Amazon Web Services ブログ
新規 – 標準取得層と S3 バッチオペレーションを使用して Amazon S3 Glacier の柔軟な復元時間を最大 85% 短縮
2022年、Amazon S3 Glacier は 10 周年を迎えました。Amazon S3 Glacier はクラウドコールドストレージのリーダーであり、私は、過去 10 年間のそのイノベーションについて書きました。
Amazon S3 Glacier ストレージクラスには、データを最小のコストで最適にアーカイブできる、長期的で安全で耐久性のあるストレージオプションが用意されています。Amazon S3 Glacier ストレージクラス (Amazon S3 Glacier Instant Retrieval、Amazon S3 Glacier Flexible Retrieval、Amazon S3 Glacier Deep Archive) は、コールドデータ専用に構築されており、ミリ秒単位から数日単位で柔軟に取得することができるほか、1 テラバイトあたり 1 か月 1 USD という低価格でアーカイブデータを保存できます。
多くのお客様から、将来的な価値が見込めることを認識しているため、データを長期間保存している、アーカイブデータのサブセットをすでに収益化している、または将来的に大量のアーカイブデータを使用する予定である、という声が寄せられています。最新のデータアーカイブは、コールドデータのストレージコストを最適化するだけではありません。データをビジネスに役立てる必要があるときに、ビジネス要件に応じて迅速にアクセスできるようにするメカニズムを設定することも重要です。
2022 年に、AWS のお客様は Amazon S3 Glacier から 320 億を超えるオブジェクトを復元しました。お客様は、メディアのトランスコーディング、運用バックアップの復元、機械学習 (ML) モデルのトレーニング、または履歴データの分析を行う際に、アーカイブされたオブジェクトを迅速に取得する必要があります。S3 Glacier Instant Retrieval をご利用のお客様は、わずか数ミリ秒でデータにアクセスできますが、S3 Glacier Flexival Retrieval は低コストで、1~5 分以内の迅速な取得、3~5 時間以内の標準的な取得、5~12時間以内の無料の一括取得という 3 つの取得オプションが用意されています。S3 Glacier Deep Archive は、当社で最も低コストのストレージクラスであり、標準取得オプションでは 12 時間以内、一括取得オプションでは 48 時間以内にデータを取得できます。
2022 年 11 月、Amazon S3 Glacier は S3 Glacier Flexible Retrieval と S3 Glacier Deep Archive で大量のアーカイブデータを取得する場合に、追加コストなしで復元スループットを最大 10 倍向上させました。Amazon S3 バッチオペレーション では、より速い速度で自動的にリクエストを開始できるため、ペタバイトのデータを含む数十億ものオブジェクトを復元できます。
10 年にわたるコールドストレージの技術革新の流れを継続するため、S3 Glacier Flexival からの標準取り出しを、追加費用なしで最大 85% 高速化することを8月9日に発表しました。S3 バッチオペレーションを使用すると、より高速なデータ復元が標準取得層に自動的に適用されます。
S3 バッチオペレーションを使用すると、取得するオブジェクトのマニフェストを提供し、取得層を指定することで、アーカイブされたデータを大規模に復元できます。S3 バッチオペレーションでは、標準取得層での復元では、通常 3~5 時間かかっていたオブジェクトが数分以内に返されるようになり、アーカイブからのデータ復元を簡単にスピードアップできます。
さらに、S3 バッチオペレーションは、ジョブに新しいパフォーマンスの最適化を適用することで、全体的な復元スループットを向上させます。その結果、データをより迅速に復元し、復元されたオブジェクトをより迅速に処理できます。復元されたデータを継続的な復元と並行して処理することで、データワークフローを加速し、ビジネスニーズに迅速に対応できます。
S3 Glacier Faster Standard Retrievals からのより高速な標準取得の開始
このようにパフォーマンスが向上した状態でアーカイブされたデータを復元するには、S3 バッチオペレーションを使用して S3 オブジェクトに対して大規模および小規模の両方のバッチオペレーションを実行できます。S3 バッチオペレーションでは、指定した S3 オブジェクトのリストに対して 1 つのオペレーションを実行できます。S3 バッチオペレーションは、AWS マネジメントコンソール、AWS コマンドラインインターフェイス (AWS CLI)、SDK、または REST API から使用できます。
バッチジョブを作成するには、Amazon S3 コンソールの左側のナビゲーションペインで Batch Operations (バッチオペレーション) を選択し、Create job (ジョブの作成) を選択します。マニフェスト形式の 1 つ、つまり取得したいオブジェクトキーを含む S3 オブジェクトのリストを選択できます。マニフェスト形式が CSV ファイルの場合、ファイルの各行にはバケット名、オブジェクトキー、およびオプションでオブジェクトバージョンを含める必要があります。

次のステップでは、マニフェストにリストされているすべてのオブジェクトに対して実行するオペレーションを選択します。復元オペレーションでは、指定した S3 オブジェクトのリストにあるアーカイブオブジェクトの復元リクエストが開始されます。復元オペレーションを使用すると、マニフェストで指定されているすべてのオブジェクトに対して復元が要求されます。
S3 Glacier Flexible Retrieval ストレージクラスの標準取得層を使用して復元すると、自動的により高速な取得が可能になります。
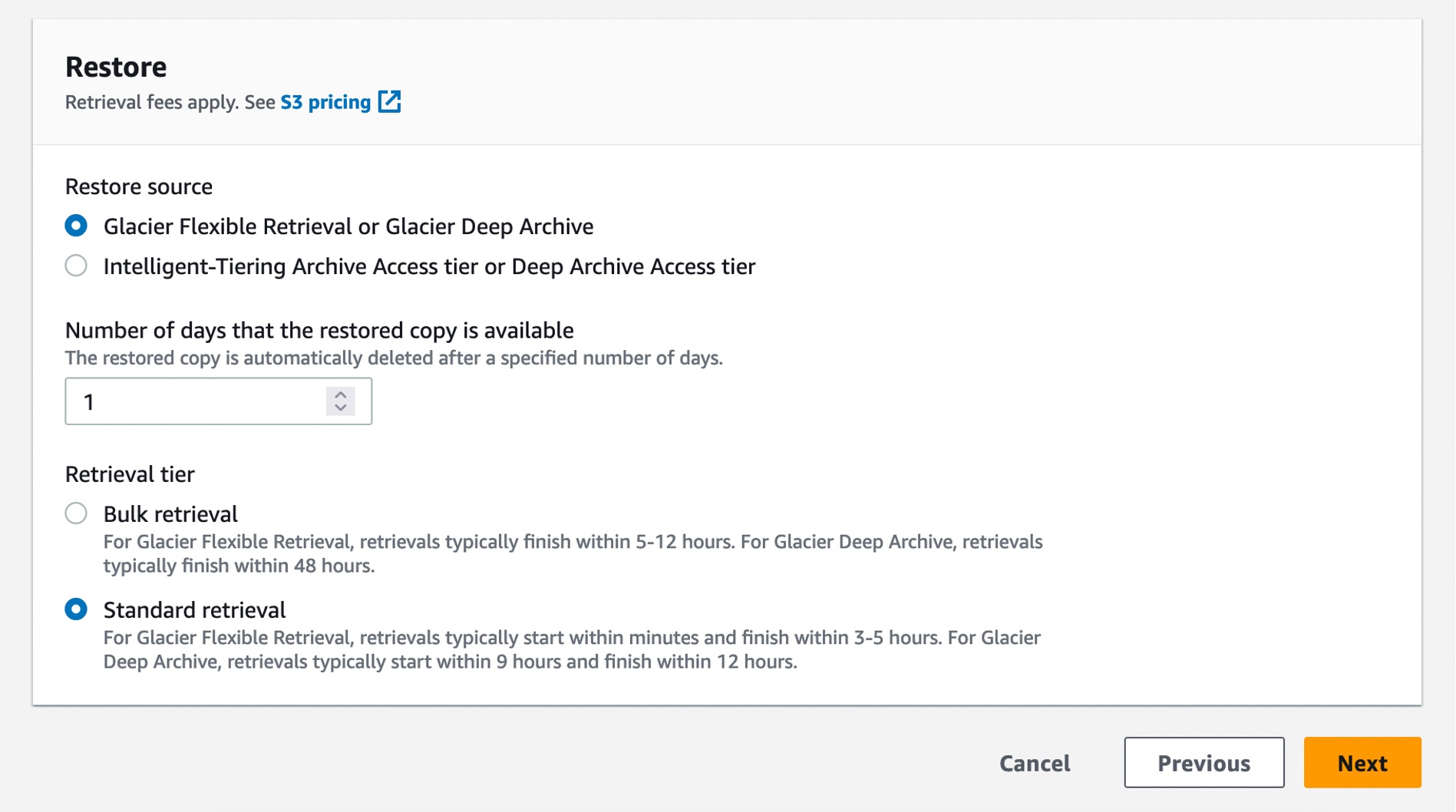
AWS CLI を使用して S3InitiateRestoreObject ジョブで復元ジョブを作成することもできます。
$aws s3control create-job \
--region us-east-1 \
--account-id 123456789012 \
--operation '{"S3InitiateRestoreObject": { "ExpirationInDays": 1, "GlacierJobTier":"STANDARD"} }' \
--report '{"Bucket":"arn:aws:s3:::reports-bucket ","Prefix":"batch-op-restore-job", "Format":" S3BatchOperations_CSV_20180820","Enabled":true,"ReportScope":"FailedTasksOnly"}' \
--manifest '{"Spec":{"Format":"S3BatchOperations_CSV_20180820", "Fields":["Bucket","Key"]},"Location":{"ObjectArn":"arn:aws:s3:::inventory-bucket/inventory_for_restore.csv", "ETag":"<ETag>"}}' \
--role-arn arn:aws:iam::123456789012:role/s3batch-roleその後、次の CLI コマンドを実行して、リクエストのジョブ送信のステータスを確認できます。
$ aws s3control describe-job \
--region us-east-1 \
--account-id 123456789012 \
--job-id <JobID> \
--query 'Job'.'ProgressSummary'ジョブステータスの表示と更新、通知とログの追加、ジョブの失敗の追跡、完了レポートの生成を行うことができます。S3 バッチオペレーションジョブのアクティビティは、AWS CloudTrail にイベントとして記録されます。ジョブイベントを追跡するには、Amazon EventBridge でカスタムルールを作成し、これらのイベントを Amazon Simple Notification Service (Amazon SNS) などの任意のターゲット通知リソースに送信できます。
S3 バッチオペレーションジョブを作成する場合、すべてのタスクまたは失敗したタスクのみの完了レポートをリクエストすることもできます。完了レポートには、オブジェクトキーの名前とバージョン、ステータス、エラーコード、エラーの説明など、各タスクに関する追加情報が含まれています。
詳細については、Amazon S3 ユーザーガイドのジョブステータスと完了レポートの追跡を参照してください。
以下は、それぞれサイズが 100 MB の 250 個のオブジェクトを含むサンプル取得ジョブの結果です。以前の復元パフォーマンスの線 (右側の青い線) からわかるように、これらの復元は通常、標準取得を使用すると 3~5 時間で終了します。現在、S3 バッチオペレーションで標準取得を使用すると、向上したパフォーマンスの線 (左のオレンジ色の線) に示されているように、ジョブは通常数分以内に開始され、データの復元時間が最大 85% 短縮されます。

詳細については、AWS Storage Blog の Amazon S3 Glacier ストレージクラスからアーカイブされたオブジェクトの大規模な復元と Amazon S3 ユーザーガイドのアーカイブされたオブジェクトの復元を参照してください。
今すぐご利用いただけます
Amazon S3 Glacier Flexible Retrieval のより高速な標準取得が、AWS GovCloud (米国) リージョンと中国リージョンを含むすべての AWS リージョンで利用できるようになりました。このパフォーマンスの向上は、追加費用なしでご利用いただけます。 S3 バッチオペレーションとデータ取得には料金がかかります。詳細については、S3 料金のページを参照してください。
 最後に、Amazon S3 Glacier でコールドストレージの価値を最大化というタイトルの新しい eBook を公開しました。この eBook を読んで、Amazon S3 Glacier が、規模や業界を問わず、データアーカイブを変革してビジネス価値を引き出し、俊敏性を高め、ストレージコストを削減する方法を学んでください。
最後に、Amazon S3 Glacier でコールドストレージの価値を最大化というタイトルの新しい eBook を公開しました。この eBook を読んで、Amazon S3 Glacier が、規模や業界を問わず、データアーカイブを変革してビジネス価値を引き出し、俊敏性を高め、ストレージコストを削減する方法を学んでください。
詳細については、S3 Glacier ストレージクラスのページと入門ガイドにアクセスし、AWS re:Post for S3 Glacier にフィードバックを送信するか、通常の AWS サポート窓口を通じてフィードバックを送信してください。
この新機能を使い始めることを本当に楽しみにしています。また、アーカイブデータを使用してビジネスを改革するさらに多くの方法についてお聞きできることを楽しみにしています。
— Channy
原文はこちらです。