARM with dual-camera セットアップが自動的に適用されます。
2. ファインチューニングパイプラインのセットアップ
デフォルトでは、以下の手順ではファインチューニングに us-west-2 リージョンを使用しますが、G6e、P4d または P5 インスタンスファミリーをサポートするリージョンであればどれでも使用可能です。
このセクションでは、AWS Batch on EC2 を使用して GR00T をファインチューニングするための再利用可能なパイプラインを作成します。これにより、新しいデータセットやモデルでの将来のファインチューニング実行は、異なる環境変数で新しいジョブを送信するだけで済みます。
一回のトレーニングジョブは Jupyter ノートブック(例:Amazon SageMaker CodeEditor/JupyterLab を使用し、Hugging Face Lerobot × NVIDIA ガイドに従う)で簡単に開始できます。しかし、機械学習エンジニアリングチームは、データセットやモデルの頻繁な更新により、信頼性、再現性、コスト効率に優れたパイプラインを要求することがよくあります。物理的な AI モデルのトレーニングには、通常、マルチコンテナセットアップによるシミュレーションが含まれます。AWS Batch は、これを安全かつスケーラブルに実行できます。
g6e.2xlarge(またはそれ以上の)インスタンスを起動するのに十分なクォータがあることを確認してください。選択したリージョン(例:us-west-2)で、AWS Service Quotas コンソール経由でより多くのコンピュートリソースをリクエストできます(「オンデマンド G および VT インスタンスの実行」には少なくとも 8 vCPU を推奨します)。
AWS CDK スタックのデプロイ
AWS CDK スタックがリポジトリで提供されており、ファインチューニングパイプラインをすぐに開始するのに役立ちます。スタックは、以下の表にリストされているファインチューニングパイプラインに必要なリソースを自動的に作成します:
| リソース | 名前 | 目的 |
|---|---|---|
| VPC | BatchVPC |
パブリック/プライベートサブネットとNATゲートウェイを備えた分離された仮想ネットワーク |
| Security Group | BatchEFSSecurityGroup |
BatchインスタンスとEFS間のNFSトラフィックを許可するセキュリティグループ |
| Elastic File System | BatchEFS |
モデルチェックポイントとトレーニングログ用の共有ストレージ |
| (Optional) S3 Bucket | IsaacGr00tCheckpointBucket |
ファインチューニングモデルのチェックポイントを保管するためのS3バケット |
| (Optional) CodeBuild | Gr00tContainerBuild |
ファインチューニングされた Docker イメージを構築して ECR にプッシュするための AWS CodeBuild プロジェクト |
| Elastic Container Registry | gr00t-finetune |
Docker イメージをファインチューニングするためのコンテナレジストリ |
| EC2 Launch Template | BatchLaunchTemplate |
大きなコンテナイメージを実行するためのルートボリュームを増やした EC2 構成 |
| Batch Compute Environment | IsaacGr00tComputeEnvironment |
GPUインスタンス用のAWSバッチコンピューティング環境 |
| Batch Job Queue | IsaacGr00tJobQueue |
ファインチューニングジョブの送信と管理のための AWS Batch ジョブキュー |
| Batch Job Definition | IsaacGr00tJobDefinition |
コンテナ仕様の AWS Batch ジョブ定義テンプレート |
| EC2 Instance | DcvInstance |
ファインチューニングされたポリシーのシミュレーションと評価結果をAmazon DCV で可視化するための EC2 インスタンス |
スタックをデプロイするには、以下のコマンドを実行します。AWS プロファイル/IAM ロールがリソースの作成を許可していることを確認してください:
# リポジトリのルートディレクトリから
cd training/gr00t/infra
cdk deploy IsaacGr00tBatchStack IsaacLabDcvStack --profile YOUR_AWS_PROFILE --region YOUR_AWS_REGIONデフォルトでは、Batch スタックはinfraフォルダをパッケージ化して AWS CodeBuild にアップロードし、Dockerfile からコンテナイメージをビルドして Amazon ECR にプッシュします。これには通常 10〜20 分かかります。既存のコンテナイメージを使用したい場合は、スタックをデプロイする際に環境変数としてカスタムの ECR イメージ URI を指定して、CodeBuild のプロセスをスキップできます:
ECR_IMAGE_URI=<ECR_IMAGE_URI> cdk deploy IsaacGr00tBatchStack IsaacLabDcvStack
その他のデプロイメントパス
環境と好みに応じて、インフラストラクチャを設定するための複数のパスが利用可能です。このブログでは、AWS CDK を使用してローカルマシンからすべてを自動的にデプロイします。このパスは、迅速なセットアップやプログラムによるカスタマイズを可能にするために選択されています。AWS Batch リソースの設定をよりよく理解し、AWS コンソールのナビゲーションに慣れるために、AWS コンソールを介してすべてのリソースを段階的に作成したい場合は、コンソールウォークスルーパスに従うことができます。
3. ファインチューニングジョブの送信と監視
AWS Batch リソースが整えば、ファインチューニングジョブを繰り返し実行できます。新しいデータセット(例:新しいエンボディメントやタスク用)を収集/追加するたびに、ジョブ環境変数を更新し、ジョブキューに新しいジョブを送信するだけです。AWS Batch は必要に応じて自動的にコンピュートリソースを開始および停止します。
ジョブを送信するには、AWS Batch コンソールまたは AWS CLI を使用できます。
- オプション A – AWS Batch コンソール: 左側のナビゲーションペインでジョブを選択し、右上にある新しいジョブの送信を選択します。名前に
IsaacGr00tFinetuningと入力し、ジョブ定義でIsaacGr00tJobDefinitionを選択し、ジョブキューでIsaacGr00tJobQueueを選択して次へを選択します。残りはデフォルトのままにして、もう一度次へを選択し、ジョブの送信を選択します。
デフォルトでは、ジョブはリポジトリで提供されているサンプルデータセットで GR00T をファインチューニングします。特定のデータセットでファインチューニングしたい場合は、コンテナオーバーライドの下にある環境変数を更新できます。例えば、
HF_DATASET_IDを設定して、カスタムの Lerobot データセットでファインチューニングすることができます。設定可能な環境変数のリストについては、サンプルの環境変数ファイルを参照してください。 - オプション B – AWS CLI: AWS CLI がインストールされ、正しいプロファイルとリージョンで設定されていることを確認します。次に、次のコマンドを実行してジョブを送信します:
aws batch submit-job \ --job-name "IsaacGr00tFinetuning" \ --job-queue "IsaacGr00tJobQueue" \ --job-definition "IsaacGr00tJobDefinition" \ --container-overrides "environment=[{name=HF_DATASET_ID,value=<YOUR_HF_DATASET_ID>}]"オプションで、リージョンを
--region <REGION>、プロファイルを--profile YOUR_AWS_PROFILE、環境変数を--container-overrides "environment=[{name=HF_DATASET_ID,value=<YOUR_HF_DATASET_ID>}]"でオーバーライドするために次のものを追加できます。
デフォルトでは、ジョブは GR00T を 6000 ステップでファインチューニングし、2000 ステップごとにモデルのチェックポイントを保存します。これは通常、g6e.4xlarge インスタンスで最大 2 時間かかります。ジョブを送信する際に
MAX_STEPSとSAVE_STEPS環境変数をオーバーライドすることで、ステップ数と保存頻度を変更できます。モデルをより速くファインチューニングしたい場合は、GPU - optionalフィールドをオーバーライドし、NUM_GPUS環境変数を追加して使用したい GPU の数を指定することで、ジョブに追加の GPU を要求できます。詳細については、GR00T コンポーネントドキュメントを参照してください。
ジョブの進行状況を監視する
コンソールまたは CLI を使用して、ステータスを追跡し、ログをストリーム配信できます。
-
- オプション A – AWS Batch コンソール
- ジョブに移動し、
IsaacGr00tJobQueueジョブキューを選択して検索を選択します。送信したジョブとそのステータスがリストに表示されるはずです。 - 送信したジョブをクリックしてLoggingタブを選択します。ログがリアルタイムで表示されるはずです。
- ジョブに移動し、
- オプション B – AWS CLI
JOB_ID(上記のbatch submit-job出力から)を提供し、オプションでREGIONとPROFILEを設定して次のコマンドを実行します。ジョブのステータスを確認します:REGION=<REGION> PROFILE=<PROFILE> JOB_ID=<JOB_ID>; aws batch describe-jobs --jobs "$JOB_ID" \ --query 'jobs[0].{status:status,statusReason:statusReason,createdAt:createdAt,startedAt:startedAt,stoppedAt:stoppedAt}' \ --output table --region "$REGION" --profile "$PROFILE"ジョブが RUNNING ステータスになると、リアルタイムでログをストリーム配信できます:
REGION=<REGION> PROFILE=<PROFILE> JOB_ID=<JOB_ID>; aws logs tail /aws/batch/job \ --log-stream-names "$(aws batch describe-jobs --jobs "$JOB_ID" --query 'jobs[0].container.logStreamName' --output text --region "$REGION" --profile "$PROFILE")" \ --follow --region "$REGION" --profile "$PROFILE"
注:ジョブが実行中の場合、セクション 4 で説明する評価環境を使用して、トレーニングの進行状況を監視し、メトリクスをリアルタイムで可視化することもできます。これにより、ファインチューニングプロセス全体が完了するのを待つ代わりに、トレーニングパフォーマンスを追跡し、チェックポイントが利用可能になったときにチェックポイントを検査できます。
4. ファインチューニングされたポリシーを評価する
トレーニングプロセスを監視し、シミュレートされた SO-ARM101 とオプションで物理的な SO-ARM101 を使用してファインチューニングされたポリシーを評価できます。また、トレーニングの進行に合わせてテンソルボードログを視覚化することもできます。
チェックポイントが利用可能になると、
DcvInstanceで GR00T ポリシーサーバーを起動し、IsaacLab を起動して、シミュレートされた環境でファインチューニングされたポリシーを視覚化および評価できるようになります。セクション 2 で CDK スタックをデプロイした際、Amazon DCV EC2 インスタンスは初期化と ユーザーデータスクリプト の実行に数分かかります。インスタンスにログインしたら、ターミナルで
sudo cat /var/log/dcv-bootstrap.summaryを実行してステータスを確認できます。19 個のSTEP_OKと最後のSTEP_OK:EFS mountが表示されれば、インスタンスは準備完了です。このスタックは、Batch スタックに接続された同じ EFS を/mnt/efsにマウントするため、ジョブの実行中に TensorBoard のログとモデルのチェックポイントをライブで確認できます。- DCV インスタンスにログインし、TensorBoard を可視化してチェックポイントを検査します
IsaacLabDcvStackのデプロイ出力(CLI または CloudFormation コンソール)をチェックして、DCV インスタンスのパブリック IP アドレス(DCVWebURL)と認証情報(DCVCredentials)を取得し、その IP アドレスにアクセスして DCV セッションにログインします。
注:ブラウザで「Your connection is not private」という警告が表示される場合があります。無視して次のステップに進むか、DCV Client を使用してインスタンスに接続してください。DCV インターフェースが読み込まれても「no session found」というエラーが表示される場合は、10 分後に再試行してください。トラブルシューティングとカスタマイズオプションについては、ユーザーデータスクリプト を参照してください。
ログイン後、
Ctrl + Alt + T(または macOS の場合はControl + Option + T)を使用してターミナルを開くと、/mnt/efs/gr00t/checkpoints/runsディレクトリに tensorboard ログがあるはずです。ls -l /mnt/efs/gr00t/checkpoints/runs次のコマンドを実行して tensorboard サーバーを起動します:
# If the conda environment is not activated, run: conda activate isaac tensorboard --logdir /mnt/efs/gr00t/checkpoints/runs --bind_alltensorboard サーバーはポート 6006 で実行されるはずです。DCV インスタンス内で自動生成された URL を「Ctrl + クリック」するか、任意のクライアント(例:ローカルラップトップのブラウザ)で
DcvInstanceのパブリック IP アドレス(例:http://<DCV_INSTANCE_PUBLIC_IP>:6006)を使用してアクセスできます。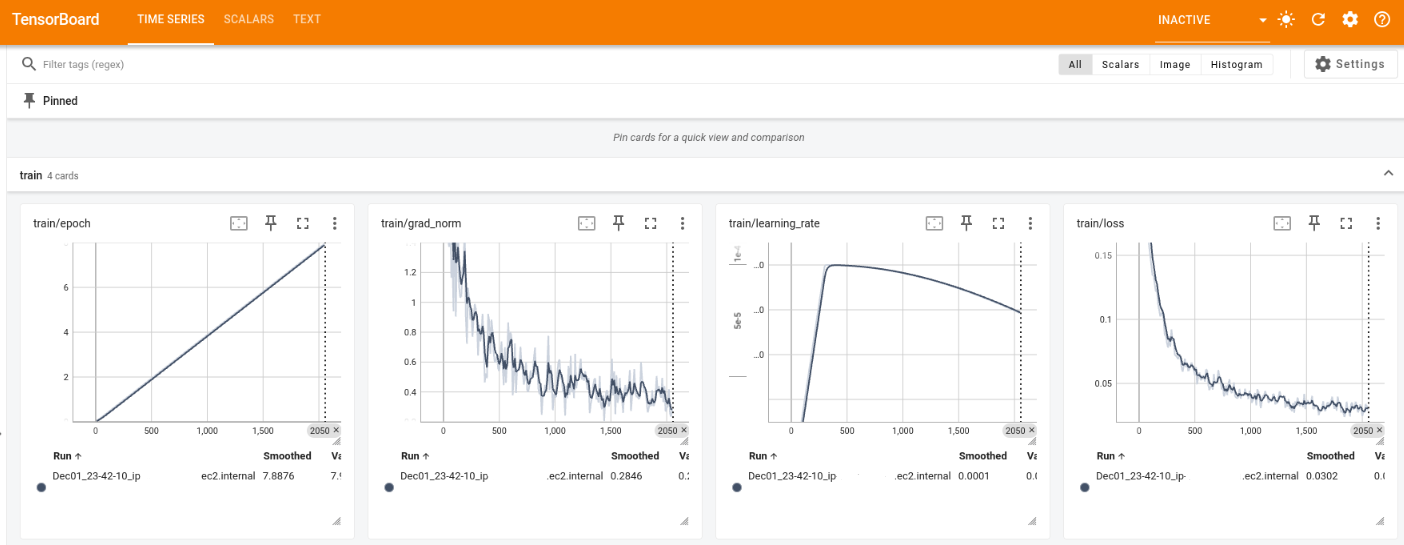
GR00T のファインチューニングの進捗状況をリアルタイムで視覚化し、4 つの主要なトレーニングメトリクスを示しています:エポックの進行(左)、勾配ノルムの安定化(中央左)、学習率スケジュール(中央右)、および損失の収束(右)。
ファインチューニングジョブが完了したら、
/mnt/efs/gr00t/checkpointsディレクトリでモデルのチェックポイントを確認できます。 - Isaac GR00T コンテナを実行し、ポリシーサーバーを起動します Amazon Elastic Container Registry コンソールに移動し、
gr00t-finetuneコンテナリポジトリを選択します。右上の View push commands をクリックして、ECR に認証するための最初のコマンドを表示します。コマンドは次のようになります:aws ecr get-login-password --region <REGION> | docker login --username AWS --password-stdin <ECR_PREFIX><ECR_IMAGE_URI>を取得するには、最新のイメージタグの URI(例:1234567890.dkr.ecr.us-west-2.amazonaws.com/gr00t-finetune:latest)をコピーし、次のコマンドを実行してイメージをプルし、EFS を読み取り専用としてマウントした状態でインタラクティブシェルを開始します:docker run -it --rm --gpus all --network host -v /mnt/efs:/mnt/efs:ro --entrypoint /bin/bash <ECR_IMAGE_URI>コンテナ内で、
<STEP>(例:6000)によってチェックポイントを選択し、サーバーを起動します:MODEL_STEP=<STEP> # e.g. 6000 MODEL_DIR="/mnt/efs/gr00t/checkpoints/checkpoint-$MODEL_STEP" python scripts/inference_service.py --server \ --model_path "$MODEL_DIR" \ --embodiment_tag new_embodiment \ --data_config so100_dualcam \ --denoising_steps 4サーバーが準備完了になると、次の出力が表示されます:
Server is ready and listening on tcp://0.0.0.0:5555 - leisaac キッチンシーンオレンジピッキングタスクを実行します。DCV インスタンスで新しいターミナルを開き、次のスクリプトを実行して leisaac キッチンシーンのオレンジピッキングタスクを起動します。これにより、シミュレートされた SO-ARM101 がコンテナで実行中の GR00T ポリシーサーバーに接続されます:
# If the conda environment is not activated, run: conda activate isaac cd /home/ubuntu/leisaac OMNI_KIT_ACCEPT_EULA=YES python scripts/evaluation/policy_inference.py \ --task=LeIsaac-SO101-PickOrange-v0 \ --policy_type=gr00tn1.5 \ --policy_host=localhost \ --policy_port=5555 \ --policy_timeout_ms=5000 \ --policy_action_horizon=16 \ --policy_language_instruction="Pick up an orange and place it on the plate" \ --device=cuda \ --enable_camerasIsaacSim は初回の初期化に数分かかる場合があります。
このスクリプトを実行する前に、コンテナ内で推論サーバーが実行されていることを確認してください。シーンがロードされ、ターミナルに
[INFO]: Completed setting up the environment...と表示されるまでに 3 ~ 5 分かかる場合があります。これはシーンがプレイする準備ができていることを示します。黄色の[Warning]メッセージと赤色の[Error]メッセージは無視してください。シーンがロードされると、シミュレートされた SO-ARM101 がオレンジを拾って皿に置くのが見えるはずです。IsaacSim アプリケーションウィンドウを選択してrキーを押すとシーンをリセットしてランダム化できます。または、ターミナルでCtrl+Cを押してシミュレーションを停止できます。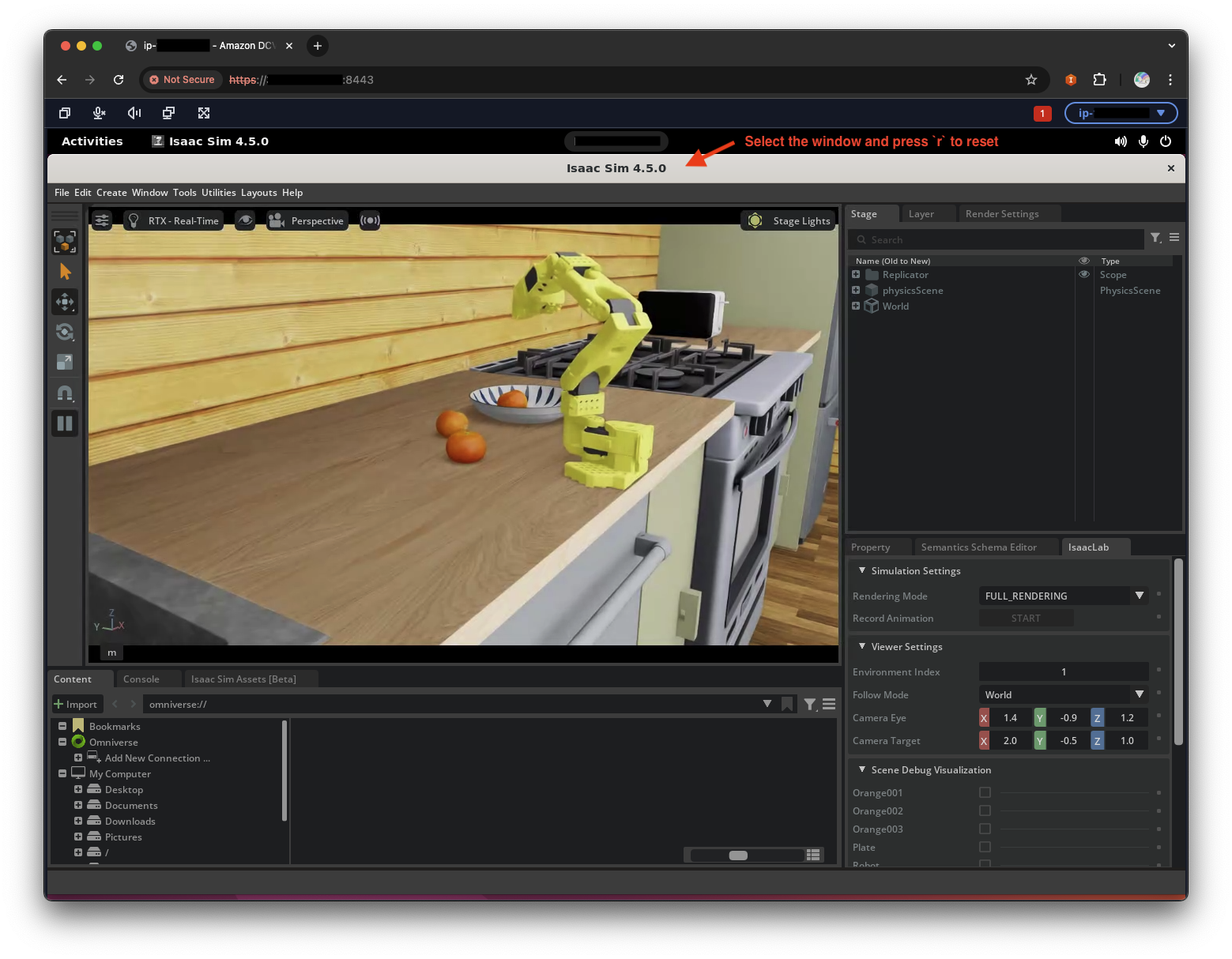
おめでとうございます!GR00T のファインチューニングが成功し、シミュレーションでファインチューニングされたポリシーを評価しました。手首と前面カメラを備えた物理的な SO-ARM101 をお持ちの場合は、ローカルのクライアントをリモートの GR00T ポリシーサーバーに接続することで、ローカルの物理的な SO-ARM101 でポリシーを評価することもできます。以下の手順に進んでください:
- デュアルカメラを備えた SO-ARM101 を組み立て、Lerobot ガイド に従ってキャリブレーションします
- Isaac GR00T 公式ガイドに従ってローカルマシンに依存関係をインストールし、Isaac GR00T サンプルクライアントを実行して物理的な SO-ARM101 を制御します
ローカルの GPU マシンもお持ちの場合は、GR00T ポリシーサーバーとサンプルクライアントの両方をローカルで実行できます。Isaac-GR00T ガイドで詳細をご確認ください。
クリーンアップ
継続的な課金を避けるため、
cdk destroyコマンドで作成したリソースを削除してください。# リポジトリのルートから cd training/gr00t/infra # まず DCV スタックを破棄します(EC2 インスタンスを終了し、EIP を解放します) cdk destroy IsaacLabDcvStack --force # Batch スタックを破棄します(Batch リソース、EFS、VPC を削除します。CDK によって作成された場合) cdk destroy IsaacGr00tBatchStack --forceまとめ
この投稿では、AWS Batch、Amazon ECR、および Amazon EFS を使用し、Amazon DCV によって強化された対話型評価環境と組み合わせて、AWS 上にケーラブルで再現可能なロボット学習パイプラインを構築しました。インフラストラクチャのプロビジョニングとコンテナ管理を自動化することで、最も重要なこと、つまり複雑な物理的タスクを解決するためのデータセットとポリシーの反復に集中できます。
このアーキテクチャは、ロボット学習ワークフローをスケーリングするための堅固な基盤を提供します。NVIDIA Isaac GR00T のような基盤モデルをファインチューニングする場合でも、LeRobot のようなオープンソースフレームワークを使用してゼロからポリシーをトレーニングする場合でも、弾力性のあるコンピューティングと共有ストレージの組み合わせにより、トレーニングとシミュレーション間のシームレスなフィードバックループを可能にする迅速な実験が可能になります。
有用な参考資料
- Robotics Fundamentals Learning Path | NVIDIA
- Robot Learning: A Tutorial – a Hugging Face Space by lerobot
- Enhance Robot Learning with Synthetic Trajectory Data Generated by World Foundation Models | NVIDIA Technical Blog
- NVIDIA Isaac GR00T in LeRobot
- Amazon FAR – TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System
- LightwheelAI/leisaac: LeIsaac は SO101Leader (LeRobot) を用いて、IsaaCLab に遠隔操作の能力を提供します。データの収集、変換、ポリシーの学習が含まれています。
- オプション A – AWS Batch コンソール
翻訳はソリューションアーキテクトの山本が実施しました。