Amazon Web Services ブログ
Javaの階層型コンパイルによるAWS Lambda 関数のパフォーマンス向上
Operating Lambda: パフォーマンスの最適化 シリーズでは、AWS Lambda関数を使ってアプリケーションを管理している開発者、アーキテクト、システム管理者にとって重要なトピックを取り上げています。この記事では、Javaで管理するランタイムを使用する際に、新しくLambdaの実行環境を開始する場合に発生する初期化時間(コールドスタート)を短縮する方法について説明します。

多くのLambdaワークロードは、同期または非同期のワークロードに対して高速なレスポンスを瞬時に返すように設計されています。例えば、Webサイトに動的コンテンツを配信するパブリックAPIや、小規模なバッチ処理を行うニアリアルタイムのデータパイプラインなどが挙げられます。
これらのシステムの利用が増えると、Lambdaは新しい実行環境を作成します。新しい環境が作られて初めて使われるときには、イベントを処理できるようにするための初期化処理が行われます。これにより、初期化処理があるものとないもの、2つの異なるパフォーマンスプロファイルが作成されます。
レスポンスタイムを向上させるためには、この初期化処理の影響を最小限に抑えることが重要です。新しいマネージドJava実行環境の構築にかかる時間を最小化する方法の一つとして、JVMのチューニングがあります。JVMは、実行時間が長くないワークロードに特化して最適化することができます。
その一例が、階層型コンパイルと呼ばれるJVMの機能の設定です。Java Development Kit(JDK)のバージョン8からは、2つのジャストインタイムコンパイラのC1とC2が併用されています。C1は、クライアント側で使用され、開発者が短いフィードバックループを実現するために設計されています。C2はサーバーサイドでの使用を想定しており、プロファイリング後の高いパフォーマンスを実現するために設計されています。
階層化とは、どのコンパイラを使用すればより高いパフォーマンスが得られるかを判断するためのものです。これらは5つのレベルで表されます。

プロファイリングにはオーバーヘッドがあり、パフォーマンスの向上は、メソッドが何度も呼び出された後にのみ達成されます(デフォルトは10,000回)。起動時間の短縮を実現したいLambdaのお客様は、ウォームスタートのパフォーマンスが低下するリスクが少ないレベル1を使用することができます。階層型コンパイルについては、「Startup, containers & Tiered Compilation」の記事で詳しく説明しています。
反復性の高い処理を行っているお客様には、この構成は向いていないかもしれません。同じコードパスを何度も繰り返すアプリケーションでは、JVMがこれらのパスをプロファイリングして最適化することが求められます。具体的な例としては、Lambdaを使ってモンテカルロシミュレーションやハッシュ計算を行うことが挙げられます。同じシミュレーションを何千回も実行することになりますが、JVMのプロファイリングによって総実行時間を大幅に短縮することができます。
パフォーマンスの向上
サンプルプロジェクトは、この変更の影響を分析するために使用されるJava 11ベースのアプリケーションです。このアプリケーションは、Amazon API Gatewayによってトリガされ、Amazon DynamoDBにアイテムを投入します。この変更によるパフォーマンスの違いを比較するために、追加変更のあるLambda関数とないLambda関数があります。コードに他の違いはありません。
このサンプルプロジェクトのコードは、GitHub repoからダウンロードしてください: https://github.com/aws-samples/aws-lambda-java-tiered-compilation-example
前提となるソフトウェアをインストールするには
- AWS CDKをインストールします
- Apache Mavenをインストールするか、お好みのIDEを使用します
- Javaアプリケーションをビルドして、softwareフォルダにパッケージ化します
cd software/ExampleFunction/ mvn package - 実行用ラッパースクリプトをZIP圧縮する
cd ../OptimizationLayer/ ./build-layer.sh cd ../../ - CDKを合成します。このコマンドで、AWSアカウントに変更を加える前にプレビューします
cd infrastructure cdk synth - Lambda関数をデプロイします
cdk deploy --outputs-file outputs.json
API GatewayのエンドポイントURLが出力に表示され、outputs.jsonというファイルに保存されます。内容は以下のようになっています。
InfrastructureStack.apiendpoint = https://{YOUR_UNIQUE_ID_HERE}.execute-api.eu-west-1.amazonaws.com
Artilleryを使った負荷テスト
まず、実施に必要なツールをインストールします。
- jqとArtillery Coreをインストールします
- 以下の2つのスクリプトを/infrastructureディレクトリから実行します
artillery run -t $(cat outputs.json | jq -r '.InfrastructureStack.apiendpoint') -v '{ "url": "/without" }' loadtest.yml artillery run -t $(cat outputs.json | jq -r '.InfrastructureStack.apiendpoint') -v '{ "url": "/with" }' loadtest.yml
Amazon CloudWatch Insightsを使って結果を確認
- Amazon CloudWatchへアクセスします
- Logs を選択し Logs Insights を選択します
- ドロップダウンリストから以下の2つのロググループを選択します
/aws/lambda/example-with-layer
/aws/lambda/example-without-layer - 次のクエリをコピーして、「クエリの実行」を選択します
filter @type = "REPORT" | parse @log /\d+:\/aws\/lambda\/example-(?<function>\w+)-\w+/ | stats count(*) as invocations, pct(@duration, 0) as p0, pct(@duration, 25) as p25, pct(@duration, 50) as p50, pct(@duration, 75) as p75, pct(@duration, 90) as p90, pct(@duration, 95) as p95, pct(@duration, 99) as p99, pct(@duration, 100) as p100 group by function, ispresent(@initDuration) as coldstart | sort by function, coldstart
 以下のような結果が表示されます。
以下のような結果が表示されます。
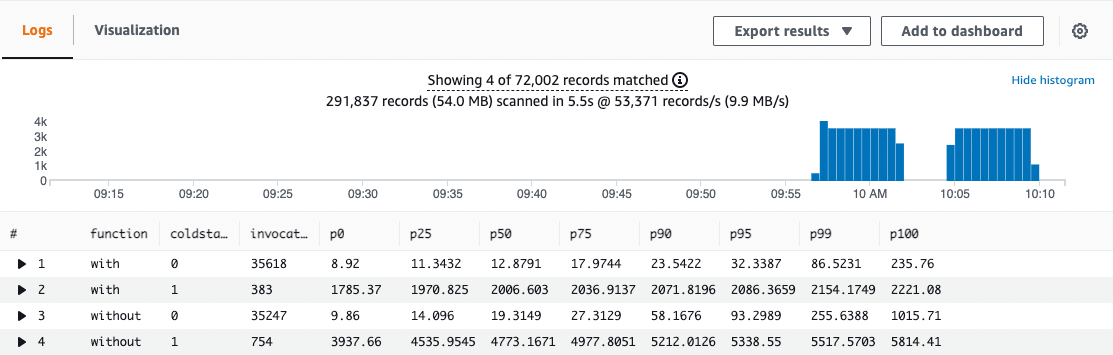
以下は、その結果を簡略化した表です。

この結果は、Artilleryと呼ばれるオープンソースソフトウェアプロジェクトを使用して、5分間に120件の同時リクエストをテストしたものです。このテストの実行方法については、GitHubのリポジトリに記載されています。その結果、このアプリケーションでは、90%の呼び出しに対するコールドスタートが3141ms(60%)改善されました。これらの数値はサンプルアプリケーションでの数値ですので、あなたのアプリケーションでは異なる結果となる可能性がある点はご注意ください。
Lambda関数のラッパースクリプトを使う
ラッパースクリプトは、Amazon Linux 2 マネージドランタイムの Java 8とJava 11 で利用できる機能です。Amazon Linux 1 マネージドランタイムのJava 8 では利用できません。
この最適化フラグをLambda関数に適用するには、ラッパースクリプトを作成し、Lambdaレイヤーのzipファイルに追加します。このスクリプトは実行環境内でJavaが起動されるJVMフラグを変更します。
#!/bin/sh
shift
export _JAVA_OPTIONS="-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
java "$@"Lambdaレイヤーを作成して共有する方法については、ドキュメントをお読みください。
コンソールでの操作
この変更は、AWS Serverless Application Model (AWS SAM)、AWS Command Line Interface (AWS CLI)、AWS CloudFormation、またはAWS Management Console内から設定することができます。
AWSマネジメントコンソールを使用します。
- AWS Lambdaのコンソールに移動します
- 関数 を選択し、レイヤーを追加するLambda関数を選択します

- デフォルトではコードタブが選択されています。レイヤーパネルまでスクロールダウンします
- レイヤーの追加を選択します

- カスタムレイヤーを選択し、レイヤーを選択します

- バージョンを選択します。追加 を選択します
- メニューから設定タブと環境変数を選択します。編集を選択します

- 環境変数の追加を選択します。以下のように追加します
– Key: AWS_LAMBDA_EXEC_WRAPPER
– Value: /opt/java-exec-wrapper

- 保存を選択します。変更が適用されたことは、関数を起動してログイベントを表示することで確認できます。「Picked up _JAVA_OPTIONS: -XX:+TieredCompilation -XX:TieredStopAtLevel=1」というログが追加されています。

まとめ
レベル1までの階層化コンパイルは、JVMがコードの最適化とプロファイリングに費やす時間を短縮します。これにより、ワークロードがプロファイリングの恩恵を受ける要件を満たしていない、高速応答を必要とするJavaアプリケーションの起動時間を短縮できる可能性があります。
GraalVMを使えば、起動時間をさらに短縮することができます。GraalVMとQuarkusフレームワークについては、アーキテクチャブログをご覧ください。https://github.com/aws-samples/aws-lambda-java-tiered-compilation-example のコード例を見て、これをLambda関数にどのように適用できるかを確認してください。
その他のサーバーレスの学習リソースについては、こちらで見つけることができます。
この記事の翻訳は Solutions Architect 岡田が担当しました。原文はこちらからご覧いただけます。