Amazon Web Services ブログ
Amazon MemoryDB for Redis の紹介 – Redis 互換で耐久性に優れたインメモリデータベースサービス
インタラクティブなアプリケーションは、リクエストを処理して迅速に対応する必要があり、この要件はアーキテクチャのすべてのコンポーネントにまで及んでいます。マイクロサービスを採用し、アーキテクチャが相互に通信する多数の小さな独立したサービスで構成されている場合、これはさらに重要です。
このため、データベースのパフォーマンスは、アプリケーションの成功に不可欠です。読み取りレイテンシーをマイクロ秒に減らすために、耐久性のあるデータベースの前にインメモリキャッシュを配置できます。キャッシュのために、多くの開発者はオープンソースのインメモリデータ構造ストアである Redis を使用しています。実際、 Stack Overflowの2021開発者調査によると、Redisは5年間最も愛されているデータベースです。
このような要件のシステムを AWS で実装するには、完全マネージド型のインメモリキャッシュサービスであるAmazon ElastiCache for Redis を、 Amazon Aurora や Amazon DynamoDB などの耐久性のあるデータベースサービスの前で低レイテンシーキャッシュとして使用して、データ損失を最小限に抑えます。ただし、この設定では、キャッシュとデータベースとの同期を維持するために、アプリケーションにカスタムコードを導入する必要があります。また、キャッシュとデータベースの両方を実行する場合にもコストが発生します。
Amazon MemoryDB for Redis の紹介
本日、Amazon MemoryDB for Redis の一般提供を発表できることを嬉しく思います。これは Redis 互換で耐久性に優れた新しいインメモリデータベースです。MemoryDB を使用すると、データの耐久性と高可用性を備えた、マイクロ秒の読み取りおよび一桁ミリ秒の書き込み性能を必要とするアプリケーションを簡単かつコスト効率に優れた方法で構築できます。
耐久性のあるデータベースの前で低レイテンシーのキャッシュを使用する代わりに、アーキテクチャを簡素化し、MemoryDB を単一のプライマリデータベースとして使用できるようになりました。MemoryDB を使用すると、すべてのデータがメモリに格納され、低レイテンシーと高スループットのデータアクセスを実現します。MemoryDB は、複数のアベイラビリティーゾーン (AZ)にまたがるデータを格納する分散 トランザクションログを使用して、高速フェイルオーバー、データベースリカバリ、およびノードの再起動を高耐久性で実現します。
MemoryDB はオープンソース Redis との互換性を維持し、使い慣れた一連の Redis データ型、パラメータ、コマンドをサポートしています。つまり、現在オープンソース Redis で既に使っているコード、アプリケーション、ドライバ、ツールを MemoryDB で使用できます。開発者は、文字列、ハッシュ、リスト、セット、範囲クエリを含むソートセット、ビットマップ、ハイパーログログ、地理空間インデックス、ストリームなどの多くのデータ構造にすぐにアクセスできます。また、組み込みレプリケーション、LRU(Least Recently Used)エヴィクション、トランザクション、自動パーティショニングなどの高度な機能も利用できます。MemoryDB は Redis 6.2 と互換性があり、オープンソースでリリースされた新しいバージョンをサポートします。
この時点での疑問の1つは、両方のサービスが Redis データ構造と API にアクセスできるため、MemoryDB が ElastiCache とどのように比較されるかでしょう。
MemoryDB は、データの耐久性とマイクロ秒の読み取り、および一桁ミリ秒の書き込みレイテンシーを提供するため、アプリケーションのプライマリデータベースとして安全に利用できます。MemoryDB を使用すると、インタラクティブなアプリケーションやマイクロサービスアーキテクチャに必要な低レイテンシーを実現するために、データベースの前にキャッシュを追加する必要はありません。
一方、ElastiCache は読み取りと書き込みの両方にマイクロ秒のレイテンシーを提供します。これは、既存のデータベースからのデータアクセスを高速化するワークロードのキャッシュに最適です。ElastiCache は、データ損失が許容される可能性があるユースケース (たとえば、別のソースからデータベースをすばやく再構築できるなど) のプライマリデータストアとしても使用できます。
Amazon MemoryDB クラスターの作成
MemoryDB コンソールで、左側のナビゲーションペインのリンクに従ってクラスタ セクションに移動し、クラスターの作成 を選択します。これにより、クラスターの設定が開き、クラスターの名前と説明を入力します。

すべての MemoryDB クラスターは、virtual private cloud (VPC) で実行されます。サブネットグループでは、VPC の 1 つを選択し、クラスターがノードの配布に使用するサブネットのリストを指定して、サブネットグループを作成します。

クラスター設定では、ネットワークポート、ノードとクラスターのランタイムプロパティを制御するパラメータグループ、ノードタイプ、シャードの数、シャードあたりのレプリカの数を変更できます。クラスターに格納されているデータは、シャード間で分割されます。シャードの数とシャードあたりのレプリカ数によって、クラスタ内のノード数が決まります。各シャードにプライマリノードとレプリカがあることを考慮すると、このクラスタには8つのノードがあることが予想されます。
Redis のバージョン互換性のために、6.2 を選択します。その他のオプションはすべてデフォルトのままにして、次へを選択します。

詳細設定 の セキュリティセクションで、サブネットグループに使用した VPC のdefaultのセキュリティグループを追加し、以前に作成したアクセスコントロールリスト (ACL) を選択します。MemoryDB ACL は Redis ACL に基づいており、クラスターに接続するためのユーザー資格情報とアクセス許可を提供します。
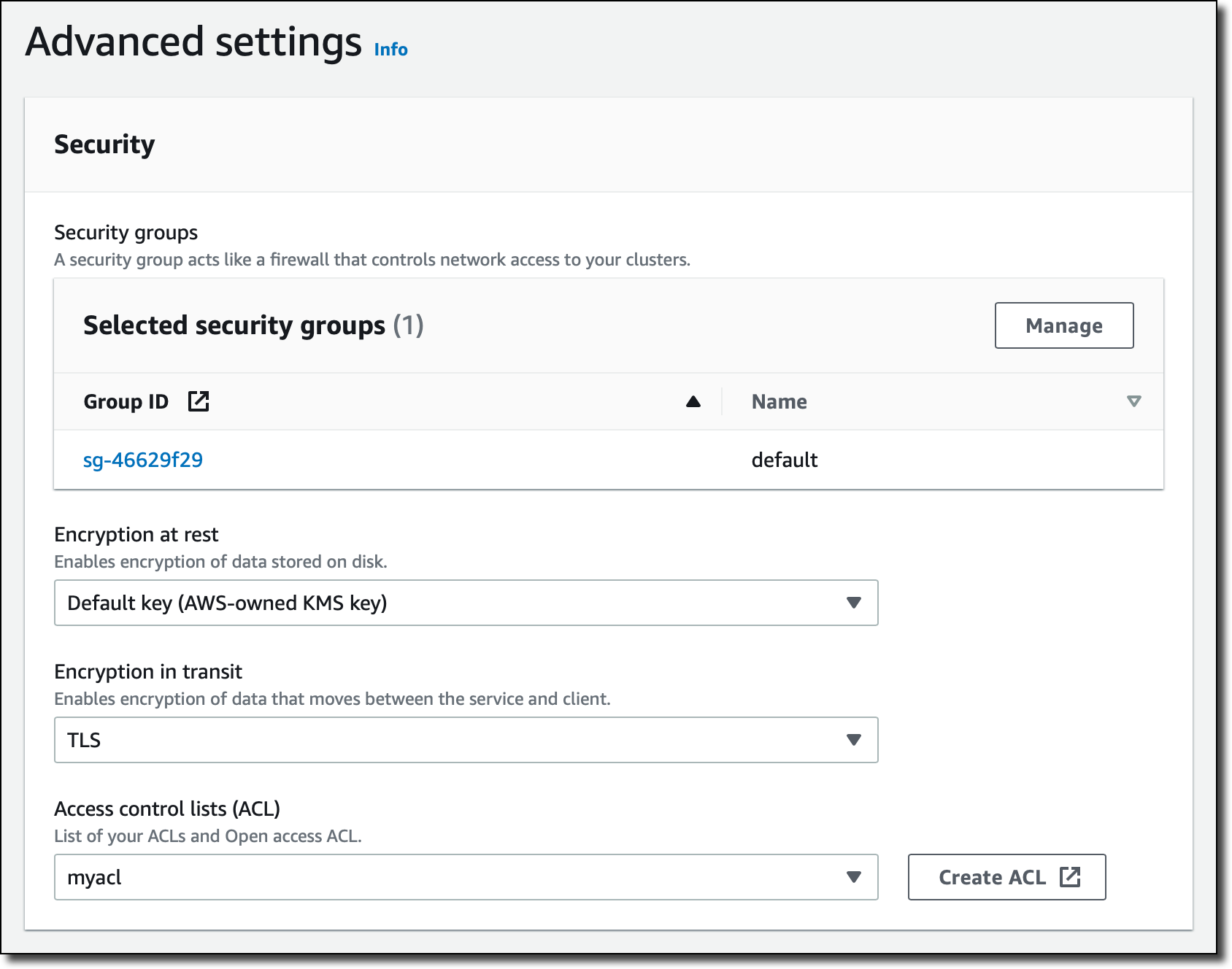
スナップショットセクションでは、MemoryDB で毎日スナップショットが自動的に作成され、7 日間の保存期間を選択するようにデフォルトのままにします。

メンテナンスでは、デフォルトのままにして 作成 を選択します。このセクションでは、重要なクラスターイベントを通知する Amazon Simple Notification Service (SNS) トピックを提供することもできます。
数分後にクラスターが実行され、Redis コマンドラインインターフェイスまたは任意の Redis クライアントを使用して接続できます。
Amazon MemoryDB をプライマリデータベースとして使用する
顧客データの管理は、多くのビジネスプロセスの重要な要素です。新しい Amazon MemoryDB クラスターの耐久性をテストするために、MemoryDB を顧客データベースとして使用したいと思います。簡単にするために、 REST API を使用して Redis クラスターから 1 つまたはすべての顧客データを作成、更新、削除、および取得できるシンプルなマイクロサービスをPythonで構築しましょう。
server.pyの実装コードは次のとおりです。
from flask import Flask, request
from flask_restful import Resource, Api, abort
from rediscluster import RedisCluster
import logging
import os
import uuid
host = os.environ['HOST']
port = os.environ['PORT']
db_host = os.environ['DBHOST']
db_port = os.environ['DBPORT']
db_username = os.environ['DBUSERNAME']
db_password = os.environ['DBPASSWORD']
logging.basicConfig(level=logging.INFO)
redis = RedisCluster(startup_nodes=[{"host": db_host, "port": db_port}],
decode_responses=True, skip_full_coverage_check=True,
ssl=True, username=db_username, password=db_password)
if redis.ping():
logging.info("Connected to Redis")
app = Flask(__name__)
api = Api(app)
class Customers(Resource):
def get(self):
key_mask = "customer:*"
customers = []
for key in redis.scan_iter(key_mask):
customer_id = key.split(':')[1]
customer = redis.hgetall(key)
customer['id'] = customer_id
customers.append(customer)
print(customer)
return customers
def post(self):
print(request.json)
customer_id = str(uuid.uuid4())
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
customer = request.json
customer['id'] = customer_id
return customer, 201
class Customers_ID(Resource):
def get(self, customer_id):
key = "customer:" + customer_id
customer = redis.hgetall(key)
print(customer)
if customer:
customer['id'] = customer_id
return customer
else:
abort(404)
def put(self, customer_id):
print(request.json)
key = "customer:" + customer_id
redis.hset(key, mapping=request.json)
return '', 204
def delete(self, customer_id):
key = "customer:" + customer_id
redis.delete(key)
return '', 204
api.add_resource(Customers, '/customers')
api.add_resource(Customers_ID, '/customers/<customer_id>')
if __name__ == '__main__':
app.run(host=host, port=port)requirements.txt ファイルで、アプリケーションが必要とする Python モジュールを一覧表示します。
同じコードは、MemoryDB、ElastiCache、または任意の Redis クラスターデータベースで動作します。
Linux Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを MemoryDB クラスターと同じ VPC で起動します。MemoryDB クラスターに接続できるようにするには、defaultのセキュリティグループを割り当てます。また、インスタンスへの SSH アクセスを許可する別のセキュリティグループを追加します。
server.py と requirements.txt ファイルをインスタンスにコピーし、依存関係をインストールします。
それでは、マイクロサービスを開始します。
別のターミナル接続では、 curl を使用して /customers リソースに HTTP POST を使用してデータベース内に顧客を作成します。
その結果、データが格納され、一意の ID (Python コードによって生成された UUIDv4) がフィールドに追加されたことを確認します。
すべてのフィールドは、 Customer:<id> として形成されたキーを持つ Redis Hash に格納されます。
前のコマンドを数回繰り返して、3 つの顧客を作成します。顧客データは同じですが、それぞれ一意の ID があります。
ここで、HTTP GET を使用して /customers リソースからすべての顧客のリストを取得します。
コードには、 SCAN コマンドを使用して一致するキーに対するイテレータがあります。レスポンスでは、3 つの顧客のデータが表示されます。
顧客の一人が残高をすべて使い切ってしまいました。ID (/customers/<id>) を含むカスタマーリソースの URL に HTTP PUT を使用してフィールドを更新します。
コードは Redis Hash のフィールドをリクエストのデータで更新しています。この場合、balanceをゼロに設定しています。ID で顧客データを取得して更新を検証します。
レスポンスでは、残高が更新されていることがわかります。
これがRedisの力です!ほんの数行のコードでマイクロサービスの骨格を作成できました。さらに、MemoryDBは、バックエンドに別のデータベースを追加する必要なく、本番環境に必要な耐久性と高可用性を実現します。
ワークロードに応じて、MemoryDB クラスターを水平方向にスケールしたり、ノードを追加または削除したり、より大きなノードタイプまたは小さいノードタイプに移行して垂直方向にスケーリングしたりできます。MemoryDB は、シャーディングによる書き込みスケーリングと、レプリカの追加による読み取りスケーリングをサポートしています。クラスタは引き続きオンライン状態になり、サイズ変更操作中に読み取りおよび書き込み操作がサポートされます。
可用性と価格
Amazon MemoryDB for Redis は現在、米国東部(バージニア北部)、欧州(アイルランド)、アジアパシフィック(ムンバイ)、南米(サンパウロ)で利用可能で、さらに多くの AWS リージョンが近日公開されます。
AWS マネジメントコンソール、AWS コマンドラインインターフェイス(CLI)、または AWS SDK を使用して MemoryDB クラスターを数分で作成できます。AWS CloudFormation のサポートが近日公開される予定です。ノードの場合、MemoryDB は現在 R6g Graviton2 インスタンスをサポートしています。
ElastiCache for Redis から MemoryDB に移行するには、ElastiCache クラスターのバックアップを取って MemoryDB クラスターに復元します。Amazon Simple Storage Service (Amazon S3) に保存されている Redis データベースバックアップ (RDB) ファイルから新しいクラスターを作成することもできます。
MemoryDB では、ノードあたりのオンデマンドインスタンス時間、クラスターに書き込まれたデータの量、およびスナップショットストレージに基づいて、使用する分に対して料金が発生します。詳細については、 MemoryDB の料金表ページを参照してください。
もっと詳しく
概要は以下のビデオをご覧ください。また、より深く掘り下げるためにはAWS公式ポッドキャストの最新エピソードをお聞きください。
今すぐプライマリデータベースとして Amazon MemoryDB for Redis の使用を開始してください。
翻訳はソリューションアーキテクトの木村が担当しました。原文はこちらをご覧ください。